OpenCL
|
| |
| Original author(s) | Apple Inc. |
|---|---|
| Developer(s) | Khronos Group |
| Initial release | August 28, 2009 |
| Stable release | 2.1 revision 23[1] / November 11, 2015 |
| Development status | Active |
| Written in | C/C++ |
| Operating system | Android (vendor dependent),[2] FreeBSD,[3] Linux, OS X, Windows |
| Platform | ARMv7, ARMv8,[4] Cell, PowerPC, x86, x86-64 |
| Type | Heterogeneous computing API |
| License | OpenCL specification license |
| Website |
www |
| As of | 25 December 2015 |
| Paradigm | Imperative (procedural), structured, object-oriented (C++ only) |
|---|---|
| Family | C |
| Stable release | OpenCL C 2.0 revision 30[5] / September 9, 2015 |
| Preview release | OpenCL C++ 1.0 provisional specification revision 8[6] / March 2, 2015 |
| Typing discipline | Static, weak, manifest, nominal |
| Implementation language | Implementation specific |
| Filename extensions | .cl |
| Website |
www |
| Major implementations | |
| AMD, Apple, freeocl, Gallium Compute, IBM, Intel Beignet, Intel SDK, Nvidia, pocl | |
| Influenced by | |
| C99, CUDA, C++14 | |
Open Computing Language (OpenCL) is a framework for writing programs that execute across heterogeneous platforms consisting of central processing units (CPUs), graphics processing units (GPUs), digital signal processors (DSPs), field-programmable gate arrays (FPGAs) and other processors or hardware accelerators. OpenCL specifies a programming language (based on C99) for programming these devices and application programming interfaces (APIs) to control the platform and execute programs on the compute devices. OpenCL provides a standard interface for parallel computing using task-based and data-based parallelism.
OpenCL is an open standard maintained by the non-profit technology consortium Khronos Group. Conformant implementations are available from Altera, AMD, Apple, ARM Holdings, Creative Technology, IBM, Imagination Technologies, Intel, Nvidia, Qualcomm, Samsung, Vivante, Xilinx, and ZiiLABS.[7][8]
Overview
OpenCL views a computing system as consisting of a number of compute devices, which might be central processing units (CPUs) or "accelerators" such as graphics processing units (GPUs), attached to a host processor (a CPU). It defines a C-like language for writing programs. Functions executed on an OpenCL device are called kernels.[1]:17 A single compute device typically consists of several compute units, which in turn comprise multiple processing elements (PEs). A single kernel execution can run on all or many of the PEs in parallel. How a compute device is subdivided into compute units and PEs is up to the vendor; a compute unit can be thought of as a "core", but the notion of core is hard to define across all the types of devices supported by OpenCL (or even within the category of "CPUs"),[9]:49–50 and the number of compute units may not correspond to the number of cores claimed in vendors' marketing literature (which may actually be counting SIMD lanes).[10]
In addition to its C-like programming language, OpenCL defines an application programming interface (API) that allows programs running on the host to launch kernels on the compute devices and manage device memory, which is (at least conceptually) separate from host memory. Programs in the OpenCL language are intended to be compiled at run-time, so that OpenCL-using applications are portable between implementations for various host devices.[11] The OpenCL standard defines host APIs for C and C++; third-party APIs exist for other programming languages and platforms such as Python,[12] Java and .NET.[9]:15 An implementation of the OpenCL standard consists of a library that implements the API for C and C++, and an OpenCL C compiler for the compute device(s) targeted.
Memory hierarchy
OpenCL defines a four-level memory hierarchy for the compute device:[11]
- global memory: shared by all processing elements, but has high access latency;
- read-only memory: smaller, low latency, writable by the host CPU but not the compute devices;
- local memory: shared by a group of processing elements;
- per-element private memory (registers).
Not every device needs to implement each level of this hierarchy in hardware. Consistency between the various levels in the hierarchy is relaxed, and only enforced by explicit synchronization constructs, notably barriers.
Devices may or may not share memory with the host CPU.[11] The host API provides handles on device memory buffers and functions to transfer data back and forth between host and devices.
OpenCL C language
The programming language used to write computation kernels is called OpenCL C and is based on C99,[13] but adapted to fit the device model in OpenCL. Memory buffers reside in specific levels of the memory hierarchy, and pointers are annotated with the region qualifiers __global, __local, __constant, and __private, reflecting this. Instead of a device program having a main function, OpenCL C functions are marked __kernel to signal that they are entry points into the program to be called from the host program. Function pointers, bit fields and variable-length arrays are omitted, recursion is forbidden.[14] The C standard library is replaced by a custom set of standard functions, geared toward math programming.
OpenCL C is extended to facilitate use of parallelism with vector types and operations, synchronization, and functions to work with work-items and work-groups.[14] In particular, besides scalar types such as float and double, which behave similarly to the corresponding types in C, OpenCL provides fixed-length vector types such as float4 (4-vector of single-precision floats); such vector types are available in lengths two, three, four, eight and sixteen for various base types.[13]:§6.1.2 Vectorized operations on these types are intended to map onto SIMD instructions sets, e.g., SSE or VMX when running OpenCL programs on CPUs.[11] Other specialized types include 2-d and 3-d image types.[13]:10–11
Example: matrix-vector multiplication
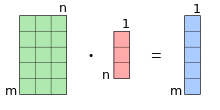
The following is a matrix-vector multiplication algorithm in OpenCL C.
// Multiplies A*x, leaving the result in y.
// A is a row-major matrix, meaning the (i,j) element is at A[i*ncols+j].
__kernel void matvec(__global const float *A, __global const float *x,
uint ncols, __global float *y)
{
size_t i = get_global_id(0); // Global id, used as the row index.
__global float const *a = &A[i*ncols]; // Pointer to the i'th row.
float sum = 0.f; // Accumulator for dot product.
for (size_t j = 0; j < ncols; j++) {
sum += a[j] * x[j];
}
y[i] = sum;
}
The kernel function matvec computes, in each invocation, the dot product of a single row of a matrix A and a vector x:
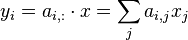 .
.
To extend this into a full matrix-vector multiplication, the OpenCL runtime maps the kernel over the rows of the matrix. On the host side, the clEnqueueNDRangeKernel function does this; it takes as arguments the kernel to execute, its arguments, and a number of work-items, corresponding to the number of rows in the matrix A.
Example: computing the FFT
This example will load a fast Fourier transform (FFT) implementation and execute it. The implementation is shown below.[15]
// create a compute context with GPU device
context = clCreateContextFromType(NULL, CL_DEVICE_TYPE_GPU, NULL, NULL, NULL);
// create a command queue
clGetDeviceIDs( NULL, CL_DEVICE_TYPE_DEFAULT, 1, &device_id, NULL );
queue = clCreateCommandQueue(context, device_id, 0, NULL);
// allocate the buffer memory objects
memobjs[0] = clCreateBuffer(context, CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR, sizeof(float)*2*num_entries, srcA, NULL);
memobjs[1] = clCreateBuffer(context, CL_MEM_READ_WRITE, sizeof(float)*2*num_entries, NULL, NULL);
// create the compute program
program = clCreateProgramWithSource(context, 1, &fft1D_1024_kernel_src, NULL, NULL);
// build the compute program executable
clBuildProgram(program, 0, NULL, NULL, NULL, NULL);
// create the compute kernel
kernel = clCreateKernel(program, "fft1D_1024", NULL);
// set the args values
clSetKernelArg(kernel, 0, sizeof(cl_mem), (void *)&memobjs[0]);
clSetKernelArg(kernel, 1, sizeof(cl_mem), (void *)&memobjs[1]);
clSetKernelArg(kernel, 2, sizeof(float)*(local_work_size[0]+1)*16, NULL);
clSetKernelArg(kernel, 3, sizeof(float)*(local_work_size[0]+1)*16, NULL);
// create N-D range object with work-item dimensions and execute kernel
global_work_size[0] = num_entries;
local_work_size[0] = 64; //Nvidia: 192 or 256
clEnqueueNDRangeKernel(queue, kernel, 1, NULL, global_work_size, local_work_size, 0, NULL, NULL);
The actual calculation (based on Fitting FFT onto the G80 Architecture):[16]
// This kernel computes FFT of length 1024. The 1024 length FFT is decomposed into
// calls to a radix 16 function, another radix 16 function and then a radix 4 function
__kernel void fft1D_1024 (__global float2 *in, __global float2 *out,
__local float *sMemx, __local float *sMemy) {
int tid = get_local_id(0);
int blockIdx = get_group_id(0) * 1024 + tid;
float2 data[16];
// starting index of data to/from global memory
in = in + blockIdx; out = out + blockIdx;
globalLoads(data, in, 64); // coalesced global reads
fftRadix16Pass(data); // in-place radix-16 pass
twiddleFactorMul(data, tid, 1024, 0);
// local shuffle using local memory
localShuffle(data, sMemx, sMemy, tid, (((tid & 15) * 65) + (tid >> 4)));
fftRadix16Pass(data); // in-place radix-16 pass
twiddleFactorMul(data, tid, 64, 4); // twiddle factor multiplication
localShuffle(data, sMemx, sMemy, tid, (((tid >> 4) * 64) + (tid & 15)));
// four radix-4 function calls
fftRadix4Pass(data); // radix-4 function number 1
fftRadix4Pass(data + 4); // radix-4 function number 2
fftRadix4Pass(data + 8); // radix-4 function number 3
fftRadix4Pass(data + 12); // radix-4 function number 4
// coalesced global writes
globalStores(data, out, 64);
}
A full, open source implementation of an OpenCL FFT can be found on Apple's website.[17]
History
OpenCL was initially developed by Apple Inc., which holds trademark rights, and refined into an initial proposal in collaboration with technical teams at AMD, IBM, Qualcomm, Intel, and Nvidia. Apple submitted this initial proposal to the Khronos Group. On June 16, 2008, the Khronos Compute Working Group was formed[18] with representatives from CPU, GPU, embedded-processor, and software companies. This group worked for five months to finish the technical details of the specification for OpenCL 1.0 by November 18, 2008.[19] This technical specification was reviewed by the Khronos members and approved for public release on December 8, 2008.[20]
OpenCL 1.0
OpenCL 1.0 released with Mac OS X Snow Leopard on August 28, 2009. According to an Apple press release:[21]
Snow Leopard further extends support for modern hardware with Open Computing Language (OpenCL), which lets any application tap into the vast gigaflops of GPU computing power previously available only to graphics applications. OpenCL is based on the C programming language and has been proposed as an open standard.
AMD decided to support OpenCL instead of the now deprecated Close to Metal in its Stream framework.[22][23] RapidMind announced their adoption of OpenCL underneath their development platform to support GPUs from multiple vendors with one interface.[24] On December 9, 2008, Nvidia announced its intention to add full support for the OpenCL 1.0 specification to its GPU Computing Toolkit.[25] On October 30, 2009, IBM released its first OpenCL implementation as a part of the XL compilers.[26]
OpenCL 1.1
OpenCL 1.1 was ratified by the Khronos Group on June 14, 2010[27] and adds significant functionality for enhanced parallel programming flexibility, functionality, and performance including:
- New data types including 3-component vectors and additional image formats;
- Handling commands from multiple host threads and processing buffers across multiple devices;
- Operations on regions of a buffer including read, write and copy of 1D, 2D, or 3D rectangular regions;
- Enhanced use of events to drive and control command execution;
- Additional OpenCL built-in C functions such as integer clamp, shuffle, and asynchronous strided copies;
- Improved OpenGL interoperability through efficient sharing of images and buffers by linking OpenCL and OpenGL events.
OpenCL 1.2
On November 15, 2011, the Khronos Group announced the OpenCL 1.2 specification,[28] which added significant functionality over the previous versions in terms of performance and features for parallel programming. Most notable features include:
- Device partitioning: the ability to partition a device into sub-devices so that work assignments can be allocated to individual compute units. This is useful for reserving areas of the device to reduce latency for time-critical tasks.
- Separate compilation and linking of objects: the functionality to compile OpenCL into external libraries for inclusion into other programs.
- Enhanced image support: 1.2 adds support for 1D images and 1D/2D image arrays. Furthermore, the OpenGL sharing extensions now allow for OpenGL 1D textures and 1D/2D texture arrays to be used to create OpenCL images.
- Built-in kernels: custom devices that contain specific unique functionality are now integrated more closely into the OpenCL framework. Kernels can be called to use specialised or non-programmable aspects of underlying hardware. Examples include video encoding/decoding and digital signal processors.
- DirectX functionality: DX9 media surface sharing allows for efficient sharing between OpenCL and DX9 or DXVA media surfaces. Equally, for DX11, seamless sharing between OpenCL and DX11 surfaces is enabled.
- The ability to force IEEE 754 compliance for single precision floating point math: OpenCL by default allows the single precision versions of the division, reciprocal, and square root operation to be less accurate than the correctly rounded values that IEEE 754 requires.[29] If the programmer passes the "-cl-fp32-correctly-rounded-divide-sqrt" command line argument to the compiler, these three operations will be computed to IEEE 754 requirements if the OpenCL implementation supports this, and will fail to compile if the OpenCL implementation does not support computing these operations to their correctly-rounded values as defined by the IEEE 754 specification.[29] This ability is supplemented by the ability to query the OpenCL implementation to determine if it can perform these operations to IEEE 754 accuracy.[29]
OpenCL 2.0
On November 18, 2013, the Khronos Group announced the ratification and public release of the finalized OpenCL 2.0 specification.[30] Updates and additions to OpenCL 2.0 include:
- Shared virtual memory
- Nested parallelism
- Generic address space
- Images
- C11 atomics
- Pipes
- Android installable client driver extension
OpenCL 2.1
The ratification and release of the OpenCL 2.1 provisional specification was announced on March 3, 2015 at the Game Developer Conference in San Francisco. It was released on November 16, 2015.[31] It replaces the OpenCL C kernel language with OpenCL C++, a subset of C++14. Vulkan and OpenCL 2.1 share SPIR-V as an intermediate language allowing high-level language front-ends to share a common compilation target. Updates to the OpenCL API include:
- Additional subgroup functionality
- Copying of kernel objects and states
- Low-latency device timer queries
- Ingestion of SPIR-V code by runtime
- Execution priority hints for queues
- Zero-sized dispatches from host
AMD, ARM, Intel, HPC, and YetiWare have declared support for OpenCL 2.1.[32][33]
Implementations
OpenCL consists of a set of headers and a shared object that is loaded at runtime. An installable client driver loader (ICD loader) must be installed on the platform for every class of vendor for which the runtime would need to support. That is, for example, in order to support Nvidia devices on a Linux platform, the Nvidia ICD would need to be installed such that the OpenCL runtime would be able to locate the ICD for the vendor and redirect the calls appropriately. The standard OpenCL header is used by the consumer application; calls to each function are then proxied by the OpenCL runtime to the appropriate driver using the ICD. Each vendor must implement each OpenCL call in their driver.[34]
A number of open source implementations of the OpenCL ICD exist, including freeocl[35] and ocl-icd.[36] An implementation of OpenCL for a number of platforms is maintained as part of the Gallium Compute Project,[37] which builds on the work of the Mesa project to support multiple platforms. An implementation by Intel for its Ivy Bridge hardware was released in 2013.[38] This software, called "Beignet", is not based on Mesa/Gallium, which has attracted criticism from developers at AMD and Red Hat,[39] as well as Michael Larabel of Phoronix.[40] A CPU-only version building on Clang and LLVM, called pocl, is intended to be a portable OpenCL implementation.[41]
Timeline of vendor implementations
- December 10, 2008: AMD and Nvidia held the first public OpenCL demonstration, a 75-minute presentation at Siggraph Asia 2008. AMD showed a CPU-accelerated OpenCL demo explaining the scalability of OpenCL on one or more cores while Nvidia showed a GPU-accelerated demo.[42][43]
- March 16, 2009: at the 4th Multicore Expo, Imagination Technologies announced the PowerVR SGX543MP, the first GPU of this company to feature OpenCL support.[44]
- March 26, 2009: at GDC 2009, AMD and Havok demonstrated the first working implementation for OpenCL accelerating Havok Cloth on AMD Radeon HD 4000 series GPU.[45]
- April 20, 2009: Nvidia announced the release of its OpenCL driver and SDK to developers participating in its OpenCL Early Access Program.[46]
- August 5, 2009: AMD unveiled the first development tools for its OpenCL platform as part of its ATI Stream SDK v2.0 Beta Program.[47]
- August 28, 2009: Apple released Mac OS X Snow Leopard, which contains a full implementation of OpenCL.[48]
- OpenCL in Snow Leopard is supported on the Nvidia GeForce 320M, GeForce GT 330M, GeForce 9400M, GeForce 9600M GT, GeForce 8600M GT, GeForce GT 120, GeForce GT 130, GeForce GTX 285, GeForce 8800 GT, GeForce 8800 GS, Quadro FX 4800, Quadro FX5600, ATI Radeon HD 4670, ATI Radeon HD 4850, Radeon HD 4870, ATI Radeon HD 5670, ATI Radeon HD 5750, ATI Radeon HD 5770 and ATI Radeon HD 5870.[49]
- September 28, 2009: Nvidia released its own OpenCL drivers and SDK implementation.
- October 13, 2009: AMD released the fourth beta of the ATI Stream SDK 2.0, which provides a complete OpenCL implementation on both R700/R800 GPUs and SSE3 capable CPUs. The SDK is available for both Linux and Windows.[50]
- November 26, 2009: Nvidia released drivers for OpenCL 1.0 (rev 48).
- The Apple,[51] Nvidia,[52] RapidMind[53] and Gallium3D[54] implementations of OpenCL are all based on the LLVM Compiler technology and use the Clang Compiler as its frontend.
- October 27, 2009: S3 released their first product supporting native OpenCL 1.0 – the Chrome 5400E embedded graphics processor.[55]
- December 10, 2009: VIA released their first product supporting OpenCL 1.0 – ChromotionHD 2.0 video processor included in VN1000 chipset.[56]
- December 21, 2009: AMD released the production version of the ATI Stream SDK 2.0,[57] which provides OpenCL 1.0 support for R800 GPUs and beta support for R700 GPUs.
- June 1, 2010: ZiiLABS released details of their first OpenCL implementation for the ZMS processor for handheld, embedded and digital home products.[58]
- June 30, 2010: IBM released a fully conformant version of OpenCL 1.0.[59]
- September 13, 2010: Intel released details of their first OpenCL implementation for the Sandy Bridge chip architecture. Sandy Bridge will integrate Intel's newest graphics chip technology directly onto the central processing unit.[60]
- November 15, 2010: Wolfram Research released Mathematica 8 with OpenCLLink package.
- March 3, 2011: Khronos Group announces the formation of the WebCL working group to explore defining a JavaScript binding to OpenCL. This creates the potential to harness GPU and multi-core CPU parallel processing from a Web browser.[61][62]
- March 31, 2011: IBM released a fully conformant version of OpenCL 1.1.[59][63]
- April 25, 2011: IBM released OpenCL Common Runtime v0.1 for Linux on x86 Architecture.[64]
- May 4, 2011: Nokia Research releases an open source WebCL extension for the Firefox web browser, providing a JavaScript binding to OpenCL.[65]
- July 1, 2011: Samsung Electronics releases an open source prototype implementation of WebCL for WebKit, providing a JavaScript binding to OpenCL.[66]
- August 8, 2011: AMD released the OpenCL-driven AMD Accelerated Parallel Processing (APP) Software Development Kit (SDK) v2.5, replacing the ATI Stream SDK as technology and concept.[67]
- December 12, 2011: AMD released AMD APP SDK v2.6[68] which contains a preview of OpenCL 1.2.
- February 27, 2012: The Portland Group released the PGI OpenCL compiler for multi-core ARM CPUs.[69]
- April 17, 2012: Khronos released a WebCL working draft.[70]
- May 6, 2013: Altera released the Altera SDK for OpenCL, version 13.0.[71] It is conformant to OpenCL 1.0.[72]
- November 18, 2013: Khronos announced that the specification for OpenCL 2.0 had been finalised.[73]
- March 19, 2014: Khronos releases the WebCL 1.0 specification[74][75]
- August 29, 2014: Intel releases HD Graphics 5300 driver that supports OpenCL 2.0.[76]
- September 25, 2014: AMD releases Catalyst 14.41 RC1, which includes an OpenCL 2.0 driver.[77]
- April 13, 2015: Nvidia releases WHQL driver v350.12, which includes OpenCL 1.2 support for GPUs based on Kepler or later architectures.[78]
- August 26, 2015: AMD released AMD APP SDK v3.0[79] which contains full support of OpenCL 2.0 and sample coding.
Conformant products
The Khronos Group maintains an extended list of OpenCL-conformant products.[4]
| Synopsis of OpenCL conformant products[4] | ||||
|---|---|---|---|---|
| AMD APP SDK (supports OpenCL CPU and accelerated processing unit Devices) | X86 + SSE2 (or higher) compatible CPUs 64-bit & 32-bit;[80] Linux 2.6 PC, Windows Vista/7 PC | AMD Fusion E-350, E-240, C-50, C-30 with HD 6310/HD 6250 | AMD Radeon/Mobility HD 6800, HD 5x00 series GPU, iGPU HD 6310/HD 6250 | ATI FirePro Vx800 series GPU |
| Intel SDK for OpenCL Applications 2013[81] (supports Intel Core processors and Intel HD Graphics 4000/2500) | Intel CPUs with SSE 4.1, SSE 4.2 or AVX support.[82][83] Microsoft Windows, Linux | Intel Core i7, i5, i3; 2nd Generation Intel Core i7/5/3, 3rd Generation Intel Core Processors with Intel HD Graphics 4000/2500 | Intel Core 2 Solo, Duo Quad, Extreme | Intel Xeon 7x00,5x00,3x00 (Core based) |
| IBM Servers with OpenCL Development Kit for Linux on Power running on Power VSX[84][85] | IBM Power 755 (PERCS), 750 | IBM BladeCenter PS70x Express | IBM BladeCenter JS2x, JS43 | IBM BladeCenter QS22 |
| IBM OpenCL Common Runtime (OCR) | X86 + SSE2 (or higher) compatible CPUs 64-bit & 32-bit;[87] Linux 2.6 PC | AMD Fusion, Nvidia Ion and Intel Core i7, i5, i3; 2nd Generation Intel Core i7/5/3 | AMD Radeon, Nvidia GeForce and Intel Core 2 Solo, Duo, Quad, Extreme | ATI FirePro, Nvidia Quadro and Intel Xeon 7x00,5x00,3x00 (Core based) |
| Nvidia OpenCL Driver and Tools[88] | Nvidia Tesla C/D/S | Nvidia GeForce GTS/GT/GTX | Nvidia Ion | Nvidia Quadro FX/NVX/Plex |
Extensions
Some vendors provide extended functionality over the standard OpenCL specification via the means of extensions. These are still specified by Khronos but provided by vendors within their SDKs. They often contain features that are to be implemented in the future – for example device fission functionality was originally an extension but is now provided as part of the 1.2 specification.
Extensions provided in the 1.2 specification include:
- Writing to 3D image memory objects
- Half-precision floating-point format
- Sharing memory objects with OpenGL
- Creating event objects from GL sync objects
- Sharing memory objects with Direct3D 10
- DX9 media Surface Sharing
- Sharing Memory Objects with Direct3D 11
Device fission
Device fission – introduced fully into the OpenCL standard with version 1.2 – allows individual command queues to be used for specific areas of a device. For example, within the Intel SDK, a command queue can be created that maps directly to an individual core. AMD also provides functionality for device fission, also originally as an extension. Device fission can be used where the availability of compute is required reliably, such as in a latency sensitive environment. Fission effectively reserves areas of the device for computation.
Portability, performance and alternatives
A key feature of OpenCL is portability, via its abstracted memory and execution model, and the programmer is not able to directly use hardware-specific technologies such as inline Parallel Thread Execution (PTX) for NVidia GPUs unless they are willing to give up direct portability on other platforms. It is possible to run any OpenCL kernel on any conformant implementation.
However, performance of the kernel is not necessarily portable across platforms. Existing implementations have been shown to be competitive when kernel code is properly tuned, though, and auto-tuning has been suggested as a solution to the performance portability problem,[89] yielding "acceptable levels of performance" in experimental linear algebra kernels.[90] Portability of an entire application containing multiple kernels with differing behaviors was also studied, and shows that portability only required limited tradeoffs.[91]
A study at Delft University that compared CUDA programs and their straightforward translation into OpenCL C found CUDA to outperform OpenCL by at most 30% on the Nvidia implementation. The researchers noted that their comparison could be made fairer by applying manual optimizations to the OpenCL programs, in which case there was "no reason for OpenCL to obtain worse performance than CUDA". The performance differences could mostly be attributed to differences in the programming model (especially the memory model) and to NVIDIA's compiler optimizations for CUDA compared to those for OpenCL.[89] Another, similar study found CUDA to perform faster data transfers to and from a GPU's memory.[92]
The fact that OpenCL allows workloads to be shared by CPU and GPU, executing the same programs, means that programmers can exploit both by dividing work among the devices.[93] This leads to the problem of deciding how to partition the work, because the relative speeds of operations differ among the devices. Machine learning has been suggested to solve this problem: Grewe and O'Boyle describe a system of support vector machines trained on compile-time features of program that can decide the device partitioning problem statically, without actually running the programs to measure their performance.[94]
See also
References
- 1 2 Howes, Lee (November 11, 2015). "The OpenCL Specification Version: 2.1 Document Revision: 23" (PDF). Khronos Group. Retrieved November 16, 2015.
- ↑ "Android Devices With OpenCL support". Google Docs. ArrayFire. Retrieved April 28, 2015.
- ↑ "FreeBSD Graphics/OpenCL". FreeBSD. Retrieved 23 December 2015.
- 1 2 3 "Conformant Products". Khronos Group. Retrieved May 9, 2015.
- ↑ Munshi, Aaftab; Howes, Lee; Sochaki, Barosz (September 9, 2015). "The OpenCL C Specification Version: 2.0 Document Revision: 30" (PDF). Khronos Group. Retrieved February 2, 2016.
- ↑ Munshi, Aaftab (March 2, 2015). "The OpenCL C++ Specification Version: 1.0 Document Revision: 08" (PDF). Khronos Group. Retrieved April 16, 2015.
- ↑ "Conformant Companies". Khronos Group. Retrieved April 8, 2015.
- ↑ Gianelli, Silvia E. (January 14, 2015). "Xilinx SDAccel Development Environment for OpenCL, C, and C++, Achieves Khronos Conformance". PR Newswire. Xilinx. Retrieved April 27, 2015.
- 1 2 Gaster, Benedict; Howes, Lee; Kaeli, David R.; Mistry, Perhaad; Schaa, Dana (2012). Heterogeneous Computing with OpenCL: Revised OpenCL 1.2 Edition. Morgan Kaufmann.
- ↑ Tompson, Jonathan; Schlachter, Kristofer (2012). "An Introduction to the OpenCL Programming Model" (PDF). New York University Media Research Lab. Retrieved July 6, 2015.
- 1 2 3 4 Stone, John E.; Gohara, David; Shi, Guochin (2010). "OpenCL: a parallel programming standard for heterogeneous computing systems". Computing in Science & Engineering. doi:10.1109/MCSE.2010.69.
- ↑ Klöckner, Andreas; Pinto, Nicolas; Lee, Yunsup; Catanzaro, Bryan; Ivanov, Paul; Fasih, Ahmed (2012). "PyCUDA and PyOpenCL: A scripting-based approach to GPU run-time code generation". Parallel Computing 38 (3): 157–174. arXiv:0911.3456. doi:10.1016/j.parco.2011.09.001.
- 1 2 3 Aaftab Munshi, ed. (2014). "The OpenCL C Specification, Version 2.0" (PDF). Retrieved June 24, 2014.
- 1 2 AMD. Introduction to OpenCL Programming 201005, page 89-90
- ↑ "OpenCL" (PDF). SIGGRAPH2008. August 14, 2008. Retrieved August 14, 2008.
- ↑ "Fitting FFT onto G80 Architecture" (PDF). Vasily Volkov and Brian Kazian, UC Berkeley CS258 project report. May 2008. Retrieved November 14, 2008.
- ↑ "OpenCL on FFT". Apple. November 16, 2009. Retrieved December 7, 2009.
- ↑ "Khronos Launches Heterogeneous Computing Initiative" (Press release). Khronos Group. June 16, 2008. Retrieved June 18, 2008.
- ↑ "OpenCL gets touted in Texas". MacWorld. November 20, 2008. Retrieved June 12, 2009.
- ↑ "The Khronos Group Releases OpenCL 1.0 Specification" (Press release). Khronos Group. December 8, 2008. Retrieved June 12, 2009.
- ↑ "Apple Previews Mac OS X Snow Leopard to Developers" (Press release). Apple Inc. June 9, 2008. Retrieved June 9, 2008.
- ↑ "AMD Drives Adoption of Industry Standards in GPGPU Software Development" (Press release). AMD. August 6, 2008. Retrieved August 14, 2008.
- ↑ "AMD Backs OpenCL, Microsoft DirectX 11". eWeek. August 6, 2008. Retrieved August 14, 2008.
- ↑ "HPCWire: RapidMind Embraces Open Source and Standards Projects". HPCWire. November 10, 2008. Archived from the original on December 18, 2008. Retrieved November 11, 2008.
- ↑ "Nvidia Adds OpenCL To Its Industry Leading GPU Computing Toolkit" (Press release). Nvidia. December 9, 2008. Retrieved December 10, 2008.
- ↑ "OpenCL Development Kit for Linux on Power". alphaWorks. October 30, 2009. Retrieved October 30, 2009.
- ↑ Khronos Drives Momentum of Parallel Computing Standard with Release of OpenCL 1.1 Specification
- ↑ "Khronos Releases OpenCL 1.2 Specification". Khronos Group. November 15, 2011. Retrieved June 23, 2015.
- 1 2 3 "OpenCL 1.2 Specification" (PDF). Khronos Group. Retrieved June 23, 2015.
- ↑ "Khronos Finalizes OpenCL 2.0 Specification for Heterogeneous Computing". Khronos Group. November 18, 2013. Retrieved February 10, 2014.
- ↑ "Khronos Releases OpenCL 2.1 and SPIR-V 1.0 Specifications for Heterogeneous Parallel Programming". Khronos Group. November 16, 2015. Retrieved November 16, 2015.
- ↑ "Khronos Announces OpenCL 2.1: C++ Comes to OpenCL". AnandTech. March 3, 2015. Retrieved April 8, 2015.
- ↑ "Khronos Releases OpenCL 2.1 Provisional Specification for Public Review". Kronos Group. March 3, 2015. Retrieved April 8, 2015.
- ↑ "OpenCL ICD Specification". Retrieved June 23, 2015.
- ↑ "freeocl – Multi-platform implementation of OpenCL 1.2 targeting CPUs". code.google.com. Retrieved June 23, 2015.
- ↑ "OpenCL ICD Loader". forge.imag.fr. Retrieved June 23, 2015.
- ↑ "GalliumCompute". dri.freedesktop.org. Retrieved June 23, 2015.
- ↑ Michael Larabel (January 10, 2013). "Beignet: OpenCL/GPGPU Comes For Ivy Bridge On Linux". Phoronix.
- ↑ Michael Larabel (April 16, 2013). "More Criticism Comes Towards Intel's Beignet OpenCL". Phoronix.
- ↑ Michael Larabel (December 24, 2013). "Intel's Beignet OpenCL Is Still Slowly Baking". Phoronix.
- ↑ Jääskeläinen, Pekka; Sánchez de La Lama, Carlos; Schnetter, Erik; Raiskila, Kalle; Takala, Jarmo; Berg, Heikki (2014). "pocl: A Performance-Portable OpenCL Implementation". Int'l J. Parallel Programming. doi:10.1007/s10766-014-0320-y.
- ↑ "OpenCL Demo, AMD CPU". December 10, 2008. Retrieved March 28, 2009.
- ↑ "OpenCL Demo, Nvidia GPU". December 10, 2008. Retrieved March 28, 2009.
- ↑ "Imagination Technologies launches advanced, highly-efficient POWERVR SGX543MP multi-processor graphics IP family". Imagination Technologies. March 19, 2009. Retrieved January 30, 2011.
- ↑ "AMD and Havok demo OpenCL accelerated physics". PC Perspective. March 26, 2009. Retrieved March 28, 2009.
- ↑ "Nvidia Releases OpenCL Driver To Developers". Nvidia. April 20, 2009. Retrieved April 27, 2009.
- ↑ "AMD does reverse GPGPU, announces OpenCL SDK for x86". Ars Technica. August 5, 2009. Retrieved August 6, 2009.
- ↑ Dan Moren; Jason Snell (June 8, 2009). "Live Update: WWDC 2009 Keynote". macworld.com. MacWorld. Retrieved June 12, 2009.
- ↑ "Mac OS X Snow Leopard – Technical specifications and system requirements". Apple Inc. March 23, 2011. Retrieved March 23, 2011.
- ↑ "ATI Stream Software Development Kit (SDK) v2.0 Beta Program". Retrieved October 14, 2009.
- ↑ "Apple entry on LLVM Users page". Retrieved August 29, 2009.
- ↑ "Nvidia entry on LLVM Users page". Retrieved August 6, 2009.
- ↑ "Rapidmind entry on LLVM Users page". Retrieved October 1, 2009.
- ↑ "Zack Rusin's blog post about the Gallium3D OpenCL implementation". Retrieved October 1, 2009.
- ↑ "S3 Graphics launched the Chrome 5400E embedded graphics processor". Retrieved October 27, 2009.
- ↑ "VIA Brings Enhanced VN1000 Graphics Processor]". Retrieved December 10, 2009.
- ↑ "ATI Stream SDK v2.0 with OpenCL 1.0 Support". Retrieved October 23, 2009.
- ↑ "OpenCL". ZiiLABS. Retrieved June 23, 2015.
- 1 2 "Khronos Group Conformant Products".
- ↑ "Intel discloses new Sandy Bridge technical details". Retrieved September 13, 2010.
- ↑ "WebCL related stories". Khronos Group. Retrieved June 23, 2015.
- ↑ "Khronos Releases Final WebGL 1.0 Specification". Khronos Group. Retrieved June 23, 2015.
- ↑ "OpenCL Development Kit for Linux on Power".
- ↑ "About the OpenCL Common Runtime for Linux on x86 Architecture".
- ↑ "Nokia Research releases WebCL prototype". Khronos Group. May 4, 2011. Retrieved June 23, 2015.
- ↑ SharathKamathK. "Samsung's WebCL Prototype for WebKit". Github.com. Retrieved June 23, 2015.
- ↑ "AMD Opens the Throttle on APU Performance with Updated OpenCL Software Development ". Amd.com. August 8, 2011. Retrieved June 16, 2013.
- ↑ "AMD APP SDK v2.6". Forums.amd.com. March 13, 2015. Retrieved June 23, 2015.
- ↑ "The Portland Group Announces OpenCL Compiler for ST-Ericsson ARM-Based NovaThor SoCs". Retrieved May 4, 2012.
- ↑ "WebCL Latest Spec". cvs.khronos.org. November 7, 2013. Retrieved June 23, 2015.
- ↑ "Altera Opens the World of FPGAs to Software Programmers with Broad Availability of SDK and Off-the-Shelf Boards for OpenCL". Altera.com. Retrieved January 9, 2014.
- ↑ "Altera SDK for OpenCL is First in Industry to Achieve Khronos Conformance for FPGAs". Altera.com. Retrieved January 9, 2014.
- ↑ "Khronos Finalizes OpenCL 2.0 Specification for Heterogeneous Computing". Khronos Group. November 18, 2013. Retrieved June 23, 2015.
- ↑ "WebCL 1.0 Press Release". Khronos Group. March 19, 2014. Retrieved June 23, 2015.
- ↑ "WebCL 1.0 Specification". Khronos Group. March 14, 2014. Retrieved June 23, 2015.
- ↑ Intel OpenCL 2.0 Driver
- ↑ "AMD OpenCL 2.0 Driver". support.amd.com. June 17, 2015. Retrieved June 23, 2015.
- ↑ "Release 349 Graphics Drivers for Windows, Version 350.12" (PDF). April 13, 2015. Retrieved February 4, 2016.
- ↑ "AMD APP SDK 3.0 Released". developer.amd.com. August 26, 2015. Retrieved September 11, 2015.
- ↑ "OpenCL and the AMD APP SDK". AMD Developer Central. developer.amd.com. Archived from the original on August 4, 2011. Retrieved August 11, 2011.
- ↑ "About Intel OpenCL SDK 1.1". software.intel.com. intel.com. Retrieved August 11, 2011.
- ↑ "Product Support". Retrieved August 11, 2011.
- ↑ "Intel OpenCL SDK – Release Notes". Retrieved August 11, 2011.
- ↑ "Announcing OpenCL Development Kit for Linux on Power v0.3". Retrieved August 11, 2011.
- ↑ "IBM releases OpenCL Development Kit for Linux on Power v0.3 – OpenCL 1.1 conformant release available". OpenCL Lounge. ibm.com. Retrieved August 11, 2011.
- ↑ "IBM releases OpenCL Common Runtime for Linux on x86 Architecture". Retrieved September 10, 2011.
- ↑ "OpenCL and the AMD APP SDK". AMD Developer Central. developer.amd.com. Retrieved September 10, 2011.
- ↑ "Nvidia Releases OpenCL Driver". Retrieved August 11, 2011.
- 1 2 Fang, Jianbin; Varbanescu, Ana Lucia; Sips, Henk (2011). A Comprehensive Performance Comparison of CUDA and OpenCL (PDF). Proc. Int'l Conf. on Parallel Processing. doi:10.1109/ICPP.2011.45.
- ↑ Du, Peng; Weber, Rick; Luszczek, Piotr; Tomov, Stanimire; Peterson, Gregory; Dongarra, Jack (2012). "From CUDA to OpenCL: Towards a performance-portable solution for multi-platform GPU programming". Parallel Computing 38 (8): 391–407. doi:10.1016/j.parco.2011.10.002.
- ↑ Romain Dolbeau, François Bodin, Guillaume Colin de Verdière (September 7, 2013). "One OpenCL to rule them all?". Archived from the original on January 16, 2014. Retrieved January 14, 2014.
- ↑ Karimi, Kamran; Dickson, Neil G.; Hamze, Firas (2011). "A Performance Comparison of CUDA and OpenCL". arXiv:1005.2581v3.
- ↑ A Survey of CPU-GPU Heterogeneous Computing Techniques, ACM Computing Surveys, 2015.
- ↑ Grewe, Dominik; O'Boyle, Michael F. P. (2011). A Static Task Partitioning Approach for Heterogeneous Systems Using OpenCL. Proc. Int'l Conf. on Compiler Construction. doi:10.1007/978-3-642-19861-8_16.
External links
| ||||||
| ||||||||||||||||||||||||||||||||||||||||||||||