Low-rank approximation
In mathematics, low-rank approximation is a minimization problem, in which the cost function measures the fit between a given matrix (the data) and an approximating matrix (the optimization variable), subject to a constraint that the approximating matrix has reduced rank. The problem is used for mathematical modeling and data compression. The rank constraint is related to a constraint on the complexity of a model that fits the data. In applications, often there are other constraints on the approximating matrix apart from the rank constraint, e.g., non-negativity and Hankel structure.
Low-rank approximation is closely related to:
- principal component analysis,
- factor analysis,
- total least squares,
- latent semantic analysis, and
- orthogonal regression.
Definition
Given
- structure specification
 ,
, - vector of structure parameters
 ,
, - norm
 , and
, and - desired rank
 ,
,

Applications
- Linear system identification, in which case the approximating matrix is Hankel structured.[1][2]
- Machine learning, in which case the approximating matrix is nonlinearly structured.[3]
- Recommender system, in which case the data matrix has missing values and the approximation is categorical.
- Distance matrix completion, in which case there is a positive definiteness constraint.
- Natural language processing, in which case the approximation is nonnegative.
- Computer algebra, in which case the approximation is Sylvester structured.
Basic low-rank approximation problem
The unstructured problem with fit measured by the Frobenius norm, i.e.,

has analytic solution in terms of the singular value decomposition of the data matrix. The result is referred to as the matrix approximation lemma or Eckart–Young–Mirsky theorem.[4] Let

be the singular value decomposition of  and partition
and partition 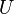 ,
,  , and
, and 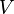 as follows:
as follows:

where  is
is  ,
,  is
is  , and
, and  is
is  . Then the rank- matrix, obtained from the truncated singular value decomposition
. Then the rank- matrix, obtained from the truncated singular value decomposition

is such that

The minimizer  is unique if and only if
is unique if and only if  .
.
Proof of Eckart–Young–Mirsky theorem (for spectral norm)

where  and
and  are orthogonal matrices, and
are orthogonal matrices, and  is a diagonal matrix with entries
is a diagonal matrix with entries 
s.t  .
.
We claim that the best approximation for 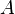 be given by
be given by

To Prove:  is indeed the Best approximation, i.e.,
is indeed the Best approximation, i.e.,

Proof by Contradiction:
Let us suppose
 where
where

Then

If  , then
, then

We know that  dimension space
dimension space

s.t. 
Since  hence a contradiction.
So we get that
hence a contradiction.
So we get that  is the best approximation.
is the best approximation.
Proof of Eckart–Young–Mirsky theorem (for Frobenius norm)
For a given (real or complex valued) matrix ,
denote its SVD by

where and are unitary matrices,
and 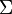 is a (often rectangular) diagonal matrix
with entries
is a (often rectangular) diagonal matrix
with entries
s.t .
The ith column of is  and the ith row of
and the ith row of 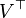 is
is
 .
.
Claim: the rank k approximation for
that minimizes the Frobenius norm
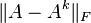 is given by
is given by

Proof:
For any matrix
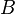 the same size as
,
define the (generally non-diagonal) matrix
the same size as
,
define the (generally non-diagonal) matrix
 ,
so
,
so
 .
Then
.
Then

Thus clearly the rank k choice of
that minimizes
 is when
is diagonal
with nonzero diagonal elements
is when
is diagonal
with nonzero diagonal elements
 .
The corresponding
matches
above.
.
The corresponding
matches
above.
Weighted low-rank approximation problems
The Frobenius norm weights uniformly all elements of the approximation error  . Prior knowledge about distribution of the errors can be taken into account by considering the weighted low-rank approximation problem
. Prior knowledge about distribution of the errors can be taken into account by considering the weighted low-rank approximation problem

where  vectorizes the matrix column wise and
vectorizes the matrix column wise and 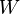 is a given positive (semi)definite weight matrix.
is a given positive (semi)definite weight matrix.
The general weighted low-rank approximation problem does not admit an analytic solution in terms of the singular value decomposition and is solved by local optimization methods, which provide no guarantee that a globally optimal solution is found.
Image and kernel representations of the rank constraints
Using the equivalences
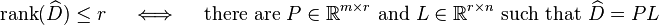
and

the weighted low-rank approximation problem becomes equivalent to the parameter optimization problems

and

where  is the identity matrix of size .
is the identity matrix of size .
Alternating projections algorithm
The image representation of the rank constraint suggests a parameter optimization methods, in which the cost function is minimized alternatively over one of the variables ( or
or  ) with the other one fixed. Although simultaneous minimization over both and is a difficult biconvex optimization problem, minimization over one of the variables alone is a linear least squares problem and can be solved globally and efficiently.
) with the other one fixed. Although simultaneous minimization over both and is a difficult biconvex optimization problem, minimization over one of the variables alone is a linear least squares problem and can be solved globally and efficiently.
The resulting optimization algorithm (called alternating projections) is globally convergent with a linear convergence rate to a locally optimal solution of the weighted low-rank approximation problem. Starting value for the (or ) parameter should be given. The iteration is stopped when a user defined convergence condition is satisfied.
Matlab implementation of the alternating projections algorithm for weighted low-rank approximation:
function [dh, f] = wlra_ap(d, w, p, tol, maxiter)
[m, n] = size(d); r = size(p, 2); f = inf;
for i = 2:maxiter
% minimization over L
bp = kron(eye(n), p);
vl = (bp' * w * bp) \ bp' * w * d(:);
l = reshape(vl, r, n);
% minimization over P
bl = kron(l', eye(m));
vp = (bl' * w * bl) \ bl' * w * d(:);
p = reshape(vp, m, r);
% check exit condition
dh = p * l; dd = d - dh;
f(i) = dd(:)' * w * dd(:);
if abs(f(i - 1) - f(i)) < tol, break, end
end
Variable projections algorithm
The alternating projections algorithm exploits the fact that the low rank approximation problem, parameterized in the image form, is bilinear in the variables or . The bilinear nature of the problem is effectively used in an alternative approach, called variable projections.[5]
Consider again the weighted low rank approximation problem, parameterized in the image form. Minimization with respect to the variable (a linear least squares problem) leads to the closed form expression of the approximation error as a function of

The original problem is therefore equivalent to the nonlinear least squares problem of minimizing  with respect to . For this purpose standard optimization methods, e.g. the Levenberg-Marquardt algorithm can be used.
with respect to . For this purpose standard optimization methods, e.g. the Levenberg-Marquardt algorithm can be used.
Matlab implementation of the variable projections algorithm for weighted low-rank approximation:
function [dh, f] = wlra_varpro(d, w, p, tol, maxiter)
prob = optimset(); prob.solver = 'lsqnonlin';
prob.options = optimset('MaxIter', maxiter, 'TolFun', tol);
prob.x0 = p; prob.objective = @(p) cost_fun(p, d, w);
[p, f ] = lsqnonlin(prob);
[f, vl] = cost_fun(p, d, w);
dh = p * reshape(vl, size(p, 2), size(d, 2));
function [f, vl] = cost_fun(p, d, w)
bp = kron(eye(size(d, 2)), p);
vl = (bp' * w * bp) \ bp' * w * d(:);
f = d(:)' * w * (d(:) - bp * vl);
The variable projections approach can be applied also to low rank approximation problems parameterized in the kernel form. The method is effective when the number of eliminated variables is much larger than the number of optimization variables left at the stage of the nonlinear least squares minimization. Such problems occur in system identification, parameterized in the kernel form, where the eliminated variables are the approximating trajectory and the remaining variables are the model parameters. In the context of linear time-invariant systems, the elimination step is equivalent to Kalman smoothing.
See also
- CUR matrix approximation is made from the rows and columns of the original matrix
References
- ↑ I. Markovsky, Structured low-rank approximation and its applications, Automatica, Volume 44, Issue 4, April 2008, Pages 891–909. doi:10.1016/j.automatica.2007.09.011
- ↑ I. Markovsky, J. C. Willems, S. Van Huffel, B. De Moor, and R. Pintelon, Application of structured total least squares for system identification and model reduction. IEEE Transactions on Automatic Control, Volume 50, Number 10, 2005, pages 1490–1500.
- ↑ I. Markovsky, Low-Rank Approximation: Algorithms, Implementation, Applications, Springer, 2012, ISBN 978-1-4471-2226-5
- ↑ C. Eckart, G. Young, The approximation of one matrix by another of lower rank. Psychometrika, Volume 1, 1936, Pages 211–8. doi:10.1007/BF02288367
- ↑ G. Golub and V. Pereyra, Separable nonlinear least squares: the variable projection method and its applications, Institute of Physics, Inverse Problems, Volume 19, 2003, Pages 1-26.
- M. T. Chu, R. E. Funderlic, R. J. Plemmons, Structured low-rank approximation, Linear Algebra and its Applications, Volume 366, 1 June 2003, Pages 157–172 doi:10.1016/S0024-3795(02)00505-0