Pivot language
A pivot language, sometimes also called a bridge language, is an artificial or natural language used as an intermediary language for translation between many different languages – to translate between any pair of languages A and B, one translates A to the pivot language P, then from P to B. Using a pivot language avoids the combinatorial explosion of having translators across every combination of the supported languages, as the number of combinations of language is linear ( ), rather than quadratic
), rather than quadratic 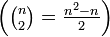 – one need only know the language A and the pivot language P (and someone else the language B and the pivot P), rather than needing a different translator for every possible combination of A and B.
– one need only know the language A and the pivot language P (and someone else the language B and the pivot P), rather than needing a different translator for every possible combination of A and B.
The disadvantage of a pivot language is that each step of retranslation introduces possible mistakes and ambiguities – using a pivot language involves two steps, rather than one. For example, when Hernán Cortés communicated with Mesoamerican Indians, he would speak Spanish to Gerónimo de Aguilar, who would speak Mayan to Malintzin, who would speak Nahuatl to the locals.
Examples
English, French, Russian, and Arabic are often used as pivot languages. Interlingua has been used as a pivot language in international conferences and has been proposed as a pivot language for the European Union.[1] Esperanto was proposed as a pivot language in the Distributed Language Translation project and has been used in this way in the Majstro Tradukvortaro at the Esperanto website Majstro.com. The Universal Networking Language is an artificial language specifically designed for use as a pivot language.
In computing
Pivot coding is also a common method of translating data for computer systems. For example, the internet protocol, XML and high level languages are pivot codings of computer data which are then often rendered into internal binary formats for particular computer systems.
Unicode was designed to be usable as a pivot coding between various major existing character encodings, though its widespread adoption as a coding in its own right has made this usage unimportant.
In machine translation (MT)
Current statistical machine translation (SMT) systems use parallel corpora for source (s) and target (t) languages to achieve their good results, but good parallel corpora are not available for all languages. A pivot language (p) enables the bridge between two languages, to which existing parallel corpora are entirely or partially not yet at hand.
Pivot translation can be problematic because of the potential lack of fidelity of the information forwarded in the use of different corpora. From the use of two bilingual corpora (s-p & p-t) to set up the s-t bridge, linguistic data are inevitably lost. Rule-based machine translation (RBMT) helps the system rescue this information, so that the system does not rely entirely on statistics but also on structural linguistic information.
Three basic techniques are used to employ pivot language in MT: (1) triangulation, which focuses on phrase paralleling between source and pivot (s-p) and between pivot and target (p-t); (2) transfer, which translates the whole sentence of the source language to a pivot language and then to the target language; and (3) synthesis, which builds a corpus of its own for system training.
The triangulation method (also called phrase table multiplication) calculates the probability of both translation correspondences and lexical weight in s-p and p-t, to try to induce a new s-t phrase table. The transfer method (also called sentence translation strategy) simply carries a straightforward translation of s into p and then another translation of p into t without using probabilistic tests (as in triangulation). The synthetic method uses an existing corpus of s and tries to build an own synthetic corpus out of it that is used by the system to train itself. Then a bilingual s-p corpus is synthesized to enable a p-t translation.
A direct comparison between triangulation and transfer methods for SMT systems has shown that triangulation achieves much better results than transfer.
All three pivot language techniques enhance the performance of SMT systems. However, the synthetic technique doesn't work well with RBMT, and systems' performances are lower than expected. Hybrid SMT/RBMT systems achieve better translation quality than strict-SMT systems that rely on bad parallel corpora.
The key role of RBMT systems is that they help fill the gap left in the translation process of s-p → p-t, in the sense that these parallels are included in the SMT model for s-t.
References
- ↑ Breinstrup, Thomas. "Linguaphobos? Non in le UE". [Linguaphobes? Not in the EU]. Panorama in Interlingua, 2006, Issue 5.