Merge (version control)

Merging (also called integration) in version control, is a fundamental operation that reconciles multiple changes made to a version-controlled collection of files. Most often, it is necessary when a file is modified by two people on two different computers at the same time. When two branches are merged, the result is a single collection of files that contains both sets of changes.
In some cases, the merge can be performed automatically, because there is sufficient history information to reconstruct the changes, and the changes do not conflict. In other cases, a person must decide exactly what the resulting files should contain. Many revision control software tools include merge capabilities.
Types of merges
There are two types of merges: automatic and manual.
Automatic merging
Automatic merging is what version control software does when it reconciles changes that have happened simultaneously (in a logical sense). Also, other pieces of software deploy automatic merging if they allow for editing the same content simultaneously. For instance, Wikipedia allows two people to edit the same article at the same time; when the latter contributor saves, their changes are merged into the article instead of overwriting the previous set of changes.
Manual merging
Manual merging is what people have to resort to (possibly assisted by merging tools) when they have to reconcile files that differ. For instance, if two systems have slightly differing versions of a configuration file and a user wants to have the good stuff in both, this can usually be achieved by merging the configuration files by hand, picking the wanted changes from both sources (this is also called two-way merging). Manual merging is also required when automatic merging runs into a change conflict; for instance, very few automatic merge tools can merge two changes to the same line of code (say, one that changes a function name, and another that adds a comment). In these cases, revision control systems resort to the user to specify the intended merge result.
Merge algorithms
Merge algorithms are an area of active research, and consequently there are many different approaches to automatic merging, with subtle differences. The more notable merge algorithms include three-way merge, recursive three-way merge, fuzzy patch application, weave merge, and patch commutation.
Three-way merge
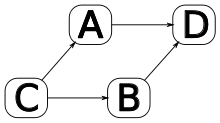
A three-way merge is performed after an automated difference analysis between a file ‘A’ and a file ‘B’ while also considering the origin, or common ancestor, of both files ‘C’. It is a rough merging method, but widely applicable since it only requires one common ancestor to reconstruct the changes that are to be merged.
The three-way merge looks for sections which are the same in two of the three files. In this case, there are two versions of the section, and the version which is in the common ancestor ‘C’ is discarded, while the version that differs is preserved in the output. If ‘A’ and ‘B’ agree, that is what appears in the output. A section that is the same in ‘A’ and ‘C’ outputs the changed version in ‘B’, and likewise a section that is the same in ‘B’ and ‘C’ outputs the version in ‘A’.
Sections that are different in all three files are marked as a conflict situation and left for the user to resolve.
Three-way merging is implemented by the ubiquitous diff3 program, and was the central innovation that allowed the switch from file-locking based revision control systems to merge-based revision control systems. It is extensively used by the Concurrent Versions System (CVS).
Recursive three-way merge
Three-way merge based revision control tools are widespread, but the technique fundamentally depends on finding a common ancestor of the versions to be merged.
There are awkward cases, particularly the "criss-cross merge",[1] where it is not possible to identify a unique last common ancestor of the modified versions.

Fortunately, in this case it can be shown that there are at most two possible candidate ancestors, and recursive three-way merge constructs a virtual ancestor by merging the non-unique ancestors first. This merge can itself suffer the same problem, so the algorithm recursively merges them. Since there are a finite number of versions in the history, the process is guaranteed to eventually terminate. This technique is used by the Git revision control tool.
(Git's recursive merge implementation also handles other awkward cases, like a file being modified in one version and renamed in the other, but those are extensions to its three-way merge implementation; not part of the technique for finding three versions to merge.)
Recursive three-way merge can only be used in situations where the tool has knowledge about the total ancestry DAG (directed acyclic graph) of the derivatives to be merged. Consequently, it cannot be used in situations where derivatives or merges do not fully specify their parent(s).
Fuzzy patch application
A patch is a file that contains a description of changes to a file. In the Unix world, there has been a tradition to disseminate changes to text files as patches in the format that is produced by "diff -u". This format can then be used by the patch program to re-apply (or remove) the changes into (or from) a text file, or a directory structure containing text files.
However, the patch program also has some facilities to apply the patch into a file that is not exactly similar as the origin file that was used to produce the patch. This process is called fuzzy patch application, and results in a kind of asymmetric three-way merge, where the changes in the patch are discarded if the patch program cannot find a place where to apply them.
Like CVS started as a set of scripts on diff3, GNU arch started as a set of scripts on patch. However, fuzzy patch application is a relatively untrustworthy method, sometimes misapplying patches that have too little context (especially ones that create a new file), sometimes refusing to apply deletions that both derivatives have done.
Weave merge
Weave merge is an algorithm that does not make use of a common ancestor for two files. Instead, it tracks how single lines are added and deleted in derivative versions of files, and produces the merged file on this information.
For each line in the derivative files, weave merge collects the following information: which lines precede it, which follow it, and whether it was deleted at some stage of either derivative's history. If either derivative has had the line deleted at some point, it must not be present in the merged version. For other lines, they must be present in the merged version.
The lines are sorted into an order where each line is after all lines that have preceded it at some point in history, and before all lines that have followed it at some point in history. If these constraints do not give a total ordering for all lines, then the lines that do not have an ordering with respect to each other are additions that conflict.
Weave merge was apparently used by the commercial revision control tool BitKeeper and can handle some of the problem cases where a three-way merge produces wrong or bad results. It is also one of the merge options of the GNU Bazaar revision control tool, and is used in Codeville.
Patch commutation
Patch commutation is used in Darcs to merge changes, and is also implemented in git (but called "rebasing"). Patch commutation merge means changing the order of patches (i.e. descriptions of changes) so that they form a linear history. In effect, when two patches are made in the context of a common situation, upon merging, one of them is rewritten so that it appears to be done in the context of the other.
Patch commutation requires that the exact changes that made derivative files are stored or can be reconstructed. From these exact changes it is possible to compute how one of them should be changed in order to rebase it on the other. For instance, if patch A adds line "X" after line 7 of file F and patch B adds line "Y" after line 310 of file F, B has to be rewritten if it is rebased on A: the line must be added on line 311 of file F, because the line added in A offsets the line numbers by one.
Patch commutation has been studied a great deal formally, but the algorithms for dealing with merge conflicts in patch commutation still remain open research questions. However, patch commutation can be proven to produce "correct" merge results where other merge strategies are mostly heuristics that try to produce what users want to see.
The Unix program flipdiff from the "patchutils" package implements patch commutation for traditional patches produced by diff -u.
Trends
The technological advancements in the 3-way merge method have led to the increase in popularity among software development environments to institute concurrent modification through branching in their practices of software configuration management (SCM). In the early to mid-1990s branching was a discouraged practice in smaller software development groups due to the complexities and conflicts introduced through the merging process and the low availability of cost-effective 3-way merge tools. However, this practice was more in demand among larger groups merely due to the increased likelihood that two developers would need to modify the same file at the same time. Merging, at that time, was indeed a challenge and in some environments, additional proprietary conventions were introduced to simplify the necessary merge.
In the early 2000s, the increased availability of reliable 3-way merge tools reduced the time that software development groups had to spend concerning themselves with the technical limitations of their infrastructure. Even smaller software groups are more inclined to approach concurrent modification in their revision control systems. Software developers use a variety of tools and techniques to facilitate 3-way merges, including visual tools for viewing changes side by side.[2]
Resolving conflicts in 3-way merges still remains one of the more taxing tasks of any software development team. This is especially because the person resolving the merge needs prior knowledge of the original code, the intermediate conflicting changes, and the result wanted.
See also
References
- ↑ Cohen, Bram (2005-04-28). "The criss-cross merge case". Git (Mailing list). Message-ID <Pine.LNX.4.44.0504271254120.4678-100000@wax.eds.org>.
- ↑ Sink, Eric. "Source Control HOWTO". Retrieved 5 Feb 2013.
External links
- Nair, Sarat (2010-09-21). "Versioning Systems and 3 Way merge process". Reflections of my thoughts blog. Archived from the original on 2012-03-13. Simple way to understand 3-Way merge process
- Cohen, Bram (2005-05-05). "The new Codeville merge algorithm". Revctrl (Mailing list). Message-ID <Pine.LNX.4.44.0505051019460.4678-100000@wax.eds.org>. Archived from the original on 2011-07-10.
- "3 way merging". Misuse blog. 2007-02-24. Retrieved 2014-11-28. Review of several popular Merge tools from various manufacturers
| ||||||||||||||||||||||||||||||||||||||||||||||||