Mean squared error
In statistics, the mean squared error (MSE) or mean squared deviation (MSD) of an estimator measures the average of the squares of the errors or deviations, that is, the difference between the estimator and what is estimated. MSE is a risk function, corresponding to the expected value of the squared error loss or quadratic loss. The difference occurs because of randomness or because the estimator doesn't account for information that could produce a more accurate estimate.[1]
The MSE is the second moment (about the origin) of the error, and thus incorporates both the variance of the estimator and its bias. For an unbiased estimator, the MSE is the variance of the estimator. Like the variance, MSE has the same units of measurement as the square of the quantity being estimated. In an analogy to standard deviation, taking the square root of MSE yields the root-mean-square error or root-mean-square deviation (RMSE or RMSD), which has the same units as the quantity being estimated; for an unbiased estimator, the RMSE is the square root of the variance, known as the standard deviation.
Definition and basic properties
The MSE assesses the quality of an estimator (i.e., a mathematical function mapping a sample of data to a parameter of the population from which the data is sampled) or a predictor (i.e., a function mapping arbitrary inputs to a sample of values of some random variable). Definition of an MSE differs according to whether one is describing an estimator or a predictor.
Predictor
If 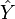 is a vector of
is a vector of  predictions, and
predictions, and 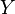 is the vector of observed values corresponding to the inputs to the function which generated the predictions, then the MSE of the predictor can be estimated by
is the vector of observed values corresponding to the inputs to the function which generated the predictions, then the MSE of the predictor can be estimated by
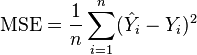
I.e., the MSE is the mean (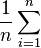 ) of the square of the errors (
) of the square of the errors (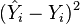 ). This is an easily computable quantity for a particular sample (and hence is sample-dependent).
). This is an easily computable quantity for a particular sample (and hence is sample-dependent).
Estimator
The MSE of an estimator  with respect to an unknown parameter
with respect to an unknown parameter  is defined as
is defined as
![\operatorname{MSE}(\hat{\theta})=\operatorname{E}\big[(\hat{\theta}-\theta)^2\big].](../I/m/032e1c8d4cc3955295c28a3eee325059.png)
This definition depends on the unknown parameter, and the MSE in this sense is a property of an estimator. Since an MSE is an expectation, it is not technically a random variable. That being said, the MSE could be a function of unknown parameters, in which case any estimator of the MSE based on estimates of these parameters would be a function of the data and thus a random variable.
The MSE can be written as the sum of the variance of the estimator and the squared bias of the estimator, providing a useful way to calculate the MSE and implying that in the case of unbiased estimators, the MSE and variance are equivalent. [2]
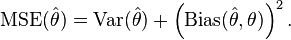
Proof of variance and bias relationship
![\begin{align}\operatorname{MSE}(\hat{\theta})\equiv \mathbb{E}((\hat{\theta}-\theta)^2)&=
\mathbb{E}\left[\left(\hat{\theta}-\mathbb{E}(\hat\theta)+\mathbb{E}(\hat\theta)-\theta\right)^2\right]
\\ & =
\mathbb{E}\left[\left(\hat{\theta}-\mathbb{E}(\hat\theta)\right)^2 +2\left((\hat{\theta}-\mathbb{E}(\hat\theta))(\mathbb{E}(\hat\theta)-\theta)\right)+\left( \mathbb{E}(\hat\theta)-\theta \right)^2\right]
\\ & = \mathbb{E}\left[\left(\hat{\theta}-\mathbb{E}(\hat\theta)\right)^2\right]+2\mathbb{E}\Big[(\hat{\theta}-\mathbb{E}(\hat\theta))(\overbrace{\mathbb{E}(\hat\theta)-\theta}^{\begin{smallmatrix} \text{This is} \\ \text{a constant,} \\ \text{so it can be} \\ \text{pulled out.} \end{smallmatrix}}) \,\Big] + \mathbb{E}\Big[\,\overbrace{\left(\mathbb{E}(\hat\theta)-\theta\right)^2}^{\begin{smallmatrix} \text{This is a} \\ \text{constant, so its} \\ \text{expected value} \\ \text{is itself.} \end{smallmatrix}}\,\Big]
\\ & = \mathbb{E}\left[\left(\hat{\theta}-\mathbb{E}(\hat\theta)\right)^2\right]+2(\overbrace{\mathbb{E}(\hat\theta)-\theta}^{\begin{smallmatrix} \text{That first} \\ \text{constant, now} \\ \text{pulled out.} \end{smallmatrix}})\underbrace{\mathbb{E}(\hat{\theta}-\mathbb{E}(\hat\theta))}_{=\mathbb{E}(\hat\theta)-\mathbb{E}(\hat\theta)=0}+\left(\mathbb{E}(\hat\theta)-\theta\right)^2
\\ & = \mathbb{E}\left[\left(\hat{\theta}-\mathbb{E}(\hat\theta)\right)^2\right]+\left(\mathbb{E}(\hat\theta)-\theta\right)^2
\\ & = \operatorname{Var}(\hat\theta)+ \operatorname{Bias}(\hat\theta,\theta)^2
\end{align}](../I/m/b05d66203821b091ba1ea862fe8ee898.png)
Regression
In regression analysis, the term mean squared error is sometimes used to refer to the unbiased estimate of error variance: the residual sum of squares divided by the number of degrees of freedom. This definition for a known, computed quantity differs from the above definition for the computed MSE of a predictor in that a different denominator is used. The denominator is the sample size reduced by the number of model parameters estimated from the same data, (n-p) for p regressors or (n-p-1) if an intercept is used.[3] For more details, see errors and residuals in statistics. Note that, although the MSE is not an unbiased estimator of the error variance, it is consistent, given the consistency of the predictor.
Also in regression analysis, "mean squared error", often referred to as mean squared prediction error or "out-of-sample mean squared error", can refer to the mean value of the squared deviations of the predictions from the true values, over an out-of-sample test space, generated by a model estimated over a particular sample space. This also is a known, computed quantity, and it varies by sample and by out-of-sample test space.
Examples
Mean
Suppose we have a random sample of size n from a population,  . Suppose the sample units were chosen with replacement. That is, the n units are selected one at a time, and previously selected units are still eligible for selection for all n draws. The usual estimator for the mean is the sample average
. Suppose the sample units were chosen with replacement. That is, the n units are selected one at a time, and previously selected units are still eligible for selection for all n draws. The usual estimator for the mean is the sample average
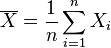
which has an expected value equal to the true mean μ (so it is unbiased) and a mean square error of
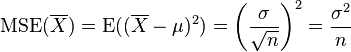
where  is the population variance.
is the population variance.
For a Gaussian distribution this is the best unbiased estimator (that is, it has the lowest MSE among all unbiased estimators), but not, say, for a uniform distribution.
Variance
The usual estimator for the variance is the corrected sample variance:
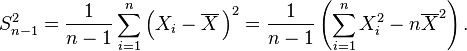
This is unbiased (its expected value is ), hence also called the unbiased sample variance, and its MSE is[4]
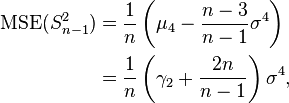
where 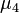 is the fourth central moment of the distribution or population and
is the fourth central moment of the distribution or population and 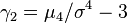 is the excess kurtosis.
is the excess kurtosis.
However, one can use other estimators for which are proportional to 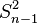 , and an appropriate choice can always give a lower mean square error. If we define
, and an appropriate choice can always give a lower mean square error. If we define
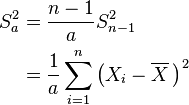
then the MSE is
![\begin{align}
\operatorname{MSE}(S^2_a)&=\operatorname{E}\left(\left(\frac{n-1}{a} S^2_{n-1}-\sigma^2\right)^2 \right) \\
&=\frac{n-1}{n a^2}[(n-1)\gamma_2+n^2+n]\sigma^4-\frac{2(n-1)}{a}\sigma^4+\sigma^4
\end{align}](../I/m/f16d807b78c197f9a52817af3318cbe5.png)
This is minimized when
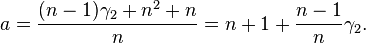
For a Gaussian distribution, where 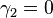 , this means the MSE is minimized when dividing the sum by
, this means the MSE is minimized when dividing the sum by 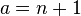 . The minimum excess kurtosis is
. The minimum excess kurtosis is 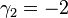 ,[lower-alpha 1] which is achieved by a Bernoulli distribution with p = 1/2 (a coin flip), and the MSE is minimized for
,[lower-alpha 1] which is achieved by a Bernoulli distribution with p = 1/2 (a coin flip), and the MSE is minimized for 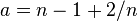 . So no matter what the kurtosis, we get a "better" estimate (in the sense of having a lower MSE) by scaling down the unbiased estimator a little bit; this is a simple example of a shrinkage estimator: one "shrinks" the estimator towards zero (scales down the unbiased estimator).
. So no matter what the kurtosis, we get a "better" estimate (in the sense of having a lower MSE) by scaling down the unbiased estimator a little bit; this is a simple example of a shrinkage estimator: one "shrinks" the estimator towards zero (scales down the unbiased estimator).
Further, while the corrected sample variance is the best unbiased estimator (minimum mean square error among unbiased estimators) of variance for Gaussian distributions, if the distribution is not Gaussian then even among unbiased estimators, the best unbiased estimator of the variance may not be 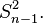
Gaussian distribution
The following table gives several estimators of the true parameters of the population, μ and σ2, for the Gaussian case.[5]
| True value | Estimator | Mean squared error |
|---|---|---|
| θ = μ | = the unbiased estimator of the population mean, 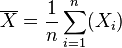 | 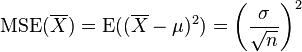 |
| θ = σ2 | = the unbiased estimator of the population variance, 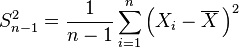 | 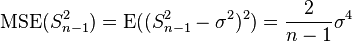 |
| θ = σ2 | = the biased estimator of the population variance, 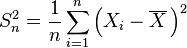 | 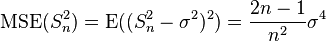 |
| θ = σ2 | = the biased estimator of the population variance, 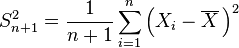 | 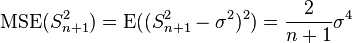 |
Note that:
- The MSEs shown for the variance estimators assume
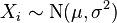 i.i.d. so that
i.i.d. so that 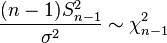 . The result for follows easily from the
. The result for follows easily from the 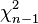 variance that is
variance that is 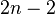 .
. - Unbiased estimators may not produce estimates with the smallest total variation (as measured by MSE): the MSE of is larger than that of
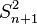 or
or 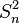 .
. - Estimators with the smallest total variation may produce biased estimates: typically underestimates σ2 by
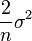
Interpretation
An MSE of zero, meaning that the estimator predicts observations of the parameter with perfect accuracy, is the ideal, but is typically not possible.
Values of MSE may be used for comparative purposes. Two or more statistical models may be compared using their MSEs as a measure of how well they explain a given set of observations: An unbiased estimator (estimated from a statistical model) with the smallest variance among all unbiased estimators is the best prediction in the sense that it minimises the variance and is called the best unbiased estimator or MVUE (Minimum Variance Unbiased Estimator).
Both linear regression techniques such as analysis of variance estimate the MSE as part of the analysis and use the estimated MSE to determine the statistical significance of the factors or predictors under study. The goal of experimental design is to construct experiments in such a way that when the observations are analyzed, the MSE is close to zero relative to the magnitude of at least one of the estimated treatment effects.
MSE is also used in several stepwise regression techniques as part of the determination as to how many predictors from a candidate set to include in a model for a given set of observations.
Applications
- Minimizing MSE is a key criterion in selecting estimators: see minimum mean-square error. Among unbiased estimators, minimizing the MSE is equivalent to minimizing the variance, and the estimator that does this is the minimum variance unbiased estimator. However, a biased estimator may have lower MSE; see estimator bias.
- In statistical modelling the MSE, representing the difference between the actual observations and the observation values predicted by the model, is used to determine the extent to which the model fits the data and whether the removal or some explanatory variables, simplifying the model, is possible without significantly harming the model's predictive ability.
Loss function
Squared error loss is one of the most widely used loss functions in statistics, though its widespread use stems more from mathematical convenience than considerations of actual loss in applications. Carl Friedrich Gauss, who introduced the use of mean squared error, was aware of its arbitrariness and was in agreement with objections to it on these grounds.[1] The mathematical benefits of mean squared error are particularly evident in its use at analyzing the performance of linear regression, as it allows one to partition the variation in a dataset into variation explained by the model and variation explained by randomness.
Criticism
The use of mean squared error without question has been criticized by the decision theorist James Berger. Mean squared error is the negative of the expected value of one specific utility function, the quadratic utility function, which may not be the appropriate utility function to use under a given set of circumstances. There are, however, some scenarios where mean squared error can serve as a good approximation to a loss function occurring naturally in an application.[6]
Like variance, mean squared error has the disadvantage of heavily weighting outliers.[7] This is a result of the squaring of each term, which effectively weights large errors more heavily than small ones. This property, undesirable in many applications, has led researchers to use alternatives such as the mean absolute error, or those based on the median.
See also
- James–Stein estimator
- Hodges' estimator
- Mean percentage error
- Mean square weighted deviation
- Mean squared displacement
- Mean squared prediction error
- Minimum mean squared error estimator
- Peak signal-to-noise ratio
- Root mean square deviation
- Squared deviations
Notes
- ↑ This can be proved by Jensen's inequality as follows. The fourth central moment is an upper bound for the square of variance, so that the least value for their ratio is one, therefore, the least value for the excess kurtosis is −2, achieved, for instance, by a Bernoulli with p=1/2.
References
- 1 2 Lehmann, E. L.; Casella, George (1998). Theory of Point Estimation (2nd ed.). New York: Springer. ISBN 0-387-98502-6. MR 1639875.
- ↑ Wackerly, Dennis; Mendenhall, William; Scheaffer, Richard L. (2008). Mathematical Statistics with Applications (7 ed.). Belmont, CA, USA: Thomson Higher Education. ISBN 0-495-38508-5.
- ↑ Steel, R.G.D, and Torrie, J. H., Principles and Procedures of Statistics with Special Reference to the Biological Sciences., McGraw Hill, 1960, page 288.
- ↑ Mood, A.; Graybill, F.; Boes, D. (1974). Introduction to the Theory of Statistics (3rd ed.). McGraw-Hill. p. 229.
- ↑ DeGroot, Morris H. (1980). Probability and Statistics (2nd ed.). Addison-Wesley.
- ↑ Berger, James O. (1985). "2.4.2 Certain Standard Loss Functions". Statistical decision theory and Bayesian Analysis (2nd ed.). New York: Springer-Verlag. p. 60. ISBN 0-387-96098-8. MR 0804611.
- ↑ Sergio Bermejo, Joan Cabestany (2001) "Oriented principal component analysis for large margin classifiers", Neural Networks, 14 (10), 1447–1461.