Indexed grammar
Indexed grammars are a generalization of context-free grammars in that nonterminals are equipped with lists of flags, or index symbols. The language produced by an indexed grammar is called an indexed language.
Definition
Modern definition by Hopcroft and Ullman
In contemporary publications following Hopcroft and Ullman (1979), [1] an indexed grammar is formally defined a 5-tuple G = ⟨N,T,F,P,S⟩ where
- N is a set of variables or nonterminal symbols,
- T is a set ("alphabet") of terminal symbols,
- F is a set of so-called index symbols, or indices,
- S ∈ N is the start symbol, and
- P is a finite set of productions.
In productions as well as in derivations of indexed grammars, a string ("stack") σ ∈ F* of index symbols is attached to every nonterminal symbol A ∈ N, denoted by A[σ].[note 1] Terminal symbols may not be followed by index stacks. For an index stack σ ∈ F* and a string α ∈ (N ∪ T)* of nonterminal and terminal symbols, α[σ] denotes the result of attaching [σ] to every nonterminal in α; for example if α equals a B C d E with a,d ∈ T terminal, and B,C ,E ∈ N nonterminal symbols, then α[σ] denotes a B[σ] C[σ] d E[σ]. Using this notation, each production in P has to be of the form
- A[σ] → α[σ],
- A[σ] → B[fσ], or
- A[fσ] → α[σ],
where A, B ∈ N are nonterminal symbols, f ∈ F is an index, σ ∈ F* is a string of index symbols, and α ∈ (N ∪ T)* is a string of nonterminal and terminal symbols. Some authors write ".." instead of "σ" for the index stack in production rules; the rule of type 1, 2, and 3 then reads A[..]→α[..], A[..]→B[f..], and A[f..]→α[..], respectively.
Derivations are similar to those in a context-free grammar except for the index stack attached to each nonterminal symbol. When a production like e.g. A[σ] → B[σ]C[σ] is applied, the index stack of A is copied to both B and C. Moreover, a rule can push an index symbol onto the stack, or pop its "topmost" (i.e., leftmost) index symbol.
Formally, the relation ⇒ ("direct derivation") is defined on the set (N[F*]∪T)* of "sentential forms" as follows:
- If A[σ] → α[σ] is a production of type 1, then β A[φ] γ ⇒ β α[φ] γ, using the above definition. That is, the rule's left hand side's index stack φ is copied to each nonterminal of the right hand side.
- If A[σ] → B[fσ] is a production of type 2, then β A[φ] γ ⇒ β B[fφ] γ. That is, the right hand side's index stack is obtained from the left hand side's stack φ by pushing f onto it.
- If A[fσ] → α[σ] is a production of type 3, then β A[fφ] γ ⇒ β α[φ] γ, using again the definition of α[σ]. That is, the first index f is popped from the left hand side's stack, which is then distributed to each nonterminal of the right hand side.
As usual, the derivation relation ⇒* is defined as the reflexive transitive closure of direct derivation ⇒. The language L(G) = { w ∈ T*: S ⇒* w } is the set of all strings of terminal symbols derivable from the start symbol.
Original definition by Aho
Historically, indexed grammar were introduced by Alfred Aho (1968)[3] using a different formalism. Aho defined an indexed grammar to be a 5-tuple (N,T,F,P,S) where
- N is a finite alphabet of variables or nonterminal symbols
- T is a finite alphabet of terminal symbols
- F ⊆ 2N × (N ∪ T)* is the finite set of so-called flags (each flag is itself a set of so-called index productions)
- P ⊆ N × (NF* ∪ T)* is the finite set of productions
- S ∈ N is the start symbol
Direct derivations were as follows:
- A production p = (A → X1η1…Xkηk) from P matches a nonterminal A ∈ N followed by its (possibly empty) string of flags ζ ∈ F*. In context, γ Aζ δ, via p, derives to γ X1θ1…Xkθk δ, where θi = ηiζ if Xi was a nonterminal and the empty word otherwise. The old flags of A are therefore copied to each new nonterminal produced by p. Each such production can be simulated by appropriate productions of type 1 and 2 in the Hopcroft/Ullman formalism.
- An index production p = (A → X1…Xk) ∈ f matches Afζ (the flag f it comes from must match the first symbol following the nonterminal A) and copies the remaining index string ζ to each new nonterminal: γ Afζ δ derives to γ X1θ1…Xkθk δ, where θi is the empty word when Xi is a nonterminal and ζ otherwise. Each such production corresponds to a production of type 3 in the Hopcroft/Ullman formalism.
This formalism is e.g. used by Hayashi (1973, p. 65-66).[4]
Examples
In practice, stacks of indices can count and remember what rules were applied and in which order. For example, indexed grammars can describe the context-sensitive language of word triples { www : w ∈ {a,b}* }:
| S[σ] | → | S[fσ] | T[fσ] | → | a T[σ] |
| S[σ] | → | S[gσ] | T[gσ] | → | b T[σ] |
| S[σ] | → | T[σ] T[σ] T[σ] | T[] | → | ε |
A derivation of abbabbabb is then
- S[] ⇒ S[g] ⇒ S[gg] ⇒ S[fgg] ⇒ T[fgg] T[fgg] T[fgg] ⇒ a T[gg] T[fgg] T[fgg] ⇒ ab T[g] T[fgg] T[fgg] ⇒ abb T[] T[fgg] T[fgg] ⇒ abb T[fgg] T[fgg] ⇒ ... ⇒ abb abb T[fgg] ⇒ ... ⇒ abb abb abb.
As another example, the grammar G = ⟨ {S,T,A,B,C}, {a,b,c}, {f,g}, P, S ⟩ produces the language { anbncn: n ≥ 1 }, where the production set P consists of
| S[σ] → T[gσ] | A[fσ] → a A[σ] | A[gσ] → a |
| T[σ] → T[fσ] | B[fσ] → b B[σ] | B[gσ] → b |
| T[σ] → A[σ] B[σ] C[σ] | C[fσ] → c C[σ] | C[gσ] → c |
An example derivation is
- S[] ⇒ T[g] ⇒ T[fg] ⇒ A[fg] B[fg] C[fg] ⇒ aA[g] B[fg] C[fg] ⇒ aA[g] bB[g] C[fg] ⇒ aA[g] bB[g] cC[g] ⇒ aa bB[g] cC[g] ⇒ aa bb cC[g] ⇒ aa bb cc.
Both example languages are known to be not context-free.
Properties
Hopcroft and Ullman tend to consider indexed languages as a "natural" class, since they are generated by several formalisms other than indexed grammars, viz.[5]
- Aho's one-way nested stack automata[6]
- Fischer's macro grammars[7]
- Greibach's automata with stacks of stacks[8]
- Maibaum's algebraic characterization[9]
Hayashi[4] generalized the pumping lemma to indexed grammars. Conversely, Gilman[10][11] gives a "shrinking lemma" for indexed languages.
Linear indexed grammars
Gerald Gazdar has defined a second class, the linear indexed grammars (LIG),[12] by requiring that at most one nonterminal in each production be specified as receiving the stack,[note 2] whereas in an ordinary indexed grammar, all nonterminals receive copies of the stack. Formally, a linear indexed grammar is defined similar to an ordinary indexed grammar, but the production's form requirements are modified to:
- A[σ] → α[] B[σ] β[],
- A[σ] → α[] B[fσ] β[],
- A[fσ] → α[] B[σ] β[],
where A, B, f, σ, α are used as above, and β ∈ (N ∪ T)* is a string of nonterminal and terminal symbols like α.[note 3] Also, the direct derivation relation ⇒ is defined similar to above. This new class of grammars defines a strictly smaller class of languages,[15] which belongs to the mildly context-sensitive classes.
The language { www : w ∈ {a,b}* } is generable by an indexed grammar, but not by a linear indexed grammar, while { an bn cn : n ≥ 1 } is generable by a linear indexed grammar.
If both the original and the modified production rules are admitted, the language class remains the indexed languages.[16]
Example
Letting σ denote an arbitrary collection of stack symbols, we can define a grammar for the language L = {an bn cn | n ≥ 1 }[note 4] as
| S[σ] | → | a S[fσ] c |
| S[σ] | → | T[σ] |
| T[fσ] | → | T[σ] b |
| T[] | → | ε |
To derive the string abc we have the steps S[] ⇒ aS[f]c ⇒ aT[f]c ⇒ aT[]bc ⇒ abc.
Similarly: S[] ⇒ aS[f]c ⇒ aaS[ff]cc ⇒ aaT[ff]cc ⇒ aaT[f]bcc ⇒ aaT[]bbcc ⇒ aabbcc.
Computational Power
The linearly indexed languages are a subset of the indexed languages, and thus all LIGs can be recoded as IGs, making the LIGs strictly less powerful than the IGs. A conversion from a LIG to an IG is relatively simple.[17] LIG rules in general look approximately like ![X[\sigma] \to \alpha Y[\sigma] \beta](../I/m/eba7406d8dca695e471849f19f7ad790.png) , modulo the push/pop part of a rewrite rule. The symbols
, modulo the push/pop part of a rewrite rule. The symbols  and
and 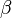 represent strings of terminal and/or non-terminal symbols, and any non-terminal symbol in either must have an empty stack, by the definition of a LIG. This is, of course, counter to how IGs are defined: in an IG, the non-terminals whose stacks are not being pushed to or popped from must have exactly the same stack as the rewritten non-terminal. Thus, somehow, we need to have non-terminals in and which, despite having non-empty stacks, behave as if they had empty stacks.
represent strings of terminal and/or non-terminal symbols, and any non-terminal symbol in either must have an empty stack, by the definition of a LIG. This is, of course, counter to how IGs are defined: in an IG, the non-terminals whose stacks are not being pushed to or popped from must have exactly the same stack as the rewritten non-terminal. Thus, somehow, we need to have non-terminals in and which, despite having non-empty stacks, behave as if they had empty stacks.
Let's consider the rule ![X[\sigma] \to Y[] Z[\sigma f]](../I/m/f2113740c0a1531b38dbddd6294f7d51.png) as an example case. In converting this to an IG, the replacement for
as an example case. In converting this to an IG, the replacement for ![Y[]](../I/m/e48e83a9f8b1e5b0eef43a3e09703957.png) must be some
must be some ![Y^{\prime}[\sigma]](../I/m/8285d28e78e3a730d4d7c367ba1bae2d.png) that behaves exactly like regardless of what
that behaves exactly like regardless of what 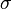 is. To achieve this, we can simply have a pair of rules that takes any where is not empty, and pops symbols from the stack. Then, when the stack is empty, it can be rewritten as .
is. To achieve this, we can simply have a pair of rules that takes any where is not empty, and pops symbols from the stack. Then, when the stack is empty, it can be rewritten as .
![Y^{\prime}[\sigma f] \to Y^{\prime}[\sigma]](../I/m/6fcc167dc9c56fb65c9e43b622e93164.png)
![Y^{\prime}[] \to Y[]](../I/m/24e4bc0ecf837f1ef8bdbafa660b25a9.png)
We can apply this in general to derive an IG from an LIG. So for example if the LIG for the language  is as follows:
is as follows:
![S[\sigma] \to T[\sigma]V[]](../I/m/f1e7dcb45f5d9346f6efe166a6874f7a.png)
![V[] \to d ~|~ dV[]](../I/m/a5ebeda3baae5ba9420c44a8d43210d5.png)
![T[\sigma] \to aT[\sigma f]c ~|~ U[\sigma]](../I/m/b368c590b011bf1a65021edcd4593911.png)
![U[\sigma f] \to bU[\sigma]](../I/m/d69757528a489e3025f103ed26d45f3f.png)
![U[] \to \epsilon](../I/m/d1841f74b630dae9b80debf7b3f9c94c.png)
The sentential rule here is not an IG rule, but using the above conversion algorithm, we can define new rules for  , changing the grammar to:
, changing the grammar to:
![S[\sigma] \to T[\sigma]V^{\prime}[\sigma]](../I/m/9a89b24f2e10ca2997176c15a9fb1a96.png)
![V^{\prime}[\sigma f] \to V^{\prime}[\sigma]](../I/m/c2cd6c173082eec0b2156234bc7cea96.png)
![V^{\prime}[] \to V[]](../I/m/04bf72ac90c36e3704d2fc14da7a6adc.png)
Each rule now fits the definition of an IG, in which all the non-terminals in the right hand side of a rewrite rule receive a copy of the rewritten symbol's stack. The indexed grammars are therefore able to describe all the languages that linearly indexed grammars can describe.
Relation to other formalism
Vijay-Shanker and Weir (1994)[18] demonstrates that Linear Indexed Grammars, Combinatory Categorial Grammars, Tree-adjoining Grammars, and Head Grammars all define the same class of string languages. Their formal definition of linear indexed grammars[19] differs from the above.
LIGs (and their weakly equivalents) are strictly less expressive (meaning they generate a proper subset) than the languages generated by another family of weakly equivalent formalism, which include: LCFRS, MCTAG, MCFG and minimalist grammars (MGs). The latter family can (also) be parsed in polynomial time.[20]
Distributed Index (DI) grammars
Another form of indexed grammars, introduced by Staudacher (1993),[13] is the class of Distributed Index grammars (DIGs). What distinguishes DIGs from Aho's Indexed Grammars is the propagation of indexes. Unlike Aho's IGs, which distribute the whole symbol stack to all non-terminals during a rewrite operation, DIGs divide the stack into substacks and distributes the substacks to selected non-terminals.
The general rule schema for a binarily distributing rule of DIG is the form
X[f1...fifi+1...fn] → α Y[f1...fi] β Z[fi+1...fn] γ
Where α, β, and γ are arbitrary terminal strings. For a ternarily distributing string:
X[f1...fifi+1...fjfj+1...fn] → α Y[f1...fi] β Z[fi+1...fj] γ W[fj+1...fn] η
And so forth for higher numbers of non-terminals in the right hand side of the rewrite rule. In general, if there are m non-terminals in the right hand side of a rewrite rule, the stack is partitioned m ways and distributed amongst the new non-terminals. Notice that there is a special case where a partition is empty, which effectively makes the rule a LIG rule. The Distributed Index languages are therefore a superset of the Linearly Indexed languages.
See also
Notes
- ↑ "[" and "]" are meta symbols to indicate the stack.
- ↑ all other nonterminals receive an empty stack
- 1 2 In order to generate any string at all, some productions must be admitted having no nonterminal symbol on their right hand side. However, Gazdar didn't discuss this issue.
- ↑ Cf. the properly indexed grammar for the same language given above. The last rule, viz. T[]→ε, of the linear indexed grammar doesn't conform to Gazdar's definition in a strict sense, cf. [note 3]
References
- ↑ Hopcroft and Ullman (1979),[2] Sect.14.3, p.389-390. This section is omitted in the 2nd edition 2003.
- 1 2 Hopcroft, John E.; Jeffrey D. Ullman (1979). Introduction to Automata Theory, Languages, and Computation. Addison-Wesley. ISBN 0-201-02988-X.
- ↑ Aho, Alfred (1968). "Indexed grammars—an extension of context-free grammars". Journal of the ACM 15 (4): 647–671. doi:10.1145/321479.321488.
- 1 2 T. Hayashi (1973). "On Derivation Trees of Indexed Grammars - An Extension of the uvxyz Theorem". Publication of the Research Institute for Mathematical Sciences (Research Institute for Mathematical Sciences) 9 (1): 61–92. doi:10.2977/prims/1195192738.
- ↑ Hopcroft and Ullman (1979),[2] Bibliographic notes, p.394-395
- ↑ Alfred Aho (1969). "Nested Stack Automata". Journal of the ACM 16 (3): 383–406. doi:10.1145/321526.321529.
- ↑ Michael J. Fischer (1968). "Grammars with Macro-Like Productions". Proc. 9th Ann. IEEE Symp. on Switching and Automata Theory (SWAT). pp. 131–142.
- ↑ Sheila A. Greibach (1970). "Full AFL's and Nested Iterated Substitution" (PDF). Information and Control 16 (1): 7–35. doi:10.1016/s0019-9958(70)80039-0.
- ↑ T.S.E. Maibaum (1974). "A Generalized Approach to Formal Languages" (PDF). J. Computer and System Sciences 8 (3): 409–439. doi:10.1016/s0022-0000(74)80031-0.
- ↑ Robert H. Gilman (1996). "A Shrinking Lemma for Indexed Languages" (PDF). Theoretical Computer Science 163: 277–281. doi:10.1016/0304-3975(96)00244-7.
- ↑ Robert H. Gilman (Sep 1995). "A Shrinking Lemma for Indexed Languages".
- ↑ According to Staudacher (1993, p.361 left, Sect.2.2),[13] the name "linear indexed grammars" wasn't used in Gazdar's 1988 paper, but appeared later, e.g. in Weir and Joshi (1988).[14]
- 1 2 Staudacher, Peter (1993), New frontiers beyond context-freeness: DI-grammars and DI-automata. (PDF), pp. 358–367
- ↑ David J. Weir, Aravind K. Joshi (1988). "Combinatory Categorial Grammars: Generative Power and Relationship to Linear Context-Free Rewriting Systems". Proc. 26th Meeting Assoc. Comput. Ling. (PDF). pp. 278–285.
- ↑ Gazdar, Gerald (1988). "Applicability of Indexed Grammars to Natural Languages". In U. Reyle and C. Rohrer. Natural Language Parsing and Linguistic Theories. Studies in linguistics and philosophy 35. D. Reidel Publishing Company. pp. 69–94. ISBN 1-55608-055-7.
- ↑ Gazdar (1988), Appendix, p.89
- ↑ Gazdar 1988, Appendix, p.89-91
- ↑ Vijay-Shanker, K. and Weir, David J. 1994. "The Equivalence of Four Extensions of Context-Free Grammars". Mathematical Systems Theory 27 (6): 511–546. doi:10.1007/bf01191624.
- ↑ p.517-518
- ↑ Johan F.A.K. van Benthem; Alice ter Meulen (2010). Handbook of Logic and Language (2nd ed.). Elsevier. p. 404. ISBN 978-0-444-53727-0.
External links
| |||||||||||||||||||