Ordered logit
| Part of a series on Statistics |
| Regression analysis |
|---|
 |
| Models |
| Estimation |
| Background |
|
In statistics, the ordered logit model (also ordered logistic regression or proportional odds model), is a regression model for ordinal dependent variables. For example, if one question on a survey is to be answered by a choice among "poor", "fair", "good", "very good", and "excellent", and the purpose of the analysis is to see how well that response can be predicted by the responses to other questions, some of which may be quantitative, then ordered logistic regression may be used. It can be thought of as an extension of the logistic regression model that applies to dichotomous dependent variables, allowing for more than two (ordered) response categories.
The model and the proportional odds assumption
The model only applies to data that meet the proportional odds assumption, the meaning of which can be exemplified as follows. Suppose the proportions of members of the statistical population who would answer "poor", "fair", "good", "very good", and "excellent" are respectively p1, p2, p3, p4, p5. Then the logarithms of the odds (not the logarithms of the probabilities) of answering in certain ways are:
![\begin{array}{rll}
\text{poor}, & \log\frac{p_1}{p_2+p_3+p_4+p_5}, & 0 \\[8pt]
\text{poor or fair}, & \log\frac{p_1+p_2}{p_3+p_4+p_5}, & 1 \\[8pt]
\text{poor, fair, or good}, & \log\frac{p_1+p_2+p_3}{p_4+p_5}, & 2 \\[8pt]
\text{poor, fair, good, or very good}, & \log\frac{p_1+p_2+p_3+p_4}{p_5}, & 3
\end{array}](../I/m/10738c53432bf367e0dd28f5cb0a14cd.png)
The proportional odds assumption is that the number added to each of these logarithms to get the next is the same in every case. In other words, these logarithms form an arithmetic sequence.[1] The model states that the number in the last column of the table – the number of times that that logarithm must be added – is some linear combination of the other observed variables.
The coefficients in the linear combination cannot be consistently estimated using ordinary least squares. They are usually estimated using maximum likelihood. The maximum-likelihood estimates are computed by using iteratively reweighted least squares.
Examples of multiple ordered response categories include bond ratings, opinion surveys with responses ranging from "strongly agree" to "strongly disagree," levels of state spending on government programs (high, medium, or low), the level of insurance coverage chosen (none, partial, or full), and employment status (not employed, employed part-time, or fully employed).[2]
Suppose the underlying process to be characterized is

where 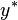 is the exact but unobserved dependent variable (perhaps the exact level of agreement with the statement proposed by the pollster);
is the exact but unobserved dependent variable (perhaps the exact level of agreement with the statement proposed by the pollster);  is the vector of independent variables, and
is the vector of independent variables, and 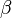 is the vector of regression coefficients which we wish to estimate. Further suppose that while we cannot observe , we instead can only observe the categories of response
is the vector of regression coefficients which we wish to estimate. Further suppose that while we cannot observe , we instead can only observe the categories of response
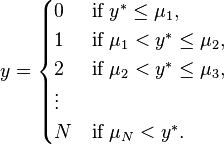
Then the ordered logit technique will use the observations on y, which are a form of censored data on y*, to fit the parameter vector .
See also
References
- ↑ http://www.ats.ucla.edu/stat/r/dae/ologit.htm
- ↑ Greene, William H. (2012). Econometric Analysis (Seventh ed.). Boston: Pearson Education. pp. 824–827. ISBN 978-0-273-75356-8.
Further reading
- Steve Simon (2004-09-22). "Sample size for an ordinal outcome". STATS − STeve's Attempt to Teach Statistics. Retrieved 2014-08-22.
- Woodward, Mark (2005). Epidemiology: Study Design and Data Analysis (2nd ed.). Chapman & Hall/CRC. ISBN 978-1-58488-415-6.
- Hardin, James; Hilbe, Joseph (2007). Generalized Linear Models and Extensions (2nd ed.). College Station: Stata Press. ISBN 978-1-59718-014-6.