Resampling (statistics)
In statistics, resampling is any of a variety of methods for doing one of the following:
- Estimating the precision of sample statistics (medians, variances, percentiles) by using subsets of available data (jackknifing) or drawing randomly with replacement from a set of data points (bootstrapping)
- Exchanging labels on data points when performing significance tests (permutation tests, also called exact tests, randomization tests, or re-randomization tests)
- Validating models by using random subsets (bootstrapping, cross validation)
Common resampling techniques include bootstrapping, jackknifing and permutation tests.
Bootstrap
Bootstrapping is a statistical method for estimating the sampling distribution of an estimator by sampling with replacement from the original sample, most often with the purpose of deriving robust estimates of standard errors and confidence intervals of a population parameter like a mean, median, proportion, odds ratio, correlation coefficient or regression coefficient. It may also be used for constructing hypothesis tests. It is often used as a robust alternative to inference based on parametric assumptions when those assumptions are in doubt, or where parametric inference is impossible or requires very complicated formulas for the calculation of standard errors. Bootstrapping techniques are also used in the updating-selection transitions of particle filters, genetic type algorithms and related Resample/Reconfiguration Monte Carlo methods used in computational physics and molecular chemistry.[1][2] . In this context, the bootstrap is used to replace sequentially empirical weighted probability measures by empirical measures. The bootstrap allows to replace the samples with low weights by copies of the samples with high weights.
Jackknife
Jackknifing, which is similar to bootstrapping, is used in statistical inference to estimate the bias and standard error (variance) of a statistic, when a random sample of observations is used to calculate it. Historically this method preceded the invention of the bootstrap with Quenouille inventing this method in 1949 and Tukey extending it in 1958.[3][4] This method was foreshadowed by Mahalanobis who in 1946 suggested repeated estimates of the statistic of interest with half the sample chosen at random.[5] He coined the name 'interpenetrating samples' for this method.
Quenouille invented this method with the intention of reducing the bias of the sample estimate. Tukey extended this method by assuming that if the replicates could be considered identically and independently distributed, then an estimate of the variance of the sample parameter could be made and that it would be approximately distributed as a t variate with n−1 degrees of freedom (n being the sample size).
The basic idea behind the jackknife variance estimator lies in systematically recomputing the statistic estimate, leaving out one or more observations at a time from the sample set. From this new set of replicates of the statistic, an estimate for the bias and an estimate for the variance of the statistic can be calculated.
Instead of using the jackknife to estimate the variance, it may instead be applied to the log of the variance. This transformation may result in better estimates particularly when the distribution of the variance itself may be non normal.
For many statistical parameters the jackknife estimate of variance tends asymptotically to the true value almost surely. In technical terms one says that the jackknife estimate is consistent. The jackknife is consistent for the sample means, sample variances, central and non-central t-statistics (with possibly non-normal populations), sample coefficient of variation, maximum likelihood estimators, least squares estimators, correlation coefficients and regression coefficients.
It is not consistent for the sample median. In the case of a unimodal variate the ratio of the jackknife variance to the sample variance tends to be distributed as one half the square of a chi square distribution with two degrees of freedom.
The jackknife, like the original bootstrap, is dependent on the independence of the data. Extensions of the jackknife to allow for dependence in the data have been proposed.
Another extension is the delete-a-group method used in association with Poisson sampling.
Comparison of bootstrap and jackknife
Both methods, the bootstrap and the jackknife, estimate the variability of a statistic from the variability of that statistic between subsamples, rather than from parametric assumptions. For the more general jackknife, the delete-m observations jackknife, the bootstrap can be seen as a random approximation of it. Both yield similar numerical results, which is why each can be seen as approximation to the other. Although there are huge theoretical differences in their mathematical insights, the main practical difference for statistics users is that the bootstrap gives different results when repeated on the same data, whereas the jackknife gives exactly the same result each time. Because of this, the jackknife is popular when the estimates need to be verified several times before publishing (e.g., official statistics agencies). On the other hand, when this verification feature is not crucial and it is of interest not to have a number but just an idea of its distribution, the bootstrap is preferred (e.g., studies in physics, economics, biological sciences).
Whether to use the bootstrap or the jackknife may depend more on operational aspects than on statistical concerns of a survey. The jackknife, originally used for bias reduction, is more of a specialized method and only estimates the variance of the point estimator. This can be enough for basic statistical inference (e.g., hypothesis testing, confidence intervals). The bootstrap, on the other hand, first estimates the whole distribution (of the point estimator) and then computes the variance from that. While powerful and easy, this can become highly computer intensive.
"The bootstrap can be applied to both variance and distribution estimation problems. However, the bootstrap variance estimator is not as good as the jackknife or the balanced repeated replication (BRR) variance estimator in terms of the empirical results. Furthermore, the bootstrap variance estimator usually requires more computations than the jackknife or the BRR. Thus, the bootstrap is mainly recommended for distribution estimation." [6]
There is a special consideration with the jackknife, particularly with the delete-1 observation jackknife. It should only be used with smooth, differentiable statistics (e.g., totals, means, proportions, ratios, odd ratios, regression coefficients, etc.; not with medians or quantiles). This may become a practical disadvantage (or not, depending on the needs of the user). This disadvantage is usually the argument favoring bootstrapping over jackknifing. More general jackknifes than the delete-1, such as the delete-m jackknife, overcome this problem for the medians and quantiles by relaxing the smoothness requirements for consistent variance estimation.
Usually the jackknife is easier to apply to complex sampling schemes than the bootstrap. Complex sampling schemes may involve stratification, multiple stages (clustering), varying sampling weights (non-response adjustments, calibration, post-stratification) and under unequal-probability sampling designs. Theoretical aspects of both the bootstrap and the jackknife can be found in Shao and Tu (1995),[7] whereas a basic introduction is accounted in Wolter (2007).[8] The bootstrap estimate of model prediction bias is more precise than jacknife estimates with linear models such as linear discriminant function or multiple regression.[9]
Subsampling
Subsampling is an alternative method for approximating the sampling distribution of an estimator. The two key differences to the bootstrap are: (i) the resample size is smaller than the sample size and (ii) resampling is done without replacement. The advantage of subsampling is that it is valid under much weaker conditions compared to the bootstrap. In particular, a set of sufficient conditions is that the rate of convergence of the estimator is known and that the limiting distribution is continuous; in addition, the resample (or subsample) size must tend to infinity together with the sample size but at a smaller rate, so that their ratio converges to zero. While subsampling was originally proposed for the case of independent and identically distributed (iid) data only, the methodology has been extended to cover time series data as well; in this case, one resamples blocks of subsequent data rather than individual data points. There are many cases of applied interest where subsampling leads to valid inference whereas bootstrapping does not; for example, such cases include examples where the rate of convergence of the estimator is not the square root of the sample size or when the limiting distribution is non-normal.
Cross-validation
Cross-validation is a statistical method for validating a predictive model. Subsets of the data are held out for use as validating sets; a model is fit to the remaining data (a training set) and used to predict for the validation set. Averaging the quality of the predictions across the validation sets yields an overall measure of prediction accuracy. Cross-Validation is employed repeatedly in building decision trees.
One form of cross-validation leaves out a single observation at a time; this is similar to the jackknife. Another, K-fold cross-validation, splits the data into K subsets; each is held out in turn as the validation set.
This avoids "self-influence". For comparison, in regression analysis methods such as linear regression, each y value draws the regression line toward itself, making the prediction of that value appear more accurate than it really is. Cross-validation applied to linear regression predicts the y value for each observation without using that observation.
This is often used for deciding how many predictor variables to use in regression. Without cross-validation, adding predictors always reduces the residual sum of squares (or possibly leaves it unchanged). In contrast, the cross-validated mean-square error will tend to decrease if valuable predictors are added, but increase if worthless predictors are added.[10]
Permutation tests

A permutation test (also called a randomization test, re-randomization test, or an exact test) is a type of statistical significance test in which the distribution of the test statistic under the null hypothesis is obtained by calculating all possible values of the test statistic under rearrangements of the labels on the observed data points. In other words, the method by which treatments are allocated to subjects in an experimental design is mirrored in the analysis of that design. If the labels are exchangeable under the null hypothesis, then the resulting tests yield exact significance levels; see also exchangeability. Confidence intervals can then be derived from the tests. The theory has evolved from the works of Ronald Fisher and E. J. G. Pitman in the 1930s.
To illustrate the basic idea of a permutation test,
suppose we have two groups 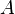 and
and 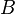 whose sample means
are
whose sample means
are 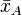 and
and 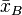 ,
and that we want to test, at 5% significance level, whether they come from the same distribution.
Let
,
and that we want to test, at 5% significance level, whether they come from the same distribution.
Let 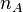 and
and 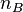 be the sample
size corresponding to each group.
The permutation test is designed to
determine whether the observed difference
between the sample means is large enough
to reject the null hypothesis H
be the sample
size corresponding to each group.
The permutation test is designed to
determine whether the observed difference
between the sample means is large enough
to reject the null hypothesis H that
the two groups have identical probability distribution.
that
the two groups have identical probability distribution.
The test proceeds as follows.
First, the difference in means between the two samples is calculated: this is the observed value of the test statistic, T(obs). Then the observations of groups and are pooled.
Next, the difference in sample means is calculated and recorded for every possible way of dividing these pooled values into two groups of size and (i.e., for every permutation of the group labels A and B). The set of these calculated differences is the exact distribution of possible differences under the null hypothesis that group label does not matter.
The one-sided p-value of the test is calculated as the proportion of sampled permutations where the difference in means was greater than or equal to T(obs). The two-sided p-value of the test is calculated as the proportion of sampled permutations where the absolute difference was greater than or equal to ABS(T(obs)).
If the only purpose of the test is reject or not reject the null hypothesis, we can as an alternative sort the recorded differences, and then observe if T(obs) is contained within the middle 95% of them. If it is not, we reject the hypothesis of identical probability curves at the 5% significance level.
Relation to parametric tests
Permutation tests are a subset of non-parametric statistics. The basic premise is to use only the assumption that it is possible that all of the treatment groups are equivalent, and that every member of them is the same before sampling began (i.e. the slot that they fill is not differentiable from other slots before the slots are filled). From this, one can calculate a statistic and then see to what extent this statistic is special by seeing how likely it would be if the treatment assignments had been jumbled.
In contrast to permutation tests, the reference distributions for many popular "classical" statistical tests, such as the t-test, F-test, z-test, and χ2 test, are obtained from theoretical probability distributions. Fisher's exact test is an example of a commonly used permutation test for evaluating the association between two dichotomous variables. When sample sizes are very large, the Pearson's chi-square test will give accurate results. For small samples, the chi-square reference distribution cannot be assumed to give a correct description of the probability distribution of the test statistic, and in this situation the use of Fisher's exact test becomes more appropriate.
Permutation tests exist in many situations where parametric tests do not (e.g., when deriving an optimal test when losses are proportional to the size of an error rather than its square). All simple and many relatively complex parametric tests have a corresponding permutation test version that is defined by using the same test statistic as the parametric test, but obtains the p-value from the sample-specific permutation distribution of that statistic, rather than from the theoretical distribution derived from the parametric assumption. For example, it is possible in this manner to construct a permutation t-test, a permutation χ2 test of association, a permutation version of Aly's test for comparing variances and so on.
The major down-side to permutation tests are that they
- Can be computationally intensive and may require "custom" code for difficult-to-calculate statistics. This must be rewritten for every case.
- Are primarily used to provide a p-value. The inversion of the test to get confidence regions/intervals requires even more computation.
Advantages
Permutation tests exist for any test statistic, regardless of whether or not its distribution is known. Thus one is always free to choose the statistic which best discriminates between hypothesis and alternative and which minimizes losses.
Permutation tests can be used for analyzing unbalanced designs[11] and for combining dependent tests on mixtures of categorical, ordinal, and metric data (Pesarin, 2001). They can also be used to analyze qualitative data that has been quantitized (i.e., turned into numbers). Permutation tests may be ideal for analyzing quantitized data that do not satisfy statistical assumptions underlying traditional parametric tests (e.g., t-tests, ANOVA) (Collingridge, 2013).
Before the 1980s, the burden of creating the reference distribution was overwhelming except for data sets with small sample sizes.
Since the 1980s, the confluence of relatively inexpensive fast computers and the development of new sophisticated path algorithms applicable in special situations, made the application of permutation test methods practical for a wide range of problems. It also initiated the addition of exact-test options in the main statistical software packages and the appearance of specialized software for performing a wide range of uni- and multi-variable exact tests and computing test-based "exact" confidence intervals.
Limitations
An important assumption behind a permutation test is that the observations are exchangeable under the null hypothesis. An important consequence of this assumption is that tests of difference in location (like a permutation t-test) require equal variance. In this respect, the permutation t-test shares the same weakness as the classical Student's t-test (the Behrens–Fisher problem). A third alternative in this situation is to use a bootstrap-based test. Good (2005) explains the difference between permutation tests and bootstrap tests the following way: "Permutations test hypotheses concerning distributions; bootstraps test hypotheses concerning parameters. As a result, the bootstrap entails less-stringent assumptions." Bootstrap tests are not exact.
Monte Carlo testing
An asymptotically equivalent permutation test can be created when there are too many possible orderings of the data to allow complete enumeration in a convenient manner. This is done by generating the reference distribution by Monte Carlo sampling, which takes a small (relative to the total number of permutations) random sample of the possible replicates. The realization that this could be applied to any permutation test on any dataset was an important breakthrough in the area of applied statistics. The earliest known reference to this approach is Dwass (1957).[12] This type of permutation test is known under various names: approximate permutation test, Monte Carlo permutation tests or random permutation tests.[13]
After  random permutations, it is possible to obtain a confidence interval for the p-value based on the Binomial distribution. For example, if after
random permutations, it is possible to obtain a confidence interval for the p-value based on the Binomial distribution. For example, if after 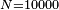 random permutations the p-value is estimated to be
random permutations the p-value is estimated to be 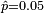 , then a 99% confidence interval for the true
, then a 99% confidence interval for the true  (the one that would result from trying all possible permutations) is
(the one that would result from trying all possible permutations) is ![\scriptstyle\ [0.044, 0.056]](../I/m/970ebb36d1b01bc8f1a36c78c3d54b42.png) .
.
On the other hand, the purpose of estimating the p-value is most often to decide whether 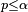 , where
, where  is the threshold at which the null hypothesis will be rejected (typically
is the threshold at which the null hypothesis will be rejected (typically 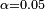 ). In the example above, the confidence interval only tells us that there is roughly a 50% chance that the p-value is smaller than 0.05, i.e. it is completely unclear whether the null hypothesis should be rejected at a level .
). In the example above, the confidence interval only tells us that there is roughly a 50% chance that the p-value is smaller than 0.05, i.e. it is completely unclear whether the null hypothesis should be rejected at a level .
If it is only important to know whether for a given , it is logical to continue simulating until the statement can be established to be true or false with a very low probability of error. Given a bound  on the admissible probability of error (the probability of finding that
on the admissible probability of error (the probability of finding that 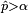 when in fact or vice versa), the question of how many permutations to generate can be seen as the question of when to stop generating permutations, based on the outcomes of the simulations so far, in order to guarantee that the conclusion (which is either or
when in fact or vice versa), the question of how many permutations to generate can be seen as the question of when to stop generating permutations, based on the outcomes of the simulations so far, in order to guarantee that the conclusion (which is either or 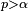 ) is correct with probability at least as large as
) is correct with probability at least as large as 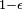 . ( will typically be chosen to be extremely small, e.g. 1/1000.) Stopping rules to achieve this have been developed[14] which can be incorporated with minimal additional computational cost. In fact, depending on the true underlying p-value it will often be found that the number of simulations required is remarkably small (e.g. as low as 5 and often not larger than 100) before a decision can be reached with virtual certainty.
. ( will typically be chosen to be extremely small, e.g. 1/1000.) Stopping rules to achieve this have been developed[14] which can be incorporated with minimal additional computational cost. In fact, depending on the true underlying p-value it will often be found that the number of simulations required is remarkably small (e.g. as low as 5 and often not larger than 100) before a decision can be reached with virtual certainty.
See also
- Bootstrap aggregating (Bagging)
- Particle filter
- Genetic algorithms
- Random permutation
- Monte Carlo methods
- Nonparametric statistics
References
- ↑ Del Moral, Pierre (2004). Feynman-Kac formulae. Genealogical and interacting particle approximations. Springer. p. 575.
Series: Probability and Applications
- ↑ Del Moral, Pierre (2013). Mean field simulation for Monte Carlo integration. Chapman & Hall/CRC Press. p. 626.
Monographs on Statistics & Applied Probability
- ↑ Quenouille, M. H. (1949). Approximate Tests of Correlation in Time-Series. J Roy Stat Soc Series B 11. pp. 68–84. JSTOR 2983696.
- ↑ Tukey, J. W. (1958). "Bias and Confidence in Not-quite Large Samples (Preliminary Report)". Ann Math Stats 29 (2): 614. JSTOR 2237363.
- ↑ Mahalanobis, P. C. (1946). "Proceedings of a Meeting of the Royal Statistical Society held on July 16th, 1946". J Roy Stat Soc 109 (4): 325–370. JSTOR 2981330.
- ↑ Shao, J. and Tu, D. (1995). The Jackknife and Bootstrap. Springer-Verlag, Inc. pp. 281.
- ↑ Shao, J.; Tu, D. (1995). The Jackknife and Bootstrap. Springer.
- ↑ Wolter, K. M. (2007). Introduction to Variance Estimation (Second ed.). Springer.
- ↑ Verbyla, D.; Litvaitis, J. (1989). "Resampling methods for evaluating classification accuracy of wildlife habitat models". Env. Management. 13 (6): 783–787. doi:10.1007/bf01868317.
- ↑ Verbyla, D. (1986). "Potential prediction bias in regression and discriminant analysis". Can. J. For. Res. 16 (6): 1255–1257. doi:10.1139/x86-222.
- ↑ Journal of Modern Applied Statistical Methods at the Wayback Machine (archived May 5, 2003)
- ↑ Dwass, Meyer (1957). "Modified Randomization Tests for Nonparametric Hypotheses". Annals of Mathematical Statistics 28 (1): 181–187. doi:10.1214/aoms/1177707045. JSTOR 2237031.
- ↑ Thomas E. Nichols, Andrew P. Holmes (2001). "Nonparametric Permutation Tests For Functional Neuroimaging: A Primer with Examples" (PDF). Human Brain Mapping 15 (1): 1–25. doi:10.1002/hbm.1058. PMID 11747097.
- ↑ Gandy, Axel (2009). "Sequential implementation of Monte Carlo tests with uniformly bounded resampling risk". Journal of the American Statistical Association 104 (488): 1504–1511. doi:10.1198/jasa.2009.tm08368.
- Good, Phillip (2005), Permutation, Parametric and Bootstrap Tests of Hypotheses (3rd ed.), Springer
Bibliography
Introductory statistics
- Good, P. (2005) Introduction to Statistics Through Resampling Methods and R/S-PLUS. Wiley. ISBN 0-471-71575-1
- Good, P. (2005) Introduction to Statistics Through Resampling Methods and Microsoft Office Excel. Wiley. ISBN 0-471-73191-9
- Hesterberg, T. C., D. S. Moore, S. Monaghan, A. Clipson, and R. Epstein (2005). Bootstrap Methods and Permutation Tests.
- Wolter, K.M. (2007). Introduction to Variance Estimation. Second Edition. Springer, Inc.
Bootstrap
- Efron, Bradley (1979). "Bootstrap methods: Another look at the jackknife". The Annals of Statistics 7: 1–26. doi:10.1214/aos/1176344552.
- Efron, Bradley (1981). "Nonparametric estimates of standard error: The jackknife, the bootstrap and other methods". Biometrika 68: 589–599. doi:10.2307/2335441.
- Efron, Bradley (1982). The jackknife, the bootstrap, and other resampling plans, In Society of Industrial and Applied Mathematics CBMS-NSF Monographs, 38.
- Diaconis, P.; Efron, Bradley (1983), "Computer-intensive methods in statistics," Scientific American, May, 116-130.
- Efron, Bradley; Tibshirani, Robert J. (1993). An introduction to the bootstrap, New York: Chapman & Hall, software.
- Davison, A. C. and Hinkley, D. V. (1997): Bootstrap Methods and their Application, software.
- Mooney, C Z & Duval, R D (1993). Bootstrapping. A Nonparametric Approach to Statistical Inference. Sage University Paper series on Quantitative Applications in the Social Sciences, 07-095. Newbury Park, CA: Sage.
- Simon, J. L. (1997): Resampling: The New Statistics.
Jackknife
- Berger, Y.G. (2007). "A jackknife variance estimator for unistage stratified samples with unequal probabilities". Biometrika 94 (4): 953–964. doi:10.1093/biomet/asm072.
- Berger, Y.G.; Rao, J.N.K. (2006). "Adjusted jackknife for imputation under unequal probability sampling without replacement". Journal of the Royal Statistical Society B. 68 (3): 531–547. doi:10.1111/j.1467-9868.2006.00555.x.
- Berger, Y.G.; Skinner, C.J. (2005). "A jackknife variance estimator for unequal probability sampling". Journal of the Royal Statistical Society B. 67 (1): 79–89. doi:10.1111/j.1467-9868.2005.00489.x.
- Jiang, J.; Lahiri, P.; Wan, S-M. (2002). "A unified jackknife theory for empirical best prediction with M-estimation". The Annals of Statistics 30 (6): 1782–810. doi:10.1214/aos/1043351257.
- Jones, H.L. (1974). "Jackknife estimation of functions of stratum means". Biometrika 61 (2): 343–348. doi:10.2307/2334363.
- Kish, L. and Frankel M.R. (1974). Inference from complex samples. Journal of the Royal Statistical Society B. Vol. 36, 1, pp. 1–37.
- Krewski, D.; Rao, J.N.K. (1981). "Inference from stratified samples: properties of the linearization, jackknife and balanced repeated replication methods". The Annals of Statistics 9 (5): 1010–1019. doi:10.1214/aos/1176345580.
- Quenouille, M.H. (1956). "Notes on bias in estimation". Biometrika 43: 353–360. doi:10.1093/biomet/43.3-4.353.
- Rao, J.N.K.; Shao, J. (1992). "Jackknife variance estimation with survey data under hot deck imputation". Biometrika 79 (4): 811–822. doi:10.1093/biomet/79.4.811.
- Rao, J.N.K.; Wu, C.F.J.; Yue, K. (1992). "Some recent work on resampling methods for complex surveys". Survey Methodology 18 (2): 209–217.
- Shao, J. and Tu, D. (1995). The Jackknife and Bootstrap. Springer-Verlag, Inc.
- Tukey, J.W. (1958). "Bias and confidence in not-quite large samples (abstract)". The Annals of Mathematical Statistics 29 (2): 614.
- Wu, C.F.J. (1986). "Jackknife, Bootstrap and other resampling methods in regression analysis". The Annals of Statistics 14 (4): 1261–1295. doi:10.1214/aos/1176350142.
Subsampling
- Delgado, M.; Rodriguez-Poo, J.; Wolf, M. (2001). "Subsampling inference in cube root asymptotics with an application to Manski's maximum score estimator". Economics Letters 73: 241–250. doi:10.1016/s0165-1765(01)00494-3.
- Gonzalo, J.; Wolf, M. (2005). "Subsampling inference in threshold autoregressive models". Journal of Econometrics 127: 201–224. doi:10.1016/j.jeconom.2004.08.004.
- Politis, D.N.; Romano, J.P. (1994). "Large-sample confidence regions based on subsamples under minimal assumptions". The Annals of Statistics 22: 2031–2050. doi:10.1214/aos/1176325770.
- Politis, D.N.; Romano, J.P.; Wolf, M. (1997). "Subsampling for heteroskedastic time series". Journal of Econometrics 81: 281–317. doi:10.1016/s0304-4076(97)86569-4.
- Politis, D.N., Romano, J.P., and Wolf, M. (1999). Subsampling. Springer, New York.
- Romano, J.P.; Wolf, M. (2001). "Subsampling intervals in autoregressive models with linear time trend". Econometrica 69: 1283–1314. doi:10.1111/1468-0262.00242.
Monte Carlo methods
- George S. Fishman (1995). Monte Carlo: Concepts, Algorithms, and Applications, Springer, New York. ISBN 0-387-94527-X.
- James E. Gentle (2009). Computational Statistics, Springer, New York. Part III: Methods of Computational Statistics. ISBN 978-0-387-98143-7.
- Pierre Del Moral (2004). Feynman-Kac formulae. Genealogical and Interacting particle systems with applications, Springer, Series Probability and Applications. ISBN 978-0-387-20268-6
- Pierre Del Moral (2013). Del Moral, Pierre (2013). Mean field simulation for Monte Carlo integration. Chapman & Hall/CRC Press, Monographs on Statistics and Applied Probability. ISBN 9781466504059
- Dirk P. Kroese, Thomas Taimre and Zdravko I. Botev. Handbook of Monte Carlo Methods, John Wiley & Sons, New York. ISBN 978-0-470-17793-8.
- Christian P. Robert and George Casella (2004). Monte Carlo Statistical Methods, Second ed., Springer, New York. ISBN 0-387-21239-6.
- Shlomo Sawilowsky and Gail Fahoome (2003). Statistics via Monte Carlo Simulation with Fortran. Rochester Hills, MI: JMASM. ISBN 0-9740236-0-4.
Permutation tests
Original references:
- Fisher, R.A. (1935) The Design of Experiments, New York: Hafner
- Pitman, E. J. G. (1937) "Significance tests which may be applied to samples from any population", Royal Statistical Society Supplement, 4: 119-130 and 225-32 (parts I and II). JSTOR 2984124 JSTOR 2983647
- Pitman, E. J. G. (1938). "Significance tests which may be applied to samples from any population. Part III. The analysis of variance test". Biometrika 29 (3-4): 322–335. doi:10.1093/biomet/29.3-4.322.
Modern references:
- Collingridge, D.S. (2013). "A Primer on Quantitized Data Analysis and Permutation Testing". Journal of Mixed Methods Research 7 (1): 79–95. doi:10.1177/1558689812454457.
- Edgington. E.S. (1995) Randomization tests, 3rd ed. New York: Marcel-Dekker
- Good, Phillip I. (2005) Permutation, Parametric and Bootstrap Tests of Hypotheses, 3rd ed., Springer ISBN 0-387-98898-X
- Good, P (2002). "Extensions of the concept of exchangeability and their applications". J. Modern Appl. Statist. Methods 1: 243–247.
- Lunneborg, Cliff. (1999) Data Analysis by Resampling, Duxbury Press. ISBN 0-534-22110-6.
- Pesarin, F. (2001). Multivariate Permutation Tests : With Applications in Biostatistics, John Wiley & Sons. ISBN 978-0471496700
- Welch, W. J. (1990). "Construction of permutation tests". Journal of the American Statistical Association 85: 693–698. doi:10.1080/01621459.1990.10474929.
Computational methods:
- Mehta, C. R.; Patel, N. R. (1983). "A network algorithm for performing Fisher's exact test in r x c contingency tables". Journal of the American Statistical Association 78 (382): 427–434. doi:10.1080/01621459.1983.10477989.
- Metha, C. R.; Patel, N. R.; Senchaudhuri, P. (1988). "Importance sampling for estimating exact probabilities in permutational inference". Journal of the American Statistical Association 83 (404): 999–1005. doi:10.1080/01621459.1988.10478691.
- Gill, P. M. W. (2007). "Efficient calculation of p-values in linear-statistic permutation significance tests". Journal of Statistical Computation and Simulation 77 (1): 55–61. doi:10.1080/10629360500108053.
Resampling methods
- Good, P. (2006) Resampling Methods. 3rd Ed. Birkhauser.
- Wolter, K.M. (2007). Introduction to Variance Estimation. 2nd Edition. Springer, Inc.
- Pierre Del Moral (2004). Feynman-Kac formulae. Genealogical and Interacting particle systems with applications, Springer, Series Probability and Applications. ISBN 978-0-387-20268-6
- Pierre Del Moral (2013). Del Moral, Pierre (2013). Mean field simulation for Monte Carlo integration. Chapman & Hall/CRC Press, Monographs on Statistics and Applied Probability. ISBN 9781466504059
External links
Current research on permutation tests
- Good, P.I. (2012) Practitioner's Guide to Resampling Methods.
- Good, P.I. (2005) Permutation, Parametric, and Bootstrap Tests of Hypotheses
- Bootstrap Sampling tutorial
- Hesterberg, T. C., D. S. Moore, S. Monaghan, A. Clipson, and R. Epstein (2005): Bootstrap Methods and Permutation Tests, software.
- Moore, D. S., G. McCabe, W. Duckworth, and S. Sclove (2003): Bootstrap Methods and Permutation Tests
- Simon, J. L. (1997): Resampling: The New Statistics.
- Yu, Chong Ho (2003): Resampling methods: concepts, applications, and justification. Practical Assessment, Research & Evaluation, 8(19). (statistical bootstrapping)
- Resampling: A Marriage of Computers and Statistics (ERIC Digests)
Software
- Angelo Canty and Brian Ripley (2010). boot: Bootstrap R (S-Plus) Functions. R package version 1.2-43. Functions and datasets for bootstrapping from the book Bootstrap Methods and Their Applications by A. C. Davison and D. V. Hinkley (1997, CUP).
- Statistics101: Resampling, Bootstrap, Monte Carlo Simulation program
- R package `samplingVarEst': Sampling Variance Estimation. Implements functions for estimating the sampling variance of some point estimators.
- Paired randomization/permutation test for evaluation of TREC results
- Randomization/permutation tests to evaluate outcomes in information retrieval experiments (with and without adjustments for multiple comparisons).
- Bioconductor resampling-based multiple hypothesis testing with Applications to Genomics.
- permtest: an R package to compare the variability within and distance between two groups within a set of microarray data.