Learning to rank
| Machine learning and data mining |
|---|
 |
| Problems |
| Clustering |
| Dimensionality reduction |
| Structured prediction |
| Anomaly detection |
| Neural nets |
| Theory |
| Machine learning venues |
| Data mining venues |
|
|
Learning to rank[1] or machine-learned ranking (MLR) is the application of machine learning, typically supervised, semi-supervised or reinforcement learning, in the construction of ranking models for information retrieval systems.[2] Training data consists of lists of items with some partial order specified between items in each list. This order is typically induced by giving a numerical or ordinal score or a binary judgment (e.g. "relevant" or "not relevant") for each item. The ranking model's purpose is to rank, i.e. produce a permutation of items in new, unseen lists in a way which is "similar" to rankings in the training data in some sense.
Learning to rank is a relatively new research area which has emerged in the past decade.
Applications
In information retrieval
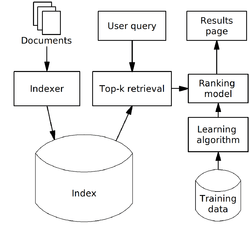
Ranking is a central part of many information retrieval problems, such as document retrieval, collaborative filtering, sentiment analysis, and online advertising.
A possible architecture of a machine-learned search engine is shown in the figure to the right.
Training data consists of queries and documents matching them together with relevance degree of each match. It may be prepared manually by human assessors (or raters, as Google calls them), who check results for some queries and determine relevance of each result. It is not feasible to check relevance of all documents, and so typically a technique called pooling is used — only the top few documents, retrieved by some existing ranking models are checked. Alternatively, training data may be derived automatically by analyzing clickthrough logs (i.e. search results which got clicks from users),[3] query chains,[4] or such search engines' features as Google's SearchWiki.
Training data is used by a learning algorithm to produce a ranking model which computes relevance of documents for actual queries.
Typically, users expect a search query to complete in a short time (such as a few hundred milliseconds for web search), which makes it impossible to evaluate a complex ranking model on each document in the corpus, and so a two-phase scheme is used.[5] First, a small number of potentially relevant documents are identified using simpler retrieval models which permit fast query evaluation, such as the vector space model, boolean model, weighted AND,[6] and BM25. This phase is called top- document retrieval and many heuristics were proposed in the literature to accelerate it, such as using a document's static quality score and tiered indexes.[7] In the second phase, a more accurate but computationally expensive machine-learned model is used to re-rank these documents.
document retrieval and many heuristics were proposed in the literature to accelerate it, such as using a document's static quality score and tiered indexes.[7] In the second phase, a more accurate but computationally expensive machine-learned model is used to re-rank these documents.
In other areas
Learning to rank algorithms have been applied in areas other than information retrieval:
- In machine translation for ranking a set of hypothesized translations;[8]
- In computational biology for ranking candidate 3-D structures in protein structure prediction problem.[8]
- In proteomics for the identification of frequent top scoring peptides.[9]
- In Recommender systems for identifying a ranked list of related news articles to recommend to a user after he or she has read a current news article.[10]
Feature vectors
For convenience of MLR algorithms, query-document pairs are usually represented by numerical vectors, which are called feature vectors. Such an approach is sometimes called bag of features and is analogous to the bag of words model and vector space model used in information retrieval for representation of documents.
Components of such vectors are called features, factors or ranking signals. They may be divided into three groups (features from document retrieval are shown as examples):
- Query-independent or static features — those features, which depend only on the document, but not on the query. For example, PageRank or document's length. Such features can be precomputed in off-line mode during indexing. They may be used to compute document's static quality score (or static rank), which is often used to speed up search query evaluation.[7][11]
- Query-dependent or dynamic features — those features, which depend both on the contents of the document and the query, such as TF-IDF score or other non-machine-learned ranking functions.
- Query level features or query features, which depend only on the query. For example, the number of words in a query. Further information: query level feature
Some examples of features, which were used in the well-known LETOR dataset:[12]
- TF, TF-IDF, BM25, and language modeling scores of document's zones (title, body, anchors text, URL) for a given query;
- Lengths and IDF sums of document's zones;
- Document's PageRank, HITS ranks and their variants.
Selecting and designing good features is an important area in machine learning, which is called feature engineering.
Evaluation measures
There are several measures (metrics) which are commonly used to judge how well an algorithm is doing on training data and to compare performance of different MLR algorithms. Often a learning-to-rank problem is reformulated as an optimization problem with respect to one of these metrics.
Examples of ranking quality measures:
- Mean average precision (MAP);
- DCG and NDCG;
- Precision@n, NDCG@n, where "@n" denotes that the metrics are evaluated only on top n documents;
- Mean reciprocal rank;
- Kendall's tau
- Spearman's Rho
DCG and its normalized variant NDCG are usually preferred in academic research when multiple levels of relevance are used.[13] Other metrics such as MAP, MRR and precision, are defined only for binary judgements.
Recently, there have been proposed several new evaluation metrics which claim to model user's satisfaction with search results better than the DCG metric:
Both of these metrics are based on the assumption that the user is more likely to stop looking at search results after examining a more relevant document, than after a less relevant document.
Approaches
Tie-Yan Liu of Microsoft Research Asia in his paper "Learning to Rank for Information Retrieval"[1] and talks at several leading conferences has analyzed existing algorithms for learning to rank problems and categorized them into three groups by their input representation and loss function:
Pointwise approach
In this case it is assumed that each query-document pair in the training data has a numerical or ordinal score. Then learning-to-rank problem can be approximated by a regression problem — given a single query-document pair, predict its score.
A number of existing supervised machine learning algorithms can be readily used for this purpose. Ordinal regression and classification algorithms can also be used in pointwise approach when they are used to predict score of a single query-document pair, and it takes a small, finite number of values.
Pairwise approach
In this case learning-to-rank problem is approximated by a classification problem — learning a binary classifier that can tell which document is better in a given pair of documents. The goal is to minimize average number of inversions in ranking.
Listwise approach
These algorithms try to directly optimize the value of one of the above evaluation measures, averaged over all queries in the training data. This is difficult because most evaluation measures are not continuous functions with respect to ranking model's parameters, and so continuous approximations or bounds on evaluation measures have to be used.
List of methods
A partial list of published learning-to-rank algorithms is shown below with years of first publication of each method:
Year Name Type Notes 1989 OPRF [16] pointwise Polynomial regression (instead of machine learning, this work refers to pattern recognition, but the idea is the same) 1992 SLR [17] pointwise Staged logistic regression 2000 Ranking SVM (RankSVM) pairwise A more recent exposition is in,[3] which describes an application to ranking using clickthrough logs. 2002 Pranking[18] pointwise Ordinal regression. 2003 RankBoost pairwise 2005 RankNet pairwise 2006 IR-SVM pairwise Ranking SVM with query-level normalization in the loss function. 2006 LambdaRank pairwise RankNet in which pairwise loss function is multiplied by the change in the IR metric caused by a swap. 2007 AdaRank listwise 2007 FRank pairwise Based on RankNet, uses a different loss function - fidelity loss. 2007 GBRank pairwise 2007 ListNet listwise 2007 McRank pointwise 2007 QBRank pairwise 2007 RankCosine listwise 2007 RankGP[19] listwise 2007 RankRLS pairwise Regularized least-squares based ranking. The work is extended in [20] to learning to rank from general preference graphs.
2007 SVMmap listwise 2008 LambdaMART pairwise Winning entry in the recent Yahoo Learning to Rank competition used an ensemble of LambdaMART models.[21] 2008 ListMLE listwise Based on ListNet. 2008 PermuRank listwise 2008 SoftRank listwise 2008 Ranking Refinement[22] pairwise A semi-supervised approach to learning to rank that uses Boosting. 2008 SSRankBoost[23] pairwise An extension of RankBoost to learn with partially labeled data (semi-supervised learning to rank) 2008 SortNet[24] pairwise SortNet, an adaptive ranking algorithm which orders objects using a neural network as a comparator. 2009 MPBoost pairwise Magnitude-preserving variant of RankBoost. The idea is that the more unequal are labels of a pair of documents, the harder should the algorithm try to rank them. 2009 BoltzRank listwise Unlike earlier methods, BoltzRank produces a ranking model that looks during query time not just at a single document, but also at pairs of documents. 2009 BayesRank listwise A method combines Plackett-Luce Model and neural network to minimize the expected Bayes risk, related to NDCG, from the decision-making aspect. 2010 NDCG Boost[25] listwise A boosting approach to optimize NDCG. 2010 GBlend pairwise Extends GBRank to the learning-to-blend problem of jointly solving multiple learning-to-rank problems with some shared features. 2010 IntervalRank pairwise & listwise 2010 CRR pointwise & pairwise Combined Regression and Ranking. Uses stochastic gradient descent to optimize a linear combination of a pointwise quadratic loss and a pairwise hinge loss from Ranking SVM.
Note: as most supervised learning algorithms can be applied to pointwise case, only those methods which are specifically designed with ranking in mind are shown above.
History
Norbert Fuhr introduced the general idea of MLR in 1992, describing learning approaches in information retrieval as a generalization of parameter estimation;[26] a specific variant of this approach (using polynomial regression) had been published by him three years earlier.[16] Bill Cooper proposed logistic regression for the same purpose in 1992 [17] and used it with his Berkeley research group to train a successful ranking function for TREC. Manning et al.[27] suggest that these early works achieved limited results in their time due to little available training data and poor machine learning techniques.
Several conferences, such as NIPS, SIGIR and ICML had workshops devoted to the learning-to-rank problem since mid-2000s (decade).
Practical usage by search engines
Commercial web search engines began using machine learned ranking systems since the 2000s (decade). One of the first search engines to start using it was AltaVista (later its technology was acquired by Overture, and then Yahoo), which launched a gradient boosting-trained ranking function in April 2003.[28][29]
Bing's search is said to be powered by RankNet algorithm,[30] which was invented at Microsoft Research in 2005.
In November 2009 a Russian search engine Yandex announced[31] that it had significantly increased its search quality due to deployment of a new proprietary MatrixNet algorithm, a variant of gradient boosting method which uses oblivious decision trees.[32] Recently they have also sponsored a machine-learned ranking competition "Internet Mathematics 2009"[33] based on their own search engine's production data. Yahoo has announced a similar competition in 2010.[34]
As of 2008, Google's Peter Norvig denied that their search engine exclusively relies on machine-learned ranking.[35] Cuil's CEO, Tom Costello, suggests that they prefer hand-built models because they can outperform machine-learned models when measured against metrics like click-through rate or time on landing page, which is because machine-learned models "learn what people say they like, not what people actually like".[36]
References
- 1 2 Tie-Yan Liu (2009), "Learning to Rank for Information Retrieval", Foundations and Trends in Information Retrieval, Foundations and Trends in Information Retrieval 3 (3): 225–331, doi:10.1561/1500000016, ISBN 978-1-60198-244-5. Slides from Tie-Yan Liu's talk at WWW 2009 conference are available online
- ↑ Mehryar Mohri, Afshin Rostamizadeh, Ameet Talwalkar (2012) Foundations of Machine Learning, The MIT Press ISBN 9780262018258.
- 1 2 Joachims, T. (2002), "Optimizing Search Engines using Clickthrough Data" (PDF), Proceedings of the ACM Conference on Knowledge Discovery and Data Mining
- ↑ Joachims T., Radlinski F. (2005), "Query Chains: Learning to Rank from Implicit Feedback" (PDF), Proceedings of the ACM Conference on Knowledge Discovery and Data Mining
- ↑ B. Cambazoglu, H. Zaragoza, O. Chapelle, J. Chen, C. Liao, Z. Zheng, and J. Degenhardt., "Early exit optimizations for additive machine learned ranking systems" (PDF), WSDM '10: Proceedings of the Third ACM International Conference on Web Search and Data Mining, 2010.
- ↑ Broder A., Carmel D., Herscovici M., Soffer A., Zien J. (2003), "Efficient query evaluation using a two-level retrieval process" (PDF), Proceedings of the twelfth international conference on Information and knowledge management: 426–434, ISBN 1-58113-723-0
- 1 2 Manning C., Raghavan P. and Schütze H. (2008), Introduction to Information Retrieval, Cambridge University Press. Section 7.1
- 1 2 Kevin K. Duh (2009), Learning to Rank with Partially-Labeled Data (PDF)
- ↑ Henneges C., Hinselmann G., Jung S., Madlung J., Schütz W., Nordheim A., Zell A. (2009), Ranking Methods for the Prediction of Frequent Top Scoring Peptides from Proteomics Data (PDF)
- ↑ Yuanhua Lv, Taesup Moon, Pranam Kolari, Zhaohui Zheng, Xuanhui Wang, and Yi Chang, Learning to Model Relatedness for News Recommendation, in International Conference on World Wide Web (WWW), 2011.
- ↑ Richardson, M.; Prakash, A.; Brill, E. (2006). "Beyond PageRank: Machine Learning for Static Ranking" (PDF). Proceedings of the 15th International World Wide Web Conference. pp. 707–715.
- ↑ LETOR 3.0. A Benchmark Collection for Learning to Rank for Information Retrieval
- ↑ http://www.stanford.edu/class/cs276/handouts/lecture15-learning-ranking.ppt
- ↑ Olivier Chapelle, Donald Metzler, Ya Zhang, Pierre Grinspan (2009), "Expected Reciprocal Rank for Graded Relevance" (PDF), CIKM
- ↑ Gulin A., Karpovich P., Raskovalov D., Segalovich I. (2009), "Yandex at ROMIP'2009: optimization of ranking algorithms by machine learning methods" (PDF), Proceedings of ROMIP'2009: 163–168 (in Russian)
- 1 2 Fuhr, Norbert (1989), "Optimum polynomial retrieval functions based on the probability ranking principle", ACM Transactions on Information Systems 7 (3): 183–204, doi:10.1145/65943.65944
- 1 2 Cooper, William S.; Gey, Frederic C.; Dabney, Daniel P. (1992), "Probabilistic retrieval based on staged logistic regression", SIGIR '92 Proceedings of the 15th annual international ACM SIGIR conference on Research and development in information retrieval: 198–210, doi:10.1145/133160.133199
- ↑ "Pranking". CiteSeerX: 10
.1 ..1 .20 .378 - ↑ "RankGP". CiteSeerX: 10
.1 ..1 .90 .220 - ↑ Pahikkala, Tapio; Tsivtsivadze, Evgeni, Airola, Antti, Järvinen, Jouni, Boberg, Jorma (2009), "An efficient algorithm for learning to rank from preference graphs", Machine Learning 75 (1): 129–165, doi:10.1007/s10994-008-5097-z. Cite uses deprecated parameter
|coauthors=(help) - ↑ C. Burges. (2010). From RankNet to LambdaRank to LambdaMART: An Overview.
- ↑ Rong Jin, Hamed Valizadegan, Hang Li, Ranking Refinement and Its Application for Information Retrieval, in International Conference on World Wide Web (WWW), 2008.
- ↑ Massih-Reza Amini, Vinh Truong, Cyril Goutte, A Boosting Algorithm for Learning Bipartite Ranking Functions with Partially Labeled Data, International ACM SIGIR conference, 2008. The code is available for research purposes.
- ↑ Leonardo Rigutini, Tiziano Papini, Marco Maggini, Franco Scarselli, "SortNet: learning to rank by a neural-based sorting algorithm", SIGIR 2008 workshop: Learning to Rank for Information Retrieval, 2008
- ↑ Hamed Valizadegan, Rong Jin, Ruofei Zhang, Jianchang Mao, Learning to Rank by Optimizing NDCG Measure, in Proceeding of Neural Information Processing Systems (NIPS), 2010.
- ↑ Fuhr, Norbert (1992), "Probabilistic Models in Information Retrieval", Computer Journal 35 (3): 243–255, doi:10.1093/comjnl/35.3.243
- ↑ Manning C., Raghavan P. and Schütze H. (2008), Introduction to Information Retrieval, Cambridge University Press. Sections 7.4 and 15.5
- ↑ Jan O. Pedersen. The MLR Story
- ↑ U.S. Patent 7,197,497
- ↑ Bing Search Blog: User Needs, Features and the Science behind Bing
- ↑ Yandex corporate blog entry about new ranking model "Snezhinsk" (in Russian)
- ↑ The algorithm wasn't disclosed, but a few details were made public in and .
- ↑ Yandex's Internet Mathematics 2009 competition page
- ↑ Yahoo Learning to Rank Challenge
- ↑ Rajaraman, Anand (2008-05-24). "Are Machine-Learned Models Prone to Catastrophic Errors?". Archived from the original on 2010-09-18.
- ↑ Costello, Tom (2009-06-26). "Cuil Blog: So how is Bing doing?". Archived from the original on 2010-09-15.
External links
- Competitions and public datasets
- LETOR: A Benchmark Collection for Research on Learning to Rank for Information Retrieval
- Yandex's Internet Mathematics 2009
- Yahoo! Learning to Rank Challenge
- Microsoft Learning to Rank Datasets
- Open Source code
- Parallel C++/MPI implementation of Gradient Boosted Regression Trees for ranking, released September 2011
- C++ implementation of Gradient Boosted Regression Trees and Random Forests for ranking
- C++ and Python tools for using the SVM-Rank algorithm