Panel analysis
Panel (data) analysis is a statistical method, widely used in social science, epidemiology, and econometrics, which deals with two and "n"-dimensional (in and by the - cross sectional/times series time) panel data.[1] The data are usually collected over time and over the same individuals and then a regression is run over these two dimensions. Multidimensional analysis is an econometric method in which data are collected over more than two dimensions (typically, time, individuals, and some third dimension).[2]
A common panel data regression model looks like 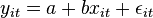 , where y is the dependent variable, x is the independent variable, a and b are coefficients, i and t are indices for individuals and time. The error
, where y is the dependent variable, x is the independent variable, a and b are coefficients, i and t are indices for individuals and time. The error 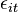 is very important in this analysis. Assumptions about the error term determine whether we speak of fixed effects or random effects. In a fixed effects model, is assumed to vary non-stochastically over
is very important in this analysis. Assumptions about the error term determine whether we speak of fixed effects or random effects. In a fixed effects model, is assumed to vary non-stochastically over  or
or  making the fixed effects model analogous to a dummy variable model in one dimension. In a random effects model, is assumed to vary stochastically over or requiring special treatment of the error variance matrix.[3]
making the fixed effects model analogous to a dummy variable model in one dimension. In a random effects model, is assumed to vary stochastically over or requiring special treatment of the error variance matrix.[3]
Panel data analysis has three more-or-less independent approaches:
- independently pooled panels;
- random effects models;
- fixed effects models or first differenced models.
The selection between these methods depends upon the objective of our analysis, and the problems concerning the exogeneity of the explanatory variables.
Independently pooled panels
Key Assumption: There are no unique attributes of individuals within the measurement set, and no universal effects across time.
Fixed effect models
Key Assumption: There are unique attributes of individuals that are not the results of random variation and that do not vary across time. Adequate if we want to draw inferences only about the examined individuals. Also known as "Least Squares Dummy Variable Model" (LSDVM)
Random effect models
Key Assumption: There are unique, time constant attributes of individuals that are the results of random variation and do not correlate with the individual regressors. This model is adequate if we want to draw inferences about the whole population, not only the examined sample.
See also
References
- ↑ Maddala, G. S. (2001). Introduction to Econometrics (Third ed.). New York: Wiley. ISBN 0-471-49728-2.
- ↑ Davies, A.; Lahiri, K. (1995). "A New Framework for Testing Rationality and Measuring Aggregate Shocks Using Panel Data". Journal of Econometrics 68 (1): 205–227. doi:10.1016/0304-4076(94)01649-K.
- ↑ Hsiao, C.; Lahiri, K.; Lee, L.; et al., eds. (1999). Analysis of Panels and Limited Dependent Variable Models. Cambridge: Cambridge University Press. ISBN 0-521-63169-6.