Long-tail traffic
A long-tailed or heavy-tailed probability distribution is one that assigns relatively high probabilities to regions far from the mean or median. A more formal mathematical definition is given below. In the context of teletraffic engineering a number of quantities of interest have been shown to have a long-tailed distribution. For example, if we consider the sizes of files transferred from a web-server, then, to a good degree of accuracy, the distribution is heavy-tailed, that is, there are a large number of small files transferred but, crucially, the number of very large files transferred remains a major component of the volume downloaded.
Many processes are technically long-range dependent but not self-similar. The differences between these two phenomena are subtle. Heavy-tailed refers to a probability distribution, and long-range dependent refers to a property of a time series and so these should be used with care and a distinction should be made. The terms are distinct although superpositions of samples from heavy-tailed distributions aggregate to form long-range dependent time series.
Additionally there is Brownian motion which is self-similar but not long-range dependent.
Overview
The design of robust and reliable networks and network services has become an increasingly challenging task in today's Internet world. To achieve this goal, understanding the characteristics of Internet traffic plays a more and more critical role. Empirical studies of measured traffic traces have led to the wide recognition of self-similarity in network traffic.[1]
Self-similar Ethernet traffic exhibits dependencies over a long range of time scales. This is to be contrasted with telephone traffic which is Poisson in its arrival and departure process.[2]
With many time-series if the series is averaged then the data begins to look smoother. However, with self-similar data, one is confronted with traces which are spiky and bursty, even at large scales. Such behaviour is caused by strong dependence in the data: large values tend to come in clusters, and clusters of clusters, etc. This can have far-reaching consequences for network performance.[3]
Heavy-tail distributions have been observed in many natural phenomena including both physical and sociological phenomena. Mandelbrot established the use of heavy-tail distributions to model real-world fractal phenomena, e.g. Stock markets, earthquakes, and the weather.[2] Ethernet, WWW, SS7, TCP, FTP, TELNET and VBR video (digitised video of the type that is transmitted over ATM networks) traffic is self-similar. [4]
Self-similarity in packetised data networks can be caused by the distribution of file sizes, human interactions and/or Ethernet dynamics.[5] Self-similar and long-range dependent characteristics in computer networks present a fundamentally different set of problems to people doing analysis and/or design of networks, and many of the previous assumptions upon which systems have been built are no longer valid in the presence of self-similarity.[6]
Short-range dependence vs. long-range dependence
Long-range and short-range dependent processes are characterised by their autocovariance functions.
In short-range dependent processes, the coupling between values at different times decreases rapidly as the time difference increases.
- The sum of the autocorrelation function over all lags is finite.
- As the lag increases, the autocorrelation function of short-range dependent processes decays quickly.
In long-range processes, the correlations at longer time scales are more significant.
- The area under the autocorrelation function summed over all lags is infinite.[7]
- The decay of the autocorrelation function is often assumed to have the specific functional form,
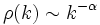
where ρ(k) is the autocorrelation function at a lag k, α is a parameter in the interval (0,1) and the ~ means asymptotically proportional to as k approaches infinity.
Long-range dependence as a consequence of mathematical convergence
Such power law scaling of the autocorrelation function can be shown to be biconditionally related to a power law relationship between the variance and the mean, when evaluated from sequences by the method of expanding bins. This variance to mean power law is an inherent feature of a family of statistical distributions called the Tweedie exponential dispersion models. Much as the central limit theorem explains how certain types of random data converge towards the form of a normal distribution there exists a related theorem, the Tweedie convergence theorem that explains how other types of random data will converge towards the form of these Tweedie distributions, and consequently express both the variance to mean power law and a power law decay in their autocorrelation functions.
The Poisson distribution and traffic
Before the heavy-tail distribution is introduced mathematically, the memoryless Poisson distribution, used to model traditional telephony networks, is briefly reviewed below. For more details, see the article on the Poisson distribution.
Assuming pure-chance arrivals and pure-chance terminations leads to the following:
- The number of call arrivals in a given time has a Poisson distribution, i.e.:
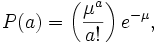
where a is the number of call arrivals and 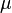 is the mean number of call arrivals in time T. For this reason, pure-chance traffic is also known as Poisson traffic.
is the mean number of call arrivals in time T. For this reason, pure-chance traffic is also known as Poisson traffic.
- The number of call departures in a given time also has a Poisson distribution, i.e.:
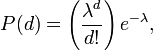
where d is the number of call departures and  is the mean number of call departures in time T.
is the mean number of call departures in time T.
- The intervals, T, between call arrivals and departures are intervals between independent, identically distributed random events. It can be shown that these intervals have a negative exponential distribution, i.e.:
![P[T \ge \ t]=e^{\frac{-t}{h}},](../I/m/f4ebffedcf275a72cda34f7cf660ceec.png)
where h is the Mean Holding Time (MHT). [4]
Information on the fundamentals of statistics and probability theory can be found in the external links section.
The heavy-tail distribution
Heavy-tail distributions have properties that are qualitatively different from commonly used (memoryless) distributions such as the Poisson distribution.
The Hurst parameter H is a measure of the level of self-similarity of a time series that exhibits long-range dependence, to which the heavy-tail distribution can be applied. H takes on values from 0.5 to 1. A value of 0.5 indicates the data is uncorrelated or has only short-range correlations. The closer H is to 1, the greater the degree of persistence or long-range dependence. [4]
Typical values of the Hurst parameter, H:
- Any pure random process has H = 0.5
- Phenomena with H > 0.5 typically have a complex process structure.
A distribution is said to be heavy-tailed if:
![P[X>x] \sim x^{- \alpha},\ \text{as} \ x \to \infty, 0< \alpha <2](../I/m/983b55cde1d01c004f6a728236ff16cf.png)
This means that regardless of the distribution for small values of the random variable, if the asymptotic shape of the distribution is hyperbolic, it is heavy-tailed. The simplest heavy-tail distribution is the Pareto distribution which is hyperbolic over its entire range. Complementary distribution functions for the exponential and Pareto distributions are shown below. Shown on the left is a graph of the distributions shown on linear axes, spanning a large domain.[8] To its right is a graph of the complementary distribution functions over a smaller domain, and with a logarithmic range.[5]
If the logarithm of the range of an exponential distribution is taken, the resulting plot is linear. In contrast, that of the heavy-tail distribution is still curvilinear. These characteristics can be clearly seen on the graph above to the right. A characteristic of long-tail distributions is that if the logarithm of both the range and the domain is taken, the tail of the long-tail distribution is approximately linear over many orders of magnitude. [9] In the graph above left, the condition for the existence of a heavy-tail distribution, as previously presented, is not met by the curve labelled "Gamma-Exponential Tail".
The probability mass function of a heavy-tail distribution is given by:
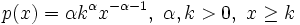
and its cumulative distribution function is given by:
![F(x)=P[X \le \ x]=1- \left(\frac{k}{x}\right)^{\alpha}](../I/m/cbc57757d76ed92f15b1d4ac79a3eefc.png)
where k represents the smallest value the random variable can take.
Readers interested in a more rigorous mathematical treatment of the subject are referred to the external links section.
What causes long-tail traffic?
In general, there are three main theories for the causes of long-tail traffic (see a review of all three causes[10]). First, is a cause based in the application layer which theorizes that user session durations vary with a long-tail distribution due to the file size distribution. If the distribution of file sizes is heavy-tailed then the superposition of many file transfers in a client/server network environment will be long-range dependent. Additionally, this causal mechanism is robust with respect to changes in network resources (bandwidth and buffer capacity) and network topology. [11] This is currently the most popular explanation in the engineering literature and the one with the most empirical evidence through observed file size distributions.
Second, is a transport layer cause which theorizes that the feedback between multiple TCP streams due to TCP's congestion avoidance algorithm in moderate to high packet loss situations causes self-similar traffic or at least allows it to propagate. However, this is believed only to be a significant factor at relatively short timescales and not the long-term cause of self-similar traffic.
Finally, is a theorized link layer cause which is predicated based on physics simulations of packet switching networks on simulated topologies. At a critical packet creation rate, the flow in a network becomes congested and exhibits 1/f noise and long-tail traffic characteristics. There have been criticisms on these sorts of models though as being unrealistic in that network traffic is long-tailed even in non-congested regions[12] and at all levels of traffic.
Simulation showed that long-range dependence could arise in the queue length dynamics at a given node (an entity which transfers traffic) within a communications network even when the traffic sources are free of long-range dependence. The mechanism for this is believed to relate to feedback from routing effects in the simulation. [13]
Modelling long-tail traffic
Modelling of long-tail traffic is necessary so that networks can be provisioned based on accurate assumptions of the traffic that they carry. The dimensioning and provisioning of networks that carry long-tail traffic is discussed in the next section.
Since (unlike traditional telephony traffic) packetised traffic exhibits self-similar or fractal characteristics, conventional traffic models do not apply to networks which carry long-tail traffic. [4] Previous analytic work done in Internet studies adopted assumptions such as exponentially-distributed packet inter-arrivals, and conclusions reached under such assumptions may be misleading or incorrect in the presence of heavy-tailed distributions.[2]
It has for long been realised that efficient and accurate modelling of various real world phenomena needs to incorporate the fact that observations made on different scales each carry essential information. In most simple terms, representing data on large scales by its mean is often useful (such as an average income or an average number of clients per day) but can be inappropriate (e.g. in the context of buffering or waiting queues).[3]
With the convergence of voice and data, the future multi-service network will be based on packetised traffic, and models which accurately reflect the nature of long-tail traffic will be required to develop, design and dimension future multi-service networks. [4] We seek an equivalent to the Erlang model for circuit switched networks.[5]
There is not an abundance of heavy-tailed models with rich sets of accompanying data fitting techniques. [14] A clear model for fractal traffic has not yet emerged, nor is there any definite direction towards a clear model. [4] Deriving mathematical models which accurately represent long-tail traffic is a fertile area of research.
Gaussian models, even long-range dependent Gaussian models, are unable to accurately model current Internet traffic. [15] Classical models of time series such as Poisson and finite Markov processes rely heavily on the assumption of independence, or at least weak dependence.[3] Poisson and Markov related processes have, however, been used with some success. Nonlinear methods are used for producing packet traffic models which can replicate both short-range and long-range dependent streams. [13]
A number of models have been proposed for the task of modelling long-tail traffic. These include the following:
- Fractional ARIMA
- Fractional Brownian motion
- Iterated Chaotic Maps
- Infinite Markov Modulated Processes
- Poisson Pareto Burst Processes (PPBP)
- Markov Modulated Poisson Processes (MMPP) [16]
- Multi-fractal models[3]
- Matrix models[4]
- Wavelet Modelling
- Tweedie distributions
No unanimity exists about which of the competing models is appropriate, [4] but the Poisson Pareto Burst Process (PPBP), which is an M/G/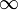 process, is perhaps the most successful model to date. It is demonstrated to satisfy the basic requirements of a simple, but accurate, model of long-tail traffic. [15]
process, is perhaps the most successful model to date. It is demonstrated to satisfy the basic requirements of a simple, but accurate, model of long-tail traffic. [15]
Finally, results from simulations [4] using  -stable stochastic processes for modelling traffic in broadband networks are presented. The simulations are compared to a variety of empirical data (Ethernet, WWW, VBR Video).
-stable stochastic processes for modelling traffic in broadband networks are presented. The simulations are compared to a variety of empirical data (Ethernet, WWW, VBR Video).
Network performance
In some cases an increase in the Hurst parameter can lead to a reduction in network performance. The extent to which heavy-tailedness degrades network performance is determined by how well congestion control is able to shape source traffic into an on-average constant output stream while conserving information. [17] Congestion control of heavy-tailed traffic is discussed in the following section.
Traffic self-similarity negatively affects primary performance measures such as queue size and packet-loss rate. The queue length distribution of long-tail traffic decays more slowly than with Poisson sources. However, long-range dependence implies nothing about its short-term correlations which affect performance in small buffers.[16] For heavy-tailed traffic, extremely large bursts occur more frequently than with light-tailed traffic. [18] Additionally, aggregating streams of long-tail traffic typically intensifies the self-similarity ("burstiness") rather than smoothing it, compounding the problem.[1]
The graph above right, taken from, [4] presents a queueing performance comparison between traffic streams of varying degrees of self-similarity. Note how the queue size increases with increasing self-similarity of the data, for any given channel utilisation, thus degrading network performance.
In the modern network environment with multimedia and other QoS sensitive traffic streams comprising a growing fraction of network traffic, second order performance measures in the form of “jitter” such as delay variation and packet loss variation are of import to provisioning user specified QoS. Self-similar burstiness is expected to exert a negative influence on second order performance measures. [19]
Packet switching based services, such as the Internet (and other networks that employ IP) are best-effort services, so degraded performance, although undesirable, can be tolerated. However, since the connection is contracted, ATM networks need to keep delays and jitter within negotiated limits. [20]
Self-similar traffic exhibits the persistence of clustering which has a negative impact on network performance.
- With Poisson traffic (found in conventional telephony networks), clustering occurs in the short term but smooths out over the long term.
- With long-tail traffic, the bursty behaviour may itself be bursty, which exacerbates the clustering phenomena, and degrades network performance. [4]
Many aspects of network quality of service depend on coping with traffic peaks that might cause network failures, such as
- Cell/packet loss and queue overflow
- Violation of delay bounds e.g. In video
- Worst cases in statistical multiplexing
Poisson processes are well-behaved because they are stateless, and peak loading is not sustained, so queues do not fill. With long-range order, peaks last longer and have greater impact: the equilibrium shifts for a while.[7]
Due to the increased demands that long-tail traffic places on networks resources, networks need to be carefully provisioned to ensure that quality of service and service level agreements are met. The following subsection deals with the provisioning of standard network resources, and the subsection after that looks at provisioning web servers which carry a significant amount of long-tail traffic.
Network provisioning for long-tail traffic
For network queues with long-range dependent inputs, the sharp increase in queuing delays at fairly low levels of utilisation and slow decay of queue lengths implies that an incremental improvement in loss performance requires a significant increase in buffer size. [21]
While throughput declines gradually as self-similarity increases, queuing delay increases more drastically. When traffic is self-similar, we find that queuing delay grows proportionally to the buffer capacity present in the system. Taken together, these two observations have potentially dire implications for QoS provisions in networks. To achieve a constant level of throughput or packet loss as self-similarity is increased, extremely large buffer capacity is needed. However, increased buffering leads to large queuing delays and thus self-similarity significantly steepens the trade-off curve between throughput/ packet loss and delay. [17]
ATM can be employed in telecommunications networks to overcome second order performance measure problems. The short fixed length cell used in ATM reduces the delay and most significantly the jitter for delay-sensitive services such as voice and video. [22]
Web site provisioning for long-tail traffic
Workload pattern complexities (for example, bursty arrival patterns) can significantly affect resource demands, throughput, and the latency encountered by user requests, in terms of higher average response times and higher response time variance. Without adaptive, optimal management and control of resources, SLAs based on response time are impossible. The capacity requirements on the site are increased while its ability to provide acceptable levels of performance and availability diminishes.[18] Techniques to control and manage long-tail traffic are discussed in the following section.
The ability to accurately forecast request patterns is an important requirement of capacity planning. A practical consequence of burstiness and heavy-tailed and correlated arrivals is difficulty in capacity planning.[18]
With respect to SLAs, the same level of service for heavy-tailed distributions requires a more powerful set of servers, compared with the case of independent light-tailed request traffic. To guarantee good performance, focus needs to be given to peak traffic duration because it is the huge bursts of requests that most degrade performance. That is why some busy sites require more head room (spare capacity) to handle the volumes; for example, a high-volume online trading site reserves spare capacity with a ratio of three to one.[18]
Reference to additional information on the effect of long-range dependency on network performance can be found in the external links section.
Controlling long-tail traffic
Given the ubiquity of scale-invariant burstiness observed across diverse networking contexts, finding an effective traffic control algorithm capable of detecting and managing self-similar traffic has become an important problem. The problem of controlling self-similar network traffic is still in its infancy.[23]
Traffic control for self-similar traffic has been explored on two fronts: Firstly, as an extension of performance analysis in the resource provisioning context, and secondly, from the multiple time scale traffic control perspective where the correlation structure at large time scales is actively exploited to improve network performance.[24]
The resource provisioning approach seeks to identify the relative utility of the two principal network resource types – bandwidth and buffer capacity – with respect to their curtailing effects on self-similarity, and advocates a small buffer/ large bandwidth resource dimensioning policy. Whereas resource provisioning is open-loop in nature, multiple time scale traffic control exploits the long-range correlation structure present in self-similar traffic.[24] Congestion control can be exercised concurrently at multiple time scales, and by cooperatively engaging information extracted at different time scales, achieve significant performance gains.[23]
Another approach adopted in controlling long-tail traffic makes traffic controls cognizant of workload properties. For example, when TCP is invoked in HTTP in the context of web client/ server interactions, the size of the file being transported (which is known at the server) is conveyed or made accessible to protocols in the transport layer, including the selection of alternative protocols, for more effective data transport. For short files, which constitute the bulk of connection requests in heavy-tailed file size distributions of web servers, elaborate feedback control may be bypassed in favour of lightweight mechanisms in the spirit of optimistic control, which can result in improved bandwidth utilisation.[19]
It was found that the simplest way to control packet traffic is to limit the length of queues. Long queues in the network invariably occur at hosts (entities that can transmit and receive packets). Congestion control can therefore be achieved by reducing the rate of packet production at hosts with long queues.[13]
It should be noted that long-range dependence and its exploitation for traffic control is best suited for flows or connections whose lifetime or connection duration is long lasting.[19]
See also
References
- 1 2 Zhu X., Yu J., Doyle J., California Institute of Technology, Heavy-tailed distributions, generalised source coding and optimal web layout design.
- 1 2 3 Medina A., Computer Science Department, Boston University, Appendix: Heavy-tailed distributions.
- 1 2 3 4 Department of Electrical and Computer Engineering, Rice University, Internet Control and Inference Tools at the Edge: Network Traffic Modelling.
- 1 2 3 4 5 6 7 8 9 10 11 Kennedy I., Lecture Notes, ELEN5007 – Teletraffic Engineering, School of Electrical and Information Engineering, University of the Witwatersrand, 2005.
- 1 2 3 Neame T., ARC Centre for Ultra Broadband Information Networks, EEE Dept., The University of Melbourne, Performance Evaluation of a Queue Fed by a Poisson Pareto Burst Process.
- ↑ Barford P., Floyd S., Computer Science Department, Boston University, The Self-similarity and Long Range Dependence in Networks Web site.
- 1 2 Linington P.F., University of Kent, Everything you always wanted to know about self-similar network traffic and long-range dependency, but were ashamed to ask.
- ↑ School of Information Technology and Engineering, George Mason University, Development of Procedures to Analyze Queuing Models with Heavy-Tailed Interarrival and Service Times.
- ↑ Air Force Research Laboratory, Information Directorate, Heavy-tailed distributions and implications.
- ↑ Smith R. (2011). "The Dynamics of Internet Traffic: Self-Similarity, Self-Organization, and Complex Phenomena". Advances in Complex Systems 14 (6): 905–949. arXiv:0807.3374. doi:10.1142/S0219525911003451.
- ↑ Park K., Kim G., Crovella M. (1996). "On the relationships between file sizes, transport protocols and self-similar network traffic" (PDF). International Conference on Network Protocols. doi:10.1109/ICNP.1996.564935. ISBN 0-8186-7453-9.
- ↑ Willinger, W., Govindan, R., Jamin, S., Paxson, V. & Shenker, S. (2002). "Scaling phenomena in the Internet: Critically examining Criticality". Proceedings of the National Academy of Sciences 99: 2573. doi:10.1073/pnas.012583099. JSTOR 3057595.
- 1 2 3 Arrowsmith D.K., Woolf M., Internet Packet Traffic Congestion in Networks, Mathematics Research Centre, Queen Mary, University of London.
- ↑ Resnick S.I., Heavy Tail Modeling and Teletraffic Data, Cornell University.
- 1 2 Neame T., Characterisation and Modelling of Internet Traffic Streams, Department of Electrical and Electronic Engineering, University of Melbourne, 2003.
- 1 2 Zukerman M., ARC Centre for Ultra Broadband Information Networks, EEE Dept., The University of Melbourne, Traffic Modelling and Related Queueing Problems.
- 1 2 Park K., Kim G., Crovella M., On the Effect of Traffic Self-similarity on Network Performance.
- 1 2 3 4 Chiu W., IBM DeveloperWorks, Planning for growth: A proven methodology for capacity planning.
- 1 2 3 Park K., Future Directions and Open Problems in Performance Evaluation and Control of Self-Similar Network Traffic, Department of Computer Sciences, University of Purdue.
- ↑ Jitter analysis of ATM self-similar traffic. utdallas.edu.
- ↑ Grossglauser M., Bolot J.C. (1999). "On the relevance of long-range dependence in network traffic". IEEE/ACM Transactions on Networking 7 (5): 629–640. doi:10.1109/90.803379.
- ↑ Biran G., Introduction to ATM switching, RAD Data Communications.
- 1 2 Tuan T., Park K., Multiple Time Scale Congestion Control for Self-Similar Network Traffic, Department of Computer Sciences, University of Purdue.
- 1 2 Park K., Self-Similar Network Traffic and its Control, Department of Computer Sciences, University of Purdue.