Misuse of statistics
Statistics are supposed to make something easier to understand but when used in a misleading fashion can trick the casual observer into believing something other than what the data shows. That is, a misuse of statistics occurs when a statistical argument asserts a falsehood. In some cases, the misuse may be accidental. In others, it is purposeful and for the gain of the perpetrator. When the statistical reason involved is false or misapplied, this constitutes a statistical fallacy.
The false statistics trap can be quite damaging to the quest for knowledge. For example, in medical science, correcting a falsehood may take decades and cost lives.
Misuses can be easy to fall into. Professional scientists, even mathematicians and professional statisticians, can be fooled by even some simple methods, even if they are careful to check everything. Scientists have been known to fool themselves with statistics due to lack of knowledge of probability theory and lack of standardization of their tests.
Importance
Statistics may be a principled means of debate with opportunities for agreement,[1][2] but this is true only if the parties agree to a set of rules. Misuses of statistics violate the rules.
Or to put it another way:
False facts are highly injurious to the progress of science, for they often long endure; but false views, if supported by some evidence, do little harm, as every one takes a salutary pleasure in proving their falseness; and when this is done, one path towards error is closed and the road to truth is often at the same time opened.
— Charles Darwin, The Descent of Man (1871), Vol. 2, 385.
Definition, limitations and context
One usable definition is: "Misuse of Statistics: Using numbers in such a manner that - either by intent, or through ignorance or carelessness - the conclusions are unjustified or incorrect."[3] The "numbers" include misleading graphics discussed elsewhere. The term is not commonly encountered in statistics texts and no authoritative definition is known. It is a generalization of lying with statistics which was richly described by examples from statisticians 60 years ago.
The definition confronts some problems (some are addressed by the source):[4]
- Statistics usually produces probabilities; conclusions are provisional
- The provisional conclusions have errors and error rates. Commonly 5% of the provisional conclusions of significance testing are wrong
- Statisticians are not in complete agreement on ideal methods
- Statistical methods are based on assumptions which are seldom fully met
- Data gathering is usually limited by ethical, practical and financial constraints.
How to Lie with Statistics acknowledges that statistics can legitimately take many forms. Whether the statistics show that a product is "light and economical" or "flimsy and cheap" can be debated whatever the numbers. Some object to the substitution of statistical correctness for moral leadership (for example) as an objective. Assigning blame for misuses is often difficult because scientists, pollsters, statisticians and reporters are often employees or consultants.
An insidious misuse(?) of statistics is completed by the listener/observer/audience/juror. The supplier provides the "statistics" as numbers or graphics (or before/after photographs), allowing the consumer to draw (possibly unjustified or incorrect) conclusions. The poor state of public statistical literacy and the non-statistical nature of human intuition permits misleading without explicitly producing faulty conclusions. The definition is weak on the responsibility of the consumer of statistics.
A historian listed over 100 fallacies in a dozen categories including those of generalization and those of causation.[5] A few of the fallacies are explicitly or potentially statistical including sampling, statistical nonsense, statistical probability, false extrapolation, false interpolation and insidious generalization. All of the technical/mathematical problems of applied probability would fit in the single listed fallacy of statistical probability. Many of the fallacies could be coupled to a statistical analysis, allowing the possibility of a false conclusion flowing from a blameless statistical analysis.
An example use of statistics is in the analysis of medical research. The process includes[6][7] experimental planning, conduct of the experiment, data analysis, drawing the logical conclusions and presentation/reporting. The report is summarized by the popular press and by advertisers. Misuses of statistics can result from problems at any step in the process. The statistical standards ideally imposed on the scientific report are much different than those imposed on the popular press and advertisers; however, cases exist of advertising disguised as science. The definition of the misuse of statistics is weak on the required completeness of statistical reporting. The opinion is expressed that newspapers must provide at least the source for the statistics reported.
Simple causes
Many misuses of statistics occur because
- The source is a subject matter expert, not a statistics expert.[8] The source may incorrectly use a method or interpret a result.
- The source is a statistician, not a subject matter expert.[9] An expert should know when the numbers being compared describe different things. Numbers change, as reality does not, when legal definitions or political boundaries change.
- The subject being studied is not well defined.[10] While IQ tests are available and numeric it is difficult to define what they measure; Intelligence is an elusive concept. Publishing "impact" has the same problem.[11] A seemingly simple question about the number of words in the English language immediately encounters questions about archaic forms, accounting for prefixes and suffixes, multiple definitions of a word, variant spellings, dialects, fanciful creations (like ectoplastistics from ectoplasm and statistics),[12] technical vocabulary...
- Data quality is poor.[13] Apparel provides an example. People have a wide range of sizes and body shapes. It is obvious that apparel sizing must be multidimensional. Instead it is complex in unexpected ways. Some apparel is sold by size only (with no explicit consideration of body shape), sizes vary by country and manufacturer and some sizes are deliberately misleading. While sizes are numeric, only the crudest of statistical analyses is possible using the size numbers with care.
- The popular press has limited expertise and mixed motives.[14] If the facts are not "newsworthy" (which may require exaggeration) they may not be published. The motives of advertisers are even more mixed.
- "Politicians use statistics in the same way that a drunk uses lamp-posts—for support rather than illumination" - Andrew Lang (WikiQuote) "What do we learn from these two ways of looking at the same numbers? We learn that that a clever propagandist, right or left, can almost always find a way to present the data on economic growth that seems to support her case. And we therefore also learn to take any statistical analysis from a strongly political source with handfuls of salt."[15] The term statistics originates from numbers generated for and utilized by the state. Good government may require accurate numbers, but popular government may require supportive numbers (not necessarily the same). "The use and misuse of statistics by governments is an ancient art."[16]
Types of misuse
Discarding unfavorable data
All a company has to do to promote a neutral (useless) product is to find or conduct, for example, 40 studies with a confidence level of 95%. If the product is really useless, this would on average produce one study showing the product was beneficial, one study showing it was harmful and thirty-eight inconclusive studies (38 is 95% of 40). This tactic becomes more effective the more studies there are available. Organizations that do not publish every study they carry out, such as tobacco companies denying a link between smoking and cancer, anti-smoking advocacy groups and media outlets trying to prove a link between smoking and various ailments, or miracle pill vendors, are likely to use this tactic.
Ronald Fisher considered this issue in his famous Lady tasting tea example experiment (from his 1935 book, The Design of Experiments). Regarding repeated experiments he said, "It would clearly be illegitimate, and would rob our calculation of its basis, if unsuccessful results were not all brought into the account."
Another term related to this concept is cherry picking.
Loaded questions
The answers to surveys can often be manipulated by wording the question in such a way as to induce a prevalence towards a certain answer from the respondent. For example, in polling support for a war, the questions:
- Do you support the attempt by the USA to bring freedom and democracy to other places in the world?
- Do you support the unprovoked military action by the USA?
will likely result in data skewed in different directions, although they are both polling about the support for the war. A better way of wording the question could be "Do you support the current US military action abroad?" A still more nearly neutral way to put that question is "What is your view about the current US military action abroad?" The point should be that the person being asked has no way of guessing from the wording what the questioner might want to hear.
Another way to do this is to precede the question by information that supports the "desired" answer. For example, more people will likely answer "yes" to the question "Given the increasing burden of taxes on middle-class families, do you support cuts in income tax?" than to the question "Considering the rising federal budget deficit and the desperate need for more revenue, do you support cuts in income tax?"
The proper formulation of questions can be very subtle. The responses to two questions can vary dramatically depending on the order in which they are asked.[17] "A survey that asked about 'ownership of stock' found that most Texas ranchers owned stock, though probably not the kind traded on the New York Stock Exchange."[18]
Overgeneralization
Overgeneralization is a fallacy occurring when a statistic about a particular population is asserted to hold among members of a group for which the original population is not a representative sample.
For example, suppose 100% of apples are observed to be red in summer. The assertion "All apples are red" would be an instance of overgeneralization because the original statistic was true only of a specific subset of apples (those in summer), which is not expected to be representative of the population of apples as a whole.
A real-world example of the overgeneralization fallacy can be observed as an artifact of modern polling techniques, which prohibit calling cell phones for over-the-phone political polls. As young people are more likely than other demographic groups to lack a conventional "landline" phone, a telephone poll that exclusively surveys responders of calls landline phones, may cause the poll results to undersample the views of young people, if no other measures are taken to account for this skewing of the sampling. Thus, a poll examining the voting preferences of young people using this technique may not be a perfectly accurate representation of young peoples' true voting preferences as a whole without overgeneralizing, because the sample used excludes young people that carry only cell phones, who may or may not have voting preferences that differ from the rest of the population.
Overgeneralization often occurs when information is passed through nontechnical sources, in particular mass media.
Biased samples
Scientists have learned at great cost that gathering good experimental data for statistical analysis is difficult. Example: The placebo effect (mind over body) is very powerful. 100% of subjects developed a rash when exposed to an inert substance that was falsely called poison ivy while few developed a rash to a "harmless" object that really was poison ivy.[19] Researchers combat this effect by double-blind randomized comparative experiments. Statisticians typically worry more about the validity of the data than the analysis. This is reflected in a field of study within statistics known as the design of experiments.
Pollsters have learned at great cost that gathering good survey data for statistical analysis is difficult. The selective effect of cellular telephones on data collection (discussed in the Overgeneralization section) is one potential example; If young people with traditional telephones are not representative, the sample can be biased. Sample surveys have many pitfalls and require great care in execution.[20] One effort required almost 3000 telephone calls to get 1000 answers. The simple random sample of the population "isn't simple and may not be random."[21]
Misreporting or misunderstanding of estimated error
If a research team wants to know how 300 million people feel about a certain topic, it would be impractical to ask all of them. However, if the team picks a random sample of about 1000 people, they can be fairly certain that the results given by this group are representative of what the larger group would have said if they had all been asked.
This confidence can actually be quantified by the central limit theorem and other mathematical results. Confidence is expressed as a probability of the true result (for the larger group) being within a certain range of the estimate (the figure for the smaller group). This is the "plus or minus" figure often quoted for statistical surveys. The probability part of the confidence level is usually not mentioned; if so, it is assumed to be a standard number like 95%.
The two numbers are related. If a survey has an estimated error of ±5% at 95% confidence, it also has an estimated error of ±6.6% at 99% confidence. ± % at 95% confidence is always ±
% at 95% confidence is always ±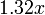 % at 99% confidence for a normally distributed population.
% at 99% confidence for a normally distributed population.
The smaller the estimated error, the larger the required sample, at a given confidence level.
at 95.4% confidence:
±1% would require 10,000 people.
±2% would require 2,500 people.
±3% would require 1,111 people.
±4% would require 625 people.
±5% would require 400 people.
±10% would require 100 people.
±20% would require 25 people.
±25% would require 16 people.
±50% would require 4 people.
People may assume, because the confidence figure is omitted, that there is a 100% certainty that the true result is within the estimated error. This is not mathematically correct.
Many people may not realize that the randomness of the sample is very important. In practice, many opinion polls are conducted by phone, which distorts the sample in several ways, including exclusion of people who do not have phones, favoring the inclusion of people who have more than one phone, favoring the inclusion of people who are willing to participate in a phone survey over those who refuse, etc. Non-random sampling makes the estimated error unreliable.
On the other hand, people may consider that statistics are inherently unreliable because not everybody is called, or because they themselves are never polled. People may think that it is impossible to get data on the opinion of dozens of millions of people by just polling a few thousands. This is also inaccurate.[lower-alpha 1] A poll with perfect unbiased sampling and truthful answers has a mathematically determined margin of error, which only depends on the number of people polled.
However, often only one margin of error is reported for a survey. When results are reported for population subgroups, a larger margin of error will apply, but this may not be made clear. For example, a survey of 1000 people may contain 100 people from a certain ethnic or economic group. The results focusing on that group will be much less reliable than results for the full population. If the margin of error for the full sample was 4%, say, then the margin of error for such a subgroup could be around 13%.
There are also many other measurement problems in population surveys.
The problems mentioned above apply to all statistical experiments, not just population surveys.
False causality
When a statistical test shows a correlation between A and B, there are usually six possibilities:
- A causes B.
- B causes A.
- A and B both partly cause each other.
- A and B are both caused by a third factor, C.
- B is caused by C which is correlated to A.
- The observed correlation was due purely to chance.
The sixth possibility can be quantified by statistical tests that can calculate the probability that the correlation observed would be as large as it is just by chance if, in fact, there is no relationship between the variables. However, even if that possibility has a small probability, there are still the five others.
If the number of people buying ice cream at the beach is statistically related to the number of people who drown at the beach, then nobody would claim ice cream causes drowning because it's obvious that it isn't so. (In this case, both drowning and ice cream buying are clearly related by a third factor: the number of people at the beach).
This fallacy can be used, for example, to prove that exposure to a chemical causes cancer. Replace "number of people buying ice cream" with "number of people exposed to chemical X", and "number of people who drown" with "number of people who get cancer", and many people will believe you. In such a situation, there may be a statistical correlation even if there is no real effect. For example, if there is a perception that a chemical site is "dangerous" (even if it really isn't) property values in the area will decrease, which will entice more low-income families to move to that area. If low-income families are more likely to get cancer than high-income families (this can happen for many reasons, such as a poorer diet or less access to medical care) then rates of cancer will go up, even though the chemical itself is not dangerous. It is believed[24] that this is exactly what happened with some of the early studies showing a link between EMF (electromagnetic fields) from power lines and cancer.[25]
In well-designed studies, the effect of false causality can be eliminated by assigning some people into a "treatment group" and some people into a "control group" at random, and giving the treatment group the treatment and not giving the control group the treatment. In the above example, a researcher might expose one group of people to chemical X and leave a second group unexposed. If the first group had higher cancer rates, the researcher knows that there is no third factor that affected whether a person was exposed because he controlled who was exposed or not, and he assigned people to the exposed and non-exposed groups at random. However, in many applications, actually doing an experiment in this way is either prohibitively expensive, infeasible, unethical, illegal, or downright impossible. For example, it is highly unlikely that an IRB would accept an experiment that involved intentionally exposing people to a dangerous substance in order to test its toxicity. The obvious ethical implications of such types of experiments limit researchers' ability to empirically test causation.
Proof of the null hypothesis
In a statistical test, the null hypothesis (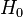 ) is considered valid until enough data proves it wrong. Then is rejected and the alternative hypothesis (
) is considered valid until enough data proves it wrong. Then is rejected and the alternative hypothesis (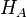 ) is considered to be proven as correct. By chance this can happen, although is true, with a probability denoted alpha, the significance level. This can be compared to the judicial process, where the accused is considered innocent () until proven guilty () beyond reasonable doubt (alpha).
) is considered to be proven as correct. By chance this can happen, although is true, with a probability denoted alpha, the significance level. This can be compared to the judicial process, where the accused is considered innocent () until proven guilty () beyond reasonable doubt (alpha).
But if data does not give us enough proof to reject that , this does not automatically prove that is correct. If, for example, a tobacco producer wishes to demonstrate that its products are safe, it can easily conduct a test with a small sample of smokers versus a small sample of non-smokers. It is unlikely that any of them will develop lung cancer (and even if they do, the difference between the groups has to be very big in order to reject ). Therefore, it is likely—even when smoking is dangerous—that our test will not reject . If is accepted, it does not automatically follow that smoking is proven harmless. The test has insufficient power to reject , so the test is useless and the value of the "proof" of is also null.
This can—using the judicial analogue above—be compared with the truly guilty defendant who is released just because the proof is not enough for a guilty verdict. This does not prove the defendant's innocence, but only that there is not proof enough for a guilty verdict.
"...the null hypothesis is never proved or established, but it is possibly disproved, in the course of experimentation. Every experiment may be said to exist only in order to give the facts a chance of disproving the null hypothesis." (Fisher in The Design of Experiments) Many reasons for confusion exist including the use of double negative logic and terminology resulting from the merger of Fisher's "significance testing" (where the null hypothesis is never accepted) with "hypothesis testing" (where some hypothesis is always accepted).
Confusing statistical significance with practical significance
Statistical significance is a measure of probability; practical significance is a measure of effect.[26] A baldness cure is statistically significant if a sparse peach-fuzz usually covers the previously naked scalp. The cure is practically significant when a hat is no longer required in cold weather and the barber asks how much to take off the top. The bald want a cure that is both statistically and practically significant; It will probably work and if it does, it will have a big hairy effect. Scientific publication often requires only statistical significance. This has led to complaints (for the last 50 years) that statistical significance testing is a misuse of statistics.[27]
Data dredging
Data dredging is an abuse of data mining. In data dredging, large compilations of data are examined in order to find a correlation, without any pre-defined choice of a hypothesis to be tested. Since the required confidence interval to establish a relationship between two parameters is usually chosen to be 95% (meaning that there is a 95% chance that the relationship observed is not due to random chance), there is a thus a 5% chance of finding a correlation between any two sets of completely random variables. Given that data dredging efforts typically examine large datasets with many variables, and hence even larger numbers of pairs of variables, spurious but apparently statistically significant results are almost certain to be found by any such study.
Note that data dredging is a valid way of finding a possible hypothesis but that hypothesis must then be tested with data not used in the original dredging. The misuse comes in when that hypothesis is stated as fact without further validation.
"You cannot legitimately test a hypothesis on the same data that first suggested that hypothesis. The remedy is clear. Once you have a hypothesis, design a study to search specifically for the effect you now think is there. If the result of this test is statistically significant, you have real evidence at last."[28]
Data manipulation
Informally called "fudging the data," this practice includes selective reporting (see also publication bias) and even simply making up false data.
Examples of selective reporting abound. The easiest and most common examples involve choosing a group of results that follow a pattern consistent with the preferred hypothesis while ignoring other results or "data runs" that contradict the hypothesis.
Psychic researchers have long disputed studies showing people with ESP ability. Critics accuse ESP proponents of only publishing experiments with positive results and shelving those that show negative results. A "positive result" is a test run (or data run) in which the subject guesses a hidden card, etc., at a much higher frequency than random chance.
Scientists, in general, question the validity of study results that cannot be reproduced by other investigators. However, some scientists refuse to publish their data and methods.[29]
Data manipulation is a serious issue/consideration in the most honest of statistical analyses. Outliers, missing data and non-normality can all adversely affect the validity of statistical analysis. It is appropriate to study the data and repair real problems before analysis begins. "[I]n any scatter diagram there will be some points more or less detached from the main part of the cloud: these points should be rejected only for cause."[30]
Other fallacies
Pseudoreplication is a technical error associated with analysis of variance. Complexity hides the fact that statistical analysis is being attempted on a single sample (N=1). For this degenerate case the variance cannot be calculated (division by zero).
The gambler's fallacy assumes that an event for which a future likelihood can be measured had the same likelihood of happening once it has already occurred. Thus, if someone had already tossed 9 coins and each has come up heads, people tend to assume that the likelihood of a tenth toss also being heads is 1023 to 1 against (which it was before the first coin was tossed) when in fact the chance of the tenth head is 50% (assuming the coin is unbiased).
The prosecutor's fallacy[31] has led, in the UK, to the false imprisonment of women for murder when the courts were given the prior statistical likelihood of a woman's 3 children dying from Sudden Infant Death Syndrome as being the chances that their already dead children died from the syndrome. This led to statements from Roy Meadow that the chance they had died of Sudden Infant Death Syndrome were extremely small (one in millions). The courts then handed down convictions in spite of the statistical inevitability that a few women would suffer this tragedy. The convictions were eventually overturned (and Meadow was subsequently struck off the U.K. Medical Register for giving “erroneous” and “misleading” evidence, although this was later reversed by the courts).[32] Meadow's calculations were irrelevant to these cases, but even if they were, using the same methods of calculation would have shown that the odds against two cases of infanticide were even smaller (one in billions).[32]
The ludic fallacy. Probabilities are based on simple models that ignore real (if remote) possibilities. Poker players do not consider that an opponent may draw a gun rather than a card. The insured (and governments) assume that insurers will remain solvent, but see AIG and systemic risk.
Other types of misuse
Other misuses include comparing apples and oranges, using the wrong average,[33] regression toward the mean,[34] and the umbrella phrase garbage in, garbage out.[35] Some statistics are simply irrelevant to an issue.[36]
See also
- Misleading graph, discusses problems arising from graphical presentations.
- Deception
- Numbers Guy weekly column in The Wall Street Journal by Carl Bialik
References
Notes
- ↑ Some data on accuracy of polls is available. Regarding one important poll by the U.S. government, "Relatively speaking, both sampling error and non-sampling [bias] error are tiny."[22] The difference between the votes predicted by one private poll and the actually tally for American presidential elections is available for comparison at "Election Year Presidential Preferences: Gallup Poll Accuracy Record: 1936-2012". The predictions were typically calculated on the basis of less than 5000 opinions by likely voters.[23]
Sources
- ↑ Abelson, Robert P. (1995). Statistics as Principled Argument. Lawrence Erlbaum Associates. ISBN 0-8058-0528-1.
... the purpose of statistics is to organize a useful argument from quantitative evidence, using a form of principled rhetoric.
- ↑ Porter, Theodore (1995). Trust in Numbers: The Pursuit of Objectivity in Science and Public Life. Princeton, N.J: Princeton University Press. ISBN 0-691-03776-0. Porter considered the history of cost-benefit analysis. While this is perhaps more economical than statistical, it is a quantitative decision-making technique considered to be in the statistical domain.
- ↑ Spirer, Spirer & Jaffe 1998, p. 1.
- ↑ Gardenier, John; Resnik, David (2002). "The misuse of statistics: concepts, tools, and a research agenda". Accountability in Research: Policies and Quality Assurance 9 (2): 65–74. doi:10.1080/08989620212968. PMID 12625352.
- ↑ Fischer, David (1979). Historians' fallacies: toward a logic of historical thought. New York: Harper & Row. pp. 337–338. ISBN 978-0060904982.
- ↑ Strasak, Alexander M.; Qamruz Zaman; Karl P. Pfeiffer; Georg Göbel; Hanno Ulmer (2007). "Statistical errors in medical research-a review of common pitfalls". Swiss medical weekly 137: 44–49. PMID 17299669. In this article anything less than best statistical practice is equated to the potential misuse of statistics. In a few pages 47 potential statistical errors are discussed; errors in study design, data analysis, documentation, presentation and interpretation. "[S]tatisticians should be involved early in study design, as mistakes at this point can have major repercussions, negatively affecting all subsequent stages of medical research."
- ↑ Indrayan, Abhaya (2007). "Statistical fallacies in orthopedic research". Indian Journal of Orthopaedics 41 (1): 37. doi:10.4103/0019-5413.30524. Contains a rich list of medical misuses of statistics of all types.
- ↑ Spirer, Spirer & Jaffe 1998, chapters 7 & 8.
- ↑ Spirer, Spirer & Jaffe 1998, chapter 3.
- ↑ Spirer, Spirer & Jaffe 1998, chapter 4.
- ↑ Adler, Robert; John Ewing; Peter Taylor (2009). "Citation statistics". Statistical Science 24.1: 1–14. doi:10.1214/09-STS285. Scientific papers and scholarly journals are often rated by "impact" - the number of times cited by later publications. Mathematicians and statisticians conclude that impact (while relatively objective) is not a very meaningful measure. "The sole reliance on citation data provides at best an incomplete and often shallow understanding of research—an understanding that is valid only when reinforced by other judgments. Numbers are not inherently superior to sound judgments."
- ↑ Spirer, Spirer & Jaffe 1998, chapter title.
- ↑ Spirer, Spirer & Jaffe 1998, chapter 5.
- ↑ Weatherburn, Don (November 2011), "Uses and abuses of crime statistics" (PDF), Crime and Justice Bulletin: Contemporary Issues in Crime and Justice (NSW Bureau of Crime Statistics and Research) 153, ISBN 9781921824357, ISSN 1030-1046 This Australian report on crime statistics provides numerous examples of interpreting and misinterpreting the data. "The increase in media access to information about crime has not been matched by an increase in the quality of media reporting on crime. The misuse of crime statistics by the media has impeded rational debate about law and order." Among the alleged media abuses: selective use of data, selective reporting of facts, misleading commentary, misrepresentation of facts and misleading headlines. Police and politicians also abused the statistics.
- ↑ Krugman, Paul (1994). Peddling prosperity: economic sense and nonsense in the age of diminished expectations. New York: W.W. Norton. p. 111. ISBN 0-393-03602-2.
- ↑ Spirer, Spirer & Jaffe 1998.
- ↑ Kahneman 2013, p. 102.
- ↑ Moore & Notz 2006, p. 59.
- ↑ Moore & Notz 2006, p. 97.
- ↑ Moore & McCabe 2003, pp. 252–254.
- ↑ Moore & Notz 2006, p. 53, Sample surveys in the real world.
- ↑ Freedman, Pisani & Purves 1998, chapter 22: Measuring Employment and Unemployment, p. 405.
- ↑ Freedman, Pisani & Purves 1998, pp. 389-390.
- ↑ Farley, John W. (2003). Barrett, Stephen, ed. "Power Lines and Cancer: Nothing to Fear". Quackwatch.
- ↑ Vince, Gaia (2005-06-03). "Large study links power lines to childhood cancer". New Scientist. Cites: Draper, G. (2005). "Childhood cancer in relation to distance from high voltage power lines in England and Wales: a case-control study". BMJ 330 (7503): 1290. doi:10.1136/bmj.330.7503.1290. PMC 558197. PMID 15933351.
- ↑ Moore & McCabe 2003, pp. 463.
- ↑ Rozeboom, William W. (1960). "The fallacy of the null-hypothesis significance test". Psychological Bulletin 57 (5): 416–428. doi:10.1037/h0042040.
- ↑ Moore & McCabe 2003, p. 466.
- ↑ Neylon, C (2009). "Scientists lead the push for open data sharing". Research Information (Europa Science) 41: 22–23. ISSN 1744-8026.
- ↑ Freedman, Pisani & Purves 1998, chapter 9: More about correlations, §3: Some exceptional cases
- ↑ Seife, Charles (2011). Proofiness: how you're being fooled by the numbers. New York: Penguin. pp. 203–205 and Appendix C. ISBN 9780143120070. Discusses the notorious British case.
- 1 2 Michael Kaplan and Ellen Kaplan, Chances Are (Adventures in Probability), Viking Penguin, 2006, pp. 192-5. ISBN 978-0143038344
- ↑ Huff 1954, chapter 2.
- ↑ Kahneman 2013, chapter 17.
- ↑ Hooke 1983, §50.
- ↑ Campbell 1974, chapter 3: Meaningless statistics.
Bibliography
- Campbell, Stephen (1974). Flaws and fallacies in statistical thinking. Prentice Hall. ISBN 0-486-43598-9.
- Christensen, R.; Reichert, T. (1976). "Unit Measure Violations in Pattern Recognition, Ambiguity and Irrelevancy". Pattern Recognition 4: 239–245. doi:10.1016/0031-3203(76)90044-3.
- Ercan I, Yazici B, Yang Y, Ozkaya G, Cangur S, Ediz B, Kan I (2007). "Misusage of Statistics in Medical Researches" (PDF). European Journal of General Medicine 4 (3): 127–133.
- Ercan I, Yazici B, Ocakoglu G, Sigirli D, Kan I (2007). "Review of Reliability and Factors Affecting the Reliability" (PDF). InterStat.
- Freedman, David; Pisani, Robert; Purves, Roger (1998). Statistics (3rd ed.). W.W. Norton. ISBN 978-0-393-97083-8.
- Hooke, Robert (1983). How to tell the liars from the statisticians. New York: M. Dekker. ISBN 0-8247-1817-8.
- Huff, Darrell (1954). How to Lie with Statistics. W. W. Norton & Company. LCCN 53013322. OL 6138576M.
- Kahneman, Daniel (2013). Thinking, fast and slow. New York: Farrar, Straus and Giroux. ISBN 9780374533557.
- Moore, David; McCabe, George P. (2003). Introduction to the practice of statistics (4th ed.). New York: W.H. Freeman and Co. ISBN 0716796570.
- Moore, David; Notz, William I. (2006). Statistics: concepts and controversies (6th ed.). New York: W.H. Freeman. ISBN 9780716786368.
- Spirer, Herbert; Spirer, Louise; Jaffe, A. J. (1998). Misused statistics (revised and expanded 2nd ed.). New York: M. Dekker. ISBN 978-0824702113. The book is based on several hundred examples of misuse.
- Oldberg, T. and R. Christensen (1995) "Erratic Measure" in NDE for the Energy Industry 1995, The American Society of Mechanical Engineers. ISBN 0-7918-1298-7 (pages 1–6) Republished on the Web by ndt.net
- Oldberg, T. (2005) "An Ethical Problem in the Statistics of Defect Detection Test Reliability," Speech to the Golden Gate Chapter of the American Society for Nondestructive Testing. Published on the Web by ndt.net
- Stone, M. (2009) Failing to Figure: Whitehall's Costly Neglect of Statistical Reasoning, Civitas, London. ISBN 1-906837-07-4
Further reading
| Wikimedia Commons has media related to Misuse of statistics. |
| Wikiquote has quotations related to: Misuse of statistics |
- Galbraith, J.; Stone, M. (2011). "The abuse of regression in the National Health Service allocation formulae: Response to the Department of Health's 2007 'resource allocation research paper'". Journal of the Royal Statistical Society, Series A 174 (3): 517–528. doi:10.1111/j.1467-985X.2010.00700.x.