Nondeterministic finite automaton
In automata theory, a finite state machine is called a deterministic finite automaton (DFA), if
- each of its transitions is uniquely determined by its source state and input symbol, and
- reading an input symbol is required for each state transition.
A nondeterministic finite automaton (NFA), or nondeterministic finite state machine, does not need to obey these restrictions. In particular, every DFA is also an NFA.
Using the subset construction algorithm, each NFA can be translated to an equivalent DFA, i.e. a DFA recognizing the same formal language.[1] Like DFAs, NFAs only recognize regular languages. Sometimes the term NFA is used in a narrower sense, meaning an automaton that properly violates an above restriction, i.e. that is not a DFA.
NFAs were introduced in 1959 by Michael O. Rabin and Dana Scott,[2] who also showed their equivalence to DFAs. NFAs are used in the implementation of regular expressions: Thompson's construction is an algorithm for compiling a regular expression to an NFA that can efficiently perform pattern matching on strings.
NFAs have been generalized in multiple ways, e.g., nondeterministic finite automaton with ε-moves, finite state transducers, pushdown automata, ω-automata, and probabilistic automata.
Informal introduction
An NFA, similar to a DFA, consumes a string of input symbols. For each input symbol, it transitions to a new state until all input symbols have been consumed. Unlike a DFA, it is non-deterministic, i.e., for some state and input symbol, the next state may be nothing or one or two or more possible states. Thus, in the formal definition, the next state is an element of the power set of the states, which is a set of states to be considered at once. The notion of accepting an input is similar to that for the DFA. When the last input symbol is consumed, the NFA accepts if and only if there is some set of transitions that will take it to an accepting state. Equivalently, it rejects, if, no matter what transitions are applied, it would not end in an accepting state.
Formal definition
An NFA is represented formally by a 5-tuple, (Q, Σ, Δ, q0, F), consisting of
- a finite set of states Q
- a finite set of input symbols Σ
- a transition function Δ : Q × Σ → P(Q).
- an initial (or start) state q0 ∈ Q
- a set of states F distinguished as accepting (or final) states F ⊆ Q.
Here, P(Q) denotes the power set of Q. Let w = a1a2 ... an be a word over the alphabet Σ. The automaton M accepts the word w if a sequence of states, r0,r1, ..., rn, exists in Q with the following conditions:
- r0 = q0
- ri+1 ∈ Δ(ri, ai+1), for i = 0, ..., n−1
- rn ∈ F.
In words, the first condition says that the machine starts in the start state q0. The second condition says that given each character of string w, the machine will transition from state to state according to the transition function Δ. The last condition says that the machine accepts w if the last input of w causes the machine to halt in one of the accepting states. In order for w being accepted by M it is not required that every state sequence ends in an accepting state, it is sufficient if one does. Otherwise, i.e. if it is impossible at all to get from q0 to a state from F by following w, it is said that the automaton rejects the string. The set of strings M accepts is the language recognized by M and this language is denoted by L(M).
We can also define L(M) in terms of Δ*: Q × Σ* → P(Q) such that:
- Δ*(r, ε)= {r} where ε is the empty string, and
- If x ∈ Σ*, a ∈ Σ, and Δ*(r, x)={r1, r2,..., rk} then Δ*(r, xa)= Δ(r1, a)∪...∪Δ(rk, a).
Now L(M) = {w | Δ*(q0, w) ∩ F ≠ ∅}.
Note that there is a single initial state, which is not necessary. Sometimes, NFAs are defined with a set of initial states. There is an easy construction that translates a NFA with multiple initial states to a NFA with single initial state, which provides a convenient notation.
For a more elementary introduction of the formal definition see automata theory.
Example
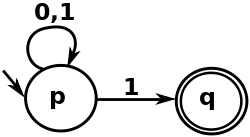
Let M be a NFA, with a binary alphabet, that determines if the input ends with a 1.
In formal notation, let M = ({p, q}, {0, 1}, Δ, p, {q}) where the transition function Δ can be defined by this state transition table:
Note that Δ(p,1) has more than one state therefore M is nondeterministic. The language of M can be described by the regular language given by the regular expression (0|1)*1. Some possible state sequences for the input word "1011" are:
| Input: | 1 | 0 | 1 | 1 | |||||
|---|---|---|---|---|---|---|---|---|---|
| State sequence 1: | p | q | ? | ||||||
| State sequence 2: | p | p | p | q | ? | ||||
| State sequence 3: | p | p | p | p | q |
The word is accepted by M since state sequence 3 satisfies the above definition; it doesn't matter that sequences 1 and 2 fail to do so. In contrast, the word "10" is rejected by M, since there is no way to reach the only accepting state, q, by reading the final 0 symbol or by an ε-transition.
Variations of NFA
- Deterministic finite automaton (DFA): In this automaton, for each state and alphabet, the transition function has exactly one state.
- Nondeterministic finite automaton with ε-moves(NFA-ε): This automaton replaces the transition function with the one that allows the empty string ε as a possible input, so the transition function is defined as Δ : Q × (Σ ∪{ε}) → P(Q).
Equivalence to DFA
For each NFA, there is a DFA such that both recognize the same formal language. The DFA can be constructed using the powerset construction. It is important in theory because it establishes that NFAs, despite their additional flexibility, are unable to recognize any language that cannot be recognized by some DFA. It is also important in practice for converting easier-to-construct NFAs into more efficiently executable DFAs. However, if the NFA has n states, the resulting DFA may have up to 2n states, an exponentially larger number, which sometimes makes the construction impractical for large NFAs.
Closure properties

NFAs are said to be closed under a (binary/unary) operator if NFAs recognize the languages that are obtained by applying the operation on the NFA recognizable languages. The NFAs are closed under the following operations.
- Union (cf. picture)
- Intersection
- Concatenation
- Negation
- Kleene closure
Since NFAs are equivalent to nondeterministic finite automaton with ε-moves(NFA-ε), the above closures are proved using closure properties of NFA-ε. The above closure properties imply that NFAs only recognize regular languages.
NFAs can be constructed from any regular expression using Thompson's construction algorithm.
Properties
The machine starts in the specified initial state and reads in a string of symbols from its alphabet. The automaton uses the state transition function Δ to determine the next state using the current state, and the symbol just read or the empty string. However, "the next state of an NFA depends not only on the current input event, but also on an arbitrary number of subsequent input events. Until these subsequent events occur it is not possible to determine which state the machine is in".[3] If, when the automaton has finished reading, it is in an accepting state, the NFA is said to accept the string, otherwise it is said to reject the string.
The set of all strings accepted by an NFA is the language the NFA accepts. This language is a regular language.
For every NFA a deterministic finite automaton (DFA) can be found that accepts the same language. Therefore it is possible to convert an existing NFA into a DFA for the purpose of implementing a (perhaps) simpler machine. This can be performed using the powerset construction, which may lead to an exponential rise in the number of necessary states. For a formal proof of the powerset construction, please see the Powerset construction article.
Implementation
There are many ways to implement a NFA:
- Convert to the equivalent DFA. In some cases this may cause exponential blowup in the number of states.[4]
- Keep a set data structure of all states which the NFA might currently be in. On the consumption of an input symbol, unite the results of the transition function applied to all current states to get the set of next states; if ε-moves are allowed, include all states reachable by such a move (ε-closure). Each step requires at most s2 computations, where s is the number of states of the NFA. On the consumption of the last input symbol, if one of the current states is a final state, the machine accepts the string. A string of length n can be processed in time O(ns2),[5] and space O(s).
- Create multiple copies. For each n way decision, the NFA creates up to
 copies of the machine. Each will enter a separate state. If, upon consuming the last input symbol, at least one copy of the NFA is in the accepting state, the NFA will accept. (This, too, requires linear storage with respect to the number of NFA states, as there can be one machine for every NFA state.)
copies of the machine. Each will enter a separate state. If, upon consuming the last input symbol, at least one copy of the NFA is in the accepting state, the NFA will accept. (This, too, requires linear storage with respect to the number of NFA states, as there can be one machine for every NFA state.) - Explicitly propagate tokens through the transition structure of the NFA and match whenever a token reaches the final state. This is sometimes useful when the NFA should encode additional context about the events that triggered the transition. (For an implementation that uses this technique to keep track of object references have a look at Tracematches.[6])
Application of NFA
NFAs and DFAs are equivalent in that if a language is recognized by an NFA, it is also recognized by a DFA and vice versa. The establishment of such equivalence is important and useful. It is useful because constructing an NFA to recognize a given language is sometimes much easier than constructing a DFA for that language. It is important because NFAs can be used to reduce the complexity of the mathematical work required to establish many important properties in the theory of computation. For example, it is much easier to prove closure properties of regular languages using NFAs than DFAs.
See also
Notes
- ↑ Martin, John (2010). Introduction to Languages and the Theory of Computation. McGraw Hill. p. 108. ISBN 978-0071289429.
- ↑ Rabin, M. O.; Scott, D. (April 1959). "Finite Automata and Their Decision Problems" (PDF, IEEE Xplore access required). IBM Journal of Research and Development 3 (2): 114–125. doi:10.1147/rd.32.0114. Retrieved 2007-03-15.
- ↑ FOLDOC Free Online Dictionary of Computing, Finite State Machine
- ↑ http://cseweb.ucsd.edu/~ccalabro/essays/fsa.pdf
- ↑ John E. Hopcroft and Rajeev Motwani and Jeffrey D. Ullman (2003). Introduction to Automata Theory, Languages, and Computation. Upper Saddle River/NJ: Addison Wesley. Here: sect.4.3.3 Testing Membership in a Regular Language, p.153
- ↑ Allan, C., Avgustinov, P., Christensen, A. S., Hendren, L., Kuzins, S., Lhoták, O., de Moor, O., Sereni, D., Sittampalam, G., and Tibble, J. 2005. Adding trace matching with free variables to AspectJ. In Proceedings of the 20th Annual ACM SIGPLAN Conference on Object Oriented Programming, Systems, Languages, and Applications (San Diego, CA, USA, October 16–20, 2005). OOPSLA '05. ACM, New York, NY, 345-364.
References
- M. O. Rabin and D. Scott, "Finite Automata and their Decision Problems", IBM Journal of Research and Development, 3:2 (1959) pp. 115–125.
- Michael Sipser, Introduction to the Theory of Computation. PWS, Boston. 1997. ISBN 0-534-94728-X. (see section 1.2: Nondeterminism, pp.47–63.)
- John E. Hopcroft and Jeffrey D. Ullman, Introduction to Automata Theory, Languages, and Computation, Addison-Wesley Publishing, Reading Massachusetts, 1979. ISBN 0-201-02988-X. (See chapter 2.)
| |||||||||||||||||||