Matrix completion
Matrix Completion is the task of filling in the missing entries of a partially observed matrix. A wide range of datasets are naturally organized in matrix form. One example is the movie-ratings matrix, as appears in the Netflix problem: Given a ratings matrix in which each entry  represents the rating of movie
represents the rating of movie 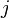 by customer
by customer  if customer has watched movie and is otherwise missing, we would like to predict the remaining entries in order to make good recommendations to customers on what to watch next. Another example is the term-document matrix: The frequencies of words used in a collection of documents can be represented as a matrix, where each entry corresponds to the number of times the associated term appears in the indicated document.
if customer has watched movie and is otherwise missing, we would like to predict the remaining entries in order to make good recommendations to customers on what to watch next. Another example is the term-document matrix: The frequencies of words used in a collection of documents can be represented as a matrix, where each entry corresponds to the number of times the associated term appears in the indicated document.
Without any restrictions on the number of degrees of freedom in the completed matrix this problem is underdetermined since the hidden entries could be assigned arbitrary values. Thus matrix completion often seeks to find the lowest rank matrix or, if the rank of the completed matrix is known, a matrix of rank  that matches the known entries. The illustration shows that a partially revealed rank-1 matrix (on the left) can be completed with zero-error (on the right) since all the rows with missing entries should be the same as the third row. In the case of the Netflix problem the ratings matrix is expected to be low-rank since user preferences can often be described by a few factors, such as the movie genre and time of release. Other applications include computer vision, where missing pixels in images need to be reconstructed, detecting the global positioning of sensors in a network from partial distance information, and multiclass learning. The matrix completion problem is in general NP-hard, but there are tractable algorithms that achieve exact reconstruction with high probability.
that matches the known entries. The illustration shows that a partially revealed rank-1 matrix (on the left) can be completed with zero-error (on the right) since all the rows with missing entries should be the same as the third row. In the case of the Netflix problem the ratings matrix is expected to be low-rank since user preferences can often be described by a few factors, such as the movie genre and time of release. Other applications include computer vision, where missing pixels in images need to be reconstructed, detecting the global positioning of sensors in a network from partial distance information, and multiclass learning. The matrix completion problem is in general NP-hard, but there are tractable algorithms that achieve exact reconstruction with high probability.
In statistical learning point of view, the matrix completion problem is an application of matrix regularization which is a generalization of vector regularization. For example, in the low-rank matrix completion problem one may apply the regularization penalty taking the form of a nuclear norm 
Low rank matrix completion
One of the variants of the matrix completion problem is to find the lowest rank matrix 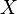 which matches the matrix
which matches the matrix 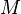 , which we wish to recover, for all entries in the set
, which we wish to recover, for all entries in the set 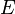 of observed entries.The mathematical formulation of this problem is as follows:
of observed entries.The mathematical formulation of this problem is as follows:

Candes and Recht[1] proved that with assumptions on the sampling of the observed entries and sufficiently many sampled entries this problem has a unique solution with high probability.
An equivalent formulation, given that the matrix to be recovered is known to be of rank , is to solve for where 
Assumptions
A number of assumptions on the sampling of the observed entries and the number of sampled entries are frequently made to simplify the analysis and to ensure the problem is not underdetermined.
Uniform sampling of observed entries
To make the analysis tractable, it is often assumed that the set of observed entries and fixed cardinality is sampled uniformly at random from the collection of all subsets of entries of cardinality  . To further simplify the analysis, it is instead assumed that is constructed by Bernoulli sampling, i.e. that each entry is observed with probability
. To further simplify the analysis, it is instead assumed that is constructed by Bernoulli sampling, i.e. that each entry is observed with probability 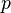 . If is set to
. If is set to  where
where 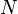 is the desired expected cardinality of , and
is the desired expected cardinality of , and 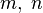 are the dimensions of the matrix (let
are the dimensions of the matrix (let  without loss of generality), is within
without loss of generality), is within  of with high probability, thus Bernoulli sampling is a good approximation for uniform sampling.[1] Another simplification is to assume that entries are sampled independently and with replacement.[2]
of with high probability, thus Bernoulli sampling is a good approximation for uniform sampling.[1] Another simplification is to assume that entries are sampled independently and with replacement.[2]
Lower bound on number of observed entries
Suppose the  by
by  matrix (with ) we are trying to recover has rank . There is an information theoretic lower bound on how many entries must be observed before can be uniquely reconstructed. Firstly, the number of degrees of freedom of a matrix of rank is
matrix (with ) we are trying to recover has rank . There is an information theoretic lower bound on how many entries must be observed before can be uniquely reconstructed. Firstly, the number of degrees of freedom of a matrix of rank is  . This can be shown by looking at the Singular Value Decomposition of the matrix and counting the degrees of freedom. Then at least entries must be observed for matrix completion to have a unique solution.
. This can be shown by looking at the Singular Value Decomposition of the matrix and counting the degrees of freedom. Then at least entries must be observed for matrix completion to have a unique solution.
Secondly, there must be at least one observed entry per row and column of . The Singular Value Decomposition of is given by  . If row is unobserved, it is easy to see the
. If row is unobserved, it is easy to see the  right singular vector of ,
right singular vector of ,  , can be changed to some arbitrary value and still yield a matrix matching over the set of observed entries. Similarly, if column is unobserved, the
, can be changed to some arbitrary value and still yield a matrix matching over the set of observed entries. Similarly, if column is unobserved, the 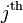 left singular vector of ,
left singular vector of ,  can be arbitrary. If we assume Bernoulli sampling of the set of observed entries, the Coupon collector effect implies that entries on the order of must be observed to ensure that there is an observation from each row and column with high probability.[3]
can be arbitrary. If we assume Bernoulli sampling of the set of observed entries, the Coupon collector effect implies that entries on the order of must be observed to ensure that there is an observation from each row and column with high probability.[3]
Combining the necessary conditions and assuming that 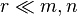 (a valid assumption for many practical applications), the lower bound on the number of observed entries required to prevent the problem of matrix completion from being underdetermined is on the order of
(a valid assumption for many practical applications), the lower bound on the number of observed entries required to prevent the problem of matrix completion from being underdetermined is on the order of  .
.
Incoherence
The concept of incoherence arose in compressed sensing. It is introduced in the context of matrix completion to ensure the singular vectors of are not too "sparse" in the sense that all coordinates of each singular vector are of comparable magnitude instead of just a few coordinates having significantly larger magnitudes.[4] The standard basis vectors are then undesirable as singular vectors, and the vector  in
in 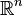 is desirable. As an example of what could go wrong if the singular vectors are sufficiently "sparse", consider the by matrix
is desirable. As an example of what could go wrong if the singular vectors are sufficiently "sparse", consider the by matrix 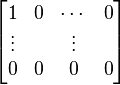 with singular value decomposition
with singular value decomposition  . Almost all the entries of must be sampled before it can be reconstructed.
. Almost all the entries of must be sampled before it can be reconstructed.
Candes and Recht[1] define the coherence of a matrix 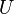 with column space an
with column space an  dimensional subspace of as
dimensional subspace of as  , where
, where  is the orthogonal projection onto . Incoherence then asserts that given the singular value decomposition of the by matrix ,
is the orthogonal projection onto . Incoherence then asserts that given the singular value decomposition of the by matrix ,
-

- The entries of
 have magnitudes upper bounded by
have magnitudes upper bounded by 
for some 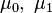 .
.
Low rank matrix completion with Noise
In real world application, one often observe only a few entries corrupted at least by a small amount of noise. For example, in the Netflix problem, the ratings are uncertain. Candes and Plan [5] showed that it is possible to fill in the many missing entries of large low-rank matrices from just a few noisy samples by nuclear norm minimization. The noisy model assumes that we observe

where  is a noise term. Note that the noise can be either stochastic or deterministic. Alternatively the model can be expressed as
is a noise term. Note that the noise can be either stochastic or deterministic. Alternatively the model can be expressed as

where 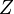 is an
is an  matrix with entries
matrix with entries  for
for  assuming that
assuming that  for some
for some  .To recover the incomplete matrix, we try to solve the following optimization problem:
.To recover the incomplete matrix, we try to solve the following optimization problem:

Among all matrices consistent with the data, find the one with minimum nuclear norm. Candes and Plan [5] have shown that this reconstruction is accurate. They have proved that when perfect noiseless recovery occurs, then matrix completion is stable vis a vis perturbations. The error is proportional to the noise level 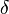 . Therefore when the noise level is small, the error is small. Here the matrix completion problem does not obey the restricted isometry property (RIP). For matrices, the RIP would assume that the sampling operator obeys
. Therefore when the noise level is small, the error is small. Here the matrix completion problem does not obey the restricted isometry property (RIP). For matrices, the RIP would assume that the sampling operator obeys

for all matrices with sufficiently small rank and  sufficiently small.
The methods are also applicable to sparse signal recovery problems in which the RIP does not hold.
sufficiently small.
The methods are also applicable to sparse signal recovery problems in which the RIP does not hold.
High rank matrix completion
The high rank matrix completion in general is NP-Hard. However, with certain assumptions, some incomplete high rank even full rank matrix can be completed.
Eriksson, Balzano and Nowak [6] have considered the problem of completing a matrix with the assumption that the columns of the matrix belong to a union of multiple low-rank subspaces. Since the columns belong to a union of subspaces, the problem may be viewed as a missing-data version of the subspace clustering problem. Let be an 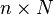 matrix whose (complete) columns lie in a union of at most
matrix whose (complete) columns lie in a union of at most  subspaces, each of
subspaces, each of 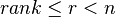 , and assume
, and assume  . Eriksson, Balzano and Nowak [6] showed that under mild assumptions each column of can be perfectly recovered with high probability from an incomplete version so long as at least
. Eriksson, Balzano and Nowak [6] showed that under mild assumptions each column of can be perfectly recovered with high probability from an incomplete version so long as at least  entries of are observed uniformly at random, with
entries of are observed uniformly at random, with 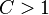 a constant depending on the usual incoherence conditions, the geometrical arrangement of subspaces, and the distribution of columns over the subspaces.
a constant depending on the usual incoherence conditions, the geometrical arrangement of subspaces, and the distribution of columns over the subspaces.
The algorithm involves several steps : (1) local neighborhoods; (2) local subspaces; (3) subspace refinement; (4) full matrix completion. This method can be applied to Internet distance matrix completion and topology identification.
Algorithms
Convex Relaxation
The rank minimization problem is NP-hard. One approach, proposed by Candes and Recht, is to form a convex relaxation of the problem and minimize the nuclear norm  (which gives the sum of the singular values of instead of
(which gives the sum of the singular values of instead of 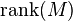 (which counts the number of non zero singular values of ).[1] This is analogous to minimizing the L1-norm rather than the L0-norm for vectors. The convex relaxation can be solved using semidefinite programming (SDP) by noticing that the optimization problem is equivalent to
(which counts the number of non zero singular values of ).[1] This is analogous to minimizing the L1-norm rather than the L0-norm for vectors. The convex relaxation can be solved using semidefinite programming (SDP) by noticing that the optimization problem is equivalent to

The complexity of using SDP to solve the convex relaxation is 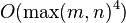 . State of the art solvers like SDP3 can only handle matrices of size up to 100 by 100 [7] An alternative first order method that approximately solves the convex relaxation is the Singular Value Thresholding Algorithm introduced by Cai, Candes and Shen.[7]
. State of the art solvers like SDP3 can only handle matrices of size up to 100 by 100 [7] An alternative first order method that approximately solves the convex relaxation is the Singular Value Thresholding Algorithm introduced by Cai, Candes and Shen.[7]
Candes and Recht show, using the study of random variables on Banach spaces, that if the number of observed entries is on the order of  (assume without loss of generality ), the rank minimization problem has a unique solution which also happens to be the solution of its convex relaxation with probability
(assume without loss of generality ), the rank minimization problem has a unique solution which also happens to be the solution of its convex relaxation with probability 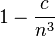 for some constant
for some constant  . If the rank of is small (
. If the rank of is small ( ), the size of the set of observations reduces to the order of
), the size of the set of observations reduces to the order of  . These results are near optimal, since the minimum number of entries that must be observed for the matrix completion problem to not be underdetermined is on the order of .
. These results are near optimal, since the minimum number of entries that must be observed for the matrix completion problem to not be underdetermined is on the order of .
This result has been improved by Candes and Tao.[3] They achieve bounds that differ from the optimal bounds only by polylogarithmic factors by strengthening the assumptions. Instead of the incoherence property, they assume the strong incoherence property with parameter  . This property states that:
. This property states that:
-
 for
for  and
and  for
for 
- The entries of
 are bounded in magnitude by
are bounded in magnitude by 
Intuitively, strong incoherence of a matrix asserts that the orthogonal projections of standard basis vectors to has magnitudes that have high likelihood if the singular vectors were distributed randomly.[4]
Candes and Tao find that when is  and the number of observed entries is on the order of
and the number of observed entries is on the order of  , the rank minimization problem has a unique solution which also happens to be the solution of its convex relaxation with probability for some constant . For arbitrary , the number of observed entries sufficient for this assertion hold true is on the order of
, the rank minimization problem has a unique solution which also happens to be the solution of its convex relaxation with probability for some constant . For arbitrary , the number of observed entries sufficient for this assertion hold true is on the order of 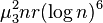
Gradient Descent [8]
Keshavan, Montanari and Oh[8] consider a variant of matrix completion where the rank of the by matrix , which is to be recovered, is known to be . They assume Bernoulli sampling of entries, constant aspect ratio  , bounded magnitude of entries of (let the upper bound be
, bounded magnitude of entries of (let the upper bound be  ), and constant condition number
), and constant condition number  (where
(where 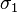 and
and  are the largest and smallest singular values of respectively). Further, they assume the two incoherence conditions are satisfied with
are the largest and smallest singular values of respectively). Further, they assume the two incoherence conditions are satisfied with 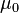 and
and  where and
where and  are constants. Let
are constants. Let  be a matrix that matches on the set of observed entries and is 0 elsewhere. They then propose the following algorithm:
be a matrix that matches on the set of observed entries and is 0 elsewhere. They then propose the following algorithm:
- Trim by removing all observations from columns with degree larger than
 by setting the entries in the columns to 0. Similarly remove all observations from rows with degree larger than .
by setting the entries in the columns to 0. Similarly remove all observations from rows with degree larger than . - Project onto its first principal components. Call the resulting matrix
 .
. - Solve
 where
where  is some regularization function by gradient descent with line search. Initialize
is some regularization function by gradient descent with line search. Initialize 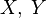 at
at  where
where  . Set as some function forcing to remain incoherent throughout gradient descent if
. Set as some function forcing to remain incoherent throughout gradient descent if  and
and  are incoherent.
are incoherent. - Return the matrix
 .
.
Steps 1 and 2 of the algorithm yield a matrix very close to the true matrix (as measured by the root mean square error (RMSE) with high probability. In particular, with probability  ,
,  for some constant
for some constant 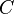 .
.  denotes the Frobenius norm. Note that the full suite of assumptions is not needed for this result to hold. The incoherence condition, for example, only comes into play in exact reconstruction. Finally, although trimming may seem counter intuitive as it involves throwing out information, it ensures projecting onto its first principal components gives more information about the underlying matrix than about the observed entries.
denotes the Frobenius norm. Note that the full suite of assumptions is not needed for this result to hold. The incoherence condition, for example, only comes into play in exact reconstruction. Finally, although trimming may seem counter intuitive as it involves throwing out information, it ensures projecting onto its first principal components gives more information about the underlying matrix than about the observed entries.
In Step 3, the space of candidate matrices can be reduced by noticing that the inner minimization problem has the same solution for  as for
as for  where
where 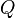 and
and 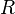 are orthonormal by matrices. Then gradient descent can be performed over the cross product of two Grassman manifolds. If
are orthonormal by matrices. Then gradient descent can be performed over the cross product of two Grassman manifolds. If  and the observed entry set is in the order of , the matrix returned by Step 3 is exactly . Then the algorithm is order optimal, since we know that for the matrix completion problem to not be underdetermined the number of entries must be in the order of .
and the observed entry set is in the order of , the matrix returned by Step 3 is exactly . Then the algorithm is order optimal, since we know that for the matrix completion problem to not be underdetermined the number of entries must be in the order of .
Alternating Least Squares Minimization
Alternating minimization represents a widely applicable and empirically successful approach for finding low-rank matrices that best fit the given data. For example, for the problem of low-rank matrix completion, this method is believed to be one of the most accurate and efficient, and formed a major component of the winning entry in the Netflix problem. In the alternating minimization approach, the low-rank target matrix is written in a bilinear form:
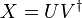 ;
;
the algorithm then alternates between finding the best and the best 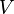 . While the overall problem is non-convex, each sub-problem is typically convex and can be solved efficiently. Jain, Netrapalli and Sanghavi [9] have given one of the first guarantees for performance of alternating minimization for both matrix completion and matrix sensing.
. While the overall problem is non-convex, each sub-problem is typically convex and can be solved efficiently. Jain, Netrapalli and Sanghavi [9] have given one of the first guarantees for performance of alternating minimization for both matrix completion and matrix sensing.
The alternating minimization algorithm can be viewed as an approximate way to solve the following non-convex problem:

The AltMinComplete Algorithm proposed by Jain, Netrapalli and Sanghavi is listed here:[9]
- Input: observed set
 , values
, values 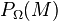
- Partition into
 subsets
subsets  with each element of belonging to one of the
with each element of belonging to one of the  with equal probability (sampling with replacement)
with equal probability (sampling with replacement) -
 i.e., top- left singular vectors of
i.e., top- left singular vectors of 
- Clipping: Set all elements of
 that have magnitude greater than
that have magnitude greater than  to zero and orthonormalize the columns of
to zero and orthonormalize the columns of - for
 do
do -
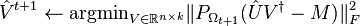
-

- end for
- Return

They showed that by observing  random entries of an incoherent matrix , AltMinComplete algorithm can recover in
random entries of an incoherent matrix , AltMinComplete algorithm can recover in  steps. In terms of sample complexity (
steps. In terms of sample complexity (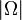 ), theoretically, Alternating Minimization may require a bigger than Convex Relaxation. However empirically it seems not the case which implies that the sample complexity bounds can be further tightened. In terms of time complexity, they showed that AltMinComplete needs time
), theoretically, Alternating Minimization may require a bigger than Convex Relaxation. However empirically it seems not the case which implies that the sample complexity bounds can be further tightened. In terms of time complexity, they showed that AltMinComplete needs time
 .
.
It is worth noting that, although convex relaxation based methods have rigorous analysis, alternating minimization based algorithms are more successful in practice.
Applications
Several applications of matrix completions is summarized by Candes and Plan[5] as follows:
Collaborative filtering
Collaborative filtering is the task of making automatic predictions about the interests of a user by collecting taste information from many users. Companies like Apple, Amazon, Barnes and Noble and Netflix are trying predict their user preferences from partial complete knowledge. In these kind of matrix completion problem, the unknown full matrix is often considered low rank because only a few factors typically contribute to an individual's tastes or preference.
System identification
In control, one would like to fit a discrete-time linear time-invariant state-space model

to a sequence of inputs 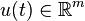 and outputs
and outputs  . The vector
. The vector  is the state of the system at time
is the state of the system at time  and is the order of the system model. From the input/output pair, one would like to recover the matrices
and is the order of the system model. From the input/output pair, one would like to recover the matrices 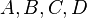 and the initial state
and the initial state  . This problem can also be view as a low-rank matrix completion problem.
. This problem can also be view as a low-rank matrix completion problem.
Global positioning
The global positioning problem emerges naturally in sensor networks. The problem is to recover the global positioning of points in Euclidean space from a local or partial set of pairwise distances. Thus it is a matrix completion problem with rank two if the sensors are located in a 2-D plane and three if they are in a 3-D space.
See also
- Matrix regularization
- Netflix Prize
- Collaborative filtering
- System identification
- Convex optimization
References
- 1 2 3 4 E. J. Candès and B. Recht, "Exact matrix completion via convex optimization", Found. of Comput. Math., 2008
- ↑ B. Recht, "A simpler approach to matrix completion", Journal of Machine Learning Research, Vol 12, pp. 3413--3430, 2011.
- 1 2 E. J. Candès and T. Tao, "The power of convex relaxation: Near-optimal matrix completion",arXiv:0903.1476, 2009.
- 1 2 http://terrytao.wordpress.com/2009/03/10/the-power-of-convex-relaxation-near-optimal-matrix-completion/, T. Tao, "The power of convex relaxation: Near-optimal matrix completion", What's New, 2009
- 1 2 3 E. J. Candès and Yaniv Plan, "Matrix Completion with Noise", arxiv:0903.3131, 2009.
- 1 2 B. Eriksson, L. Balzano and R. Nowak, "High-Rank Matrix Completion and Subspace Clustering with Missing Data", arxiv:1112.5629, 2011.
- 1 2 J. F. Cai, E. J. Candès and Z. Shen, "A singular value thresholding algorithm for matrix completion", SIAM J. Optim., Vol. 20, pp. 1956-1982, 2010.
- 1 2 R. H. Keshavan, A. Montanari and S. Oh, "Matrix completion from a few entries", arXiv:0901.3150, 2009.
- 1 2 P. Jain, P. Netrapalli and Sanghavi, "Low-rank Matrix Completion using Alternating Minimization", arxiv:1212.0467, 2012