Pointer machine
In theoretical computer science a pointer machine is an "atomistic" abstract computational machine model akin to the Random access machine.
Depending on the type, a pointer machine may be called a linking automaton, a KU-machine, an SMM, an atomistic LISP machine, a tree-pointer machine, etc. (cf Ben-Amram 1995). At least three major varieties exist in the literature—the Kolmogorov-Uspenskii model (KUM, KU-machine), the Knuth linking automaton, and the Schönhage Storage Modification Machine model (SMM). The SMM seems to be the most common.
From its "read-only tape" (or equivalent) a pointer machine receives input -- bounded symbol-sequences ("words") made of at least two symbols e.g. { 0, 1 } -- and it writes output symbol-sequences on an output "write-only" tape (or equivalent). To transform a symbol-sequence (input word) to an output symbol-sequence the machine is equipped with a "program" -- a finite-state machine (memory and list of instructions). Via its state machine the program reads the input symbols, operates on its storage structure -- a collection of "nodes" (registers) interconnected by "edges" (pointers labelled with the symbols e.g. { 0, 1 }), and writes symbols on the output tape.
Pointer machines cannot do arithmetic. Computation proceeds only by reading input symbols, modifying and doing various tests on its storage structure—the pattern of nodes and pointers, and outputting symbols based on the tests. "Information" is in the storage structure.
Types of "Pointer Machines"
Both Gurevich and Ben-Amram list a number of very similar "atomistic" models of "abstract machines"; Ben-Amram believes that the 6 "atomistic models" must be distinguished from "High-level" models. This article will discuss the following 3 atomistic models in particular:
- Schönhage's Storage Modification Machines (SMM),
- Kolmogorov-Uspenskii Machines (KUM or KU-Machines),
- Knuth's "Linking Automaton"
But Ben-Amram add more:
- Atomistic Pure-LISP Machine (APLM)
- Atomistic Full-LISP machine (AFLM),
- General atomistic Pointer Machines,
- Jone's I Language (two types)
Problems with the pointer machine model
Use of the model in complexity theory: van Emde Boas (1990) expresses concern that this form of abstract model is:
- "an interesting theoretical model, but ... its attractiveness as a fundamental model for complexity theory is questionable. Its time measure is based on uniform time in a context where this measure is known to underestimate the true time complexity. The same observation holds for the space measure for the machine" (van Emde Boas (1990) p. 35)
Gurevich 1988 also expresses concern:
- "Pragmatically speaking, the Schönhage model provides a good measure of time complexity at the current state of the art (though I would prefer something along the lines of the random access computers of Angluin and Valiant)" (Gurevich (1988) p. 6 with reference to Angluin D. and Valiant L. G., Fast Probabilistic Algorithms for Hamiltonian Circuits and Matchings", Journal of Computer and System Sciences 18 (1979) 155-193.)
The fact that, in §3 and §4 (pp. 494–497), Schönhage himself (1980) demonstrates the real-time equivalences of his two Random Access Machine models "RAM0" and "RAM1" leads one to question the necessity of the SMM for complexity studies.
Potential uses for the model: However, Schönhage (1980) demonstrates in his §6, Integer-multiplication in linear time. And Gurevich wonders whether or not the "parallel KU machine" "resembles somewhat the human brain" (Gurevich (1988) p. 5)
Schönhage's Storage Modification Machine (SMM) model
Schönhage's SMM model seems to be the most common and most accepted. It is quite unlike the register machine model and other common computational models e.g. the tape-based Turing machine or the labeled holes and indistinguishable pebbles of the counter machine.[1]
The computer consists of a fixed alphabet of input symbols, and a mutable directed graph (aka a state diagram) with its arrows labelled by alphabet symbols. Each node of the graph has exactly one outgoing arrow labelled with each symbol, although some of these may loop back into the original node. One fixed node of the graph is identified as the start or "active" node.
Each word of symbols in the alphabet can then be translated to a pathway through the machine; for example 10011 would translate to taking path 1 from the start node, then path 0 from the resulting node, then path 0, then path 1, then path 1. The path can in turn be identified with the resulting node, but this identification will change as the graph changes during the computation.
The machine can receive instructions which change the layout of the graph. The basic instructions are the new w instruction, which creates a new node which is the "result" of following the string w, and the set w to v instruction which (re)directs an edge to a different node. Here w and v represent words. v is a former word—i.e. a previously-created string of symbols—so that the redirected edge will point "backwards" to an old node that is the "result" of that string.
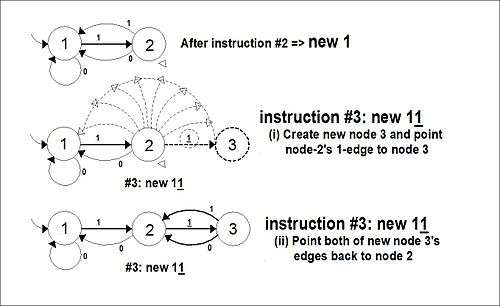
(1) new w: creates a new node. w represents the new word that creates the new node. The machine reads the word w, following the path represented by the symbols of w until the machine comes to the last, "additional" symbol in the word. The additional symbol instead forces the last state to create a new node, and "flip" its corresponding arrow (the one labelled with that symbol) from its old position to point to the new node. The new node in turn points all its edges back to the old last-state, where they just "rest" until redirected by another new or set. In a sense the new nodes are "sleeping", waiting for an assignment. In the case of the starting or center node we likewise would begin with both of its edges pointing back to itself.
- Example: Let "w" be 10110[1], where the final character is in brackets to denote its special status. We take the 1 edge of the node reached by 10110 (at the end of a five-edge, hence six-node, pathway), and point it to a new 7th node. The two edges of this new node then point "backward" to the 6th node of the path.
(2)Set w to v: redirects (moves) an edge (arrow) from the path represented by word w to a former node that represents word v. Again it is the last arrow in the path that is redirected.
- Example: Set 1011011 to 1011, after the above instruction, would change the 1 arrow of the new node at 101101 to point to the fifth node in the pathway, reached at 1011. Thus the path 1011011 would now have the same result as 1011.
(3)If v = w then instruction z : Conditional instruction that compares two paths represented by words w and v to see if they end at the same node; if so jump to instruction z else continue. This instruction serves the same purpose as its counterpart in a register machine or Wang b-machine, corresponding to a Turing machine's ability to jump to a new state.

Knuth's "Linking Automaton" model
According to Schoenhage, Knuth noted that the SMM model coincides with a special type of "linking automata" briefly explained in volume one of The Art of Computer Programming (cf. [4, pp. 462-463])
Kolmogorov-Uspenskii Machine (KU-machine) model
KUM differs from SMM in allowing only invertible pointers: for every pointer from a node x to a node y, an inverse pointer from y to x must be present. Since outgoing pointers must be labeled by distinct symbols of the alphabet, both KUM and SMM graphs have O(1) outdegree. However, KUM pointers' invertibility restricts the in-degree to O(1), as well. This addresses some concerns for physical (as opposite to purely informational) realism, like those in the above van Emde Boas quote.
An additional difference is that the KUM was intended as a generalization of the Turing machine, and so it allows the currently "active" node to be moved around the graph. Accordingly, nodes can be specified by individual characters instead of words, and the action to be taken can be determined by a state table instead of a fixed list of instructions.
See also
Register machine -- generic register-based abstract machine computational model
- Counter machine -- most primitive machine, base models' instruction-sets are used throughout the class of register machines
- Random access machine -- RAM: counter machine with added indirect addressing capability
- Random access stored program machine -- RASP: counter-based or RAM-based machine with a "program of instructions" to be found in the registers themselves in the matter of a Universal Turing machine i.e. the von Neumann architecture.
Turing machine -- generic tape-based abstract machine computational model
- Post-Turing machine -- minimalist one-tape, two-direction, 1 symbol { blank, mark } Turing-like machine but with default sequential instruction execution in a manner similar to the basic 3-instruction counter machines.
References
- ↑ The treatment is that of van Emde Boas 1990 rather than of Schönhage, which lacks examples.
Most references and a bibliography are to be found at the article Register machine. The following are particular to this article:
- Amir Ben-Amram (1995), What is a "Pointer machine?, SIGACTN: SIGACT News (ACM Special Interest Group on Automata and Computability Theory)", volume 26, 1995. also: DIKU, Department of Computer Science, University of Copenhagen, amirben@diku.dk. Wherein Ben-Amram describes the types and subtypes: (type 1a) Abstract Machines: Atomistic models including Kolmogorov-Uspenskii Machines (KUM), Schönhage's Storage Modification Machines (SMM), Knuth's "Linking Automaton", APLM and AFLM (Atomistic Pure-LISP Machine) and (Atomistic Full-LISP machine), General atomistic Pointer Machines, Jone's I Language; (type 1b) Abstract Machines: High-level models, (type 2) Pointer algorithms.
- Andrey Kolmogorov and V. Uspenskii, On the definition of an algorithm, Uspehi Mat. Nauk. 13 (1958), 3-28. English translation in American Mathematical Society Translations, Series II, Volume 29 (1963), pp. 217–245.
- Yuri Gurevich (2000), Sequential Abstract State Machines Capture Sequential Algorithms, ACM Transactions on Computational Logic, vol. 1, no. 1, (July 2000), pages 77–111. In a single sentence Gurevich compares the Schönhage [1980] "storage modification machines" to Knuth's "pointer machines." For more, similar models such as "random access machines" Gurevich references:
- J. E. Savage (1998), Models of Computation: Exploring the Power of Computing. Addison Wesley Longman.
- Yuri Gurevich (1988), On Kolmogorov Machines and Related Issues, the column on "Logic in Computer Science", Bulletin of European Association for Theoretical Computer Science, Number 35, June 1988, 71-82. Introduced the unified description of Schōnhage and Kolmogorov-Uspenskii machines used here.
- A. Schōnhage (1980), Storage Modification Machines, Society for Industrial and Applied Mathematics, SIAM J. Comput. Vol. 9, No. 3, August 1980. Wherein Schōnhage shows the equivalence of his SMM with the "successor RAM" (Random Access Machine), etc. He refers to an earlier paper where he introduces the SMM:
- A. Schōnhage (1970), Universelle Turing Speicherung, Automatentheorie und Formale Sprachen, Dōrr, Hotz, eds. Bibliogr. Institut, Mannheim, 1970, pp. 69–383.
- Peter van Emde Boas, Machine Models and Simulations pp. 3–66, appearing in:
- Jan van Leeuwen, ed. "Handbbook of Theoretical Computer Science. Volume A: Algorithms and Complexity, The MIT PRESS/Elsevier, 1990. ISBN 0-444-88071-2 (volume A). QA 76.H279 1990.
- van Emde Boas' treatment of SMMs appears on pp. 32-35. This treatment clarifies Schōnhage 1980 -- it closely follows but expands slightly the Schōnhage treatment. Both references may be needed for effective understanding.