Feature learning
| Machine learning and data mining |
|---|
 |
| Problems |
| Clustering |
| Dimensionality reduction |
| Structured prediction |
| Anomaly detection |
| Neural nets |
| Theory |
| Machine learning venues |
| Data mining venues |
|
|
In machine learning, feature learning or representation learning[1] is a set of techniques that learn a feature: a transformation of raw data input to a representation that can be effectively exploited in machine learning tasks. This obviates manual feature engineering, which is otherwise necessary, and allows a machine to both learn at a specific task (using the features) and learn the features themselves: to learn how to learn.
Feature learning is motivated by the fact that machine learning tasks such as classification often require input that is mathematically and computationally convenient to process. However, real-world data such as images, video, and sensor measurement is usually complex, redundant, and highly variable. Thus, it is necessary to discover useful features or representations from raw data. Traditional hand-crafted features often require expensive human labor and often rely on expert knowledge. Also, they normally do not generalize well. This motivates the design of efficient feature learning techniques, to automate and generalize this.
Feature learning can be divided into two categories: supervised and unsupervised feature learning, analogous to these categories in machine learning generally.
- In supervised feature learning, features are learned with labeled input data. Examples include neural networks, multilayer perceptron, and (supervised) dictionary learning.
- In unsupervised feature learning, features are learned with unlabeled input data. Examples include dictionary learning, independent component analysis, autoencoders, matrix factorization,[2] and various forms of clustering.[3][4][5]
Supervised feature learning
Supervised feature learning is to learn features from labeled data. Several approaches are introduced in the following.
Supervised dictionary learning
Dictionary learning is to learn a set (dictionary) of representative elements from the input data such that each data point can be represented as a weighted sum of the representative elements. The dictionary elements and the weights may be found by minimizing the average representation error (over the input data), together with L1 regularization on the weights to enable sparsity (i.e., the representation of each data point has only a few nonzero weights).
Supervised dictionary learning exploits both the structure underlying the input data and the labels for optimizing the dictionary elements. For example, a supervised dictionary learning technique was proposed by Mairal et al. in 2009.[6] The authors apply dictionary learning on classification problems by jointly optimizing the dictionary elements, weights for representing data points, and parameters of the classifier based on the input data. In particular, a minimization problem is formulated, where the objective function consists of the classification error, the representation error, an L1 regularization on the representing weights for each data point (to enable sparse representation of data), and an L2 regularization on the parameters of the classifier.
Neural networks
Neural networks are used to illustrate a family of learning algorithms via a "network" consisting of multiple layers of inter-connected nodes. It is inspired by the nervous system, where the nodes are viewed as neurons and edges are viewed as synapse. Each edge has an associated weight, and the network defines computational rules that passes input data from the input layer to the output layer. A network function associated with a neural network characterizes the relationship between input and output layers, which is parameterized by the weights. With appropriately defined network functions, various learning tasks can be performed by minimizing a cost function over the network function (weights).
Multilayer neural networks can be used to perform feature learning, since they learn a representation of their input at the hidden layer(s) which is subsequently used for classification or regression at the output layer.
Unsupervised feature learning
Unsupervised feature learning is to learn features from unlabeled data. The goal of unsupervised feature learning is often to discover low-dimensional features that captures some structure underlying the high-dimensional input data. When the feature learning is performed in an unsupervised way, it enables a form of semisupervised learning where first, features are learned from an unlabeled dataset, which are then employed to improve performance in a supervised setting with labeled data.[7][8] Several approaches are introduced in the following.
K-means clustering
K-means clustering is an approach for vector quantization. In particular, given a set of n vectors, k-means clustering groups them into k clusters (i.e., subsets) in such a way that each vector belongs to the cluster with the closest mean. The problem is computationally NP-hard, and suboptimal greedy algorithms have been developed for k-means clustering.
In feature learning, k-means clustering can be used to group an unlabeled set of inputs into k clusters, and then use the centroids of these clusters to produce features. These features can be produced in several ways. The simplest way is to add k binary features to each sample, where each feature j has value one iff the jth centroid learned by k-means is the closest to the sample under consideration.[3] It is also possible to use the distances to the clusters as features, perhaps after transforming them through a radial basis function (a technique that has used to train RBF networks[9]). Coates and Ng note that certain variants of k-means behave similarly to sparse coding algorithms.[10]
In a comparative evaluation of unsupervised feature learning methods, Coates, Lee and Ng found that k-means clustering with an appropriate transformation outperforms the more recently invented auto-encoders and RBMs on an image classification task.[3] K-means has also been shown to improve performance in the domain of NLP, specifically for named-entity recognition;[11] there, it competes with Brown clustering, as well as with distributed word representations (also known as neural word embeddings).[8]
Principal component analysis
Principal component analysis (PCA) is often used for dimension reduction. Given an unlabeled set of n input data vectors, PCA generates p (which is much smaller than the dimension of the input data) right singular vectors corresponding to the p largest singular values of the data matrix, where the kth row of the data matrix is the kth input data vector shifted by the sample mean of the input (i.e., subtracting the sample mean from the data vector). Equivalently, these singular vectors are the eigenvectors corresponding to the p largest eigenvalues of the sample covariance matrix of the input vectors. These p singular vectors are the feature vectors learned from the input data, and they represent directions along which the data has the largest variations.
PCA is a linear feature learning approach since the p singular vectors are linear functions of the data matrix. The singular vectors can be generated via a simple algorithm with p iterations. In the ith iteration, the projection of the data matrix on the (i-1)th eigenvector is subtracted, and the ith singular vector is found as the right singular vector corresponding to the largest singular of the residual data matrix.
PCA has several limitations. First, it assumes that the directions with large variance are of most interest, which may not be the case in many applications. PCA only relies on orthogonal transformations of the original data, and it only exploits the first- and second-order moments of the data, which may not well characterize the distribution of the data. Furthermore, PCA can effectively reduce dimension only when the input data vectors are correlated (which results in a few dominant eigenvalues).
Local linear embedding
Local linear embedding (LLE) is a nonlinear unsupervised learning approach for generating low-dimensional neighbor-preserving representations from (unlabeled) high-dimension input. The approach was proposed by Sam T. Roweis and Lawrence K. Saul in 2000.[12][13]
The general idea of LLE is to reconstruct the original high-dimensional data using lower-dimensional points while maintaining some geometric properties of the neighborhoods in the original data set. LLE consists of two major steps. The first step is for "neighbor-preserving," where each input data point Xi is reconstructed as a weighted sum of K nearest neighboring data points, and the optimal weights are found by minimizing the average squared reconstruction error (i.e., difference between a point and its reconstruction) under the constraint that the weights associated to each point sum up to one. The second step is for "dimension reduction," by looking for vectors in a lower-dimensional space that minimizes the representation error using the optimized weights in the first step. Note that in the first step, the weights are optimized with data being fixed, which can be solved as a least squares problem; while in the second step, lower-dimensional points are optimized with the weights being fixed, which can be solved via sparse eigenvalue decomposition.
The reconstruction weights obtained in the first step captures the "intrinsic geometric properties" of a neighborhood in the input data.[13] It is assumed that original data lie on a smooth lower-dimensional manifold, and the "intrinsic geometric properties" captured by the weights of the original data are expected also on the manifold. This is why the same weights are used in the second step of LLE. Compared with PCA, LLE is more powerful in exploiting the underlying structure of data.
Independent component analysis
Independent component analysis (ICA) is technique for learning a representation of data using a weighted sum of independent non-Gaussian components.[14] The assumption of non-Gaussian is imposed since the weights cannot be uniquely determined when all the components follow Gaussian distribution.
Unsupervised dictionary learning
Different from supervised dictionary learning, unsupervised dictionary learning does not utilize the labels of the data and only exploits the structure underlying the data for optimizing the dictionary elements. An example of unsupervised dictionary learning is sparse coding, which aims to learn basis functions (dictionary elements) for data representation from unlabeled input data. Sparse coding can be applied to learn overcomplete dictionary, where the number of dictionary elements is larger than the dimension of the input data.[15] Aharon et al. proposed an algorithm known as K-SVD for learning from unlabeled input data a dictionary of elements that enables sparse representation of the data.[16]
Multilayer/Deep architectures
The hierarchical architecture of the neural system inspires deep learning architectures for feature learning by stacking multiple layers of simple learning blocks.[17] These architectures are often designed based on the assumption of distributed representation: observed data is generated by the interactions of many different factors on multiple levels. In a deep learning architecture, the output of each intermediate layer can be viewed as a representation of the original input data. Each level uses the representation produced by previous level as input, and produces new representations as output, which is then fed to higher levels. The input of bottom layer is the raw data, and the output of the final layer is the final low-dimensional feature or representation.
Restricted Boltzmann machine
Restricted Boltzmann machines (RBMs) are often used as a building block for multilayer learning architectures.[3][18] An RBM can be represented by an undirected bipartite graph consisting of a group of binary hidden variables, a group of visible variables, and edges connecting the hidden and visible nodes. It is a special case of the more general Boltzmann machines with the constraint of no intra-node connections. Each edge in an RBM is associated with a weight. The weights together with the connections define an energy function, based on which a joint distribution of visible and hidden nodes can be devised. Based on the topology of the RBM, the hidden (visible) variables are independent conditioned on the visible (hidden) variables. Such conditional independence facilitates computations on RBM.
An RBM can be viewed as a single layer architecture for unsupervised feature learning. In particular, the visible variables correspond to input data, and the hidden variables correspond to feature detectors. The weights can be trained by maximizing the probability of visible variables using the contrastive divergence (CD) algorithm by Geoffrey Hinton.[18]
In general, the training of RBM by solving the above maximization problem tends to result in non-sparse representations. The sparse RBM,
[19] a modification of the RBM, was proposed to enable sparse representations. The idea is to add a regularization term in the objective function of data likelihood, which penalizes the deviation of the expected hidden variables from a small constant 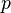 .
.
Autoencoder
An autoencoder consisting of encoder and decoder is a paradigm for deep learning architectures. An example is provided by Hinton and Salakhutdinov[18] where the encoder uses raw data (e.g., image) as input and produces feature or representation as output, and the decoder uses the extracted feature from the encoder as input and reconstructs the original input raw data as output. The encoder and decoder are constructed by stacking multiple layers of RBMs. The parameters involved in the architecture were originally trained in a greedy layer-by-layer manner: after one layer of feature detectors is learned, they are fed to upper layers as visible variables for training the corresponding RBM. Current approaches typically apply end-to-end training with stochastic gradient descent methods. Training can be repeated until some stopping criteria is satisfied.
See also
- Basis function
- Deep learning
- Feature detection (computer vision)
- Feature extraction
- Kernel trick
- Vector quantization
References
- ↑ Y. Bengio; A. Courville; P. Vincent (2013). "Representation Learning: A Review and New Perspectives". IEEE Trans. PAMI, special issue Learning Deep Architectures 35: 1798–1828. doi:10.1109/tpami.2013.50.
- ↑ Nathan Srebro; Jason D. M. Rennie; Tommi S. Jaakkola (2004). Maximum-Margin Matrix Factorization. NIPS.
- 1 2 3 4 Coates, Adam; Lee, Honglak; Ng, Andrew Y. (2011). An analysis of single-layer networks in unsupervised feature learning (PDF). Int'l Conf. on AI and Statistics (AISTATS).
- ↑ Csurka, Gabriella; Dance, Christopher C.; Fan, Lixin; Willamowski, Jutta; Bray, Cédric (2004). Visual categorization with bags of keypoints (PDF). ECCV Workshop on Statistical Learning in Computer Vision.
- ↑ Daniel Jurafsky; James H. Martin (2009). Speech and Language Processing. Pearson Education International. pp. 145–146.
- ↑ Mairal, Julien; Bach, Francis; Ponce, Jean; Sapiro, Guillermo; Zisserman, Andrew (2009). "Supervised Dictionary Learning". Advances in neural information processing systems.
- ↑ Percy Liang (2005). Semi-Supervised Learning for Natural Language (PDF) (M. Eng.). MIT. pp. 44–52.
- 1 2 Joseph Turian; Lev Ratinov; Yoshua Bengio (2010). Word representations: a simple and general method for semi-supervised learning (PDF). Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics.
- ↑ Schwenker, Friedhelm; Kestler, Hans A.; Palm, Günther (2001). "Three learning phases for radial-basis-function networks". Neural Networks 14: 439–458. doi:10.1016/s0893-6080(01)00027-2. CiteSeerX: 10
.1 ..1 .109 .312 - ↑ Coates, Adam; Ng, Andrew Y. (2012). "Learning feature representations with k-means". In G. Montavon, G. B. Orr and K.-R. Müller. Neural Networks: Tricks of the Trade. Springer.
- ↑ Dekang Lin; Xiaoyun Wu (2009). Phrase clustering for discriminative learning (PDF). Proc. J. Conf. of the ACL and 4th Int'l J. Conf. on Natural Language Processing of the AFNLP. pp. 1030–1038.
- ↑ Roweis, Sam T; Saul, Lawrence K (2000). "Nonlinear Dimensionality Reduction by Locally Linear Embedding". Science, New Series 290 (5500): 2323–2326. doi:10.1126/science.290.5500.2323. JSTOR 3081722. PMID 11125150.
- 1 2 Saul, Lawrence K; Roweis, Sam T (2000). "An Introduction to Locally Linear Embedding".
- ↑ Hyvärinen, Aapo; Oja, Erkki (2000). "Independent Component Analysis: Algorithms and Applications". Neural Networks 13 (4): 411–430. doi:10.1016/s0893-6080(00)00026-5. PMID 10946390.
- ↑ Lee, Honglak; Battle, Alexis; Raina, Rajat; Ng, Andrew Y (2007). "Efficient sparse coding algorithms". Advances in neural information processing systems.
- ↑ Aharon, Michal; Elad, Michael; Bruckstein, Alfred (2006). "K-SVD: An Algorithm for Designing Overcomplete Dictionaries for Sparse Representation". IEEE Trans. Signal Process. 54 (11): 4311–4322. doi:10.1109/TSP.2006.881199.
- ↑ Bengio, Yoshua (2009). "Learning Deep Architectures for AI". Foundations and Trends in Machine Learning 2 (1): 1–127. doi:10.1561/2200000006.
- 1 2 3 Hinton, G. E.; Salakhutdinov, R. R. (2006). "Reducing the Dimensionality of Data with Neural Networks" (PDF). Science 313 (5786): 504–507. doi:10.1126/science.1127647. PMID 16873662.
- ↑ Lee, Honglak; Ekanadham, Chaitanya; Andrew, Ng (2008). "Sparse deep belief net model for visual area V2". Advances in neural information processing systems.