Clique problem

In computer science, the clique problem refers to computational problems of finding cliques (subsets of vertices, all adjacent to each other, also called complete subgraphs) in a graph.
For example, the maximum clique problem arises in the following real-world setting. Consider a social network, where the graph’s vertices represent people, and the graph’s edges represent mutual acquaintance. To find a largest subset of people who all know each other, one can systematically inspect all subsets, a process that is too time-consuming to be practical for social networks comprising more than a few dozen people. Although this brute-force search can be improved by more efficient algorithms, all of these algorithms take exponential time to solve the problem. Therefore, much of the theory about the clique problem is devoted to identifying special types of graph that admit more efficient algorithms, or to establishing the computational difficulty of the general problem in various models of computation.[1] Along with its applications in social networks, the clique problem also has many applications in bioinformatics and computational chemistry.[2]
Clique problems include:
- finding a maximum clique (largest clique by vertices),
- finding a maximum weight clique in a weighted graph,
- listing all maximal cliques (cliques that cannot be enlarged)
- solving the decision problem of testing whether a graph contains a clique larger than a given size.
These problems are all hard: the clique decision problem is NP-complete (one of Karp's 21 NP-complete problems), the problem of finding the maximum clique is both fixed-parameter intractable and hard to approximate, and listing all maximal cliques may require exponential time as there exist graphs with exponentially many maximal cliques. Nevertheless, there are algorithms for these problems that run in exponential time or that handle certain more specialized input graphs in polynomial time.[1]
History
Although complete subgraphs have been studied for longer in mathematics,[3] the term "clique" and the problem of algorithmically listing cliques both come from the social sciences, where complete subgraphs are used to model social cliques, groups of people who all know each other. The "clique" terminology comes from Luce & Perry (1949), and the first algorithm for solving the clique problem is that of Harary & Ross (1957),[1] who were motivated by the sociological application.
Since the work of Harary and Ross, many others have devised algorithms for various versions of the clique problem.[1] In the 1970s, researchers began studying these algorithms from the point of view of worst-case analysis; see, for instance, Tarjan & Trojanowski (1977), an early work on the worst-case complexity of the maximum clique problem. Also in the 1970s, beginning with the work of Cook (1971) and Karp (1972), researchers began finding mathematical justification for the perceived difficulty of the clique problem in the theory of NP-completeness and related intractability results. In the 1990s, a breakthrough series of papers beginning with Feige et al. (1991) and reported at the time in major newspapers,[4] showed that it is not even possible to approximate the problem accurately and efficiently.
Definitions

An undirected graph is formed by a finite set of vertices and a set of unordered pairs of vertices, which are called edges. By convention, in algorithm analysis, the number of vertices in the graph is denoted by n and the number of edges is denoted by m. A clique in a graph G is a complete subgraph of G; that is, it is a subset S of the vertices such that every two vertices in S are connected by an edge in G. A maximal clique is a clique to which no more vertices can be added; a maximum clique is a clique that includes the largest possible number of vertices, and the clique number ω(G) is the number of vertices in a maximum clique of G.[1]
Several closely related clique-finding problems have been studied.
- In the maximum clique problem, the input is an undirected graph, and the output is a maximum clique in the graph. If there are multiple maximum cliques, only one need be output.
- In the weighted maximum clique problem, the input is an undirected graph with weights on its vertices (or, less frequently, edges) and the output is a clique with maximum total weight. The maximum clique problem is the special case in which all weights are equal.
- In the maximal clique listing problem, the input is an undirected graph, and the output is a list of all its maximal cliques. The maximum clique problem may be solved using as a subroutine an algorithm for the maximal clique listing problem, because the maximum clique must be included among all the maximal cliques.
- In the k-clique problem, the input is an undirected graph and a number k, and the output is a clique of size k if one exists (or, sometimes, all cliques of size k).
- In the clique decision problem, the input is an undirected graph and a number k, and the output is a Boolean value: true if the graph contains a k-clique, and false otherwise.
The first four of these problems are all important in practical applications; the clique decision problem is not, but is necessary in order to apply the theory of NP-completeness to clique-finding problems.
The clique problem and the independent set problem are complementary: a clique in G is an independent set in the complement graph of G and vice versa. Therefore, many computational results may be applied equally well to either problem, and some research papers do not clearly distinguish between the two problems. However, the two problems have different properties when applied to restricted families of graphs; for instance, the clique problem may be solved in polynomial time for planar graphs[5] while the independent set problem remains NP-hard on planar graphs.
Algorithms
Maximal versus maximum
A maximal clique, sometimes called inclusion-maximal, is a clique that is not included in a larger clique. Note, therefore, that every clique is contained in a maximal clique.
Maximal cliques can be very small. A graph may contain a non-maximal clique with many vertices and a separate clique of size 2 which is maximal. While a maximum (i.e., largest) clique is necessarily maximal, the converse does not hold. There are some types of graphs in which every maximal clique is maximum (the complements of well-covered graphs, notably including complete graphs, triangle-free graphs without isolated vertices, complete multipartite graphs, and k-trees) but other graphs have maximal cliques that are not maximum.
Finding a maximal clique is straightforward: Starting with an arbitrary clique (for instance, a single vertex), grow the current clique one vertex at a time by iterating over the graph’s remaining vertices, adding a vertex if it is connected to each vertex in the current clique, and discarding it otherwise. This algorithm runs in linear time. Because of the ease of finding maximal cliques, and their potential small size, more attention has been given to the much harder algorithmic problem of finding a maximum or otherwise large clique than has been given to the problem of finding a single maximal clique.
Cliques of fixed size
A brute force algorithm to test whether a graph G contains a k-vertex clique, and to find any such clique that it contains, is to examine each subgraph with k vertices and check to see whether it forms a clique. This algorithm takes time O(nk k2): there are O(nk) subgraphs to check, each of which has O(k2) edges whose presence in G needs to be checked. Thus, the problem may be solved in polynomial time whenever k is a fixed constant. When k is part of the input to the problem, however, the time is exponential.[6]
The simplest nontrivial case of the clique-finding problem is finding a triangle in a graph, or equivalently determining whether the graph is triangle-free. In a graph with m edges, there may be at most Θ(m3/2) triangles; the worst case occurs when G is itself a clique. Therefore, algorithms for listing all triangles must take at least Ω(m3/2) time in the worst case, and algorithms are known that match this time bound.[7] For instance, Chiba & Nishizeki (1985) describe an algorithm that sorts the vertices in order from highest degree to lowest and then iterates through each vertex v in the sorted list, looking for triangles that include v and do not include any previous vertex in the list. To do so the algorithm marks all neighbors of v, searches through all edges incident to a neighbor of v outputting a triangle for every edge that has two marked endpoints, and then removes the marks and deletes v from the graph. As the authors show, the time for this algorithm is proportional to the arboricity of the graph (a(G)) times the number of edges, which is O(m a(G)). Since the arboricity is at most O(m1/2), this algorithm runs in time O(m3/2). More generally, all k-vertex cliques can be listed by a similar algorithm that takes time proportional to the number of edges times the (k − 2)nd power of the arboricity.[5] For graphs of constant arboricity, such as planar graphs (or in general graphs from any non-trivial minor-closed graph family), this algorithm takes O(m) time, which is optimal since it is linear in the size of the input.
If one desires only a single triangle, or an assurance that the graph is triangle-free, faster algorithms are possible. As Itai & Rodeh (1978) observe, the graph contains a triangle if and only if its adjacency matrix and the square of the adjacency matrix contain nonzero entries in the same cell; therefore, fast matrix multiplication techniques such as the Coppersmith–Winograd algorithm can be applied to find triangles in time O(n2.376), which may be faster than O(m3/2) for sufficiently dense graphs. Alon, Yuster & Zwick (1994) have improved the O(m3/2) algorithm for finding triangles to O(m1.41) by using fast matrix multiplication. This idea of using fast matrix multiplication to find triangles has also been extended to problems of finding k-cliques for larger values of k.[8]
Listing all maximal cliques
By a result of Moon & Moser (1965), any n-vertex graph has at most 3n/3 maximal cliques. The Bron–Kerbosch algorithm is a recursive backtracking procedure of Bron & Kerbosch (1973) that augments a candidate clique by considering one vertex at a time, either adding it to the candidate clique or to a set of excluded vertices that cannot be in the clique but must have some non-neighbor in the eventual clique; variants of this algorithm can be shown to have worst-case running time O(3n/3).[9] Therefore, this provides a worst-case-optimal solution to the problem of listing all maximal independent sets; further, the Bron–Kerbosch algorithm has been widely reported as being faster in practice than its alternatives.[10]
As Tsukiyama et al. (1977) showed, it is also possible to list all maximal cliques in a graph in an amount of time that is polynomial per generated clique. An algorithm such as theirs in which the running time depends on the output size is known as an output-sensitive algorithm. Their algorithm is based on the following two observations, relating the maximal cliques of the given graph G to the maximal cliques of a graph G \ v formed by removing an arbitrary vertex v from G:
- For every maximal clique C of G \ v, either C continues to form a maximal clique in G, or C ⋃ {v} forms a maximal clique in G. Therefore, G has at least as many maximal cliques as G \ v does.
- Each maximal clique in G that does not contain v is a maximal clique in G \ v, and each maximal clique in G that does contain v can be formed from a maximal clique C in G \ v by adding v and removing the non-neighbors of v from C.
Using these observations they can generate all maximal cliques in G by a recursive algorithm that, for each maximal clique C in G \ v, outputs C and the clique formed by adding v to C and removing the non-neighbors of v. However, some cliques of G may be generated in this way from more than one parent clique of G \ v, so they eliminate duplicates by outputting a clique in G only when its parent in G \ v is lexicographically maximum among all possible parent cliques. On the basis of this principle, they show that all maximal cliques in G may be generated in time O(mn) per clique, where m is the number of edges in G and n is the number of vertices; Chiba & Nishizeki (1985) improve this to O(ma) per clique, where a is the arboricity of the given graph. Makino & Uno (2004) provide an alternative output-sensitive algorithm based on fast matrix multiplication, and Johnson & Yannakakis (1988) show that it is even possible to list all maximal cliques in lexicographic order with polynomial delay per clique, although the reverse of this order is NP-hard to generate.
On the basis of this result, it is possible to list all maximal cliques in polynomial time, for families of graphs in which the number of cliques is polynomially bounded. These families include chordal graphs, complete graphs, triangle-free graphs, interval graphs, graphs of bounded boxicity, and planar graphs.[11] In particular, the planar graphs, and more generally, any family of graphs that is both sparse (having a number of edges at most a constant times the number of vertices) and closed under the operation of taking subgraphs, have O(n) cliques, of at most constant size, that can be listed in linear time.[5][12]
Finding maximum cliques in arbitrary graphs
It is possible to find the maximum clique, or the clique number, of an arbitrary n-vertex graph in time O(3n/3) = O(1.4422n) by using one of the algorithms described above to list all maximal cliques in the graph and returning the largest one. However, for this variant of the clique problem better worst-case time bounds are possible. The algorithm of Tarjan & Trojanowski (1977) solves this problem in time O(2n/3) = O(1.2599n); it is a recursive backtracking scheme similar to that of the Bron–Kerbosch algorithm, but is able to eliminate some recursive calls when it can be shown that some other combination of vertices not used in the call is guaranteed to lead to a solution at least as good. Jian (1986) improved this to O(20.304n) = O(1.2346n). Robson (1986) improved this to O(20.276n) = O(1.2108n) time, at the expense of greater space usage, by a similar backtracking scheme with a more complicated case analysis, together with a dynamic programming technique in which the optimal solution is precomputed for all small connected subgraphs of the complement graph and these partials solutions are used to shortcut the backtracking recursion. The fastest algorithm known today is due to Robson (2001) which runs in time O(20.249n) = O(1.1888n).
There has also been extensive research on heuristic algorithms for solving maximum clique problems without worst-case runtime guarantees, based on methods including branch and bound,[13] local search,[14] greedy algorithms,[15] and constraint programming.[16] Non-standard computing methodologies for finding cliques include DNA computing[17] and adiabatic quantum computation.[18] The maximum clique problem was the subject of an implementation challenge sponsored by DIMACS in 1992–1993,[19] and a collection of graphs used as benchmarks for the challenge is publicly available.[20]
Special classes of graphs

Planar graphs, and other families of sparse graphs, have been discussed above: they have linearly many maximal cliques, of bounded size, that can be listed in linear time.[5] In particular, for planar graphs, any clique can have at most four vertices, by Kuratowski's theorem.
Perfect graphs are defined by the properties that their clique number equals their chromatic number, and that this equality holds also in each of their induced subgraphs. For perfect graphs, it is possible to find a maximum clique in polynomial time, using an algorithm based on semidefinite programming.[21] However, this method is complex and non-combinatorial, and specialized clique-finding algorithms have been developed for many subclasses of perfect graphs.[22] In the complement graphs of bipartite graphs, König's theorem allows the maximum clique problem to be solved using techniques for matching. In another class of perfect graphs, the permutation graphs, a maximum clique is a longest decreasing subsequence of the permutation defining the graph and can be found using known algorithms for the longest decreasing subsequence problem.[23] In chordal graphs, the maximal cliques are a subset of the n cliques formed as part of an elimination ordering.
In some cases, these algorithms can be extended to other, non-perfect, classes of graphs as well: for instance, in a circle graph, the neighborhood of each vertex is a permutation graph, so a maximum clique in a circle graph can be found by applying the permutation graph algorithm to each neighborhood.[24] Similarly, in a unit disk graph (with a known geometric representation), there is a polynomial time algorithm for maximum cliques based on applying the algorithm for complements of bipartite graphs to shared neighborhoods of pairs of vertices.[25]
The algorithmic problem of finding a maximum clique in a random graph drawn from the Erdős–Rényi model (in which each edge appears with probability 1/2, independently from the other edges) was suggested by Karp (1976). It has been shown that a maximum clique in a random graph can be computed in expected 2O(log22n) time.[26] Although the clique number of such graphs is very close to 2 log2n, simple greedy algorithms as well as more sophisticated randomized approximation techniques[27] only find cliques with size log2n, and the number of maximal cliques in such graphs is with high probability exponential in log2n preventing a polynomial time solution that lists all of them. Because of the difficulty of this problem, several authors have investigated the planted clique problem, the clique problem on random graphs that have been augmented by adding large cliques. While spectral methods[28] and semidefinite programming[29] can detect hidden cliques of size Ω(√n), no polynomial-time algorithms are currently known to detect those of size o(√n).
Approximation algorithms
Several authors have considered approximation algorithms that attempt to find a clique or independent set that, although not maximum, has size as close to the maximum as can be found in polynomial time. Although much of this work has focused on independent sets in sparse graphs, a case that does not make sense for the complementary clique problem, there has also been work on approximation algorithms that do not use such sparsity assumptions.[30]
Feige (2004) describes a polynomial time algorithm that finds a clique of size Ω((log n/log log n)2) in any graph that has clique number Ω(n/logkn) for any constant k. By combining this algorithm to find cliques in graphs with clique numbers between n/log n and n/log3n with a different algorithm of Boppana & Halldórsson (1992) to find cliques in graphs with higher clique numbers, and choosing a two-vertex clique if both algorithms fail to find anything, Feige provides an approximation algorithm that finds a clique with a number of vertices within a factor of O(n(log log n)2/log3n) of the maximum. Although the approximation ratio of this algorithm is weak, it is the best known to date, and the results on hardness of approximation described below suggest that there can be no approximation algorithm with an approximation ratio significantly less than linear.
Lower bounds
NP-completeness
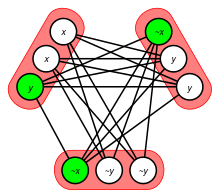
The clique decision problem is NP-complete. It was one of Richard Karp's original 21 problems shown NP-complete in his 1972 paper "Reducibility Among Combinatorial Problems". This problem was also mentioned in Stephen Cook's paper introducing the theory of NP-complete problems. Thus, the problem of finding a maximum clique is NP-hard: if one could solve it, one could also solve the decision problem, by comparing the size of the maximum clique to the size parameter given as input in the decision problem.
Karp's NP-completeness proof is a many-one reduction from the Boolean satisfiability problem for formulas in conjunctive normal form, which was proved NP-complete in the Cook–Levin theorem.[32] From a given CNF formula, Karp forms a graph that has a vertex for every pair (v,c), where v is a variable or its negation and c is a clause in the formula that contains v. Vertices are connected by an edge if they represent compatible variable assignments for different clauses: that is, there is an edge from (v,c) to (u,d) whenever c ≠ d and u and v are not each other's negations. If k denotes the number of clauses in the CNF formula, then the k-vertex cliques in this graph represent ways of assigning truth values to some of its variables in order to satisfy the formula; therefore, the formula is satisfiable if and only if a k-vertex clique exists.
Some NP-complete problems (such as the travelling salesman problem in planar graphs) may be solved in time that is exponential in a sublinear function of the input size parameter n.[33] However, as Impagliazzo, Paturi & Zane (2001) describe, it is unlikely that such bounds exist for the clique problem in arbitrary graphs, as they would imply similarly subexponential bounds for many other standard NP-complete problems.
Circuit complexity
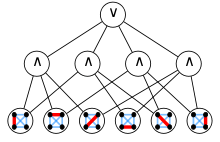
The computational difficulty of the clique problem has led it to be used to prove several lower bounds in circuit complexity. Because the existence of a clique of a given size is a monotone graph property (if a clique exists in a given graph, it will exist in any supergraph) there must exist a monotone circuit, using only and gates and or gates, to solve the clique decision problem for a given fixed clique size. However, the size of these circuits can be proven to be a super-polynomial function of the number of vertices and the clique size, exponential in the cube root of the number of vertices.[34] Even if a small number of NOT gates are allowed, the complexity remains superpolynomial.[35] Additionally, the depth of a monotone circuit for the clique problem using gates of bounded fan-in must be at least a polynomial in the clique size.[36]
Decision tree complexity
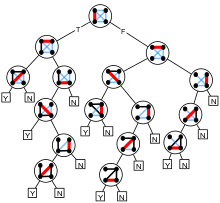
The (deterministic) decision tree complexity of determining a graph property is the number of questions of the form "Is there an edge between vertex u and vertex v?" that have to be answered in the worst case to determine whether a graph has a particular property. That is, it is the minimum height of a boolean decision tree for the problem. Since there are at most n(n − 1)/2 possible questions to be asked, any graph property can be determined with n(n − 1)/2 questions. It is also possible to define random and quantum decision tree complexity of a property, the expected number of questions (for a worst case input) that a randomized or quantum algorithm needs to have answered in order to correctly determine whether the given graph has the property.
Because the property of containing a clique is a monotone property (adding an edge can only cause more cliques to exist within the graph, not fewer), it is covered by the Aanderaa–Karp–Rosenberg conjecture, which states that the deterministic decision tree complexity of determining any non-trivial monotone graph property is exactly n(n − 1)/2. For deterministic decision trees, the property of containing a k-clique (2 ≤ k ≤ n) was shown to have decision tree complexity exactly n(n − 1)/2 by Bollobás (1976). Deterministic decision trees also require exponential size to detect cliques, or large polynomial size to detect cliques of bounded size.[37]
The Aanderaa–Karp–Rosenberg conjecture also states that the randomized decision tree complexity of non-trivial monotone functions is Θ(n2). The conjecture is resolved for the property of containing a k-clique (2 ≤ k ≤ n), since it is known to have randomized decision tree complexity Θ(n2).[38] For quantum decision trees, the best known lower bound is Ω(n), but no matching algorithm is known for the case of k ≥ 3.[39]
Fixed-parameter intractability
Parameterized complexity[40] is the complexity-theoretic study of problems that are naturally equipped with a small integer parameter k, and for which the problem becomes more difficult as k increases, such as finding k-cliques in graphs. A problem is said to be fixed-parameter tractable if there is an algorithm for solving it on inputs of size n in time f(k) nO(1); that is, if it can be solved in polynomial time for any fixed value of k and moreover if the exponent of the polynomial does not depend on k.
For the clique problem, the brute force search algorithm has running time O(nkk2), and although it can be improved by fast matrix multiplication the running time still has an exponent that is linear in k. Thus, although the running time of known algorithms for the clique problem is polynomial for any fixed k, these algorithms do not suffice for fixed-parameter tractability. Downey & Fellows (1995) defined a hierarchy of parametrized problems, the W hierarchy, that they conjectured did not have fixed-parameter tractable algorithms; they proved that independent set (or, equivalently, clique) is hard for the first level of this hierarchy, W[1]. Thus, according to their conjecture, clique is not fixed-parameter tractable. Moreover, this result provides the basis for proofs of W[1]-hardness of many other problems, and thus serves as an analogue of the Cook–Levin theorem for parameterized complexity.
Chen et al. (2006) showed that the clique problem cannot be solved in time 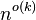 unless the exponential time hypothesis fails.
unless the exponential time hypothesis fails.
Although the problems of listing maximal cliques or finding maximum cliques are unlikely to be fixed-parameter tractable with the parameter k, they may be fixed-parameter tractable for other parameters of instance complexity. For instance, both problems are known to be fixed-parameter tractable when parametrized by the degeneracy of the input graph.[12]
Hardness of approximation

The computational complexity of approximating the clique problem has been studied for a long time; for instance, Garey & Johnson (1978) observed that, because of the fact that the clique number takes on small integer values and is NP-hard to compute, it cannot have a fully polynomial-time approximation scheme. However, little more was known until the early 1990s, when several authors began to make connections between the approximation of maximum cliques and probabilistically checkable proofs, and used these connections to prove hardness of approximation results for the maximum clique problem.[4][41] After many improvements to these results it is now known that, unless P = NP, there can be no polynomial time algorithm that approximates the maximum clique to within a factor better than O(n1 − ε), for any ε > 0.[42]
The rough idea of these inapproximability results[43] is to form a graph that represents a probabilistically checkable proof system for an NP-complete problem such as Satisfiability. A proof system of this type is defined by a family of proof strings (sequences of bits) and proof checkers: algorithms that, after a polynomial amount of computation over a given Satisfiability instance, examine a small number of randomly chosen bits of the proof string and on the basis of that examination either declare it to be a valid proof or declare it to be invalid. False negatives are not allowed: a valid proof must always be declared to be valid, but an invalid proof may be declared to be valid as long as the probability that a checker makes a mistake of this type is low. To transform a probabilistically checkable proof system into a clique problem, one forms a graph in which the vertices represent all the possible ways that a proof checker could read a sequence of proof string bits and end up accepting the proof. Two vertices are connected by an edge whenever the two proof checker runs that they describe agree on the values of the proof string bits that they both examine. The maximal cliques in this graph consist of the accepting proof checker runs for a single proof string, and one of these cliques is large if and only if there exists a proof string that many proof checkers accept. If the original Satisfiability instance is satisfiable, there will be a large clique defined by a valid proof string for that instance, but if the original instance is not satisfiable, then all proof strings are invalid, any proof string has only a small number of checkers that mistakenly accept it, and all cliques are small. Therefore, if one could distinguish in polynomial time between graphs that have large cliques and graphs in which all cliques are small, one could use this ability to distinguish the graphs generated from satisfiable and unsatisfiable instances of the Satisfiability problem, not possible unless P = NP. An accurate polynomial-time approximation to the clique problem would allow these two sets of graphs to be distinguished from each other, and is therefore also impossible.
Notes
- 1 2 3 4 5 For surveys of these algorithms, and basic definitions used in this article, see Bomze et al. (1999) and Gutin (2004).
- ↑ For more details and references, see clique (graph theory).
- ↑ Complete subgraphs make an early appearance in the mathematical literature in the graph-theoretic reformulation of Ramsey theory by Erdős & Szekeres (1935).
- 1 2 Kolata, Gina (June 26, 1990), "In a Frenzy, Math Enters Age of Electronic Mail", New York Times.
- 1 2 3 4 Chiba & Nishizeki (1985).
- ↑ E.g., see Downey & Fellows (1995).
- ↑ Itai & Rodeh (1978) provide an algorithm with O(m3/2) running time that finds a triangle if one exists but does not list all triangles; Chiba & Nishizeki (1985) list all triangles in time O(m3/2).
- ↑ Eisenbrand & Grandoni (2004); Kloks, Kratsch & Müller (2000); Nešetřil & Poljak (1985); Vassilevska & Williams (2009); Yuster (2006).
- ↑ Tomita, Tanaka & Takahashi (2006).
- ↑ Cazals & Karande (2008); Eppstein & Strash (2011).
- ↑ Rosgen & Stewart (2007).
- 1 2 Eppstein, Löffler & Strash (2010).
- ↑ Balas & Yu (1986); Carraghan & Pardalos (1990); Pardalos & Rogers (1992); Östergård (2002); Fahle (2002); Tomita & Seki (2003); Tomita & Kameda (2007); Konc & Janežič (2007).
- ↑ Battiti & Protasi (2001); Katayama, Hamamoto & Narihisa (2005).
- ↑ Abello, Pardalos & Resende (1999); Grosso, Locatelli & Della Croce (2004).
- ↑ Régin (2003).
- ↑ Ouyang et al. (1997). Although the title refers to maximal cliques, the problem this paper solves is actually the maximum clique problem.
- ↑ Childs et al. (2002).
- ↑ Johnson & Trick (1996).
- ↑ DIMACS challenge graphs for the clique problem, accessed 2009-12-17.
- ↑ Grötschel, Lovász & Schrijver (1988).
- ↑ Golumbic (1980).
- ↑ Golumbic (1980), p. 159. Even, Pnueli & Lempel (1972) provide an alternative quadratic-time algorithm for maximum cliques in comparability graphs, a broader class of perfect graphs that includes the permutation graphs as a special case.
- ↑ Gavril (1973); Golumbic (1980), p. 247.
- ↑ Clark, Colbourn & Johnson (1990).
- ↑ Song (2015)
- ↑ Jerrum (1992).
- ↑ Alon, Krivelevich & Sudakov (1998).
- ↑ Feige & Krauthgamer (2000).
- ↑ Boppana & Halldórsson (1992); Feige (2004); Halldórsson (2000).
- ↑ Adapted from Sipser (1996)
- ↑ Cook (1971) gives essentially the same reduction, from 3-SAT instead of Satisfiability, to show that subgraph isomorphism is NP-complete.
- ↑ Lipton & Tarjan (1980).
- ↑ Alon & Boppana (1987). For earlier and weaker bounds on monotone circuits for the clique problem, see Valiant (1983) and Razborov (1985).
- ↑ Amano & Maruoka (1998).
- ↑ Goldmann & Håstad (1992) used communication complexity to prove this result.
- ↑ Wegener (1988).
- ↑ For instance, this follows from Gröger (1992).
- ↑ Childs & Eisenberg (2005); Magniez, Santha & Szegedy (2007).
- ↑ Downey & Fellows (1999).
- ↑ Feige et al. (1991); Arora & Safra (1998); Arora et al. (1998).
- ↑ Håstad (1999) showed inapproximability for this ratio using a stronger complexity theoretic assumption, the inequality of NP and ZPP; Khot (2001) described more precisely the inapproximation ratio, and Zuckerman (2006) derandomized the construction weakening its assumption to P ≠ NP.
- ↑ This reduction is originally due to Feige et al. (1991) and used in all subsequent inapproximability proofs; the proofs differ in the strengths and details of the probabilistically checkable proof systems that they rely on.
References
- Abello, J.; Pardalos, P. M.; Resende, M. G. C. (1999), "On maximum clique problems in very large graphs", in Abello, J.; Vitter, J., External Memory Algorithms, DIMACS Series on Discrete Mathematics and Theoretical Computer Science 50, American Mathematical Society, pp. 119–130, ISBN 0-8218-1184-3.
- Alon, N.; Boppana, R. (1987), "The monotone circuit complexity of boolean functions", Combinatorica 7 (1): 1–22, doi:10.1007/BF02579196.
- Alon, N.; Krivelevich, M.; Sudakov, B. (1998), "Finding a large hidden clique in a random graph", Random Structures & Algorithms 13 (3–4): 457–466, doi:10.1002/(SICI)1098-2418(199810/12)13:3/4<457::AID-RSA14>3.0.CO;2-W.
- Alon, N.; Yuster, R.; Zwick, U. (1994), "Finding and counting given length cycles", Proceedings of the 2nd European Symposium on Algorithms, Utrecht, The Netherlands, pp. 354–364.
- Amano, K.; Maruoka, A. (1998), "A superpolynomial lower bound for a circuit computing the clique function with at most (1/6)log log n negation gates", Proc. Symp. Mathematical Foundations of Computer Science, Lecture Notes in Computer Science 1450, Springer-Verlag, pp. 399–408.
- Arora, Sanjeev; Lund, Carsten; Motwani, Rajeev; Sudan, Madhu; Szegedy, Mario (1998), "Proof verification and the hardness of approximation problems", Journal of the ACM 45 (3): 501–555, doi:10.1145/278298.278306, ECCC TR98-008. Originally presented at the 1992 Symposium on Foundations of Computer Science, doi:10.1109/SFCS.1992.267823.
- Arora, S.; Safra, S. (1998), "Probabilistic checking of proofs: A new characterization of NP", Journal of the ACM 45 (1): 70–122, doi:10.1145/273865.273901. Originally presented at the 1992 Symposium on Foundations of Computer Science, doi:10.1109/SFCS.1992.267824.
- Balas, E.; Yu, C. S. (1986), "Finding a maximum clique in an arbitrary graph", SIAM Journal on Computing 15 (4): 1054–1068, doi:10.1137/0215075.
- Battiti, R.; Protasi, M. (2001), "Reactive local search for the maximum clique problem", Algorithmica 29 (4): 610–637, doi:10.1007/s004530010074.
- Bollobás, Béla (1976), "Complete subgraphs are elusive", Journal of Combinatorial Theory, Series B 21 (1): 1–7, doi:10.1016/0095-8956(76)90021-6, ISSN 0095-8956.
- Bomze, I. M.; Budinich, M.; Pardalos, P. M.; Pelillo, M. (1999), "The maximum clique problem", Handbook of Combinatorial Optimization 4, Kluwer Academic Publishers, pp. 1–74, CiteSeerX: 10
.1 ..1 .48 .4074 - Boppana, R.; Halldórsson, M. M. (1992), "Approximating maximum independent sets by excluding subgraphs", BIT 32 (2): 180–196, doi:10.1007/BF01994876.
- Bron, C.; Kerbosch, J. (1973), "Algorithm 457: finding all cliques of an undirected graph", Communications of the ACM 16 (9): 575–577, doi:10.1145/362342.362367.
- Carraghan, R.; Pardalos, P. M. (1990), "An exact algorithm for the maximum clique problem" (PDF), Operations Research Letters 9 (6): 375–382, doi:10.1016/0167-6377(90)90057-C.
- Cazals, F.; Karande, C. (2008), "A note on the problem of reporting maximal cliques" (PDF), Theoretical Computer Science 407 (1): 564–568, doi:10.1016/j.tcs.2008.05.010.
- Chen, Jianer; Huang, Xiuzhen; Kanj, Iyad A.; Xia, Ge (2006), "Strong computational lower bounds via parameterized complexity", Journal of Computer and System Sciences 72 (8): 1346–1367, doi:10.1016/j.jcss.2006.04.007
- Chiba, N.; Nishizeki, T. (1985), "Arboricity and subgraph listing algorithms", SIAM Journal on Computing 14 (1): 210–223, doi:10.1137/0214017.
- Childs, A. M.; Farhi, E.; Goldstone, J.; Gutmann, S. (2002), "Finding cliques by quantum adiabatic evolution", Quantum Information and Computation 2 (3): 181–191, arXiv:quant-ph/0012104.
- Childs, A. M.; Eisenberg, J. M. (2005), "Quantum algorithms for subset finding", Quantum Information and Computation 5 (7): 593–604, arXiv:quant-ph/0311038.
- Clark, Brent N.; Colbourn, Charles J.; Johnson, David S. (1990), "Unit disk graphs", Discrete Mathematics 86 (1–3): 165–177, doi:10.1016/0012-365X(90)90358-O
- Cook, S. A. (1971), "The complexity of theorem-proving procedures", Proc. 3rd ACM Symposium on Theory of Computing, pp. 151–158, doi:10.1145/800157.805047.
- Downey, R. G.; Fellows, M. R. (1995), "Fixed-parameter tractability and completeness. II. On completeness for W[1]", Theoretical Computer Science 141 (1–2): 109–131, doi:10.1016/0304-3975(94)00097-3.
- Downey, R. G.; Fellows, M. R. (1999), Parameterized complexity, Springer-Verlag, ISBN 0-387-94883-X.
- Eisenbrand, F.; Grandoni, F. (2004), "On the complexity of fixed parameter clique and dominating set", Theoretical Computer Science 326 (1–3): 57–67, doi:10.1016/j.tcs.2004.05.009.
- Eppstein, David; Löffler, Maarten; Strash, Darren (2010), "Listing All Maximal Cliques in Sparse Graphs in Near-Optimal Time", in Cheong, Otfried; Chwa, Kyung-Yong; Park, Kunsoo, 21st International Symposium on Algorithms and Computation (ISAAC 2010), Jeju, Korea, Lecture Notes in Computer Science 6506, Springer-Verlag, pp. 403–414, arXiv:1006.5440, doi:10.1007/978-3-642-17517-6_36, ISBN 978-3-642-17516-9.
- Eppstein, David; Strash, Darren (2011), "Listing all maximal cliques in large sparse real-world graphs", 10th International Symposium on Experimental Algorithms, arXiv:1103.0318.
- Erdős, Paul; Szekeres, George (1935), "A combinatorial problem in geometry" (PDF), Compositio Mathematica 2: 463–470.
- Even, S.; Pnueli, A.; Lempel, A. (1972), "Permutation graphs and transitive graphs", Journal of the ACM 19 (3): 400–410, doi:10.1145/321707.321710.
- Fahle, T. (2002), "Simple and Fast: Improving a Branch-And-Bound Algorithm for Maximum Clique", Proc. 10th European Symposium on Algorithms, Lecture Notes in Computer Science 2461, Springer-Verlag, pp. 47–86, doi:10.1007/3-540-45749-6_44, ISBN 978-3-540-44180-9.
- Feige, U. (2004), "Approximating maximum clique by removing subgraphs", SIAM Journal on Discrete Mathematics 18 (2): 219–225, doi:10.1137/S089548010240415X.
- Feige, U.; Goldwasser, S.; Lovász, L.; Safra, S; Szegedy, M. (1991), "Approximating clique is almost NP-complete", Proc. 32nd IEEE Symp. on Foundations of Computer Science, pp. 2–12, doi:10.1109/SFCS.1991.185341, ISBN 0-8186-2445-0.
- Feige, U.; Krauthgamer, R. (2000), "Finding and certifying a large hidden clique in a semirandom graph", Random Structures and Algorithms 16 (2): 195–208, doi:10.1002/(SICI)1098-2418(200003)16:2<195::AID-RSA5>3.0.CO;2-A.
- Garey, M. R.; Johnson, D. S. (1978), ""Strong" NP-completeness results: motivation, examples and implications", Journal of the ACM 25 (3): 499–508, doi:10.1145/322077.322090.
- Gavril, F. (1973), "Algorithms for a maximum clique and a maximum independent set of a circle graph", Networks 3 (3): 261–273, doi:10.1002/net.3230030305.
- Goldmann, M.; Håstad, J. (1992), "A simple lower bound for monotone clique using a communication game", Information Processing Letters 41 (4): 221–226, doi:10.1016/0020-0190(92)90184-W.
- Golumbic, M. C. (1980), Algorithmic Graph Theory and Perfect Graphs, Computer Science and Applied Mathematics, Academic Press, ISBN 0-444-51530-5.
- Gröger, Hans Dietmar (1992), "On the randomized complexity of monotone graph properties" (PDF), Acta Cybernetica 10 (3): 119–127, retrieved 2009-10-02
- Grosso, A.; Locatelli, M.; Della Croce, F. (2004), "Combining swaps and node weights in an adaptive greedy approach for the maximum clique problem", Journal of Heuristics 10 (2): 135–152, doi:10.1023/B:HEUR.0000026264.51747.7f.
- Grötschel, M.; Lovász, L.; Schrijver, A. (1988), "9.4 Coloring Perfect Graphs", Geometric Algorithms and Combinatorial Optimization, Algorithms and Combinatorics 2, Springer–Verlag, pp. 296–298, ISBN 0-387-13624-X.
- Gutin, G. (2004), "5.3 Independent sets and cliques", in Gross, J. L.; Yellen, J., Handbook of graph theory, Discrete Mathematics & Its Applications, CRC Press, pp. 389–402, ISBN 978-1-58488-090-5.
- Halldórsson, M. M. (2000), "Approximations of Weighted Independent Set and Hereditary Subset Problems" (PDF), Journal of Graph Algorithms and Applications 4 (1): 1–16, doi:10.7155/jgaa.00020.
- Harary, F.; Ross, I. C. (1957), "A procedure for clique detection using the group matrix", Sociometry (American Sociological Association) 20 (3): 205–215, doi:10.2307/2785673, JSTOR 2785673, MR 0110590.
- Håstad, J. (1999), "Clique is hard to approximate within n1 − ε", Acta Mathematica 182 (1): 105–142, doi:10.1007/BF02392825.
- Impagliazzo, R.; Paturi, R.; Zane, F. (2001), "Which problems have strongly exponential complexity?", Journal of Computer and System Sciences 63 (4): 512–530, doi:10.1006/jcss.2001.1774.
- Itai, A.; Rodeh, M. (1978), "Finding a minimum circuit in a graph", SIAM Journal on Computing 7 (4): 413–423, doi:10.1137/0207033.
- Jerrum, M. (1992), "Large cliques elude the Metropolis process", Random Structures and Algorithms 3 (4): 347–359, doi:10.1002/rsa.3240030402.
- Jian, T (1986), "An O(20.304n) Algorithm for Solving Maximum Independent Set Problem", IEEE Transactions on Computers (IEEE Computer Society) 35 (9): 847–851, doi:10.1109/TC.1986.1676847, ISSN 0018-9340.
- Johnson, D. S.; Trick, M. A., eds. (1996), Cliques, Coloring, and Satisfiability: Second DIMACS Implementation Challenge, October 11–13, 1993, DIMACS Series in Discrete Mathematics and Theoretical Computer Science 26, American Mathematical Society, ISBN 0-8218-6609-5.
- Johnson, D. S.; Yannakakis, M. (1988), "On generating all maximal independent sets", Information Processing Letters 27 (3): 119–123, doi:10.1016/0020-0190(88)90065-8.
- Karp, Richard M. (1972), "Reducibility among combinatorial problems", in Miller, R. E.; Thatcher, J. W., Complexity of Computer Computations (PDF), New York: Plenum, pp. 85–103.
- Karp, Richard M. (1976), "Probabilistic analysis of some combinatorial search problems", in Traub, J. F., Algorithms and Complexity: New Directions and Recent Results, New York: Academic Press, pp. 1–19.
- Katayama, K.; Hamamoto, A.; Narihisa, H. (2005), "An effective local search for the maximum clique problem", Information Processing Letters 95 (5): 503–511, doi:10.1016/j.ipl.2005.05.010.
- Khot, S. (2001), "Improved inapproximability results for MaxClique, chromatic number and approximate graph coloring", Proc. 42nd IEEE Symp. Foundations of Computer Science, pp. 600–609, doi:10.1109/SFCS.2001.959936, ISBN 0-7695-1116-3.
- Kloks, T.; Kratsch, D.; Müller, H. (2000), "Finding and counting small induced subgraphs efficiently", Information Processing Letters 74 (3–4): 115–121, doi:10.1016/S0020-0190(00)00047-8.
- Konc, J.; Janežič, D. (2007), "An improved branch and bound algorithm for the maximum clique problem" (PDF), MATCH Communications in Mathematical and in Computer Chemistry 58 (3): 569–590. Source code
- Lipton, R. J.; Tarjan, R. E. (1980), "Applications of a planar separator theorem", SIAM Journal on Computing 9 (3): 615–627, doi:10.1137/0209046.
- Luce, R. Duncan; Perry, Albert D. (1949), "A method of matrix analysis of group structure", Psychometrika 14 (2): 95–116, doi:10.1007/BF02289146, PMID 18152948.
- Magniez, Frédéric; Santha, Miklos; Szegedy, Mario (2007), "Quantum algorithms for the triangle problem", SIAM Journal on Computing 37 (2): 413–424, arXiv:quant-ph/0310134, doi:10.1137/050643684.
- Makino, K.; Uno, T. (2004), "New algorithms for enumerating all maximal cliques", Algorithm Theory: SWAT 2004, Lecture Notes in Computer Science 3111, Springer-Verlag, pp. 260–272.
- Moon, J. W.; Moser, L. (1965), "On cliques in graphs", Israel Journal of Mathematics 3: 23–28, doi:10.1007/BF02760024, MR 0182577.
- Nešetřil, J.; Poljak, S. (1985), "On the complexity of the subgraph problem", Commentationes Mathematicae Universitatis Carolinae 26 (2): 415–419.
- Östergård, P. R. J. (2002), "A fast algorithm for the maximum clique problem", Discrete Applied Mathematics 120 (1–3): 197–207, doi:10.1016/S0166-218X(01)00290-6.
- Ouyang, Q.; Kaplan, P. D.; Liu, S.; Libchaber, A. (1997), "DNA solution of the maximal clique problem", Science 278 (5337): 446–449, doi:10.1126/science.278.5337.446, PMID 9334300.
- Pardalos, P. M.; Rogers, G. P. (1992), "A branch and bound algorithm for the maximum clique problem", Computers & Operations Research 19 (5): 363–375, doi:10.1016/0305-0548(92)90067-F.
- Razborov, A. A. (1985), "Lower bounds for the monotone complexity of some Boolean functions", Proceedings of the USSR Academy of Sciences (in Russian) 281: 798–801. English translation in Sov. Math. Dokl. 31 (1985): 354–357.
- Régin, J.-C. (2003), "Using constraint programming to solve the maximum clique problem", Proc. 9th Int. Conf. Principles and Practice of Constraint Programming – CP 2003, Lecture Notes in Computer Science 2833, Springer-Verlag, pp. 634–648.
- Robson, J. M. (1986), "Algorithms for maximum independent sets", Journal of Algorithms 7 (3): 425–440, doi:10.1016/0196-6774(86)90032-5.
- Robson, J. M. (2001), Finding a maximum independent set in time O(2n/4).
- Rosgen, B; Stewart, L (2007), "Complexity results on graphs with few cliques", Discrete Mathematics and Theoretical Computer Science 9 (1): 127–136.
- Sipser, M. (1996), Introduction to the Theory of Computation, International Thompson Publishing, ISBN 0-534-94728-X.
- Song, Y. (2015), "On the independent set problem in random graphs", International Journal of Computer Mathematics 92 (11): 2233–2242.
- Tarjan, R. E.; Trojanowski, A. E. (1977), "Finding a maximum independent set" (PDF), SIAM Journal on Computing 6 (3): 537–546, doi:10.1137/0206038.
- Tomita, E.; Kameda, T. (2007), "An efficient branch-and-bound algorithm for finding a maximum clique with computational experiments", Journal of Global Optimization 37 (1): 95–111, doi:10.1007/s10898-006-9039-7.
- Tomita, E.; Seki, T. (2003), "An Efficient Branch-and-Bound Algorithm for Finding a Maximum Clique", Discrete Mathematics and Theoretical Computer Science, Lecture Notes in Computer Science 2731, Springer-Verlag, pp. 278–289, doi:10.1007/3-540-45066-1_22, ISBN 978-3-540-40505-4.
- Tomita, E.; Tanaka, A.; Takahashi, H. (2006), "The worst-case time complexity for generating all maximal cliques and computational experiments", Theoretical Computer Science 363 (1): 28–42, doi:10.1016/j.tcs.2006.06.015.
- Tsukiyama, S.; Ide, M.; Ariyoshi, I.; Shirakawa, I. (1977), "A new algorithm for generating all the maximal independent sets", SIAM Journal on Computing 6 (3): 505–517, doi:10.1137/0206036.
- Valiant, L. G. (1983), "Exponential lower bounds for restricted monotone circuits", Proc. 15th ACM Symposium on Theory of Computing, pp. 110–117, doi:10.1145/800061.808739, ISBN 0-89791-099-0.
- Vassilevska, V.; Williams, R. (2009), "Finding, minimizing, and counting weighted subgraphs", Proc. 41st ACM Symposium on Theory of Computing, pp. 455–464, doi:10.1145/1536414.1536477, ISBN 978-1-60558-506-2.
- Wegener, I. (1988), "On the complexity of branching programs and decision trees for clique functions", Journal of the ACM 35 (2): 461–472, doi:10.1145/42282.46161.
- Yuster, R. (2006), "Finding and counting cliques and independent sets in r-uniform hypergraphs", Information Processing Letters 99 (4): 130–134, doi:10.1016/j.ipl.2006.04.005.
- Zuckerman, D. (2006), "Linear degree extractors and the inapproximability of max clique and chromatic number", Proc. 38th ACM Symp. Theory of Computing, pp. 681–690, doi:10.1145/1132516.1132612, ISBN 1-59593-134-1, ECCC TR05-100.