Odds ratio
In statistics, the odds ratio[1][2][3] (usually abbreviated "OR") is one of three main ways to quantify how strongly the presence or absence of property A is associated with the presence or absence of property B in a given population. If each individual in a population either does or does not have a property "A", (e.g. "high blood pressure"), and also either does or does not have a property "B" (e.g. "moderate alcohol consumption") where both properties are appropriately defined, then a ratio can be formed which quantitatively describes the association between the presence/absence of "A" (high blood pressure) and the presence/absence of "B" (moderate alcohol consumption) for individuals in the population. This ratio is the odds ratio (OR) and can be computed following these steps:
- For a given individual that has "B" compute the odds that the same individual has "A"
- For a given individual that does not have "B" compute the odds that the same individual has "A"
- Divide the odds from step 1 by the odds from step 2 to obtain the odds ratio (OR).
The term "individual" in this usage does not have to refer to a human being, as a statistical population can measure any set of entities, whether living or inanimate.
If the OR is greater than 1, then having "A" is considered to be "associated" with having "B" in the sense that the having of "B" raises (relative to not-having "B") the odds of having "A". Note that this is not enough to establish that B is a contributing cause of "A": it could be that the association is due to a third property, "C", which is a contributing cause of both "A" and "B" (confounding).
The two other major ways of quantifying association are the risk ratio ("RR") and the absolute risk reduction ("ARR"). In clinical studies and many other settings, the parameter of greatest interest is often actually the RR, which is determined in a way that is similar to the one just described for the OR, except using probabilities instead of odds. Frequently, however, the available data only allows the computation of the OR; notably, this is so in the case of case-control studies, as explained below. On the other hand, if one of the properties (say, A) is sufficiently rare (the "rare disease assumption"), then the OR of having A given that the individual has B is a good approximation to the corresponding RR (the specification "A given B" is needed because, while the OR treats the two properties symmetrically, the RR and other measures do not).
In a more technical language, the OR is a measure of effect size, describing the strength of association or non-independence between two binary data values. It is used as a descriptive statistic, and plays an important role in logistic regression.
Definition and basic properties
A motivating example, in the context of the rare disease assumption
Imagine there is rare disease, afflicting, say, only one in many thousands of adults in a country. Imagine we suspect that being exposed to something (say, having had a particular sort of injury in childhood) makes one more likely to develop that disease in adulthood. The most informative thing to compute would be the risk ratio, RR. To do this in the ideal case, for all the adults in the population we would need to know whether they (a) had the exposure to the injury as children and (b) whether they developed the disease as adults. From this we would extract the following information: the total number of people exposed to the childhood injury, 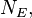 out of which
out of which 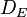 developed the disease and
developed the disease and 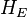 stayed healthy; and the total number of people not exposed,
stayed healthy; and the total number of people not exposed, 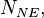 out of which
out of which 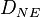 developed the disease and
developed the disease and 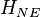 stayed healthy. Since
stayed healthy. Since 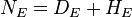 and similarly for the "NE" numbers, we only have four independent numbers, which we can organize in a table:
and similarly for the "NE" numbers, we only have four independent numbers, which we can organize in a table:
| Diseased | Healthy | |
| Exposed | | |
| Not exposed | | |
To avoid possible confusion, we emphasize that all these numbers refer to the entire population, and not to some sample of it.
Now the risk of developing the disease given exposure is 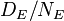 (where ), and of developing the disease given non-exposure is
(where ), and of developing the disease given non-exposure is 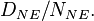 The risk ratio, RR, is just the ratio of the two,
The risk ratio, RR, is just the ratio of the two,
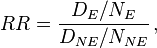
which can be rewritten as 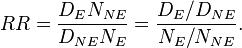
In contrast, the odds of developing the disease given exposure is 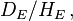 and of developing the disease given non-exposure is
and of developing the disease given non-exposure is 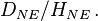 The odds ratio, OR, is the ratio of the two,
The odds ratio, OR, is the ratio of the two,
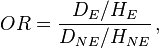
which can be rewritten as 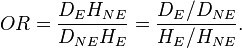
We may already note that if the disease is rare, then OR≈RR. Indeed, for a rare disease, we will have 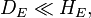 and so
and so 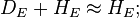 but then
but then 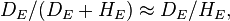 in other words, for the exposed population, the risk of developing the disease is approximately equal to the odds. Analogous reasoning shows that the risk is approximately equal to the odds for the non-exposed population as well; but then the ratio of the risks, which is RR, is approximately equal to the ratio of the odds, which is OR. Or, we could just notice that the rare disease assumption says that
in other words, for the exposed population, the risk of developing the disease is approximately equal to the odds. Analogous reasoning shows that the risk is approximately equal to the odds for the non-exposed population as well; but then the ratio of the risks, which is RR, is approximately equal to the ratio of the odds, which is OR. Or, we could just notice that the rare disease assumption says that 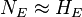 and
and 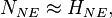 from which it follows that
from which it follows that 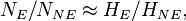 in other words that the denominators in the final expressions for the RR and the OR are approximately the same. The numerators are exactly the same, and so, again, we conclude that OR≈RR.
in other words that the denominators in the final expressions for the RR and the OR are approximately the same. The numerators are exactly the same, and so, again, we conclude that OR≈RR.
Returning to our hypothetical study, the problem we often face is that we may not have the data to estimate these four numbers. For example, we may not have the population-wide data on who did or did not have the childhood injury.
Often we may overcome this problem by employing random sampling of the population: namely, if neither the disease nor the exposure to the injury are too rare in our population, then we can pick (say) a hundred people at random, and find out these four numbers in that sample; assuming the sample is representative enough of the population, then the RR computed for this sample will be a good estimate for the RR for the whole population.
However, some diseases may be so rare that, in all likelihood, even a large random sample may not contain even a single diseased individual (or it may contain some, but too few to be statistically significant). This would make it impossible to compute the RR. But, we may nevertheless be able to estimate the OR, provided that, unlike the disease, the exposure to the childhood injury is not too rare. Of course, because the disease is rare, this is then also our estimate for the RR.
Looking at the final expression for the OR: the fraction in the numerator, 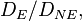 we can estimate by collecting all the known cases of the disease (presumably there must be some, or else we likely wouldn't be doing the study in the first place), and seeing how many of the diseased people had the exposure, and how many did not. And the fraction in the denominator,
we can estimate by collecting all the known cases of the disease (presumably there must be some, or else we likely wouldn't be doing the study in the first place), and seeing how many of the diseased people had the exposure, and how many did not. And the fraction in the denominator, 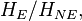 is the odds that a healthy individual in the population was exposed to the childhood injury. Now note that this latter odds can indeed be estimated by random sampling of the population—provided, as we said, that the prevalence of the exposure to the childhood injury is not too small, so that a random sample of a manageable size would be likely to contain a fair number of individuals who have had the exposure. So here the disease is very rare, but the factor thought to contribute to it is not quite so rare; such situations are quite common in practice.
is the odds that a healthy individual in the population was exposed to the childhood injury. Now note that this latter odds can indeed be estimated by random sampling of the population—provided, as we said, that the prevalence of the exposure to the childhood injury is not too small, so that a random sample of a manageable size would be likely to contain a fair number of individuals who have had the exposure. So here the disease is very rare, but the factor thought to contribute to it is not quite so rare; such situations are quite common in practice.
Thus we can estimate the OR, and then, invoking the rare disease assumption again, we say that this is also a good approximation of the RR. Incidentally, the story just told is a paradigmatic example of a case-control study.[4]
The same story could be told without ever mentioning the OR, like so: as soon as we have that and then we have that 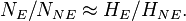 Thus if, by random sampling, we manage to estimate then, by rare disease assumption, that will be a good estimate of
Thus if, by random sampling, we manage to estimate then, by rare disease assumption, that will be a good estimate of 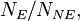 which is all we need (besides which we presumably already know by studying the few cases of the disease) to compute the RR. However, it is standard in the literature to explicitly report the OR and then claim that the RR is approximately equal to it.
which is all we need (besides which we presumably already know by studying the few cases of the disease) to compute the RR. However, it is standard in the literature to explicitly report the OR and then claim that the RR is approximately equal to it.
Definition in terms of group-wise odds
The odds ratio is the ratio of the odds of an event occurring in one group to the odds of it occurring in another group. The term is also used to refer to sample-based estimates of this ratio. These groups might be men and women, an experimental group and a control group, or any other dichotomous classification. If the probabilities of the event in each of the groups are p1 (first group) and p2 (second group), then the odds ratio is:
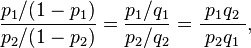
where qx = 1 − px. An odds ratio of 1 indicates that the condition or event under study is equally likely to occur in both groups. An odds ratio greater than 1 indicates that the condition or event is more likely to occur in the first group. And an odds ratio less than 1 indicates that the condition or event is less likely to occur in the first group. The odds ratio must be nonnegative if it is defined. It is undefined if p2q1 equals zero, i.e., if p2 equals zero or q1 equals zero.
Definition in terms of joint and conditional probabilities
The odds ratio can also be defined in terms of the joint probability distribution of two binary random variables. The joint distribution of binary random variables X and Y can be written
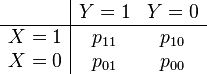
where p11, p10, p01 and p00 are non-negative "cell probabilities" that sum to one. The odds for Y within the two subpopulations defined by X = 1 and X = 0 are defined in terms of the conditional probabilities given X, i.e., P(Y|X):
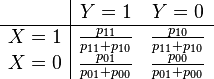
Thus the odds ratio is
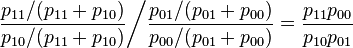
The simple expression on the right, above, is easy to remember as the product of the probabilities of the "concordant cells" (X = Y) divided by the product of the probabilities of the "discordant cells" (X ≠ Y). However note that in some applications the labeling of categories as zero and one is arbitrary, so there is nothing special about concordant versus discordant values in these applications.
Symmetry
If we had calculated the odds ratio based on the conditional probabilities given Y,
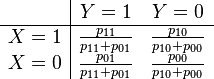
we would have gotten the same result
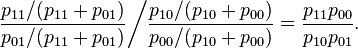
Other measures of effect size for binary data such as the relative risk do not have this symmetry property.
Relation to statistical independence
If X and Y are independent, their joint probabilities can be expressed in terms of their marginal probabilities px = P(X = 1) and py = P(Y = 1), as follows
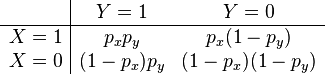
In this case, the odds ratio equals one, and conversely the odds ratio can only equal one if the joint probabilities can be factored in this way. Thus the odds ratio equals one if and only if X and Y are independent.
Recovering the cell probabilities from the odds ratio and marginal probabilities
The odds ratio is a function of the cell probabilities, and conversely, the cell probabilities can be recovered given knowledge of the odds ratio and the marginal probabilities P(X = 1) = p11 + p10 and P(Y = 1) = p11 + p01. If the odds ratio R differs from 1, then
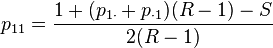
where p1• = p11 + p10, p•1 = p11 + p01, and
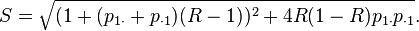
In the case where R = 1, we have independence, so p11 = p1•p•1.
Once we have p11, the other three cell probabilities can easily be recovered from the marginal probabilities.
Example

Suppose that in a sample of 100 men, 90 drank wine in the previous week, while in a sample of 100 women only 20 drank wine in the same period. The odds of a man drinking wine are 90 to 10, or 9:1, while the odds of a woman drinking wine are only 20 to 80, or 1:4 = 0.25:1. The odds ratio is thus 9/0.25, or 36, showing that men are much more likely to drink wine than women. The detailed calculation is:
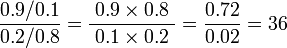
This example also shows how odds ratios are sometimes sensitive in stating relative positions: in this sample men are 90/20 = 4.5 times as likely to have drunk wine than women, but have 36 times the odds. The logarithm of the odds ratio, the difference of the logits of the probabilities, tempers this effect, and also makes the measure symmetric with respect to the ordering of groups. For example, using natural logarithms, an odds ratio of 36/1 maps to 3.584, and an odds ratio of 1/36 maps to −3.584.
Statistical inference

Several approaches to statistical inference for odds ratios have been developed.
One approach to inference uses large sample approximations to the sampling distribution of the log odds ratio (the natural logarithm of the odds ratio). If we use the joint probability notation defined above, the population log odds ratio is
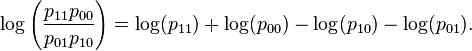
If we observe data in the form of a contingency table
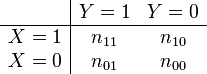
then the probabilities in the joint distribution can be estimated as
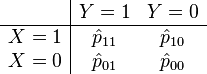
where ij = nij / n, with n = n11 + n10 + n01 + n00 being the sum of all four cell counts. The sample log odds ratio is
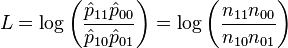 .
.
The distribution of the log odds ratio is approximately normal with:
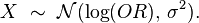
The standard error for the log odds ratio is approximately
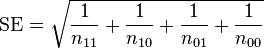 .
.
This is an asymptotic approximation, and will not give a meaningful result if any of the cell counts are very small. If L is the sample log odds ratio, an approximate 95% confidence interval for the population log odds ratio is L ± 1.96SE.[5] This can be mapped to exp(L − 1.96SE), exp(L + 1.96SE) to obtain a 95% confidence interval for the odds ratio. If we wish to test the hypothesis that the population odds ratio equals one, the two-sided p-value is 2P(Z < −|L|/SE), where P denotes a probability, and Z denotes a standard normal random variable.
An alternative approach to inference for odds ratios looks at the distribution of the data conditionally on the marginal frequencies of X and Y. An advantage of this approach is that the sampling distribution of the odds ratio can be expressed exactly.
Role in logistic regression
Logistic regression is one way to generalize the odds ratio beyond two binary variables. Suppose we have a binary response variable Y and a binary predictor variable X, and in addition we have other predictor variables Z1, ..., Zp that may or may not be binary. If we use multiple logistic regression to regress Y on X, Z1, ..., Zp, then the estimated coefficient 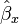 for X is related to a conditional odds ratio. Specifically, at the population level
for X is related to a conditional odds ratio. Specifically, at the population level
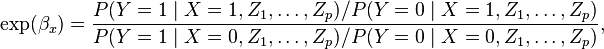
so 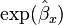 is an estimate of this conditional odds ratio. The interpretation of is as an estimate of the odds ratio between Y and X when the values of Z1, ..., Zp are held fixed.
is an estimate of this conditional odds ratio. The interpretation of is as an estimate of the odds ratio between Y and X when the values of Z1, ..., Zp are held fixed.
Insensitivity to the type of sampling
If the data form a "population sample", then the cell probabilities ij are interpreted as the frequencies of each of the four groups in the population as defined by their X and Y values. In many settings it is impractical to obtain a population sample, so a selected sample is used. For example, we may choose to sample units with X = 1 with a given probability f, regardless of their frequency in the population (which would necessitate sampling units with X = 0 with probability 1 − f). In this situation, our data would follow the following joint probabilities:
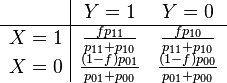
The odds ratio p11p00 / p01p10 for this distribution does not depend on the value of f. This shows that the odds ratio (and consequently the log odds ratio) is invariant to non-random sampling based on one of the variables being studied. Note however that the standard error of the log odds ratio does depend on the value of f.
This fact is exploited in two important situations:
- Suppose it is inconvenient or impractical to obtain a population sample, but it is practical to obtain a convenience sample of units with different X values, such that within the X = 0 and X = 1 subsamples the Y values are representative of the population (i.e. they follow the correct conditional probabilities).
- Suppose the marginal distribution of one variable, say X, is very skewed. For example, if we are studying the relationship between high alcohol consumption and pancreatic cancer in the general population, the incidence of pancreatic cancer would be very low, so it would require a very large population sample to get a modest number of pancreatic cancer cases. However we could use data from hospitals to contact most or all of their pancreatic cancer patients, and then randomly sample an equal number of subjects without pancreatic cancer (this is called a "case-control study").
In both these settings, the odds ratio can be calculated from the selected sample, without biasing the results relative to what would have been obtained for a population sample.
Use in quantitative research
Due to the widespread use of logistic regression, the odds ratio is widely used in many fields of medical and social science research. The odds ratio is commonly used in survey research, in epidemiology, and to express the results of some clinical trials, such as in case-control studies. It is often abbreviated "OR" in reports. When data from multiple surveys is combined, it will often be expressed as "pooled OR".
Relation to relative risk
In clinical studies, as well as in some other settings, the parameter of greatest interest is often the relative risk rather than the odds ratio. The relative risk is best estimated using a population sample, but if the rare disease assumption holds, the odds ratio is a good approximation to the relative risk — the odds is p / (1 − p), so when p moves towards zero, 1 − p moves towards 1, meaning that the odds approaches the risk, and the odds ratio approaches the relative risk.[6] When the rare disease assumption does not hold, the odds ratio can overestimate the relative risk.[7][8][9]
If the absolute risk in the control group is available, conversion between the two is calculated by:[7]
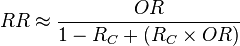
where:
- RR = relative risk
- OR = odds ratio
- RC = absolute risk in the unexposed group, given as a fraction (for example: fill in 10% risk as 0.1)
Confusion and exaggeration
Odds ratios have often been confused with relative risk in medical literature. For non-statisticians, the odds ratio is a difficult concept to comprehend, and it gives a more impressive figure for the effect.[10] However, most authors consider that the relative risk is readily understood.[11] In one study, members of a national disease foundation were actually 3.5 times more likely than nonmembers to have heard of a common treatment for that disease – but the odds ratio was 24 and the paper stated that members were ‘more than 20-fold more likely to have heard of’ the treatment.[12] A study of papers published in two journals reported that 26% of the articles that used an odds ratio interpreted it as a risk ratio.[13]
This may reflect the simple process of uncomprehending authors choosing the most impressive-looking and publishable figure.[11] But its use may in some cases be deliberately deceptive.[14] It has been suggested that the odds ratio should only be presented as a measure of effect size when the risk ratio cannot be estimated directly.[10]
Invertibility and invariance
The odds ratio has another unique property of being directly mathematically invertible whether analyzing the OR as either disease survival or disease onset incidence – where the OR for survival is direct reciprocal of 1/OR for risk. This is known as the 'invariance of the odds ratio'. In contrast, the relative risk does not possess this mathematical invertible property when studying disease survival vs. onset incidence. This phenomenon of OR invertibility vs. RR non-invertibility is best illustrated with an example:
Suppose in a clinical trial, one has an adverse event risk of 4/100 in drug group, and 2/100 in placebo... yielding a RR=2 and OR=2.04166 for drug-vs-placebo adverse risk. However, if analysis was inverted and adverse events were instead analyzed as event-free survival, then the drug group would have a rate of 96/100, and placebo group would have a rate of 98/100—yielding a drug-vs-placebo a RR=0.9796 for survival, but an OR=0.48979. As one can see, a RR of 0.9796 is clearly not the reciprocal of a RR of 2. In contrast, an OR of 0.48979 is indeed the direct reciprocal of an OR of 2.04166.
This is again what is called the 'invariance of the odds ratio', and why a RR for survival is not the same as a RR for risk, while the OR has this symmetrical property when analyzing either survival or adverse risk. The danger to clinical interpretation for the OR comes when the adverse event rate is not rare, thereby exaggerating differences when the OR rare-disease assumption is not met. On the other hand, when the disease is rare, using a RR for survival (e.g. the RR=0.9796 from above example) can clinically hide and conceal an important doubling of adverse risk associated with a drug or exposure.
Alternative estimators of the odds ratio
The sample odds ratio n11n00 / n10n01 is easy to calculate, and for moderate and large samples performs well as an estimator of the population odds ratio. When one or more of the cells in the contingency table can have a small value, the sample odds ratio can be biased and exhibit high variance. A number of alternative estimators of the odds ratio have been proposed to address this issue. One alternative estimator is the conditional maximum likelihood estimator, which conditions on the row and column margins when forming the likelihood to maximize (as in Fisher's exact test).[15] Another alternative estimator is the Mantel-Haenszel estimator.
Numerical examples
The following four contingency tables contain observed cell counts, along with the corresponding sample odds ratio (OR) and sample log odds ratio (LOR):
| OR = 1, LOR = 0 | OR = 1, LOR = 0 | OR = 4, LOR = 1.39 | OR = 0.25, LOR = −1.39 | |||||
|---|---|---|---|---|---|---|---|---|
| Y = 1 | Y = 0 | Y = 1 | Y = 0 | Y = 1 | Y = 0 | Y = 1 | Y = 0 | |
| X = 1 | 10 | 10 | 100 | 100 | 20 | 10 | 10 | 20 |
| X = 0 | 5 | 5 | 50 | 50 | 10 | 20 | 20 | 10 |
The following joint probability distributions contain the population cell probabilities, along with the corresponding population odds ratio (OR) and population log odds ratio (LOR):
| OR = 1, LOR = 0 | OR = 1, LOR = 0 | OR = 16, LOR = 2.77 | OR = 0.67, LOR = −0.41 | |||||
|---|---|---|---|---|---|---|---|---|
| Y = 1 | Y = 0 | Y = 1 | Y = 0 | Y = 1 | Y = 0 | Y = 1 | Y = 0 | |
| X = 1 | 0.2 | 0.2 | 0.4 | 0.4 | 0.4 | 0.1 | 0.1 | 0.3 |
| X = 0 | 0.3 | 0.3 | 0.1 | 0.1 | 0.1 | 0.4 | 0.2 | 0.4 |
Worked example
| Example 1: risk reduction | Example 2: risk increase | |||||
|---|---|---|---|---|---|---|
| Experimental group (E) | Control group (C) | Total | (E) | (C) | Total | |
| Events (E) | EE = 15 | CE = 100 | 115 | EE = 75 | CE = 100 | 175 |
| Non-events (N) | EN = 135 | CN = 150 | 285 | EN = 75 | CN = 150 | 225 |
| Total subjects (S) | ES = EE + EN = 150 | CS = CE + CN = 250 | 400 | ES = 150 | CS = 250 | 400 |
| Event rate (ER) | EER = EE / ES = 0.1, or 10% | CER = CE / CS = 0.4, or 40% | EER = 0.5 (50%) | CER = 0.4 (40%) | ||
| Equation | Variable | Abbr. | Example 1 | Example 2 |
|---|---|---|---|---|
| EER − CER | < 0: absolute risk reduction | ARR | (−)0.3, or (−)30% | N/A |
| > 0: absolute risk increase | ARI | N/A | 0.1, or 10% | |
| (EER − CER) / CER | < 0: relative risk reduction | RRR | (−)0.75, or (−)75% | N/A |
| > 0: relative risk increase | RRI | N/A | 0.25, or 25% | |
| 1 / (EER − CER) | < 0: number needed to treat | NNT | (−)3.33 | N/A |
| > 0: number needed to harm | NNH | N/A | 10 | |
| EER / CER | relative risk | RR | 0.25 | 1.25 |
| (EE / EN) / (CE / CN) | odds ratio | OR | 0.167 | 1.5 |
| EER − CER | attributable risk | AR | (−)0.30, or (−)30% | 0.1, or 10% |
| (RR − 1) / RR | attributable risk percent | ARP | N/A | 20% |
| 1 − RR (or 1 − OR) | preventive fraction | PF | 0.75, or 75% | N/A |
See also
References
- ↑ Cornfield, J (1951). "A Method for Estimating Comparative Rates from Clinical Data. Applications to Cancer of the Lung, Breast, and Cervix". Journal of the National Cancer Institute 11: 1269–1275. PMID 14861651.
- ↑ Mosteller, Frederick (1968). "Association and Estimation in Contingency Tables". Journal of the American Statistical Association (American Statistical Association) 63 (321): 1–28. doi:10.2307/2283825. JSTOR 2283825.
- ↑ Edwards, A.W.F. (1963). "The measure of association in a 2x2 table". Journal of the Royal Statistical Society, Series A (Blackwell Publishing) 126 (1): 109–114. doi:10.2307/2982448. JSTOR 2982448.
- ↑ LaMorte, Wayne W. (May 13, 2013), Case-Control Studies, Boston University School of Public Health, retrieved 2013-09-02
- ↑ Morris and Gardner; Gardner, MJ (1988). "Calculating confidence intervals for relative risks (odds ratios) and standardised ratios and rates". British Medical Journal 296 (6632): 1313–1316. doi:10.1136/bmj.296.6632.1313. PMC 2545775. PMID 3133061.
- ↑ Viera AJ (July 2008). "Odds ratios and risk ratios: what's the difference and why does it matter?". South. Med. J. 101 (7): 730–4. doi:10.1097/SMJ.0b013e31817a7ee4. PMID 18580722.
- 1 2 Zhang J, Yu KF (November 1998). "What's the relative risk? A method of correcting the odds ratio in cohort studies of common outcomes". JAMA 280 (19): 1690–1. doi:10.1001/jama.280.19.1690. PMID 9832001.
- ↑ Robbins AS, Chao SY, Fonseca VP (October 2002). "What's the relative risk? A method to directly estimate risk ratios in cohort studies of common outcomes". Ann Epidemiol 12 (7): 452–4. doi:10.1016/S1047-2797(01)00278-2. PMID 12377421.
- ↑ Nurminen, Markku (1995). "To Use or Not to Use the Odds Ratio in Epidemiologic Analyses?". European Journal of Epidemiology 11 (4): 365–371. doi:10.1007/BF01721219. JSTOR 3582428.
- 1 2 "On the use, misuse and interpretation of odds ratios". Dirk Taeger, Yi Sun, Kurt Straif. 10 August 1998. doi: 10.1136/bmj.316.7136.989 http://www.bmj.com/content/316/7136/989?tab=responses
- 1 2 "Against all odds? Improving the understanding of risk reporting". A'Court, Christine; Stevens, Richard; Heneghan, Carl. British Journal of General Practice, Volume 62, Number 596, March 2012, pp. e220-e223(4). doi:10.3399/bjgp12X630223
- ↑ Nijsten T, Rolstad T, Feldman SR, Stern RS. Members of the national psoriasis foundation: more extensive disease and better informed about treatment options. Archives of Dermatology 2005;141(1): 19–26, p24 table 3 and text. http://archderm.ama-assn.org/cgi/reprint/141/1/19.pdf
- ↑ Holcomb WL, Chaiworapongsa T, Luke DA, Burgdorf KD. (2001) "An Odd Measure of Risk: Use and Misuse of the Odds Ratio". Obstetrics and Gynecology, 98(4): 685–688.
- ↑ "The trouble with odds ratios". Thabani Sibanda. 1 May 2003 doi: 10.1136/bmj.316.7136.989 http://www.bmj.com/content/316/7136/989?tab=responses
- ↑ Rothman, Kenneth J.; Greenland, Sander; Lash, Timothy L. (2008). Modern Epidemiology. Lippincott Williams & Wilkins. ISBN 0-7817-5564-6.
External links
- Odds Ratio Calculator – website
- Odds Ratio Calculator with various tests – website
- OpenEpi, a web-based program that calculates the odds ratio, both unmatched and pair-matched
| ||||||||||||||||||||||||||||||||||
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||