List decoding
In computer science, particularly in coding theory, list decoding is an alternative to unique decoding of error-correcting codes for large error rates. The notion was proposed by Elias in the 1950s. The main idea behind list decoding is that the decoding algorithm instead of outputting a single possible message outputs a list of possibilities one of which is correct. This allows for handling a greater number of errors than that allowed by unique decoding.
The unique decoding model in coding theory, which is constrained to output a single valid codeword from the received word could not tolerate greater fraction of errors. This resulted in a gap between the error-correction performance for stochastic noise models (proposed by Shannon) and the adversarial noise model (considered by Richard Hamming). Since the mid 90s, significant algorithmic progress by the coding theory community has bridged this gap. Much of this progress is based on a relaxed error-correction model called list decoding, wherein the decoder outputs a list of codewords for worst-case pathological error patterns where the actual transmitted codeword is included in the output list. In case of typical error patterns though, the decoder outputs a unique single codeword, given a received word, which is almost always the case (However, this is not known to be true for all codes). The improvement here is significant in that the error-correction performance doubles. This is because now the decoder is not confined by the half-the-minimum distance barrier. This model is very appealing because having a list of codewords is certainly better than just giving up. The notion of list-decoding has many interesting applications in complexity theory.
The way the channel noise is modeled plays a crucial role in that it governs the rate at which reliable communication is possible. There are two main schools of thought in modeling the channel behavior:
- Probabilistic noise model studied by Shannon in which the channel noise is modeled precisely in the sense that the probabilistic behavior of the channel is well known and the probability of occurrence of too many or too few errors is low
- Worst-case or adversarial noise model considered by Hamming in which the channel acts as an adversary that arbitrarily corrupts the codeword subject to a bound on the total number of errors.
The highlight of list-decoding is that even under adversarial noise conditions, it is possible to achieve the information-theoretic optimal trade-off between rate and fraction of errors that can be corrected. Hence, in a sense this is like improving the error-correction performance to that possible in case of a weaker, stochastic noise model.
Mathematical formulation
Let  be a
be a 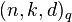 error-correcting code; in other words, is a code of length
error-correcting code; in other words, is a code of length  , dimension
, dimension  and minimum distance
and minimum distance 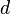 over an alphabet
over an alphabet 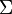 of size
of size 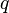 . The list-decoding problem can now be formulated as follows:
. The list-decoding problem can now be formulated as follows:
Input: Received word 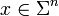 , error bound
, error bound 
Output: A list of all codewords 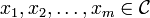 whose hamming distance from
whose hamming distance from  is at most .
is at most .
Motivation for list decoding
Given a received word 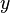 , which is a noisy version of some transmitted codeword
, which is a noisy version of some transmitted codeword  , the decoder tries to output the transmitted codeword by placing its bet on a codeword that is “nearest” to the received word. The Hamming distance between two codewords is used as a metric in finding the nearest codeword, given the received word by the decoder. If is the minimum Hamming distance of a code , then there exists two codewords
, the decoder tries to output the transmitted codeword by placing its bet on a codeword that is “nearest” to the received word. The Hamming distance between two codewords is used as a metric in finding the nearest codeword, given the received word by the decoder. If is the minimum Hamming distance of a code , then there exists two codewords 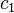 and
and 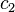 that differ in exactly positions. Now, in the case where the received word is equidistant from the codewords and , unambiguous decoding becomes impossible as the decoder cannot decide which one of and to output as the original transmitted codeword. As a result, the half-the minimum distance acts as a combinatorial barrier beyond which unambiguous error-correction is impossible, if we only insist on unique decoding. However, received words such as considered above occur only in the worst-case and if one looks at the way Hamming balls are packed in high-dimensional space, even for error patterns beyond half-the minimum distance, there is only a single codeword within Hamming distance from the received word. This claim has been shown to hold with high probability for a random code picked from a natural ensemble and more so for the case of Reed–Solomon codes which is well studied and quite ubiquitous in the real world applications. In fact, Shannon’s proof of the capacity theorem for q-ary symmetric channels can be viewed in light of the above claim for random codes.
that differ in exactly positions. Now, in the case where the received word is equidistant from the codewords and , unambiguous decoding becomes impossible as the decoder cannot decide which one of and to output as the original transmitted codeword. As a result, the half-the minimum distance acts as a combinatorial barrier beyond which unambiguous error-correction is impossible, if we only insist on unique decoding. However, received words such as considered above occur only in the worst-case and if one looks at the way Hamming balls are packed in high-dimensional space, even for error patterns beyond half-the minimum distance, there is only a single codeword within Hamming distance from the received word. This claim has been shown to hold with high probability for a random code picked from a natural ensemble and more so for the case of Reed–Solomon codes which is well studied and quite ubiquitous in the real world applications. In fact, Shannon’s proof of the capacity theorem for q-ary symmetric channels can be viewed in light of the above claim for random codes.
Under the mandate of list-decoding, for worst-case errors, the decoder is allowed to output a small list of codewords. With some context specific or side information, it may be possible to prune the list and recover the original transmitted codeword. Hence, in general, this seems to be a stronger error-recovery model than unique decoding.
List-decoding potential
For a polynomial-time list-decoding algorithm to exist, we need the combinatorial guarantee that any Hamming ball of radius 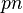 around a received word
around a received word  (where
(where 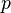 is the fraction of errors in terms of the block length ) has a small number of codewords. This is because the list size itself is clearly a lower bound on the running time of the algorithm. Hence, we require the list size to be a polynomial in the block length of the code. A combinatorial consequence of this requirement is that it imposes an upper bound on the rate of a code. List decoding promises to meet this upper bound. It has been shown non-constructively that codes of rate
is the fraction of errors in terms of the block length ) has a small number of codewords. This is because the list size itself is clearly a lower bound on the running time of the algorithm. Hence, we require the list size to be a polynomial in the block length of the code. A combinatorial consequence of this requirement is that it imposes an upper bound on the rate of a code. List decoding promises to meet this upper bound. It has been shown non-constructively that codes of rate 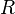 exist that can be list decoded up to a fraction of errors approaching
exist that can be list decoded up to a fraction of errors approaching  . The quantity is referred to in the literature as the list-decoding capacity. This is a substantial gain compared to the unique decoding model as we now have the potential to correct twice as many errors. Naturally, we need to have at least a fraction of the transmitted symbols to be correct in order to recover the message. This is an information-theoretic lower bound on the number of correct symbols required to perform decoding and with list decoding, we can potentially achieve this information-theoretic limit. However, to realize this potential, we need explicit codes (codes that can be constructed in polynomial time) and efficient algorithms to perform encoding and decoding.
. The quantity is referred to in the literature as the list-decoding capacity. This is a substantial gain compared to the unique decoding model as we now have the potential to correct twice as many errors. Naturally, we need to have at least a fraction of the transmitted symbols to be correct in order to recover the message. This is an information-theoretic lower bound on the number of correct symbols required to perform decoding and with list decoding, we can potentially achieve this information-theoretic limit. However, to realize this potential, we need explicit codes (codes that can be constructed in polynomial time) and efficient algorithms to perform encoding and decoding.
Definitions of list decoding
(p, L)-list-decodability
For any error fraction 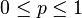 and an integer
and an integer 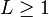 , a code
, a code 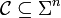 is said to be list decodable up to a fraction of errors with list size at most
is said to be list decodable up to a fraction of errors with list size at most  . In other words, if for every
. In other words, if for every 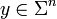 , the number of codewords
, the number of codewords 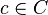 within Hamming distance from is at most , then the code is said to be (, )-list-decodable.
within Hamming distance from is at most , then the code is said to be (, )-list-decodable.
Combinatorics of list decoding
The relation between list decodability of a code and other fundamental parameters such as minimum distance and rate have been fairly well studied. It has been shown that every code can be list decoded using small lists beyond half the minimum distance up to a bound called the Johnson radius. This is quite significant because it proves the existence of (, )-list-decodable codes of good rate with a list-decoding radius much larger than 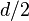 . In other words, the Johnson bound rules out the possibility of having a large number of codewords in a Hamming ball of radius slightly greater than which means that it is possible to correct far more errors with list decoding.
. In other words, the Johnson bound rules out the possibility of having a large number of codewords in a Hamming ball of radius slightly greater than which means that it is possible to correct far more errors with list decoding.
List-decoding capacity
Below, 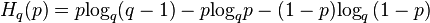 is the q-ary entropy function (defined for
is the q-ary entropy function (defined for  and extended by continuity to ).
and extended by continuity to ).
Theorem (list-decoding capacity)
Let 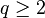 ,
, 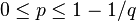 , and
, and  , then the following two statements hold for large enough block length .
, then the following two statements hold for large enough block length .
i) If 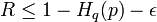 , then there exists a (,
, then there exists a (, 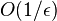 )-list decodable code.
)-list decodable code.
ii) If 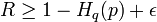 , then every (, )-list-decodable code has
, then every (, )-list-decodable code has 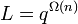 .
.
What this means is that for rates approaching the channel capacity, there exists list decodable codes with polynomial sized lists enabling efficient decoding algorithms whereas for rates exceeding the channel capacity, the list size becomes exponential which rules out the existence of efficient decoding algorithms.
The proof for list-decoding capacity is a significant one in that it exactly matches the capacity of a -ary symmetric channel 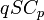 . In fact, the term "list-decoding capacity" should actually be read as the capacity of an adversarial channel under list decoding. Also, the proof for list-decoding capacity is an important result that pin points the optimal trade-off between rate of a code and the fraction of errors that can be corrected under list decoding.
. In fact, the term "list-decoding capacity" should actually be read as the capacity of an adversarial channel under list decoding. Also, the proof for list-decoding capacity is an important result that pin points the optimal trade-off between rate of a code and the fraction of errors that can be corrected under list decoding.
Sketch of proof
The idea behind the proof is similar to that of Shannon's proof for capacity of the binary symmetric channel 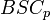 where a random code is picked and showing that it is (, )-list-decodable with high probability as long as the rate
where a random code is picked and showing that it is (, )-list-decodable with high probability as long as the rate 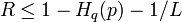 . For rates exceeding the above quantity, it can be shown that the list size becomes super-polynomially large.
. For rates exceeding the above quantity, it can be shown that the list size becomes super-polynomially large.
A "bad" event is defined as one in which, given a received word ![y \in [q]^n](../I/m/3f216e041cf866c4468452a80a8265b3.png) and
and  messages
messages ![m_0, \dots, m_L \in [q]^k](../I/m/e4ca014809ef39f24266325156497b67.png) , it so happens that
, it so happens that 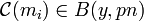 , for every
, for every 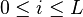 where is the fraction of errors that we wish to correct and
where is the fraction of errors that we wish to correct and 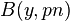 is the Hamming ball of radius with the received word as the center.
is the Hamming ball of radius with the received word as the center.
Now, the probability that a codeword 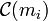 associated with a fixed message
associated with a fixed message ![m_i \in [q]^k](../I/m/b5d24f9e446d0f7a6db9d3e6a9bd32f5.png) lies in a Hamming ball is given by
lies in a Hamming ball is given by
![\Pr[C(m_i) \in B(y, pn)] = \mathrm{Vol}_q(y, pn)/q^n \leq q^{-n(1 - H_q(p))},](../I/m/097f55cc7026b2e4c8700e47e59b3874.png)
where the quantity 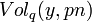 is the volume of a Hamming ball of radius with the received word as the center. The inequality in the above relation follows from the upper bound on the volume of a Hamming ball. The quantity
is the volume of a Hamming ball of radius with the received word as the center. The inequality in the above relation follows from the upper bound on the volume of a Hamming ball. The quantity 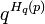 gives a very good estimate on the volume of a Hamming ball of radius centered on any word in
gives a very good estimate on the volume of a Hamming ball of radius centered on any word in ![[q]^n](../I/m/fd56f53f413fd36b409cfdc732be355d.png) . Put another way, the volume of a Hamming ball is translation invariant. To continue with the proof sketch, we conjure the union bound in probability theory which tells us that the probability of a bad event happening for a given
. Put another way, the volume of a Hamming ball is translation invariant. To continue with the proof sketch, we conjure the union bound in probability theory which tells us that the probability of a bad event happening for a given 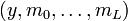 is upper bounded by the quantity
is upper bounded by the quantity 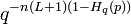 .
.
With the above in mind, the probability of "any" bad event happening can be shown to be less than 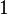 . To show this, we work our way over all possible received words and every possible subset of messages in
. To show this, we work our way over all possible received words and every possible subset of messages in ![[q]^k](../I/m/cb5639474553c23b551c2da8adcc2ca6.png) .
.
Now turning to the proof of part (ii), we need to show that there are super-polynomially many codewords around every when the rate exceeds the list-decoding capacity. We need to show that 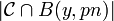 is super-polynomially large if the rate . Fix a codeword
is super-polynomially large if the rate . Fix a codeword 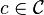 . Now, for every picked at random, we have
. Now, for every picked at random, we have
![\Pr[c \in B(y, pn)] = \Pr[y \in B(c, pn)] \,](../I/m/53e008927397345200d68ad3756db6d3.png)
since Hamming balls are translation invariant. From the definition of the volume of a Hamming ball and the fact that is chosen uniformly at random from we also have
![\Pr[c \in B(y, pn)] = \Pr[y \in B(c, pn)] = \mathrm{Vol}(y, pn) / q^n \ge q^{-n(1-H_q(p)) - o(n)} \,](../I/m/102295880ffa7078c0ae0c98430651e4.png)
Let us now define an indicator variable 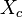 such that
such that
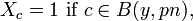
0 otherwise.
Taking the expectation of the volume of a Hamming ball we have
![\begin{align}
E[|B(y, pn)|] & = \sum E[X_c] \text{ for every } c \in \mathcal{C} \\
& = \sum \Pr[X_c = 1]\text{ for every } c \in \mathcal{C} \\
& \ge \sum q^{-n(1 - H_q(p) + o(n))} \\
& = \sum q^{n[R - 1 + H_q(p) + o(1)]} \\
& \ge q^{\Omega(n)}
\end{align}](../I/m/45d5def296ebe4eb2648b56542084dbf.png)
Therefore, by the probabilistic method, we have shown that if the rate exceeds the list-decoding capacity, then the list size becomes super-polynomially large. This completes the proof sketch for the list-decoding capacity.
List-decoding algorithms
In the period from 1995 to 2007, the coding theory community developed progressivly more efficient list-decoding algorithms. Algorithms for Reed–Solomon codes that can decode up to the Johnson radius which is 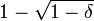 exist where
exist where 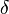 is the normalised distance or relative distance. However, for Reed-Solomon codes,
is the normalised distance or relative distance. However, for Reed-Solomon codes, 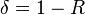 which means a fraction
which means a fraction 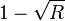 of errors can be corrected. Some of the most prominent list-decoding algorithms are the following:
of errors can be corrected. Some of the most prominent list-decoding algorithms are the following:
- Sudan '95 – The first known non-trivial list-decoding algorithm for Reed–Solomon codes that achieved efficient list decoding up to
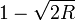 errors developed by Madhu Sudan.
errors developed by Madhu Sudan.
- Guruswami–Sudan '98 – An improvement on the above algorithm for list decoding Reed–Solomon codes up to errors by Madhu Sudan and his then doctoral student Venkatesan Guruswami.
- Parvaresh–Vardy '05 – In a breakthrough paper, Farzad Parvaresh and Alexander Vardy presented codes that can be list decoded beyond the radius for low rates . Their codes are variants of Reed-Solomon codes which are obtained by evaluating
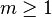 correlated polynomials instead of just as in the case of usual Reed-Solomon codes.
correlated polynomials instead of just as in the case of usual Reed-Solomon codes.
- Guruswami–Rudra '06 - In yet another breakthrough, Venkatesan Guruswami and Atri Rudra give explicit codes that achieve list-decoding capacity, that is, they can be list decoded up to the radius
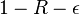 for any
for any  . In other words, this is error-correction with optimal redundancy. This answered a question that had been open for about 50 years. This work has been invited to the Research Highlights section of the Communications of the ACM (which is “devoted to the most important research results published in Computer Science in recent years”) and was mentioned in an article titled “Coding and Computing Join Forces” in the Sep 21, 2007 issue of the Science magazine. The codes that they are give are called folded Reed-Solomon codes which are nothing but plain Reed-Solomon codes but viewed as a code over a larger alphabet by careful bundling of codeword symbols.
. In other words, this is error-correction with optimal redundancy. This answered a question that had been open for about 50 years. This work has been invited to the Research Highlights section of the Communications of the ACM (which is “devoted to the most important research results published in Computer Science in recent years”) and was mentioned in an article titled “Coding and Computing Join Forces” in the Sep 21, 2007 issue of the Science magazine. The codes that they are give are called folded Reed-Solomon codes which are nothing but plain Reed-Solomon codes but viewed as a code over a larger alphabet by careful bundling of codeword symbols.
Because of their ubiquity and the nice algebraic properties they possess, list-decoding algorithms for Reed–Solomon codes were a main focus of researchers. The list-decoding problem for Reed–Solomon codes can be formulated as follows:
Input: For an ![[n, k + 1]_q](../I/m/ca6b8f35538b1b70a3d900aa50f86f37.png) Reed-Solomon code, we are given the pair
Reed-Solomon code, we are given the pair 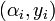 for
for  , where
, where 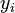 is the
is the  th bit of the received word and the
th bit of the received word and the  's are distinct points in the finite field
's are distinct points in the finite field 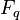 and an error parameter
and an error parameter 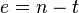 .
.
Output: The goal is to find all the polynomials ![P(X) \in F_q[X]](../I/m/059fd836aa1b571a73a2a0134db3fdab.png) of degree at most which is the message length such that
of degree at most which is the message length such that 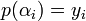 for at least
for at least  values of . Here, we would like to have as small as possible so that greater number of errors can be tolerated.
values of . Here, we would like to have as small as possible so that greater number of errors can be tolerated.
With the above formulation, the general structure of list-decoding algorithms for Reed-Solomon codes is as follows:
Step 1: (Interpolation) Find a non-zero bivariate polynomial 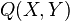 such that
such that 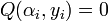 for .
for .
Step 2: (Root finding/Factorization) Output all degree polynomials 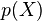 such that
such that 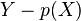 is a factor of i.e.
is a factor of i.e. 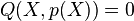 . For each of these polynomials, check if for at least values of
. For each of these polynomials, check if for at least values of ![i \in [n]](../I/m/bc2042aaa4625cfa2270ea184ca820d9.png) . If so, include such a polynomial in the output list.
. If so, include such a polynomial in the output list.
Given the fact that bivariate polynomials can be factored efficiently, the above algorithm runs in polynomial time.
Applications in complexity theory and cryptography
Algorithms developed for list decoding of several interesting code families have found interesting applications in computational complexity and the field of cryptography. Following is a sample list of applications outside of coding theory:
- Construction of hard-core predicates from one-way permutations.
- Predicting witnesses for NP-search problems.
- Amplifying hardness of Boolean functions.
- Average case hardness of permanent of random matrices.
- Extractors and Pseudorandom generators.
- Efficient traitor tracing.
External links
- A Survey on list decoding by Madhu Sudan
- Notes from a course taught by Madhu Sudan
- Notes from a course taught by Luca Trevisan
- Notes from a course taught by Venkatesan Guruswami
- Notes from a course taught by Atri Rudra
- P. Elias, "List decoding for noisy channels," Technical Report 335, Research Laboratory of Electronics, MIT, 1957.
- P. Elias, "Error-correcting codes for list decoding," IEEE Transactions on Information Theory, vol. 37, pp. 5–12, 1991.
- J. M. Wozencraft, "List decoding," Quarterly Progress Report, Research Laboratory of Electronics, MIT, vol. 48, pp. 90–95, 1958.
- Venkatesan Guruswami's PhD thesis
- Algorithmic Results in List Decoding
- Folded Reed–Solomon code