Matrix exponential
In mathematics, the matrix exponential is a matrix function on square matrices analogous to the ordinary exponential function. Abstractly, the matrix exponential gives the connection between a matrix Lie algebra and the corresponding Lie group.
Let X be an n×n real or complex matrix. The exponential of X, denoted by eX or exp(X), is the n×n matrix given by the power series

The above series always converges, so the exponential of X is well-defined. If X is a 1×1 matrix the matrix exponential of X is a 1×1 matrix whose single element is the ordinary exponential of the single element of X.
Properties
Let X and Y be n×n complex matrices and let a and b be arbitrary complex numbers. We denote the n×n identity matrix by I and the zero matrix by 0. The matrix exponential satisfies the following properties:[1]
- e0 = I
- eaXebX = e(a + b)X
- eXe−X = I
- If XY = YX then eXeY = eYeX = e(X + Y).
- If Y is invertible then eYXY−1 = YeXY−1.
- exp(XT) = (exp X)T, where XT denotes the transpose of X. It follows that if X is symmetric then eX is also symmetric, and that if X is skew-symmetric then eX is orthogonal.
- exp(X∗) = (exp X)∗, where X∗ denotes the conjugate transpose of X. It follows that if X is Hermitian then eX is also Hermitian, and that if X is skew-Hermitian then eX is unitary.
- A Laplace transform of matrix exponentials amounts to the resolvent, ∫0∞dt e−t etX = I / (I−X).
Linear differential equation systems
One of the reasons for the importance of the matrix exponential is that it can be used to solve systems of linear ordinary differential equations. The solution of

where A is a constant matrix, is given by

The matrix exponential can also be used to solve the inhomogeneous equation

See the section on applications below for examples.
There is no closed-form solution for differential equations of the form

where A is not constant, but the Magnus series gives the solution as an infinite sum.
The exponential of sums
For any real numbers (scalars) x and y we know that the exponential function satisfies ex+y = ex ey. The same is true for commuting matrices. If matrices X and Y commute (meaning that XY = YX), then

However, for matrices that do not commute the above equality does not necessarily hold. In this case the Baker–Campbell–Hausdorff formula can be used to calculate eX+Y.
The converse is not true in general. The equation eX+Y = eX eY does not imply that X and Y commute.
For Hermitian matrices there are two notable theorems related to the trace of matrix exponentials.
Golden–Thompson inequality
If A and H are Hermitian matrices, then

Note that there is no requirement of commutativity. There are counterexamples to show that the Golden–Thompson inequality cannot be extended to three matrices – and, in any event, tr(exp(A)exp(B)exp(C)) is not guaranteed to be real for Hermitian A, B, C. However, the next theorem accomplishes this in one sense.
Lieb's theorem
The Lieb's theorem, named after Elliott H. Lieb, states that, for a fixed Hermitian matrix H, the function
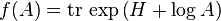
is concave on the cone of positive-definite matrices.[3]
The exponential map
Note that the exponential of a matrix is always an invertible matrix. The inverse matrix of eX is given by e−X. This is analogous to the fact that the exponential of a complex number is always nonzero. The matrix exponential then gives us a map

from the space of all n×n matrices to the general linear group of degree n, i.e. the group of all n×n invertible matrices. In fact, this map is surjective which means that every invertible matrix can be written as the exponential of some other matrix[4] (for this, it is essential to consider the field C of complex numbers and not R).
For any two matrices X and Y,

where || · || denotes an arbitrary matrix norm. It follows that the exponential map is continuous and Lipschitz continuous on compact subsets of Mn(C).
The map

defines a smooth curve in the general linear group which passes through the identity element at t = 0.
In fact, this gives a one-parameter subgroup of the general linear group since
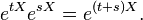
The derivative of this curve (or tangent vector) at a point t is given by

The derivative at t = 0 is just the matrix X, which is to say that X generates this one-parameter subgroup.
More generally,[5] for a generic t-dependent exponent, X(t),

Taking the above expression eX(t) outside the integral sign and expanding the integrand with the help of the Hadamard lemma one can obtain the following useful expression for the derivative of the matrix exponent,
![\left(\frac{d}{dt}e^{X(t)}\right)e^{-X(t)} = \frac{d}{dt}X(t) + \frac{1}{2!}[X(t),\frac{d}{dt}X(t)] + \frac{1}{3!}[X(t),[X(t),\frac{d}{dt}X(t)]]+\cdots](../I/m/c2828f71dabd324d2b27bfa8bb89fd31.png)
Note that the coefficients in the expression above are different from what appears in the exponential. For a closed form, see derivative of the exponential map.
The determinant of the matrix exponential
By Jacobi's formula, for any complex square matrix the following trace identity holds:[6]

In addition to providing a computational tool, this formula demonstrates that a matrix exponential is always an invertible matrix. This follows from the fact that the right hand side of the above equation is always non-zero, and so det(eA) ≠ 0, which implies that eA must be invertible.
In the real-valued case, the formula also exhibits the map
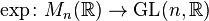
to not be surjective, in contrast to the complex case mentioned earlier. This follows from the fact that, for real-valued matrices, the right-hand side of the formula is always positive, while there exist invertible matrices with a negative determinant.
Computing the matrix exponential
Finding reliable and accurate methods to compute the matrix exponential is difficult, and this is still a topic of considerable current research in mathematics and numerical analysis. Matlab, GNU Octave, and SciPy all use the Padé approximant.[7][8][9]
Diagonalizable case
If a matrix is diagonal:
 ,
,
then its exponential can be obtained by exponentiating each entry on the main diagonal:
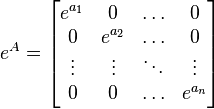 .
.
This also allows one to exponentiate diagonalizable matrices. If A = UDU−1 and D is diagonal, then eA = UeDU−1. Application of Sylvester's formula yields the same result. (To see this, note that addition and multiplication, hence also exponentiation, of diagonal matrices is equivalent to element-wise addition and multiplication, and hence exponentiation; in particular, the "one-dimensional" exponentiation is felt element-wise for the diagonal case.)
Projection case
If P is a projection matrix (i.e. is idempotent), its matrix exponential is eP = I + (e − 1)P. This may be derived by expansion of the definition of the exponential function and by use of the idempotency of P:
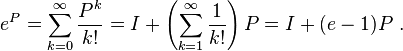
Rotation case
For a simple rotation in which the perpendicular unit vectors a and b specify a plane,[10] the rotation matrix R can be expressed in terms of a similar exponential function involving a generator G and angle θ.[11][12]



The formula for the exponential results from reducing the powers of G in the series expansion and identifying the respective series coefficients of G2 and G with −cos(θ) and sin(θ) respectively. The second expression here for eGθ is the same as the expression for R(θ) in the article containing the derivation of the generator, R(θ) = eGθ.
In two dimensions, if  and
and  , then
, then  ,
,  , and
, and

reduces to the standard matrix for a plane rotation.
The matrix P = −G2 projects a vector onto the ab-plane and the rotation only affects this part of the vector. An example illustrating this is a rotation of 30° = π/6 in the plane spanned by a and b,
Let N = I − P, so N2 = N and its products with P and G are zero. This will allow us to evaluate powers of R.

Nilpotent case
A matrix N is nilpotent if Nq = 0 for some integer q. In this case, the matrix exponential eN can be computed directly from the series expansion, as the series terminates after a finite number of terms:
Generalization
When the minimal polynomial of a matrix X can be factored into a product of first degree polynomials, it can be expressed as a sum

where
- A is diagonalizable
- N is nilpotent
- A commutes with N (i.e. AN = NA)
This is the Jordan–Chevalley decomposition.
This means that we can compute the exponential of X by reducing to the previous two cases:

Note that we need the commutativity of A and N for the last step to work.
Another (closely related) method if the field is algebraically closed is to work with the Jordan form of X. Suppose that X = PJP −1 where J is the Jordan form of X. Then
Also, since
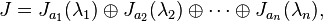

Therefore, we need only know how to compute the matrix exponential of a Jordan block. But each Jordan block is of the form

where N is a special nilpotent matrix. The matrix exponential of this block is given by
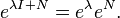
Evaluation by Laurent series
By virtue of the Cayley–Hamilton theorem the matrix exponential is expressible as a polynomial of order n−1.
If P and Qt are nonzero polynomials in one variable, such that P(A) = 0, and if the meromorphic function

is entire, then
 .
.
To prove this, multiply the first of the two above equalities by P(z) and replace z by A.
Such a polynomial Qt(z) can be found as follows−−see Sylvester's formula. Letting a be a root of P, Qa,t(z) is solved from the product of P by the principal part of the Laurent series of f at a: It is proportional to the relevant Frobenius covariant. Then the sum St of the Qa,t, where a runs over all the roots of P, can be taken as a particular Qt. All the other Qt will be obtained by adding a multiple of P to St(z). In particular, St(z), the Lagrange-Sylvester polynomial, is the only Qt whose degree is less than that of P.
Example: Consider the case of an arbitrary 2-by-2 matrix,

The exponential matrix etA, by virtue of the Cayley–Hamilton theorem, must be of the form
 .
.
(For any complex number z and any C-algebra B, we denote again by z the product of z by the unit of B.)
Let α and β be the roots of the characteristic polynomial of A,

Then we have
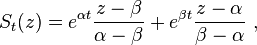
and hence

if α ≠ β; while, if α = β,
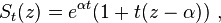
so that
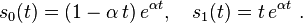
Defining

we have

where sin(qt)/q is 0 if t = 0, and t if q = 0. Thus,

Thus, as indicated above, the matrix A having decomposed into the sum of two mutually commuting pieces, the traceful piece and the traceless piece,
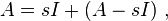
the matrix exponential reduces to a plain product of the exponentials of the two respective pieces. This is a formula often used in physics, as it amounts to the analog of Euler's formula for Pauli spin matrices, that is rotations of the doublet representation of the group SU(2).
The polynomial St can also be given the following "interpolation" characterization. Define et(z) ≡ etz, and n ≡ degP. Then St(z) is the unique degree < n polynomial which satisfies St(k)(a) = et(k)(a) whenever k is less than the multiplicity of a as a root of P. We assume, as we obviously can, that P is the minimal polynomial of A. We further assume that A is a diagonalizable matrix. In particular, the roots of P are simple, and the "interpolation" characterization indicates that St is given by the Lagrange interpolation formula, so it is the Lagrange−Sylvester polynomial .
At the other extreme, if P = (z−a)n, then

The simplest case not covered by the above observations is when  with a ≠ b, which yields
with a ≠ b, which yields

Evaluation by implementation of Sylvester's formula
A practical, expedited computation of the above reduces to the following rapid steps. Recall from above that an n×n matrix exp(tA) amounts to a linear combination of the first n−1 powers of A by the Cayley-Hamilton theorem. For diagonalizable matrices, as illustrated above, e.g. in the 2×2 case, Sylvester's formula yields exp(tA) = Bα exp(tα)+Bβ exp(tβ), where the Bs are the Frobenius covariants of A.
It is easiest, however, to simply solve for these Bs directly, by evaluating this expression and its first derivative at t=0, in terms of A and I, to find the same answer as above.
But this simple procedure also works for defective matrices, in a generalization due to Buchheim.[13] This is illustrated here for a 4×4 example of a matrix which is not diagonalizable, and the Bs are not projection matrices.
Consider

with eigenvalues λ1=3/4 and λ2=1, each with a multiplicity of two.
Consider the exponential of each eigenvalue multiplied by t, exp(λit). Multiply each such by the corresponding undetermined coefficient matrix Bi. If the eigenvalues have an algebraic multiplicity greater than 1, then repeat the process, but now multiplying by an extra factor of t for each repetition, to ensure linear independence.
(If one eigenvalue had a multiplicity of three, then there would be the three terms:  . By contrast, when all eigenvalues are distinct, the Bs are just the Frobenius covariants, and solving for them as below just amounts to the inversion of the Vandermonde matrix of these 4 eigenvalues.)
. By contrast, when all eigenvalues are distinct, the Bs are just the Frobenius covariants, and solving for them as below just amounts to the inversion of the Vandermonde matrix of these 4 eigenvalues.)
Sum all such terms, here four such,
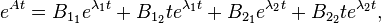
 .
.
To solve for all of the unknown matrices B in terms of the first three powers of A and the identity, one needs four equations, the above one providing one such at t =0. Further, differentiate it with respect to t,
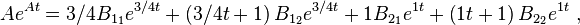
and again,
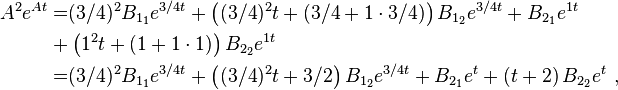
and once more,
 .
.
(In the general case, n−1 derivatives need be taken.)
Setting t=0 in these four equations, the four coefficient matrices Bs may now be solved for,
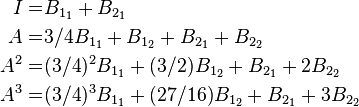 ,
,
to yield
 .
.
Substituting with the value for A yields the coefficient matrices
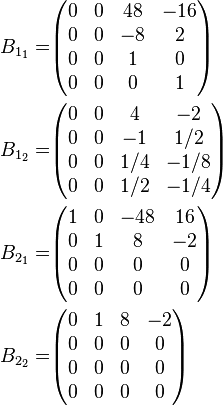
so the final answer is
 .
.
The procedure is much shorter than Putzer's algorithm sometimes utilized in such cases.
Illustrations
Suppose that we want to compute the exponential of

Its Jordan form is

where the matrix P is given by

Let us first calculate exp(J). We have
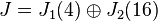
The exponential of a 1×1 matrix is just the exponential of the one entry of the matrix, so exp(J1(4)) = [e4]. The exponential of J2(16) can be calculated by the formula e(λI + N) = eλ eN mentioned above; this yields[14]
![\begin{align}
\exp \left( \begin{bmatrix} 16 & 1 \\ 0 & 16 \end{bmatrix} \right)
& = e^{16} \exp \left( \begin{bmatrix} 0 & 1 \\ 0 & 0 \end{bmatrix} \right) \\[6pt]
& = e^{16} \left(\begin{bmatrix} 1 & 0 \\ 0 & 1 \end{bmatrix} + \begin{bmatrix} 0 & 1 \\ 0 & 0 \end{bmatrix} + {1 \over 2!}\begin{bmatrix} 0 & 0 \\ 0 & 0 \end{bmatrix} + \cdots \right)
= \begin{bmatrix} e^{16} & e^{16} \\ 0 & e^{16} \end{bmatrix}.
\end{align}](../I/m/e0d7e11df7f5bb619dd71e936b742f0e.png)
Therefore, the exponential of the original matrix B is
![\begin{align}
\exp(B)
& = P \exp(J) P^{-1}
= P \begin{bmatrix} e^4 & 0 & 0 \\ 0 & e^{16} & e^{16} \\ 0 & 0 & e^{16} \end{bmatrix} P^{-1} \\[6pt]
& = {1\over 4} \begin{bmatrix}
13e^{16} - e^4 & 13e^{16} - 5e^4 & 2e^{16} - 2e^4 \\
-9e^{16} + e^4 & -9e^{16} + 5e^4 & -2e^{16} + 2e^4 \\
16e^{16} & 16e^{16} & 4e^{16}
\end{bmatrix}.
\end{align}](../I/m/ed30c579f00f86414adace5af3300da1.png)
Applications
Linear differential equations
The matrix exponential has applications to systems of linear differential equations. (See also matrix differential equation.) Recall from earlier in this article that a homogeneous differential equation of the form
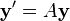
has solution eAt y(0).
If we consider the vector

we can express a system of inhomogeneous coupled linear differential equations as

Making an ansatz to use an integrating factor of e−At and multiplying throughout, yields



The second step is possible due to the fact that, if AB = BA, then eAtB = BeAt. So, calculating eAt leads to the solution to the system, by simply integrating the third step in ts.
Example (homogeneous)
Consider the system
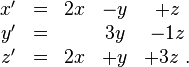
The associated defective matrix is

The matrix exponential is

so that the general solution of the homogeneous system is

amounting to

Example (inhomogeneous)
Consider now the inhomogeneous system

We again have
![A= \left[ \begin{array}{rrr}
2 & -1 & 1 \\
0 & 3 & -1 \\
2 & 1 & 3 \end{array} \right] ~,](../I/m/3264280ffa56445071856b20c23d5e43.png)
and

From before, we already have the general solution to the homogeneous equation. Since the sum of the homogeneous and particular solutions give the general solution to the inhomogeneous problem, we now only need find the particular solution.
We have, by above,



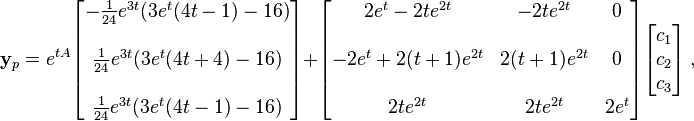
which could be further simplified to get the requisite particular solution determined through variation of parameters. Note c = yp(0). For more rigor, see the following generalization.
Inhomogeneous case generalization: variation of parameters
For the inhomogeneous case, we can use integrating factors (a method akin to variation of parameters). We seek a particular solution of the form yp(t) = exp(tA) z (t) ,
![\begin{align}
\mathbf{y}_p'(t) & = (e^{tA})'\mathbf{z}(t)+e^{tA}\mathbf{z}'(t) \\[6pt]
& = Ae^{tA}\mathbf{z}(t)+e^{tA}\mathbf{z}'(t) \\[6pt]
& = A\mathbf{y}_p(t)+e^{tA}\mathbf{z}'(t)~.
\end{align}](../I/m/96517e47bcab2f56924e65443ffcee29.png)
For yp to be a solution,
![\begin{align}
e^{tA}\mathbf{z}'(t) & = \mathbf{b}(t) \\[6pt]
\mathbf{z}'(t) & = (e^{tA})^{-1}\mathbf{b}(t) \\[6pt]
\mathbf{z}(t) & = \int_0^t e^{-uA}\mathbf{b}(u)\,du+\mathbf{c} ~.
\end{align}](../I/m/d58d772a014ef9d7aff13d1fb7cde69c.png)
Thus,

where c is determined by the initial conditions of the problem.
More precisely, consider the equation

with the initial condition Y(t0) = Y0, where A is an n by n complex matrix,
F is a continuous function from some open interval I to ℂn,
 is a point of I, and
is a point of I, and
 is a vector of ℂn.
is a vector of ℂn.
Left-multiplying the above displayed equality by e−tA yields

We claim that the solution to the equation

with the initial conditions  for 0 ≤ k < n is
for 0 ≤ k < n is

where the notation is as follows:
![P\in\mathbb{C}[X]](../I/m/20f56686c6eaf7e0841ad88aa8362f26.png) is a monic polynomial of degree n > 0,
is a monic polynomial of degree n > 0,
f is a continuous complex valued function defined on some open interval I,
is a point of I,
 is a complex number, and
is a complex number, and
sk(t) is the coefficient of 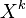 in the polynomial denoted by
in the polynomial denoted by ![S_t\in\mathbb{C}[X]](../I/m/bad75894959eff359dd42def6e3b6f48.png) in Subsection Evaluation by Laurent series above.
in Subsection Evaluation by Laurent series above.
To justify this claim, we transform our order n scalar equation into an order one vector equation by the usual reduction to a first order system. Our vector equation takes the form

where A is the transpose companion matrix of P. We solve this equation as explained above, computing the matrix exponentials by the observation made in Subsection Alternative above.
In the case n = 2 we get the following statement. The solution to

is

where the functions s0 and s1 are as in Subsection Evaluation by Laurent series above.
Matrix-matrix exponentials
The matrix exponential of another matrix (matrix-matrix exponential),[15] is defined as

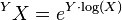
for X any normal and non-singular n×n matrix, and Y any complex n×n matrix.
For matrix-matrix exponentials, there is a distinction between the left exponential YX and the right exponential XY, because the multiplication operator for matrix-to-matrix is not commutative. Moreover,
- If X is normal and non-singular, then XY and YX have the same set of eigenvalues.
- If X is normal and non-singular, Y is normal, and XY = YX, then XY = YX.
- If X is normal and non-singular, and X, Y, Z commute with each other, then XY+Z = XY·XZ and Y+ZX = YX·ZX.
See also
References
- ↑ Hall 2015 Proposition 2.3
- ↑ Bhatia, R. (1997). Matrix Analysis. Graduate Texts in Mathematics 169. Springer. ISBN 978-0-387-94846-1.
- ↑ E. H. Lieb (1973). "Convex trace functions and the Wigner–Yanase–Dyson conjecture". Adv. Math. 11 (3): 267–288. doi:10.1016/0001-8708(73)90011-X. H. Epstein (1973). "Remarks on two theorems of E. Lieb". Commun Math. Phys. 31 (4): 317–325. doi:10.1007/BF01646492.
- ↑ Hall 2015 Exercises 2.9 and 2.10
- ↑ R. M. Wilcox (1967). "Exponential Operators and Parameter Differentiation in Quantum Physics". Journal of Mathematical Physics 8 (4): 962–982. doi:10.1063/1.1705306.
- ↑ Hall 2015 Theorem 2.12
- ↑ "Matrix exponential - MATLAB expm - MathWorks Deutschland". Mathworks.de. 2011-04-30. Retrieved 2013-06-05.
- ↑ "GNU Octave - Functions of a Matrix". Network-theory.co.uk. 2007-01-11. Retrieved 2013-06-05.
- ↑ "scipy.linalg.expm function documentation". The SciPy Community. 2015-01-18. Retrieved 2015-05-29.
- ↑ in a Euclidean space
- ↑ Weyl, Hermann (1952). Space Time Matter. Dover. p. 142. ISBN 0-486-60267-2.
- ↑ Bjorken, James D.; Drell, Sidney D. (1964). Relativistic Quantum Mechanics. McGraw-Hill. p. 22.
- ↑ Rinehart, R. F. (1955). "The equivalence of definitions of a matric function". The American Mathematical Monthly, 62 (6), 395-414.
- ↑ This can be generalized; in general, the exponential of Jn(a) is an upper triangular matrix with ea/0! on the main diagonal, ea/1! on the one above, ea/2! on the next one, and so on.
- ↑ Ignacio Barradas and Joel E. Cohen (1994). "Iterated Exponentiation, Matrix-Matrix Exponentiation, and Entropy" (PDF). Academic Press, Inc.
- Hall, Brian C. (2015), Lie groups, Lie algebras, and representations: An elementary introduction, Graduate Texts in Mathematics 222 (2nd ed.), Springer
- Horn, Roger A.; Johnson, Charles R. (1991). Topics in Matrix Analysis. Cambridge University Press. ISBN 978-0-521-46713-1..
- Moler, Cleve; Van Loan, Charles F. (2003). "Nineteen Dubious Ways to Compute the Exponential of a Matrix, Twenty-Five Years Later" (PDF). SIAM Review 45 (1): 3–49. doi:10.1137/S00361445024180. ISSN 1095-7200..
- Suzuki, Masuo (1985). "Decomposition formulas of exponential operators and Lie exponentials with some applications to quantum mechanics and statistical physics". Journal of Mathematical Physics 26: 601. doi:10.1063/1.526596.
- Curtright, T L; Fairlie, D B; Zachos, C K (2014). "A compact formula for rotations as spin matrix polynomials". SIGMA 10: 084. doi:10.3842/SIGMA.2014.084.
- Householder, Alston S. (2006). The Theory of Matrices in Numerical Analysis. Dover Books on Mathematics. ISBN 0486449726.