Eigenvalue algorithm
In numerical analysis, one of the most important problems is designing efficient and stable algorithms for finding the eigenvalues of a matrix, or for a continuous linear operator (for example, the eigenvectors of the Hamiltonian of a particular quantum system are the different energy eigenstates of that system and their eigenvalues are the corresponding energy levels). These eigenvalue algorithms may also find eigenvectors.
Eigenvalues and eigenvectors
Given an n × n square matrix A of real or complex numbers, an eigenvalue λ and its associated generalized eigenvector v are a pair obeying the relation[1]
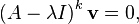
where v is a nonzero n × 1 column vector, I is the n × n identity matrix, k is a positive integer, and both λ and v are allowed to be complex even when A is real. When k = 1, the vector is called simply an eigenvector, and the pair is called an eigenpair. In this case, Av = λv. Any eigenvalue λ of A has ordinary[note 1] eigenvectors associated to it, for if k is the smallest integer such that (A - λI)k v = 0 for a generalized eigenvector v, then (A - λI)k-1 v is an ordinary eigenvector. The value k can always be taken as less than or equal to n. In particular, (A - λI)n v = 0 for all generalized eigenvectors v associated with λ.
For each eigenvalue λ of A, the kernel ker(A - λI) consists of all eigenvectors associated with λ (along with 0), called the eigenspace of λ, while the vector space ker((A - λI)n) consists of all generalized eigenvectors, and is called the generalized eigenspace. The geometric multiplicity of λ is the dimension of its eigenspace. The algebraic multiplicity of λ is the dimension of its generalized eigenspace. The latter terminology is justified by the equation
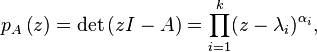
where det is the determinant function, the λi are all the distinct eigenvalues of A and the αi are the corresponding algebraic multiplicities. The function pA(z) is the characteristic polynomial of A. So the algebraic multiplicity is the multiplicity of the eigenvalue as a zero of the characteristic polynomial. Since any eigenvector is also a generalized eigenvector, the geometric multiplicity is less than or equal to the algebraic multiplicity. The algebraic multiplicities sum up to n, the degree of the characteristic polynomial. The equation pA(z) = 0 is called the characteristic equation, as its roots are exactly the eigenvalues of A. By the Cayley-Hamilton theorem, A itself obeys the same equation: pA(A) = 0.[note 2] As a consequence, the columns of the matrix 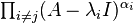 must be either 0 or generalized eigenvectors of the eigenvalue λj, since they are annihilated by
must be either 0 or generalized eigenvectors of the eigenvalue λj, since they are annihilated by 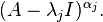 In fact, the column space is the generalized eigenspace of λj.
In fact, the column space is the generalized eigenspace of λj.
Any collection of generalized eigenvectors of distinct eigenvalues is linearly independent, so a basis for all of C n can be chosen consisting of generalized eigenvectors. More particularly, this basis {vi}n
i=1 can be chosen and organized so that
- if vi and vj have the same eigenvalue, then so does vk for each k between i and j, and
- if vi is not an ordinary eigenvector, and if λi is its eigenvalue, then (A - λiI )vi = vi-1 (in particular, v1 must be an ordinary eigenvector).
If these basis vectors are placed as the column vectors of a matrix V = [ v1 v2 ... vn ], then V can be used to convert A to its Jordan normal form:
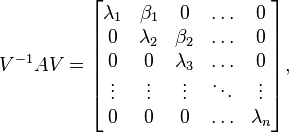
where the λi are the eigenvalues, βi = 1 if (A - λi+1)vi+1 = vi and βi = 0 otherwise.
More generally, if W is any invertible matrix, and λ is an eigenvalue of A with generalized eigenvector v, then (W−1AW - λI )k W−kv = 0. Thus λ is an eigenvalue of W−1AW with generalized eigenvector W−kv. That is, similar matrices have the same eigenvalues.
Normal, hermitian, and real-symmetric matrices
The adjoint M* of a complex matrix M is the transpose of the conjugate of M: M * = M T. A square matrix A is called normal if it commutes with its adjoint: A*A = AA*. It is called hermitian if it is equal to its adjoint: A* = A. All hermitian matrices are normal. If A has only real elements, then the adjoint is just the transpose, and A is hermitian if and only if it is symmetric. When applied to column vectors, the adjoint can be used to define the canonical inner product on C n: w • v = w* v.[note 3] Normal, hermitian, and real-symmetric matrices have several useful properties:
- Every generalized eigenvector of a normal matrix is an ordinary eigenvector.
- Any normal matrix is similar to a diagonal matrix, since its Jordan normal form is diagonal.
- Eigenvectors of distinct eigenvalues of a normal matrix are orthogonal.
- For any normal matrix A, C n has an orthonormal basis consisting of eigenvectors of A. The corresponding matrix of eigenvectors is unitary.
- The eigenvalues of a hermitian matrix are real, since (λ - λ)v = (A* - A)v = (A - A)v = 0 for a non-zero eigenvector v.
- If A is real, there is an orthonormal basis for R n consisting of eigenvectors of A if and only if A is symmetric.
It is possible for a real or complex matrix to have all real eigenvalues without being hermitian. For example, a real triangular matrix has its eigenvalues along its diagonal, but in general is not symmetric.
Condition number
Any problem of numeric calculation can be viewed as the evaluation of some function ƒ for some input x. The condition number κ(ƒ, x) of the problem is the ratio of the relative error in the function's output to the relative error in the input, and varies with both the function and the input. The condition number describes how error grows during the calculation. Its base-10 logarithm tells how many fewer digits of accuracy exist in the result than existed in the input. The condition number is a best-case scenario. It reflects the instability built into the problem, regardless of how it is solved. No algorithm can ever produce more accurate results than indicated by the condition number, except by chance. However, a poorly designed algorithm may produce significantly worse results. For example, as mentioned below, the problem of finding eigenvalues for normal matrices is always well-conditioned. However, the problem of finding the roots of a polynomial can be very ill-conditioned. Thus eigenvalue algorithms that work by finding the roots of the characteristic polynomial can be ill-conditioned even when the problem is not.
For the problem of solving the linear equation Av = b where A is invertible, the condition number κ(A−1, b) is given by ||A||op||A−1||op, where || ||op is the operator norm subordinate to the normal Euclidean norm on C n. Since this number is independent of b and is the same for A and A−1, it is usually just called the condition number κ(A) of the matrix A. This value κ(A) is also the absolute value of the ratio of the largest eigenvalue of A to its smallest. If A is unitary, then ||A||op = ||A−1||op = 1, so κ(A) = 1. For general matrices, the operator norm is often difficult to calculate. For this reason, other matrix norms are commonly used to estimate the condition number.
For the eigenvalue problem, Bauer and Fike proved that if λ is an eigenvalue for a diagonalizable n × n matrix A with eigenvector matrix V, then the absolute error in calculating λ is bounded by the product of κ(V) and the absolute error in A.[2] As a result, the condition number for finding λ is κ(λ, A) = κ(V) = ||V ||op ||V −1||op. If A is normal, then V is unitary, and κ(λ, A) = 1. Thus the eigenvalue problem for all normal matrices is well-conditioned.
The condition number for the problem of finding the eigenspace of a normal matrix A corresponding to an eigenvalue λ has been shown to be inversely proportional to the minimum distance between λ and the other distinct eigenvalues of A.[3] In particular, the eigenspace problem for normal matrices is well-conditioned for isolated eigenvalues. When eigenvalues are not isolated, the best that can be hoped for is to identify the span of all eigenvectors of nearby eigenvalues.
Algorithms
Any monic polynomial is the characteristic polynomial of its companion matrix. Therefore a general algorithm for finding eigenvalues could also be used to find the roots of polynomials. The Abel-Ruffini theorem shows that any such algorithm for dimensions greater than 4 must either be infinite, or involve functions of greater complexity than elementary arithmetic operations and fractional powers. For this reason algorithms that exactly calculate eigenvalues in a finite number of steps only exist for a few special classes of matrices. For general matrices, algorithms are iterative, producing better approximate solutions with each iteration.
Some algorithms produce every eigenvalue, others will produce a few, or only one. However, even the latter algorithms can be used to find all eigenvalues. Once an eigenvalue λ of a matrix A has been identified, it can be used to either direct the algorithm towards a different solution next time, or to reduce the problem to one that no longer has λ as a solution.
Redirection is usually accomplished by shifting: replacing A with A - μI for some constant μ. The eigenvalue found for A - μI must have μ added back in to get an eigenvalue for A. For example, for power iteration, μ = λ. Power iteration finds the largest eigenvalue in absolute value, so even when λ is only an approximate eigenvalue, power iteration is unlikely to find it a second time. Conversely, inverse iteration based methods find the lowest eigenvalue, so μ is chosen well away from λ and hopefully closer to some other eigenvalue.
Reduction can be accomplished by restricting A to the column space of the matrix A - λI, which A carries to itself. Since A - λI is singular, the column space is of lesser dimension. The eigenvalue algorithm can then be applied to the restricted matrix. This process can be repeated until all eigenvalues are found.
If an eigenvalue algorithm does not produce eigenvectors, a common practice is to use an inverse iteration based algorithm with μ set to a close approximation to the eigenvalue. This will quickly converge to the eigenvector of the closest eigenvalue to μ. For small matrices, an alternative is to look at the column space of the product of A - λ'I for each of the other eigenvalues λ'.
Hessenberg and Tri-diagonal matrices
Because the eigenvalues of a triangular matrix are its diagonal elements, for general matrices there is no finite method like gaussian elimination to convert a matrix to triangular form while preserving eigenvalues. But it is possible to reach something close to triangular. An upper Hessenberg matrix is a square matrix for which all entries below the subdiagonal are zero. A lower Hessenberg matrix is one for which all entries above the superdiagonal are zero. Matrices that are both upper and lower Hessenberg are tridiagonal. Hessenberg and tridiagonal matrices are the starting points for many eigenvalue algorithms because the zero entries reduce the complexity of the problem. Several methods are commonly used to convert a general matrix into a Hessenberg matrix with the same eigenvalues. If the original matrix was symmetric or hermitian, then the resulting matrix will be tridiagonal.
When only eigenvalues are needed, there is no need to calculate the similarity matrix, as the transformed matrix has the same eigenvalues. If eigenvectors are needed as well, the similarity matrix may be needed to transform the eigenvectors of the Hessenberg matrix back into eigenvectors of the original matrix.
| Method | Applies to | Produces | Cost without similarity matrix | Cost with similarity matrix | Description |
|---|---|---|---|---|---|
| Householder transformations | General | Hessenberg | 2n3⁄3 + O(n2)[4](p474) | 4n3⁄3 + O(n2)[4](p474) | Reflect each column through a subspace to zero out its lower entries. |
| Givens rotations | General | Hessenberg | 4n3⁄3 + O(n2)[4](p470) | Apply planar rotations to zero out individual entries. Rotations are ordered so that later ones do not cause zero entries to become non-zero again. | |
| Arnoldi iteration | General | Hessenberg | Perform Gram–Schmidt orthogonalization on Krylov subspaces. | ||
| Lanczos algorithm | Hermitian | Tridiagonal | Arnoldi iteration for hermitian matrices, with shortcuts. |
Iterative algorithms
Iterative algorithms solve the eigenvalue problem by producing sequences that converge to the eigenvalues. Some algorithms also produce sequences of vectors that converge to the eigenvectors. Most commonly, the eigenvalue sequences are expressed as sequences of similar matrices which converge to a triangular or diagonal form, allowing the eigenvalues to be read easily. The eigenvector sequences are expressed as the corresponding similarity matrices.
| Method | Applies to | Produces | Cost per step | Convergence | Description |
|---|---|---|---|---|---|
| Power iteration | General | eigenpair with largest value | O(n2) | Linear | Repeatedly applies the matrix to an arbitrary starting vector and renormalizes. |
| Inverse iteration | General | eigenpair with value closest to μ | Linear | Power iteration for (A - μI )−1 | |
| Rayleigh quotient iteration | Hermitian | eigenpair with value closest to μ | Cubic | Power iteration for (A - μiI )−1, where μi for each iteration is the Rayleigh quotient of the previous iteration. | |
| Preconditioned Inverse iteration[5] or LOBPCG algorithm | Positive Definite Real Symmetric | eigenpair with value closest to μ | Inverse iteration using a preconditioner (an approximate inverse to A). | ||
| Bisection method | Real Symmetric Tridiagonal | any eigenvalue | linear | Uses the bisection method to find roots of the characteristic polynomial, supported by the Sturm sequence. | |
| Laguerre iteration | Real Symmetric Tridiagonal | any eigenvalue | cubic[6] | Uses Laguerre's method to find roots of the characteristic polynomial, supported by the Sturm sequence. | |
| QR algorithm | Hessenberg | all eigenvalues | O(n2) | cubic | Factors A = QR, where Q is orthogonal and R is triangular, then applies the next iteration to RQ. |
| all eigenpairs | 6n3 + O(n2) | ||||
| Jacobi eigenvalue algorithm | Real Symmetric | all eigenvalues | O(n3) | quadratic | Uses Givens rotations to attempt clearing all off-diagonal entries. This fails, but strengthens the diagonal. |
| Divide-and-conquer | Hermitian Tridiagonal | all eigenvalues | O(n2) | Divides the matrix into submatrices that are diagonalized then recombined. | |
| all eigenpairs | (4⁄3)n3 + O(n2) | ||||
| Homotopy method | Real Symmetric Tridiagonal | all eigenpairs | O(n2)[7] | Constructs a computable homotopy path from a diagonal eigenvalue problem. | |
| Folded spectrum method | Real Symmetric | eigenpair with value closest to μ | Preconditioned inverse iteration applied to (A - μI )2 | ||
| MRRR algorithm[8] | Real Symmetric Tridiagonal | some or all eigenpairs | O(n2) | "Multiple Relatively Robust Representations" - Performs inverse iteration on a LDLT decomposition of the shifted matrix. |
Direct calculation
While there is no simple algorithm to directly calculate eigenvalues for general matrices, there are numerous special classes of matrices where eigenvalues can be directly calculated. These include:
Triangular matrices
Since the determinant of a triangular matrix is the product of its diagonal entries, if T is triangular, then 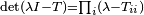 . Thus the eigenvalues of T are its diagonal entries.
. Thus the eigenvalues of T are its diagonal entries.
Factorable polynomial equations
If p is any polynomial and p(A) = 0, then the eigenvalues of A also satisfy the same equation. If p happens to have a known factorization, then the eigenvalues of A lie among its roots.
For example, a projection is a square matrix P satisfying P2 = P. The roots of the corresponding scalar polynomial equation, λ2 = λ, are 0 and 1. Thus any projection has 0 and 1 for its eigenvalues. The multiplicity of 0 as an eigenvalue is the nullity of P, while the multiplicity of 1 is the rank of P.
Another example is a matrix A that satisfies A2 = α2I for some scalar α. The eigenvalues must be ±α. The projection operators
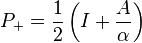
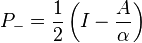
satisfy
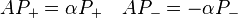
and
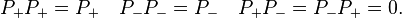
The column spaces of P+ and P- are the eigenspaces of A corresponding to +α and -α, respectively.
2×2 matrices
For dimensions 2 through 4, formulas involving radicals exist that can be used to find the eigenvalues. While a common practice for 2×2 and 3×3 matrices, for 4×4 matrices the increasing complexity of the root formulas makes this approach less attractive.
For the 2×2 matrix
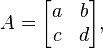
the characteristic polynomial is
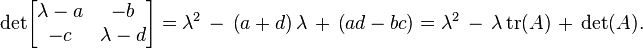
Thus the eigenvalues can be found by using the quadratic formula:
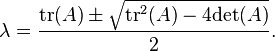
Defining 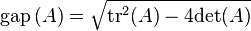 to be the distance between the two eigenvalues, it is straightforward to calculate
to be the distance between the two eigenvalues, it is straightforward to calculate
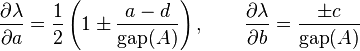
with similar formulas for c and d. From this it follows that the calculation is well-conditioned if the eigenvalues are isolated.
Eigenvectors can be found by exploiting the Cayley-Hamilton theorem. If λ1, λ2 are the eigenvalues, then (A - λ1I )(A - λ2I ) = (A - λ2I )(A - λ1I ) = 0, so the columns of (A - λ2I ) are annihilated by (A - λ1I ) and vice versa. Assuming neither matrix is zero, the columns of each must include eigenvectors for the other eigenvalue. (If either matrix is zero, then A is a multiple of the identity and any non-zero vector is an eigenvector.)
For example, suppose
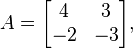
then tr(A) = 4 - 3 = 1 and det(A) = 4(-3) - 3(-2) = -6, so the characteristic equation is
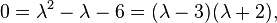
and the eigenvalues are 3 and -2. Now,
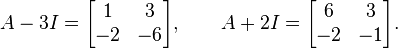
In both matrices, the columns are multiples of each other, so either column can be used. Thus, (1, -2) can be taken as an eigenvector associated with the eigenvalue -2, and (3, -1) as an eigenvector associated with the eigenvalue 3, as can be verified by multiplying them by A.
3×3 matrices
If A is a 3×3 matrix, then its characteristic equation can be expressed as:
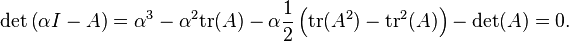
This equation may be solved using the methods of Cardano or Lagrange, but an affine change to A will simplify the expression considerably, and lead directly to a trigonometric solution. If A = pB + qI, then A and B have the same eigenvectors, and β is an eigenvalue of B if and only if α = pβ + q is an eigenvalue of A. Letting 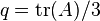 and
and 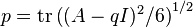 , gives
, gives
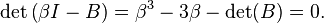
The substitution β = 2cos θ and some simplification using the identity cos 3θ = 4cos3 θ - 3cos θ reduces the equation to cos 3θ = det(B) / 2. Thus
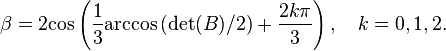
If det(B) is complex or is greater than 2 in absolute value, the arccosine should be taken along the same branch for all three values of k. This issue doesn't arise when A is real and symmetric, resulting in a simple algorithm:[9]
% Given a real symmetric 3x3 matrix A, compute the eigenvalues
p1 = A(1,2)^2 + A(1,3)^2 + A(2,3)^2
if (p1 == 0)
% A is diagonal.
eig1 = A(1,1)
eig2 = A(2,2)
eig3 = A(3,3)
else
q = trace(A)/3
p2 = (A(1,1) - q)^2 + (A(2,2) - q)^2 + (A(3,3) - q)^2 + 2 * p1
p = sqrt(p2 / 6)
B = (1 / p) * (A - q * I) % I is the identity matrix
r = det(B) / 2
% In exact arithmetic for a symmetric matrix -1 <= r <= 1
% but computation error can leave it slightly outside this range.
if (r <= -1)
phi = pi / 3
elseif (r >= 1)
phi = 0
else
phi = acos(r) / 3
end
% the eigenvalues satisfy eig3 <= eig2 <= eig1
eig1 = q + 2 * p * cos(phi)
eig3 = q + 2 * p * cos(phi + (2*pi/3))
eig2 = 3 * q - eig1 - eig3 % since trace(A) = eig1 + eig2 + eig3
end
Once again, the eigenvectors of A can be obtained by recourse to the Cayley-Hamilton theorem. If α1, α2, α3 are distinct eigenvalues of A, then (A - α1I)(A - α2I)(A - α3I) = 0. Thus the columns of the product of any two of these matrices will contain an eigenvector for the third eigenvalue. However, if a3 = a1, then (A - α1I)2(A - α2I) = 0 and (A - α2I)(A - α1I)2 = 0. Thus the generalized eigenspace of α1 is spanned by the columns of A - α2I while the ordinary eigenspace is spanned by the columns of (A - α1I)(A - α2I). The ordinary eigenspace of α2 is spanned by the columns of (A - α1I)2.
For example, let
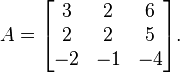
The characteristic equation is
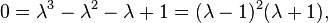
with eigenvalues 1 (of multiplicity 2) and -1. Calculating,

and
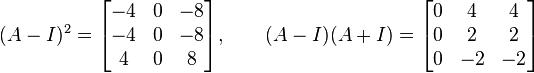
Thus (-4, -4, 4) is an eigenvector for -1, and (4, 2, -2) is an eigenvector for 1. (2, 3, -1) and (6, 5, -3) are both generalized eigenvectors associated with 1, either one of which could be combined with (-4, -4, 4) and (4, 2, -2) to form a basis of generalized eigenvectors of A.In some routine eigenvectors are normalized to one, in such case make sure you normalized by column.
See also
Notes
- ↑ The term "ordinary" is used here only to emphasize the distinction between "eigenvector" and "generalized eigenvector".
- ↑ where the constant term is multiplied by the identity matrix I.
- ↑ This ordering of the inner product (with the conjugate-linear position on the left), is preferred by physicists. Algebraists often place the conjugate-linear position on the right: w • v = v* w.
References
- ↑ Axler, Sheldon (1995), "Down with Determinants!" (PDF), American Mathematical Monthly 102: 139–154, doi:10.2307/2975348
- ↑ F. L. Bauer; C. T. Fike (1960), "Norms and exclusion theorems", Numer. Math. 2: 137–141, doi:10.1007/bf01386217
- ↑ S.C. Eisenstat; I.C.F. Ipsen (1998), "Relative Perturbation Results for Eigenvalues and Eigenvectors of Diagonalisable Matrices", BIT 38 (3): 502–9, doi:10.1007/bf02510256
- 1 2 3 Press, William H.; Teukolsky, Saul A.; Vetterling, William T.; Flannery, Brian P. (1992). Numerical Recipes in C (2nd ed.). Cambridge University Press. ISBN 0-521-43108-5.
- ↑ Neymeyr, K. (2006), "A geometric theory for preconditioned inverse iteration IV: On the fastest convergence cases.", Linear Algebra Appl. 415 (1): 114–139, doi:10.1016/j.laa.2005.06.022
- ↑ Li, T. Y.; Zeng, Zhonggang (1992), "Laguerre's Iteration In Solving The Symmetric Tridiagonal Eigenproblem - Revisited", SIAM Journal on Scientific Computing
- ↑ Chu, Moody T. (1988), "A Note on the Homotopy Method for Linear Algebraic Eigenvalue Problems", Linear Algebra Appl. 105: 225–236, doi:10.1016/0024-3795(88)90015-8
- ↑ Dhillon, Inderjit S.; Parlett, Beresford N.; Vömel, Christof (2006), "The Design and Implementation of the MRRR Algorithm", ACM Transactions on Mathematical Software 32 (4): 533–560, doi:10.1145/1186785.1186788
- ↑ Smith, Oliver K. (April 1961), "Eigenvalues of a symmetric 3 × 3 matrix.", Communications of the ACM 4 (4): 168, doi:10.1145/355578.366316
Further reading
- Bojanczyk, Adam W.; Adam Lutoborski (Jan 1991). "Computation of the Euler angles of a symmetric 3X3 matrix". SIAM Journal on Matrix Analysis and Applications 12 (1): 41–48. doi:10.1137/0612005.
| ||||||||||||||||||