Missing data
In statistics, missing data, or missing values, occur when no data value is stored for the variable in an observation. Missing data are a common occurrence and can have a significant effect on the conclusions that can be drawn from the data.
Missing data can occur because of nonresponse: no information is provided for several items or no information is provided for a whole unit. Some items are more sensitive for nonresponse than others, for example items about private subjects such as income.
Dropout is a type of missingness that occurs mostly when studying development over time. In this type of study the measurement is repeated after a certain period of time. Missingness occurs when participants drop out before the test ends and one or more measurements are missing.
Sometimes missing values are caused by the researcher—for example, when data collection is done improperly or mistakes are made in data entry.[1] Data often are missing in research in economics, sociology, and political science because governments choose not to, or fail to, report critical statistics.[2]
Types of missing data
Understanding the reasons why data are missing can help with analyzing the remaining data. If values are missing at random, the data sample may still be representative of the population. But if the values are missing systematically, analysis may be harder. For example, in a study of the relation between IQ and income, participants with an above-average IQ might tend to skip the question ‘What is your salary?’ Analysis may falsely show no association between IQ and salary, while in fact there may be a relationship. Because of these problems, methodologists routinely advise researchers to design studies to minimize the incidence of missing values.[1]
Missing completely at random
Values in a data set are missing completely at random (MCAR) if the events that lead to any particular data-item being missing are independent both of observable variables and of unobservable parameters of interest, and occur entirely at random.[3] When data are MCAR, the analyses performed on the data are unbiased; however, data are rarely MCAR.
Missing at random
Missing at random (MAR) occurs when the missingness is not random, but where missingness can be fully accounted for by variables where there is complete information.[4] MAR is an assumption that is impossible to verify statistically, we must rely on its substantive reasonableness.[5] An example is that males are less likely to fill in a depression survey but this has nothing to do with their level of depression, after accounting for maleness.
Missing not at random
Missing not at random (MNAR) (also known as nonignorable nonresponse) is data that is neither MAR nor MCAR (i.e. the value of the variable that's missing is related to the reason it's missing).[3] An example is if men failed to fill in a depression survey because of their level of depression.
Graphical models[6][7] can be used to describe the missing data mechanism in detail.
Techniques of dealing with missing data
Missing data reduce the representativeness of the sample and can therefore distort inferences about the population. If it is possible try to think about how to prevent data from missingness before the actual data gathering takes place. For example, in computer questionnaires it is often not possible to skip a question. A question has to be answered, otherwise one cannot continue to the next. So missing values due to the participant are eliminated by this type of questionnaire, though this method may not be permitted by an ethics board overseeing the research. And in survey research, it is common to make multiple efforts to contact each individual in the sample, often sending letters to attempt to persuade those who have decided not to participate to change their minds (Stoop et al. 2010: 161-187). However, such techniques can either help or hurt in terms of reducing the negative inferential effects of missing data, because the kind of people who are willing to be persuaded to participate after initially refusing or not being home are likely to be significantly different from the kinds of people who will still refuse or remain unreachable after additional effort (Stoop et al. 2010: 188-198).
In situations where missing data are likely to occur, the researcher is often advised to plan to use methods of data analysis methods that are robust to missingness. An analysis is robust when we are confident that mild to moderate violations of the technique's key assumptions will produce little or no bias, or distortion in the conclusions drawn about the population.
Imputation
If it is known that the data analysis technique which is to be used isn't content robust, it is good to consider imputing the missing data. This can be done in several ways. Recommended is to use multiple imputations. Rubin (1987) argued that even a small number (5 or fewer) of repeated imputations enormously improves the quality of estimation.[1]
For many practical purposes, 2 or 3 imputations capture most of the relative efficiency that could be captured with a larger number of imputations. However, a too-small number of imputations can lead to a substantial loss of statistical power, and some scholars now recommend 20 to 100 or more.[8] Any multiply-imputed data analysis must be repeated for each of the imputed data sets and, in some cases, the relevant statistics must be combined in a relatively complicated way.[1]
Examples of imputations are listed below.
Partial imputation
The expectation-maximization algorithm is an approach in which values of the statistics which would be computed if a complete dataset were available are estimated (imputed), taking into account the pattern of missing data. In this approach, values for individual missing data-items are not usually imputed.
Partial deletion
Methods which involve reducing the data available to a dataset having no missing values include:
- Listwise deletion/casewise deletion
- Pairwise deletion
Full analysis
Methods which take full account of all information available, without the distortion resulting from using imputed values as if they were actually observed:
- The expectation-maximization algorithm
- full information maximum likelihood estimation
Interpolation
In the mathematical field of numerical analysis, interpolation is a method of constructing new data points within the range of a discrete set of known data points.
Model-Based Techniques
Model based techniques, often using graphs, offer additional tools for testing missing data types (MCAR, MAR, MNAR) and for estimating parameters under missing data conditions. For example, a test for refuting MAR/MCAR reads as follows:
For any three variables X,Y, and Z where Z is fully observed and X and Y partially observed, the data should satisfy:
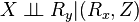 .
.
In words, the observed portion of X should be independent on the missingness status of Y, conditional on every value of Z. Failure to satisfy this condition indicates that the problem belongs to the MNAR category.[9]
(Remark: These tests are necessary for variable-based MAR which is a slight variation of event-based MAR.[10][11][12])
When data falls into MNAR category techniques are available for consistently estimating parameters when certain conditions hold in the model.[6] For example, if Y explains the reason for missingness in X and Y itself has missing values, the joint probability distribution of X and Y can still be estimated if the missingness of Y is random. The estimand in this case will be:
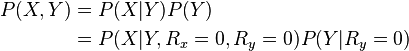
where 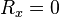 and
and 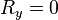 denote the observed portions of their respective variables.
denote the observed portions of their respective variables.
Different model structures may yield different estimands and different procedures of estimation whenever consistent estimation is possible. The preceding estimand calls for first
estimating 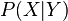 from complete data and multiplying it by
from complete data and multiplying it by  estimated from cases in which Y is observed regardless of the status of X. Moreover, in order to
obtain a consistent estimate it is crucial that the first term be as opposed to
estimated from cases in which Y is observed regardless of the status of X. Moreover, in order to
obtain a consistent estimate it is crucial that the first term be as opposed to 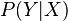 .
.
In many cases model based techniques permit the model structure to undergo refutation tests.[12]
Any model which implies the independence between a partially observed variable X and the missingness indicator of another variable Y (i.e.  ), conditional
on
), conditional
on  can be submitted to the following refutation test:
can be submitted to the following refutation test:
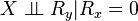 .
.
Finally, the estimands that emerge from these techniques are derived in closed form and do not require iterative procedures such as Expectation Maximization that are susceptible to local optima.[13]
See also
References
- 1 2 3 4 Ader, H.J., Mellenbergh, G.J. 2008
- ↑ Messner SF (1992). "Exploring the Consequences of Erratic Data Reporting for Cross-National Research on Homicide". Journal of Quantitative Criminology 8 (2): 155–173. doi:10.1007/bf01066742.
- 1 2 Polit DF Beck CT (2012). Nursing Research: Generating and Assessing Evidence for Nursing Practice, 9th ed. Philadelphia, USA: Wolters Klower Health, Lippincott Williams & Wilkins.
- ↑ http://missingdata.lshtm.ac.uk/index.php?option=com_content&view=article&id=76%3Amissing-at-random-mar&catid=40%3Amissingness-mechanisms&Itemid=96
- ↑ Little, Roderick (2002). Statistical analysis with missing data. Hoboken, N.J: Wiley. ISBN 978-0471183860.
- 1 2 Mohan, Karthika; Pearl, Judea; Tian, Jin (2013). Advances in Neural Information Processing Systems 26. pp. 1277–1285.
- ↑ Karvanen, Juha (2015). "Study design in causal models". Scandinavian Journal of Statistics 42 (2): 361–377. doi:10.1111/sjos.12110.
- ↑ Graham J.W., Olchowski A.E., Gilreath T.D. (2007). "How Many Imputations Are Really Needed? Some Practical Clarifications of Multiple Imputation Theory". Preventative Science 8 (3): 208–213. doi:10.1007/s11121-007-0070-9.
- ↑ Mohan, Karthika; Pearl, Judea (2014). "On the testability of models with missing data". Proceedings of AISTAT-2014, Forthcoming.
- ↑ Darwiche, Adnan (2009). Modeling and Reasoning with Bayesian Networks. Cambridge University Press.
- ↑ Potthoff, R.F.; Tudor, G.E.; Pieper, K.S.; Hasselblad, V. (2006). "Can one assess whether missing data are missing at random in medical studies?". Statistical Methods in Medical Research 15 (3): 213–234. doi:10.1191/0962280206sm448oa.
- 1 2 Pearl, Judea; Mohan, Karthika (2013). [Available at http://ftp.cs.ucla.edu/pub/stat\_ser/r417.pdf Recoverability and Testability of Missing data: Introduction and Summary of Results] Check
|url= - ↑ Mohan, K.; Van den Broeck, G.; Choi, A.; Pearl, J. (2014). "An Efficient Method for Bayesian Network Parameter Learning from Incomplete Data". Presented at Causal Modeling and Machine learning Workshop, ICML-2014.
- Adèr, H.J. (2008). "Chapter 13: Missing data". In Adèr, H.J., & Mellenbergh, G.J. (Eds.) (with contributions by Hand, D.J.), Advising on Research Methods: A consultant's companion (pp. 305–332). Huizen, The Netherlands: Johannes van Kessel Publishing. ISBN 90-79418-01-3
- Stoop, I., Billiet, J., Koch, A., and Fitzgerald, R. (2010) Improving Survey Response: Lessons Learned from the European Social Survey. Wiley. ISBN 0-470-51669-0
- Zarate LE, Nogueira BM, Santos TRA, Song MAJ (2006). "Techniques for Missing Value Recovering in Imbalanced Databases: Application in a Marketing Database with Massive Missing Data". IEEE International Conference on Systems, Man and Cybernetics, 2006. SMC '06. pp. 2658–64. doi:10.1109/ICSMC.2006.385265.
Further reading
- Rubin, Donald B.; Little, Roderick J. A. (2002). Statistical analysis with missing data (2nd ed.). New York: Wiley. ISBN 0-471-18386-5.
- Enders, Craig K. (2010). Applied Missing Data Analysis (1st ed.). New York: Guildford Press. ISBN 978-1-60623-639-0.
- Allison, Paul D. (2001). Missing Data (1st ed.). Thousand Oaks: Sage Publications, Inc. ISBN 978-0-7619-1672-7.
- Acock AC (2005). "'Working With Missing Values". Journal of Marriage and Family 67 (4): 1012–28. doi:10.1111/j.1741-3737.2005.00191.x.
- Van den Broeck J, Cunningham SA, Eeckels R, Herbst K (October 2005). "Data cleaning: detecting, diagnosing, and editing data abnormalities". PLoS Med. 2 (10): e267. doi:10.1371/journal.pmed.0020267. PMC 1198040. PMID 16138788.
- Schafer, J. L.; Graham, J. W. (2002). "Missing data: Our view of the state of the art". Psychological Methods 7 (2): 147–177. doi:10.1037/1082-989X.7.2.147. PMID 12090408.
- Graham, John W. (2009). "Missing Data Analysis: Making It Work in the Real World". Annual Review of Psychology 60: 549–576. doi:10.1146/annurev.psych.58.110405.085530.
- Rubin DB (1976). "Inference and missing data". Biometrika 63 (3): 581–92. doi:10.1093/biomet/63.3.581.
External links
Background
- Missing values-envision
- psychwiki.com: Missing Values, Identifying Missing Values, and Dealing with Missing Values
- missingdata.org.uk, Department of Medical Statistics, London School of Hygiene & Tropical Medicine