Latent semantic analysis
| Semantics | ||||||||
|---|---|---|---|---|---|---|---|---|
| Computing | ||||||||
|
||||||||
Latent semantic analysis (LSA) is a technique in natural language processing, in particular distributional semantics, of analyzing relationships between a set of documents and the terms they contain by producing a set of concepts related to the documents and terms. LSA assumes that words that are close in meaning will occur in similar pieces of text. A matrix containing word counts per paragraph (rows represent unique words and columns represent each paragraph) is constructed from a large piece of text and a mathematical technique called singular value decomposition (SVD) is used to reduce the number of rows while preserving the similarity structure among columns. Words are then compared by taking the cosine of the angle between the two vectors (or the dot product between the normalizations of the two vectors) formed by any two rows. Values close to 1 represent very similar words while values close to 0 represent very dissimilar words.[1]
An information retrieval technique using latent semantic structure was patented in 1988 (US Patent 4,839,853, now expired) by Scott Deerwester, Susan Dumais, George Furnas, Richard Harshman, Thomas Landauer, Karen Lochbaum and Lynn Streeter. In the context of its application to information retrieval, it is sometimes called Latent Semantic Indexing (LSI).[2]
Overview
Occurrence matrix
LSA can use a term-document matrix which describes the occurrences of terms in documents; it is a sparse matrix whose rows correspond to terms and whose columns correspond to documents. A typical example of the weighting of the elements of the matrix is tf-idf (term frequency–inverse document frequency): the weight of an element of the matrix is proportional to the number of times the terms appear in each document, where rare terms are upweighted to reflect their relative importance.
This matrix is also common to standard semantic models, though it is not necessarily explicitly expressed as a matrix, since the mathematical properties of matrices are not always used.
Rank lowering
After the construction of the occurrence matrix, LSA finds a low-rank approximation[3] to the term-document matrix. There could be various reasons for these approximations:
- The original term-document matrix is presumed too large for the computing resources; in this case, the approximated low rank matrix is interpreted as an approximation (a "least and necessary evil").
- The original term-document matrix is presumed noisy: for example, anecdotal instances of terms are to be eliminated. From this point of view, the approximated matrix is interpreted as a de-noisified matrix (a better matrix than the original).
- The original term-document matrix is presumed overly sparse relative to the "true" term-document matrix. That is, the original matrix lists only the words actually in each document, whereas we might be interested in all words related to each document—generally a much larger set due to synonymy.
The consequence of the rank lowering is that some dimensions are combined and depend on more than one term:
- {(car), (truck), (flower)} --> {(1.3452 * car + 0.2828 * truck), (flower)}
This mitigates the problem of identifying synonymy, as the rank lowering is expected to merge the dimensions associated with terms that have similar meanings. It also mitigates the problem with polysemy, since components of polysemous words that point in the "right" direction are added to the components of words that share a similar meaning. Conversely, components that point in other directions tend to either simply cancel out, or, at worst, to be smaller than components in the directions corresponding to the intended sense.
Derivation
Let 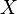 be a matrix where element
be a matrix where element  describes the occurrence of term
describes the occurrence of term  in document
in document 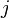 (this can be, for example, the frequency). will look like this:
(this can be, for example, the frequency). will look like this:

Now a row in this matrix will be a vector corresponding to a term, giving its relation to each document:

Likewise, a column in this matrix will be a vector corresponding to a document, giving its relation to each term:

Now the dot product  between two term vectors gives the correlation between the terms over the documents. The matrix product
between two term vectors gives the correlation between the terms over the documents. The matrix product 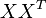 contains all these dot products. Element
contains all these dot products. Element  (which is equal to element
(which is equal to element 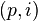 ) contains the dot product (
) contains the dot product ( ). Likewise, the matrix
). Likewise, the matrix  contains the dot products between all the document vectors, giving their correlation over the terms:
contains the dot products between all the document vectors, giving their correlation over the terms:  .
.
Now, from the theory of linear algebra, there exists a decomposition of such that 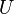 and
and 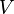 are orthogonal matrices and
are orthogonal matrices and 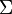 is a diagonal matrix. This is called a singular value decomposition (SVD):
is a diagonal matrix. This is called a singular value decomposition (SVD):

The matrix products giving us the term and document correlations then become

Since  and
and 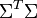 are diagonal we see that must contain the eigenvectors of , while must be the eigenvectors of . Both products have the same non-zero eigenvalues, given by the non-zero entries of , or equally, by the non-zero entries of . Now the decomposition looks like this:
are diagonal we see that must contain the eigenvectors of , while must be the eigenvectors of . Both products have the same non-zero eigenvalues, given by the non-zero entries of , or equally, by the non-zero entries of . Now the decomposition looks like this:

The values  are called the singular values, and
are called the singular values, and 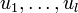 and
and  the left and right singular vectors.
Notice the only part of that contributes to
the left and right singular vectors.
Notice the only part of that contributes to  is the
is the 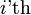 row.
Let this row vector be called
row.
Let this row vector be called  .
Likewise, the only part of
.
Likewise, the only part of 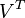 that contributes to
that contributes to 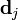 is the
is the  column,
column,  .
These are not the eigenvectors, but depend on all the eigenvectors.
.
These are not the eigenvectors, but depend on all the eigenvectors.
It turns out that when you select the  largest singular values, and their corresponding singular vectors from and , you get the rank approximation to with the smallest error (Frobenius norm). This approximation has a minimal error. But more importantly we can now treat the term and document vectors as a "semantic space". The vector
largest singular values, and their corresponding singular vectors from and , you get the rank approximation to with the smallest error (Frobenius norm). This approximation has a minimal error. But more importantly we can now treat the term and document vectors as a "semantic space". The vector  then has entries mapping it to a lower-dimensional space dimensions. These new dimensions do not relate to any comprehensible concepts. They are a lower-dimensional approximation of the higher-dimensional space. Likewise, the vector
then has entries mapping it to a lower-dimensional space dimensions. These new dimensions do not relate to any comprehensible concepts. They are a lower-dimensional approximation of the higher-dimensional space. Likewise, the vector 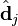 is an approximation in this lower-dimensional space. We write this approximation as
is an approximation in this lower-dimensional space. We write this approximation as

You can now do the following:
- See how related documents and
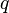 are in the low-dimensional space by comparing the vectors
are in the low-dimensional space by comparing the vectors 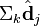 and
and  (typically by cosine similarity).
(typically by cosine similarity). - Comparing terms and
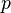 by comparing the vectors
by comparing the vectors  and
and 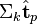 .
. - Documents and term vector representations can be clustered using traditional clustering algorithms like k-means using similarity measures like cosine.
- Given a query, view this as a mini document, and compare it to your documents in the low-dimensional space.
To do the latter, you must first translate your query into the low-dimensional space. It is then intuitive that you must use the same transformation that you use on your documents:
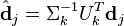
Note here that the inverse of the diagonal matrix 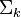 may be found by inverting each nonzero value within the matrix.
may be found by inverting each nonzero value within the matrix.
This means that if you have a query vector , you must do the translation  before you compare it with the document vectors in the low-dimensional space. You can do the same for pseudo term vectors:
before you compare it with the document vectors in the low-dimensional space. You can do the same for pseudo term vectors:



Applications
The new low-dimensional space typically can be used to:
- Compare the documents in the low-dimensional space (data clustering, document classification).
- Find similar documents across languages, after analyzing a base set of translated documents (cross language retrieval).
- Find relations between terms (synonymy and polysemy).
- Given a query of terms, translate it into the low-dimensional space, and find matching documents (information retrieval).
- Find the best similarity between small groups of terms, in a semantic way (i.e. in a context of a knowledge corpus), as for example in multi choice questions MCQ answering model.[4]
Synonymy and polysemy are fundamental problems in natural language processing:
- Synonymy is the phenomenon where different words describe the same idea. Thus, a query in a search engine may fail to retrieve a relevant document that does not contain the words which appeared in the query. For example, a search for "doctors" may not return a document containing the word "physicians", even though the words have the same meaning.
- Polysemy is the phenomenon where the same word has multiple meanings. So a search may retrieve irrelevant documents containing the desired words in the wrong meaning. For example, a botanist and a computer scientist looking for the word "tree" probably desire different sets of documents.
Commercial applications
LSA has been used to assist in performing prior art searches for patents.[5]
Applications in human memory
The use of Latent Semantic Analysis has been prevalent in the study of human memory, especially in areas of free recall and memory search. There is a positive correlation between the semantic similarity of two words (as measured by LSA) and the probability that the words would be recalled one after another in free recall tasks using study lists of random common nouns. They also noted that in these situations, the inter-response time between the similar words was much quicker than between dissimilar words. These findings are referred to as the Semantic Proximity Effect.[6]
When participants made mistakes in recalling studied items, these mistakes tended to be items that were more semantically related to the desired item and found in a previously studied list. These prior-list intrusions, as they have come to be called, seem to compete with items on the current list for recall.[7]
Another model, termed Word Association Spaces (WAS) is also used in memory studies by collecting free association data from a series of experiments and which includes measures of word relatedness for over 72,000 distinct word pairs.[8]
Implementation
The SVD is typically computed using large matrix methods (for example, Lanczos methods) but may also be computed incrementally and with greatly reduced resources via a neural network-like approach, which does not require the large, full-rank matrix to be held in memory.[9] A fast, incremental, low-memory, large-matrix SVD algorithm has recently been developed.[10] MATLAB and Python implementations of these fast algorithms are available. Unlike Gorrell and Webb's (2005) stochastic approximation, Brand's algorithm (2003) provides an exact solution. In recent years progress has been made to reduce the computational complexity of SVD; for instance, by using a parallel ARPACK algorithm to perform parallel eigenvalue decomposition it is possible to speed up the SVD computation cost while providing comparable prediction quality.[11]
Limitations
Some of LSA's drawbacks include:
- The resulting dimensions might be difficult to interpret. For instance, in
- {(car), (truck), (flower)} ↦ {(1.3452 * car + 0.2828 * truck), (flower)}
- the (1.3452 * car + 0.2828 * truck) component could be interpreted as "vehicle". However, it is very likely that cases close to
- {(car), (bottle), (flower)} ↦ {(1.3452 * car + 0.2828 * bottle), (flower)}
- will occur. This leads to results which can be justified on the mathematical level, but have no interpretable meaning in natural language.
- LSA cannot capture polysemy (i.e., multiple meanings of a word). Each occurrence of a word is treated as having the same meaning due to the word being represented as a single point in space. For example, the occurrence of "chair" in a document containing "The Chair of the Board" and in a separate document containing "the chair maker" are considered the same. The behavior results in the vector representation being an average of all the word's different meanings in the corpus, which can make it difficult for comparison. However, the effect is often lessened due to words having a predominant sense throughout a corpus (i.e. not all meanings are equally likely).
- Limitations of bag of words model (BOW), where a text is represented as an unordered collection of words. To address some of the limitation of bag of words model (BOW), multi-gram dictionary can be used to find direct and indirect association as well as higher-order co-occurrences among terms.[12]
- The probabilistic model of LSA does not match observed data: LSA assumes that words and documents form a joint Gaussian model (ergodic hypothesis), while a Poisson distribution has been observed. Thus, a newer alternative is probabilistic latent semantic analysis, based on a multinomial model, which is reported to give better results than standard LSA.[13]
See also
- Compound term processing
- Explicit semantic analysis
- Latent semantic mapping
- Latent Semantic Structure Indexing
- Principal components analysis
- Probabilistic latent semantic analysis
- Spamdexing
- Topic model
- Distributional semantics
- Coh-Metrix
References
- ↑ Susan T. Dumais (2005). "Latent Semantic Analysis". Annual Review of Information Science and Technology 38: 188. doi:10.1002/aris.1440380105.
- ↑ "The Latent Semantic Indexing home page".
- ↑ Markovsky I. (2012) Low-Rank Approximation: Algorithms, Implementation, Applications, Springer, 2012, ISBN 978-1-4471-2226-5
- ↑ Alain Lifchitz, Sandra Jhean-Larose, Guy Denhière (2009). "Effect of tuned parameters on an LSA multiple choice questions answering model" (PDF). Behavior Research Methods 41 (4): 1201–1209. doi:10.3758/BRM.41.4.1201. PMID 19897829.
- ↑ Gerry J. Elman (October 2007). "Automated Patent Examination Support - A proposal". Biotechnology Law Report 26 (5): 435. doi:10.1089/blr.2007.9896
- ↑ Marc W. Howard and Michael J. Kahana (1999). "Contextual Variability and Serial Position Effects in Free Recall" (PDF).
- ↑ Franklin M. Zaromb; et al. (2006). "Temporal Associations and Prior-List Intrusions in Free Recall" (PDF).
- ↑ Nelson, Douglas. "The University of South Florida Word Association, Rhyme and Word Fragment Norms". Retrieved May 8, 2011.
- ↑ Geneviève Gorrell and Brandyn Webb (2005). "Generalized Hebbian Algorithm for Latent Semantic Analysis" (PDF). Interspeech'2005.
- ↑ Matthew Brand (2006). "Fast Low-Rank Modifications of the Thin Singular Value Decomposition" (PDF). Linear Algebra and Its Applications 415: 20–30. doi:10.1016/j.laa.2005.07.021.
- ↑ doi: 10.1109/ICCSNT.2011.6182070
- ↑ J Transl Med. 2014 Nov 27;12(1):324.
- ↑ Thomas Hofmann (1999). "Probabilistic Latent Semantic Analysis" (PDF). Uncertainty in Artificial Intelligence.
- Thomas Landauer, Peter W. Foltz, & Darrell Laham (1998). "Introduction to Latent Semantic Analysis" (PDF). Discourse Processes 25 (2–3): 259–284. doi:10.1080/01638539809545028.
- Scott Deerwester, Susan T. Dumais, George W. Furnas, Thomas K. Landauer, Richard Harshman (1990). "Indexing by Latent Semantic Analysis" (PDF). Journal of the American Society for Information Science 41 (6): 391–407. doi:10.1002/(SICI)1097-4571(199009)41:6<391::AID-ASI1>3.0.CO;2-9. Original article where the model was first exposed.
- Michael Berry, Susan T. Dumais, Gavin W. O'Brien (1995). "Using Linear Algebra for Intelligent Information Retrieval". (PDF). Illustration of the application of LSA to document retrieval.
- "Latent Semantic Analysis". InfoVis.
- Fridolin Wild (November 23, 2005). "An Open Source LSA Package for R". CRAN. Retrieved 2006-11-20.
- Thomas Landauer, Susan T. Dumais. "A Solution to Plato's Problem: The Latent Semantic Analysis Theory of Acquisition, Induction, and Representation of Knowledge". Retrieved 2007-07-02.
External links
Articles on LSA
- Latent Semantic Analysis, a scholarpedia article on LSA written by Tom Landauer, one of the creators of LSA.
Talks and demonstrations
- LSA Overview, talk by Prof. Thomas Hofmann describing LSA, its applications in Information Retrieval, and its connections to probabilistic latent semantic analysis.
- Complete LSA sample code in C# for Windows. The demo code includes enumeration of text files, filtering stop words, stemming, making a document-term matrix and SVD.
Implementations
Due to its cross-domain applications in Information Retrieval, Natural Language Processing (NLP), Cognitive Science and Computational Linguistics, LSA has been implemented to support many different kinds of applications.
- Sense Clusters, an Information Retrieval-oriented perl implementation of LSA
- S-Space Package, a Computational Linguistics and Cognitive Science-oriented Java implementation of LSA
- Semantic Vectors applies Random Projection, LSA, and Reflective Random Indexing to Lucene term-document matrices
- Infomap Project, an NLP-oriented C implementation of LSA (superseded by semanticvectors project)
- Text to Matrix Generator, A MATLAB Toolbox for generating term-document matrices from text collections, with support for LSA
- Gensim contains a Python implementation of LSA for matrices larger than RAM.