Uniform Resource Identifier
In information technology, a Uniform Resource Identifier (URI) is a string of characters used to identify a resource. Such identification enables interaction with representations of the resource over a network, typically the World Wide Web, using specific protocols. Schemes specifying a concrete syntax and associated protocols define each URI. The most common form of URI is the Uniform Resource Locator (URL), frequently referred to informally as a web address. More rarely seen in usage is the Uniform Resource Name (URN), which was designed to complement URLs by providing a mechanism for the identification of resources in particular namespaces.
Relationships among URIs, URLs, and URNs
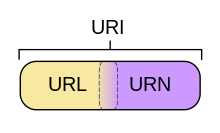
A Uniform Resource Name (URN) functions like a person's name, while a Uniform Resource Locator (URL) resembles that person's street address. In other words: the URN defines an item's identity, while the URL provides a method for finding it.
URLs
A URL is a URI that, in addition to identifying a web resource, specifies the means of acting upon or obtaining the representation of it, i.e. specifying both its primary access mechanism and network location. For example, the URL http://example.org/wiki/Main_Page refers to a resource identified as /wiki/Main_Page whose representation, in the form of HTML and related code, is obtainable via HyperText Transfer Protocol (http) from a network host whose domain name is example.org.
URNs
A URN is a URI that identifies a resource by name in a particular namespace. A URN can be used to talk about a resource without implying its location or how to access it.
The International Standard Book Number (ISBN) system for uniquely identifying books provides a typical example of the use of URNs. ISBN 0-486-27557-4 cites unambiguously a specific edition of Shakespeare's play Romeo and Juliet. The URN for that edition would be urn:isbn:0-486-27557-4. To gain access to this object and read the book, its location is needed, for which a URL would have to be specified.
Conceptual distinctions
Technical publications, especially standards produced by the IETF and by the W3C, normally reflect a view outlined in a W3C Recommendation of 2001, which acknowledges the precedence of the term URI rather than endorsing any formal subdivision into URL and URN.
URL is a useful but informal concept: a URL is a type of URI that identifies a resource via a representation of its primary access mechanism (e.g., its network "location"), rather than by some other attributes it may have.[1]
A URL is simply a URI that happens to point to a physical resource over a network.[lower-alpha 1]
However, in non-technical contexts and in software for the World Wide Web, the term URL remains widely used. Additionally, the term web address (which has no formal definition) often occurs in non-technical publications as a synonym for a URI that uses the 'http' or 'https' scheme. Such assumptions can lead to confusion, for example when viewing XML source: the normal means of identifying unique XML vocabularies within an XML document is to declare XML namespaces whose names are URIs that begin with 'http' and use the syntax of a genuine domain name followed by a file path, but which have no need to point to any specific file locations that actually exist.[3]
While most URI schemes were originally designed to be used with a particular protocol, and often have the same name (such as the http scheme, which is generally used for interacting with web resources using HyperText Transfer Protocol), they should not be referred to as protocols. Some URI schemes are not associated with any specific protocol (e.g. file) and many others do not use the name of a protocol as their prefix (e.g. news).
Syntax
The syntax of generic URIs and absolute URI references was first defined in Request for Comments (RFC) 2396, published in August 1998,[4] and finalized in RFC 3986, published in January 2005.[5] A generic URI is of the form:
scheme:[//[user:password@]host[:port]][/]path[?query][#fragment]
It is composed of the following components:
- The scheme consists of a sequence of characters beginning with a letter and followed by any combination of letters, digits, plus (
+), period (.), or hyphen (-). Although schemes are case-insensitive, the canonical form is lowercase and documents that specify schemes must do so with lowercase letters. It is followed by a colon (:). Examples of popular schemes includehttp,ftp,mailto,file, anddata. URI schemes should be registered with the Internet Assigned Numbers Authority (IANA), although non-registered schemes are used in practice.[lower-alpha 2] - Two slashes (
//): This is required by some schemes and not required by some others. When the authority component (explained below) is absent, the path component cannot begin with two slashes.[7] - An authority part, comprising:
- An optional authentication section of a user name and password, separated by a colon, followed by an at symbol (
@) - A "host", consisting of either a registered name (including but not limited to a hostname), or an IP address. IPv4 addresses must be in dot-decimal notation, and IPv6 addresses must be enclosed in brackets (
[ ]).[8] For URIs relating to resources on the World Wide Web, some web browsers allow ".0" portions of dot-decimal notation to be dropped and even raw integer IP addresses to be used.[9] - An optional port number, separated from the hostname by a colon
- An optional authentication section of a user name and password, separated by a colon, followed by an at symbol (
- A path, which contains data, usually organized in hierarchical form, that appears as a sequence of segments separated by slashes. Such a sequence may resemble or map exactly to a file system path, but does not always imply a relation to one.[4] The path must begin with a single slash (
/) if an authority part was present, and may also if one was not, but must not begin with a double slash.
| Query delimiter | Example |
|---|---|
Ampersand (&) |
key1=value1&key2=value2 |
Semicolon (;)[lower-alpha 3] |
key1=value1;key2=value2 |
- An optional query, separated from the preceding part by a question mark (
?), containing a query string of non-hierarchical data. Its syntax is not well defined, but by convention is most often a sequence of attribute–value pairs separated by a delimiter. - An optional fragment, separated from the preceding part by a hash (
#). The fragment contains a fragment identifier providing direction to a secondary resource, such as a section heading in an article identified by the remainder of the URI. When the primary resource is an HTML document, the fragment is often anidattribute of a specific element, and web browsers will scroll this element into view.
Strings of data octets within a URI are represented as characters. Permitted characters within a URI are the ASCII characters for the lowercase and uppercase letters of the modern English alphabet, and the Arabic numerals. Octets represented by any other character must be percent-encoded, as in %26 for an ampersand (&).[5]
Examples
The following figure displays two example URIs and their component parts.
hierarchical part
┌───────────────────┴─────────────────────┐
authority path
┌───────────────┴───────────────┐┌───┴────┐
abc://username:password@example.com:123/path/data?key=value#fragid1
└┬┘ └───────┬───────┘ └────┬────┘ └┬┘ └───┬───┘ └──┬──┘
scheme user information host port query fragment
urn:example:mammal:monotreme:echidna
└┬┘ └──────────────┬───────────────┘
scheme path
History
Naming, addressing, and identifying resources
URIs and URLs have a shared history. In 1994, Tim Berners-Lee’s proposals for hypertext[11] implicitly introduced the idea of a URL as a short string representing a resource that is the target of a hyperlink. At the time, people referred to it as a "hypertext name"[12] or "document name".
Over the next three and a half years, as the World Wide Web's core technologies of HTML (the HyperText Markup Language), HTTP, and web browsers developed, a need to distinguish a string that provided an address for a resource from a string that merely named a resource emerged. Although not yet formally defined, the term Uniform Resource Locator came to represent the former, and the more contentious Uniform Resource Name came to represent the latter.
During the debate over defining URLs and URNs it became evident that the two concepts embodied by the terms were merely aspects of the fundamental, overarching notion of resource identification. In June 1994, the IETF published Berners-Lee's RFC 1630: the first RFC that (in its non-normative text) acknowledged the existence of URLs and URNs, and, more importantly, defined a formal syntax for Universal Resource Identifiers — URL-like strings whose precise syntaxes and semantics depended on their schemes. In addition, this RFC attempted to summarize the syntaxes of URL schemes in use at the time. It also acknowledged, but did not standardize, the existence of relative URLs and fragment identifiers.
Refinement of specifications
In December 1994, RFC 1738 formally defined relative and absolute URLs, refined the general URL syntax, defined how to resolve relative URLs to absolute form, and better enumerated the URL schemes then in use. The agreed definition and syntax of URNs had to wait until the publication of RFC 2141 in May 1997.
The publication of RFC 2396 in August 1998 saw the URI syntax become a separate specification[4] and most of the parts of RFCs 1630 and 1738 relating to URIs and URLs in general were revised and expanded by the IETF. The new RFC changed the significance of the "U" in "URI": it came to represent "Uniform" rather than "Universal".
In December 1999, RFC 2732 provided a minor update to RFC 2396, allowing URIs to accommodate IPv6 addresses. Some time later, a number of shortcomings discovered in the two specifications led to the development of a number of draft revisions under the title rfc2396bis. This community effort, coordinated by RFC 2396 co-author Roy Fielding, culminated in the publication of RFC 3986 in January 2005. This RFC, as of 2009 the current version of the URI syntax recommended for use on the Internet, renders RFC 2396 obsolete. It does not, however, render the details of existing URL schemes obsolete; RFC 1738 continues to govern such schemes except where otherwise superseded – RFC 2616 for example, refines the "http" scheme. Simultaneously, the IETF published the content of RFC 3986 as the full standard STD 66, reflecting the establishment of the URI generic syntax as an official Internet protocol.
In August 2002, RFC 3305 pointed out that the term "URL" has, despite its widespread use in the vernacular of the Internet-aware public at large, faded into near obsolescence. It now serves only as a reminder that some URIs act as addresses because they have schemes that imply some kind of network accessibility, regardless of whether systems actually use them for that purpose. As URI-based standards such as Resource Description Framework make evident, resource identification need not suggest the retrieval of resource representations over the Internet, nor need they imply network-based resources at all.
In 2001, the W3C's Technical Architecture Group (TAG) published a guide to best practices and canonical URIs for publishing multiple versions of a given resource.[13] For example, content might differ by language or by size to adjust for capacity or settings of the device used to access that content.
The Semantic Web uses the HTTP URI scheme to identify both documents and concepts in the real world, a distinction which has caused confusion as to how to distinguish the two. The TAG published an e-mail in 2005 on how to solve the problem, which became known as the httpRange-14 resolution.[14] The W3C subsequently published an Interest Group Note titled Cool URIs for the Semantic Web,[15] which explained the use of content negotiation and the HTTP 303 response code for redirections in more detail.
URI reference
A URI reference may take the form of a full URI, or just the scheme-specific portion of one, or even some trailing component thereof – even the empty string. An optional fragment identifier, preceded by #, may be present at the end of a URI reference. The part of the reference before the # indirectly identifies a resource, and the fragment identifier identifies some portion of that resource.
To derive a URI from a URI reference, software converts the URI reference to 'absolute' form by merging it with an absolute 'base' URI according to a fixed algorithm. The system treats the URI reference as relative to the base URI, although in the case of an absolute reference, the base has no relevance. The base URI typically identifies the document containing the URI reference, although this can be overridden by declarations made within the document or as part of an external data transmission protocol. If the base URI includes a fragment identifier, it is ignored during the merging process. If a fragment identifier is present in the URI reference, it is preserved during the merging process.
Web document markup languages frequently use URI references to point to other resources, such as external documents or specific portions of the same logical document.
Uses of URI references in markup languages
- In HTML, the value of the
srcattribute of theimgelement provides a URI reference, as does the value of thehrefattribute of theaorlinkelement. - In XML, the system identifier appearing after the
SYSTEMkeyword in a DTD is a fragmentless URI reference. - In XSLT, the value of the
hrefattribute of thexsl:importelement/instruction is a URI reference; likewise the first argument to thedocument()function.
Examples of absolute URIs
- https://example.org/absolute/URI/with/absolute/path/to/resource.txt
- ftp://example.org/resource.txt
- urn:ISSN:1535-3613
Examples of URI references
- https://example.org/absolute/URI/with/absolute/path/to/resource.txt
- //example.org/scheme-relative/URI/with/absolute/path/to/resource.txt
- /relative/URI/with/absolute/path/to/resource.txt
- relative/path/to/resource.txt
- ../../../resource.txt
- ./resource.txt#frag01
- resource.txt
- #frag01
URI resolution
To resolve a URI means either to convert a relative URI reference to absolute form, or to dereference a URI or URI reference by attempting to obtain a representation of the resource that it identifies. The 'resolver' component in document processing software generally provides both services.
One can regard a URI reference as a same document reference: a reference to the document containing the URI reference itself. Document processing software can efficiently use its current representation of the document to satisfy the resolution of a same document reference without fetching a new representation. This is only a recommendation, and document processing software can alternatively use other mechanisms to determine whether to obtain a new representation.
The current URI specification as of 2009, RFC 3986, defines a URI reference as a same document reference if, when resolved to absolute form, it equates exactly to the base URI in effect for the reference. Typically, the base URI is the URI of the document containing the reference. XSLT 1.0, for example, has a document() function that, in effect, implements this functionality. RFC 3986 also formally defines URI equivalence, which can be used to determine that a URI reference, while not identical to the base URI, still represents the same resource and thus can be considered to be a same document reference.
RFC 2396 prescribed a different method for determining same document references; RFC 3986 made RFC 2396 obsolete, but RFC 2396 still serves as the basis of many specifications and implementations. This specification defines a URI reference as a same document reference if it is an empty string or consists of only the # character followed by an optional fragment.
Relation to XML namespaces
XML has a concept of a namespace, an abstract domain to which a collection of element and attribute names can be assigned. The namespace name (a character string which must adhere to the generic URI syntax) identifies an XML namespace. However, the namespace name is generally not considered[16] to be a URI, because the "URI-ness" of strings is, according to the URI specification, based on their intended use, not just their lexical components. A namespace name also does not necessarily imply any of the semantics of URI schemes; a namespace name beginning with 'http:', for example, may have nothing to do with the HTTP protocol.
Initially, the namespace name could match the syntax of any non-empty URI reference, but the use of relative URI references was later deprecated by the W3C.[17] A separate W3C specification for namespaces in XML 1.1 permits internationalized resource identifier (IRI) references to serve as the basis for namespace names in addition to URI references.[18]
See also
- CURIE (Compact URI)
- Dereferenceable Uniform Resource Identifier
- Extensible Resource Identifier (XRI)
- History of the Internet
- Namespace (programming)
- Percent-encoding
- Persistent Uniform Resource Locator (PURL)
- Resource Directory Description Language (RDDL), a descriptive language to provide machine- and human-readable information about a particular namespace and about the XML documents that use it
- Uniform Naming Convention (UNC)
Notes
- ↑ A report published in 2002 by a joint W3C/IETF working group aimed to normalize the divergent views held within the IETF and W3C over the relationship between the various 'UR*' terms and standards. While not published as a full standard by either organization, it has become the basis for the above common understanding and has informed many standards since then.[2]
- ↑ The procedures for registering new URI schemes were originally defined in 1999 by RFC 2717, and are now defined by RFC 7595, published in June 2015.[6]
- ↑ RFC 1866 encourages CGI authors to support ';' in addition to '&'.[10]
Citations
- ↑ Joint W3C/IETF URI Planning Interest Group (2001).
- ↑ Joint W3C/IETF URI Planning Interest Group (2002).
- ↑ Morrison (2006).
- 1 2 3 RFC 2396 (1998).
- 1 2 RFC 3986 (2005).
- ↑ IETF (2015).
- ↑ RFC 3986 (2005), pp. 6,15.
- ↑ RFC 3986 (2005), pp. 18—21.
- ↑ Lawrence, Eric (6 March 2014). "Browser Arcana: IP Literals in URLs". IEInternals. Microsoft.
- ↑ RFC 1866 (1995).
- ↑ Palmer (2001).
- ↑ W3C (1992).
- ↑ W3C (2001).
- ↑ Fielding (2005).
- ↑ W3C (2008).
- ↑ Harold (2004).
- ↑ W3C (2009).
- ↑ W3C (2006).
References
- Fielding, Roy T. (18 June 2005). "[httpRange-14] Resolved". Retrieved 24 July 2009.
- Harold, Elliotte Rusty (2004). XML 1.1 Bible (Third ed.). Wiley Publishing. p. 291. ISBN 0764549863.
- Joint W3C/IETF URI Planning Interest Group (21 September 2001). "URIs, URLs, and URNs: Clarifications and Recommendations 1.0". Retrieved 2009-07-27.
- Mealling, M.; Denenberg, R., eds. (August 2002). "Report from the Joint W3C/IETF URI Planning Interest Group: Uniform Resource Identifiers (URIs), URLs, and Uniform Resource Names (URNs): Clarifications and Recommendations". World Wide Web Consortium. Retrieved 13 September 2015.
- Hansen, T.; Hardie, T. (June 2015). Thaler, D., ed. "Guidelines and Registration Procedures for URI Schemes". Internet Engineering Task Force. ISSN 2070-1721.
- Morrison, Michael (2006). "Hour 5: Putting Namespaces to Use". Sams Teach Yourself XML. Sams Publishing. p. 91.
- Palmer, Sean B. (2001). "The Early History of HTML". Retrieved 2009-04-30.
- URI Planning Interest Group, W3C/IETF (21 September 2001). "URIs, URLs, and URNs: Clarifications and Recommendations 1.0". Retrieved 2009-07-27.
- "W3 Naming Schemes". World Wide Web Consortium. 1992. Retrieved 2009-07-24.
- "On Linking Alternative Representations To Enable Discovery And Publishing". World Wide Web Consortium. 2006 [2001]. Retrieved 2012-04-03.
- Bray, Tim; Hollander, Dave; Layman, Andrew; Tobin, Richard, eds. (16 August 2006). "Namespaces in XML 1.1 (Second Edition)". World Wide Web Consortium. 2.2 Use of URIs as Namespace Names. Retrieved 31 August 2015.
- Ayers, Danny; Völkel, Max (3 December 2008). Sauermann, Leo; Cyganiak, Richard, eds. "Cool URIs for the Semantic Web". World Wide Web Consortium. Retrieved 2012-04-03.
- Bray, Tim; Hollander, Dave; Layman, Andrew; Tobin, Richard; Thompson, Henry S., eds. (8 December 2009). "Namespaces in XML 1.0 (Third Edition)". World Wide Web Consortium. 2.2 Use of URIs as Namespace Names. Retrieved 31 August 2015.
- Berners-Lee, Tim; Connolly, Dan (November 1995). "Hypertext Markup Language - 2.0". Internet Engineering Task Force. Retrieved 13 September 2015.
- Berners-Lee, Tim; Fielding, Roy; Masinter, Larry (August 1998). "Uniform Resource Identifiers (URI): Generic Syntax". Internet Engineering Task Force. Retrieved 31 August 2015.
- Berners-Lee, Tim; Fielding, Roy; Masinter, Larry (January 2005). "Uniform Resource Identifiers (URI): Generic Syntax". Internet Engineering Task Force. Retrieved 31 August 2015.
External links
- URI Schemes – IANA-maintained registry of URI Schemes
- URI schemes on the W3C wiki
- Architecture of the World Wide Web, Volume One, §2: Identification – by W3C
- W3C URI Clarification
| ||||||||||||||||||||||||||||||||||||
| ||||||||||||||
|