Partially observable Markov decision process
A partially observable Markov decision process (POMDP) is a generalization of a Markov decision process (MDP). A POMDP models an agent decision process in which it is assumed that the system dynamics are determined by an MDP, but the agent cannot directly observe the underlying state. Instead, it must maintain a probability distribution over the set of possible states, based on a set of observations and observation probabilities, and the underlying MDP.
The POMDP framework is general enough to model a variety of real-world sequential decision processes. Applications include robot navigation problems, machine maintenance, and planning under uncertainty in general. The framework originated in the operations research community, and was later taken over by the artificial intelligence and automated planning communities.
An exact solution to a POMDP yields the optimal action for each possible belief over the world states. The optimal action maximizes (or minimizes) the expected reward (or cost) of the agent over a possibly infinite horizon. The sequence of optimal actions is known as the optimal policy of the agent for interacting with its environment.
Definition
Formal definition
A discrete-time POMDP models the relationship between an agent and its environment. Formally, a POMDP is a 7-tuple 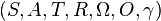 , where
, where
-
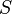 is a set of states,
is a set of states, -
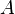 is a set of actions,
is a set of actions, -
 is a set of conditional transition probabilities between states,
is a set of conditional transition probabilities between states, -
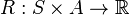 is the reward function.
is the reward function. -
 is a set of observations,
is a set of observations, -
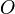 is a set of conditional observation probabilities, and
is a set of conditional observation probabilities, and -
![\gamma \in [0, 1]](../I/m/ee133ef1a28ae6f8bcf231e9dca9c222.png) is the discount factor.
is the discount factor.
At each time period, the environment is in some state 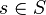 . The agent takes an action
. The agent takes an action  ,
which causes the environment to transition to state
,
which causes the environment to transition to state 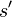 with probability
with probability 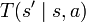 . At the same time, the agent receives an observation
. At the same time, the agent receives an observation 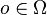 which depends on the new state of the environment with probability
which depends on the new state of the environment with probability 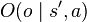 . Finally, the agent receives a reward equal to
. Finally, the agent receives a reward equal to 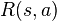 . Then the process repeats. The goal is for the agent to choose actions at each time step that maximize its expected future discounted reward:
. Then the process repeats. The goal is for the agent to choose actions at each time step that maximize its expected future discounted reward: ![E \left[ \sum_{t=0}^\infty \gamma^t r_t \right]](../I/m/9303d4187e36fa805d0e15512e9de159.png) . The discount factor
. The discount factor 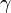 determines how much immediate rewards are favored over more distant rewards. When
determines how much immediate rewards are favored over more distant rewards. When 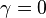 the agent only cares about which action will yield the largest expected immediate reward; when
the agent only cares about which action will yield the largest expected immediate reward; when 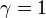 the agent cares about maximizing the expected sum of future rewards.
the agent cares about maximizing the expected sum of future rewards.
Discussion
Because the agent does not directly observe the environment's state, the agent must make decisions under uncertainty of the true environment state. However, by interacting with the environment and receiving observations, the agent may update its belief in the true state by updating the probability distribution of the current state. A consequence of this property is that the optimal behavior may often include information gathering actions that are taken purely because they improve the agent's estimate of the current state, thereby allowing it to make better decisions in the future.
It is instructive to compare the above definition with the definition of a Markov decision process. An MDP does not include the observation set, because the agent always knows with certainty the environment's current state. Alternatively, an MDP can be reformulated as a POMDP by setting the observation set to be equal to the set of states and defining the observation conditional probabilities to deterministically select the observation that corresponds to the true state.
Belief update
An agent needs to update its belief upon taking the action  and observing
and observing  . Since the state is Markovian, maintaining a belief over the states solely requires knowledge of the previous belief state, the action taken, and the current observation. The operation is denoted
. Since the state is Markovian, maintaining a belief over the states solely requires knowledge of the previous belief state, the action taken, and the current observation. The operation is denoted 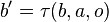 . Below we describe how this belief update is computed.
. Below we describe how this belief update is computed.
After reaching , the agent observes with probability . Let 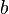 be a probability distribution over the state space .
be a probability distribution over the state space . 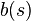 denotes the probability that the environment is in state
denotes the probability that the environment is in state  . Given , then after taking action and observing ,
. Given , then after taking action and observing ,
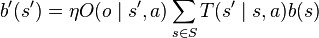
where 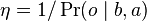 is a normalizing constant with
is a normalizing constant with 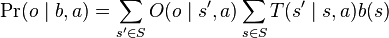 .
.
Belief MDP
A Markovian belief state allows a POMDP to be formulated as a Markov decision process where every belief is a state. The resulting belief MDP will thus be defined on a continuous state space, since there are infinite beliefs for any given POMDP.[1] In other words, there are technically infinite belief states (in 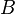 ) because there are an infinite number of mixtures of () the originating states.
) because there are an infinite number of mixtures of () the originating states.
Formally, the belief MDP is defined as a tuple 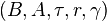 where
where
- is the set of belief states over the POMDP states,
- is the same finite set of action as for the original POMDP,
-
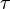 is the belief state transition function,
is the belief state transition function, -
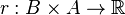 is the reward function on belief states,
is the reward function on belief states, - is the discount factor equal to the in the original POMDP.
Of these, and  need to be derived from the original POMDP. is
need to be derived from the original POMDP. is
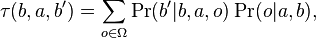
where 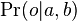 is the value derived in the previous section and
is the value derived in the previous section and

The belief MDP reward function () is the expected reward from the POMDP reward function over the belief state distribution:
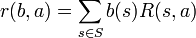 .
.
The belief MDP is not partially observable anymore, since at any given time the agent knows its belief, and by extension the state of the belief MDP.
Also, unlike the "originating" MDP, where each action is available from only one state; in the corresponding Belief MDP, all belief states allow all actions, since you (almost) always have some probability of believing you are in any (originating) state.
Policy and Value Function
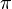 specifies an action
specifies an action 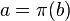 for any belief . Here it is assumed the objective is to maximize the expected total discounted reward over an infinite horizon. When
for any belief . Here it is assumed the objective is to maximize the expected total discounted reward over an infinite horizon. When 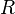 defines a cost, the objective becomes the minimization of the expected cost.
defines a cost, the objective becomes the minimization of the expected cost.
The expected reward for policy starting from belief  is defined as
is defined as
![V^\pi(b_0) = \sum_{t=0}^\infty \gamma^t r(b_t, a_t) = \sum_{t=0}^\infty \gamma^t E\Bigl[ R(s_t,a_t) \mid b_0, \pi \Bigr]](../I/m/bdb88d7fbce5c895d7ccdb9057c99542.png)
where  is the discount factor. The optimal policy
is the discount factor. The optimal policy 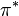 is obtained by optimizing the long-term reward.
is obtained by optimizing the long-term reward.
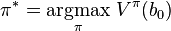
where is the initial belief.
The optimal policy, denoted by , yields the highest expected reward value for each belief state, compactly represented by the optimal value function  . This value function is solution to the Bellman optimality equation:
. This value function is solution to the Bellman optimality equation:
![V^*(b) = \max_{a\in A}\Bigl[ r(b,a) + \gamma\sum_{o\in \Omega} O(o\mid b,a) V^*(\tau(b,a,o)) \Bigr]](../I/m/322e403e99e262b09bbbff5eb4da692e.png)
For finite-horizon POMDPs, the optimal value function is piecewise-linear and convex.[2] It can be represented as a finite set of vectors. In the infinite-horizon formulation, a finite vector set can approximate arbitrarily closely, whose shape remains convex. Value iteration applies dynamic programming update to gradually improve on the value until convergence to an  -optimal value function, and preserves its piecewise linearity and convexity.[3] By improving the value, the policy is implicitly improved. Another dynamic programming technique called policy iteration explicitly represents and improves the policy instead.[4][5]
-optimal value function, and preserves its piecewise linearity and convexity.[3] By improving the value, the policy is implicitly improved. Another dynamic programming technique called policy iteration explicitly represents and improves the policy instead.[4][5]
Approximate POMDP solutions
In practice, POMDPs are often computationally intractable to solve exactly, so computer scientists have developed methods that approximate solutions for POMDPs.[6]
Grid-based algorithms [7] comprise one approximate solution technique. In this approach, the value function is computed for a set of points in the belief space, and interpolation is used to determine the optimal action to take for other belief states that are encountered which are not in the set of grid points. More recent work makes use of sampling techniques, generalization techniques and exploitation of problem structure, and has extended POMDP solving into large domains with millions of states [8][9] For example, point-based methods sample random reachable belief points to constrain the planning to relevant areas in the belief space.[10] Dimensionality reduction using PCA has also been explored.[11]
POMDP uses
POMDPs model many kinds of real-world problems. Notable works include the use of a POMDP in management of patients with ischemic heart disease,[12] assistive technology for persons with dementia,[8][9] the conservation of the critically endangered and difficult to detect Sumatran tigers [13] and aircraft collision avoidance.[14]
References
- ↑ Kaelbling, L.P., Littman, M.L., Cassandra, A.R. (1998). "Planning and acting in partially observable stochastic domains". Artificial Intelligence Journal 101: 99–134. doi:10.1016/S0004-3702(98)00023-X.
- ↑ Sondik, E.J. (1971). The optimal control of partially observable Markov processes (PhD thesis). Stanford University.
- ↑ Smallwood, R.D., Sondik, E.J. (1973). "The optimal control of partially observable Markov decision processes over a finite horizon". Operations Research 21 (5): 1071–88. doi:10.1287/opre.21.5.1071.
- ↑ Sondik, E.J. (1978). "The optimal control of partially observable Markov processes over the infinite horizon: discounted cost". Operations Research 26 (2): 282–304. doi:10.1287/opre.26.2.282.
- ↑ Hansen, E. (1998). "Solving POMDPs by searching in policy space". Proceedings of the Fourteenth International Conference on Uncertainty In Artificial Intelligence (UAI-98).
- ↑ Hauskrecht, M. (2000). "Value function approximations for partially observable Markov decision processes". Journal of Artificial Intelligence Research 13: 33–94. doi:10.1613/jair.678.
- ↑ Lovejoy, W. (1991). "Computationally feasible bounds for partially observed Markov decision processes". Operations Research 39: 162–175. doi:10.1287/opre.39.1.162.
- 1 2 Jesse Hoey, Axel von Bertoldi, Pascal Poupart, Alex Mihailidis (2007). "Assisting Persons with Dementia during Handwashing Using a Partially Observable Markov Decision Process". Proc. International Conference on Computer Vision Systems (ICVS). doi:10.2390/biecoll-icvs2007-89.
- 1 2 Jesse Hoey, Pascal Poupart, Axel von Bertoldi, Tammy Craig, Craig Boutilier, Alex Mihailidis. (2010). "Automated Handwashing Assistance For Persons With Dementia Using Video and a Partially Observable Markov Decision Process". Computer Vision and Image Understanding (CVIU) 114 (5). doi:10.1016/j.cviu.2009.06.008.
- ↑ Pineau, J., Gordon, G., Thrun, S. (August 2003). "Point-based value iteration: An anytime algorithm for POMDPs". International Joint Conference on Artificial Intelligence (IJCAI). Acapulco, Mexico. pp. 1025–32.
- ↑ Roy, Nicholas; Gordon, Geoffrey (2003). "Exponential Family PCA for Belief Compression in POMDPs". Advances in Neural Information Processing Systems.
- ↑ Hauskrecht, M. , Fraser, H. (2000). "Planning treatment of ischemic heart disease with partially observable Markov decision processes". Artificial Intelligence in Medicine 18 (3): 221–244. doi:10.1016/S0933-3657(99)00042-1.
- ↑ Chadès, I., McDonald-Madden, E., McCarthy, M.A., Wintle, B., Linkie, M., Possingham, H.P. (16 September 2008). "When to stop managing or surveying cryptic threatened species". Proc. Natl. Acad. Sci. U.S.A. 105 (37): 13936–40. Bibcode:2008PNAS..10513936C. doi:10.1073/pnas.0805265105. PMC 2544557. PMID 18779594.
- ↑ Kochenderfer, Mykel J. (2015). "Optimized Airborne Collision Avoidance". Decision Making Under Uncertainty. The MIT Press.
External links
- Tony Cassandra's POMDP pages with a tutorial, examples of problems modeled as POMDPs, and software for solving them.
- zmdp, a POMDP solver by Trey Smith
- APPL, a fast point-based POMDP solver
- SPUDD, a factored structured (PO)MDP solver that uses algebraic decision diagrams (ADDs).
- pyPOMDP, a (PO)MDP toolbox (simulator, solver, learner, file reader) for Python by Oliver Stollmann and Bastian Migge
- Finite-state Controllers using Branch-and-Bound An Exact POMDP Solver for Policies of a Bounded Size