Mildly context-sensitive grammar formalism
In computational linguistics, the term mildly context-sensitive grammar formalisms refers to several grammar formalisms that have been developed with the ambition to provide adequate descriptions of the syntactic structure of natural language.
Every mildly context-sensitive grammar formalism defines a class of mildly context-sensitive grammars (the grammars that can be specified in the formalism), and therefore also a class of mildly context-sensitive languages (the formal languages generated by the grammars).
Background
By 1985, several researchers in descriptive and mathematical linguistics had provided evidence against the hypothesis that the syntactic structure of natural language can be adequately described by context-free grammars.[1][2] At the same time, the step to the next level of the Chomsky hierarchy, to context-sensitive grammars, appeared both unnecessary and undesirable. In an attempt to pinpoint the exact formal power required for the adequate description of natural language syntax, Aravind Joshi characterized ‘grammars (and associated languages) that are only slightly more powerful than context-free grammars (context-free languages)’.[3] He called these grammars mildly context-sensitive grammars and the associated languages mildly context-sensitive languages.
Joshi’s characterization of mildly context-sensitive grammars was biased toward his work on tree-adjoining grammar (TAG). However, together with his students Vijay Shanker and David Weir, Joshi soon discovered that TAGs are equivalent, in terms of the generated string languages, to the independently introduced head grammar (HG).[4] This was followed by two similar equivalence results, for linear indexed grammar (LIG)[5] and combinatory categorial grammar (CCG),[6] which showed that the notion of mildly context-sensitivity is a very general one and not tied to a specific formalism.
The TAG-equivalent formalisms were generalized by the introduction of linear context-free rewriting systems (LCFRS).[7][8] These grammars define an infinite hierarchy of string languages in between the context-free and the context-sensitive languages, with the languages generated by the TAG-equivalent formalisms at the lower end of the hierarchy. Independently of and almost simultaneously to LCFRS, Hiroyuki Seki et al. proposed the essentially identical formalism of multiple context-free grammar (MCFG).[9] LCFRS/MCFG is sometimes regarded as the most general formalism for specifying mildly context-sensitive grammars. However, several authors have noted that some of the characteristic properties of the TAG-equivalent formalisms are not preserved by LCFRS/MCFG,[10] and that there are languages that have the characteristic properties of mildly context-sensitivity but are not generated by LCFRS/MCFG.[11]
Recent years have seen increased interest in the restricted class of well-nested linear context-free rewriting systems/multiple context-free grammars,[10][12] which define a class of grammars that properly includes the TAG-equivalent formalisms but is properly included in the unrestricted LCFRS/MCFG hierarchy.
Characterization
Despite a considerable amount of work on the subject, there is no generally accepted formal definition of mild context-sensitivity.
According to the original characterization by Joshi,[3] a class of mildly context-sensitive grammars should have the following properties:
- limited cross-serial dependencies
- constant growth
- polynomial parsing
In addition to these, it is understood that every class of mildly context-sensitive grammars should be able to generate all context-free languages.
Joshi’s characterization is not a formal definition. He notes:[3]
| “ |
This is only a rough characterization because conditions 1 and 3 depend on the grammars, while condition 2 depends on the languages; further, condition 1 needs to be specified much more precisely than I have done so far. |
” |
Other authors have proposed alternative characterizations of mild context-sensitivity, some of which take the form of formal definitions. For example, Laura Kallmeyer[13] takes the perspective that mild context-sensitivity should be defined as a property of classes of languages rather than, as in Joshi’s characterization, classes of grammars. Such a language-based definition leads to a different notion of the concept than Joshi’s.
Cross-serial dependencies
The term cross-serial dependencies refers to certain characteristic word ordering patterns, in particular to the verb–argument patterns observed in subordinate clauses in Dutch[1] and Swiss German.[2] These are the very patterns that can be used to argue against the context-freeness of natural language; thus requiring mildly context-sensitive grammars to model cross-serial dependencies means that these grammars must be more powerful than context-free grammars.
Kallmeyer[13] identifies the ability to model cross-serial dependencies with the ability to generate the copy language
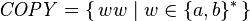
and its generalizations to two or more copies of w, up to some bound. These languages are not context-free, which can be shown using the pumping lemma.
Constant growth
A formal language is of constant growth if every string in the language is longer than the next shorter strings by at most a (language-specific) constant. Languages that violate this property are often considered to be beyond human capacity, although some authors have argued that certain phenomena in natural language do show a growth that cannot be bounded by a constant .[14]
Most mildly context-sensitive grammar formalisms (in particular, LCFRS/MCFG) actually satisfy a stronger property than constant growth called semilinearity.[7] A language is semilinear if its image under the Parikh-mapping (the mapping that ‘forgets’ the relative position of the symbols in a string, effectively treating it as a bag of words) is a regular language. All semilinear languages are of constant growth, but not every language with constant growth is semilinear.[11]
Polynomial parsing
A grammar formalism is said to have polynomial parsing if its membership problem can be solved in deterministic polynomial time. This is the problem to decide, given a grammar G written in the formalism and a string w, whether w is generated by G – that is, whether w is ‘grammatical’ according to G. The time complexity of this problem is measured in terms of the combined size of G and w.
Under the view on mild context-sensitivity as a property of classes of languages, polynomial parsing refers to the language membership problem. This is the problem to decide, for a fixed language L, whether a given string w belongs to L. The time complexity of this problem is measured in terms of the length of w; it ignores the question how L is specified.
Note that both understandings of polynomial parsing are idealizations in the sense that for practical applications one is interested not only in the yes/no question whether a sentence is grammatical, but also in the syntactic structure that the grammar assigns to the sentence.
Formalisms
Over the years, a large number of grammar formalisms have been introduced that satisfy some or all of the characteristic properties put forth by Joshi. Several of them have alternative, automaton-based characterizations that are not discussed in this article; for example, the languages generated by tree-adjoining grammar can be characterized by embedded pushdown automata.
Formalisms equivalent to TAG
- Tree-adjoining grammar (TAG)[3]
- Head grammar (HG)[15][16]
- Linear indexed grammar (LIG)[17]
- Combinatory categorial grammar (CCG)[6]
- Well-nested LCFRS/MCFG of fan-out 2
Formalisms equivalent to general LCFRS/MCFG
- Linear context-free rewriting systems (LCFRS)[7][8]
- Multiple context-free grammars (MCFG)[9]
- Multicomponent tree-adjoining grammars (MCTAG)[7]
- Minimalist grammars (MG)[18]
- Simple (linear, non-erasing, non-combinatorial), positive range concatenation grammars (sRCG)[19]
Formalisms equivalent to well-nested LCFRS/MCFG
- Non-duplicating macro grammars[20]
- Coupled context-free grammars (CCFG)[21]
- Well-nested linear context-free rewriting systems[12]
- Well-nested multiple context-free grammars[10]
Relations among the formalisms
Linear context-free rewriting systems/multiple context-free grammars form a two-dimensional hierarchy of generative power with respect to two grammar-specific parameters called fan-out and rank.[22] More precisely, the languages generated by LCFRS/MCFG with fan-out f ≥ 1 and rank r ≥ 3 are properly included in the class of languages generated by LCFRS/MCFG with rank r + 1 and fan-out f, as well as the class of languages generated by LCFRS/MCFG with rank r and fan-out f + 1. In the presence of well-nestedness, this hierarchy collapses to a one-dimensional hierarchy with respect to fan-out; this is because every well-nested LCFRS/MCFG can be transformed into an equivalent well-nested LCFRS/MCFG with the same fan-out and rank 2.[10][12] Within the LCFRS/MCFG hierarchy, the context-free languages can be characterized by the grammars with fan-out 1; for this fan-out there is no difference between general and well-nested grammars. The TAG-equivalent formalisms can be characterized as well-nested LCFRS/MCFG of fan-out 2.
See also
- Tree-adjoining grammar
- Linear context-free rewriting system
- Range concatenation grammar
- Weir hierarchy
References
- 1 2 Riny Huybregts. The Weak Inadequacy of Context-Free Phrase Structure Grammars. In Ger de Haan, Mieke Trommelen, and Wim Zonneveld, editors, Van periferie naar kern, pages 81–99. Foris, Dordrecht, The Netherlands, 1984.
- 1 2 Stuart M. Shieber. Evidence Against the Context-Freeness of Natural Language. Linguistics and Philosophy, 8(3):333–343, 1985.
- 1 2 3 4 Aravind K. Joshi. Tree Adjoining Grammars: How Much Context-Sensitivity Is Required to Provide Reasonable Structural Descriptions?. In David R. Dowty, Lauri Karttunen, and Arnold M. Zwicky, editors, Natural Language Parsing, pages 206–250. Cambridge University Press, 1985.
- ↑ David J. Weir, K. Vijay-Shanker, and Aravind K. Joshi. The Relationship Between Tree Adjoining Grammars and Head Grammars. In Proceedings of the 24th Annual Meeting of the Association for Computational Linguistics (ACL), pages 67–74, New York, USA, 1986.
- ↑ K. Vijay-Shanker. A Study of Tree Adjoining Grammars. Ph.D. thesis, University of Pennsylvania, Philadelphia, USA, 1987.
- 1 2 David J. Weir and Aravind K. Joshi. Combinatory Categorial Grammars: Generative Power and Relationship to Linear Context-Free Rewriting Systems. In Proceedings of the 26th Annual Meeting of the Association for Computational Linguistics (ACL), pages 278–285, Buffalo, USA, 1988.
- 1 2 3 4 K. Vijay-Shanker, David J. Weir, and Aravind K. Joshi. Characterizing Structural Descriptions Produced by Various Grammatical Formalisms. In Proceedings of the 25th Annual Meeting of the Association for Computational Linguistics (ACL), pages 104–111, Stanford, CA, USA, 1987.
- 1 2 David J. Weir. Characterizing Mildly Context-Sensitive Grammar Formalisms. Ph.D. thesis, University of Pennsylvania, Philadelphia, USA, 1988.
- 1 2 Hiroyuki Seki, Takashi Matsumura, Mamoru Fujii, and Tadao Kasami. On Multiple Context-Free Grammars. Theoretical Computer Science, 88(2):191–229, 1991.
- 1 2 3 4 Makoto Kanazawa. The Pumping Lemma for Well-Nested Multiple Context-Free Languages. In Developments in Language Theory. 13th International Conference, DLT 2009, Stuttgart, Germany, June 30–July 3, 2009. Proceedings, volume 5583 of Lecture Notes in Computer Science, pages 312–325, 2009.
- 1 2 Laura Kallmeyer. On Mildly Context-Sensitive Non-Linear Rewriting. Research on Language and Computation, 8(4):341–363, 2010.
- 1 2 3 Carlos Gómez-Rodríguez, Marco Kuhlmann, and Giorgio Satta. Efficient Parsing of Well-Nested Linear Context-Free Rewriting Systems. In Proceedings of Human Language Technologies: The 2010 Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL), pages 276–284, Los Angeles, USA, 2010.
- 1 2 Laura Kallmeyer. Parsing Beyond Context-Free Grammars. Springer, 2010.
- ↑ Jens Michaelis and Marcus Kracht. Semilinearity as a Syntactic Invariant. In Logical Aspects of Computational Linguistics. First International Conference, LACL 1996, Nancy, France, September 23–25, 1996. Selected Papers, volume 1328 of Lecture Notes in Computer Science, pages 329–345. Springer, 1997.
- ↑ Carl J. Pollard. Generalized Phrase Structure Grammars, Head Grammars, and Natural Language. Ph.D. thesis, Stanford University, 1984.
- ↑ Kelly Roach. Formal Properties of Head Grammars. In Alexis Manaster-Ramer, editor, Mathematics of Language, pages 293–347. John Benjamins, 1987.
- ↑ Gerald Gazdar. Applicability of Indexed Grammars to Natural Language. In Uwe Reyle and Christian Rohrer, editors, Natural Language Parsing and Linguistic Theories, pages 69–94. D. Reidel, 1987.
- ↑ Jens Michaelis. Derivational Minimalism Is Mildly Context-Sensitive. In Logical Aspects of Computational Linguistics, Third International Conference, LACL 1998, Grenoble, France, December 14–16, 1998, Selected Papers, volume 2014 of Lecture Notes in Computer Science, pages 179–198. Springer, 1998.
- ↑ Pierre Boullier. Range Concatenation Grammars. In Harry C. Bunt, John Carroll, and Giorgio Satta, editors, New Developments in Parsing Technology, volume 23 of Text, Speech and Language Technology, pages 269–289. Kluwer Academic Publishers, 2004.
- ↑ Michael J. Fischer. Grammars with Macro-Like Productions. In Ninth Annual Symposium on Switching and Automata Theory, pages 131–142, Schenectady, NY, USA, 1968.
- ↑ Günter Hotz and Gisela Pitsch. On Parsing Coupled-Context-Free Languages. Theoretical Computer Science, 161(1–2):205–233, 1996.
- ↑ Owen Rambow and Giorgio Satta. A Two-Dimensional Hierarchy for Parallel Rewriting Systems. Technical Report IRCS-94-02, University of Pennsylvania, Philadelphia, USA, 1994.
| |||||||||||||||||||