Low-density parity-check code
In information theory, a low-density parity-check (LDPC) code is a linear error correcting code, a method of transmitting a message over a noisy transmission channel.[1][2] An LDPC is constructed using a sparse bipartite graph.[3] LDPC codes are capacity-approaching codes, which means that practical constructions exist that allow the noise threshold to be set very close (or even arbitrarily close on the BEC) to the theoretical maximum (the Shannon limit) for a symmetric memoryless channel. The noise threshold defines an upper bound for the channel noise, up to which the probability of lost information can be made as small as desired. Using iterative belief propagation techniques, LDPC codes can be decoded in time linear to their block length.
LDPC codes are finding increasing use in applications requiring reliable and highly efficient information transfer over bandwidth or return channel-constrained links in the presence of corrupting noise. Implementation of LDPC codes has lagged behind that of other codes, notably turbo codes. The fundamental patent for Turbo Codes expired on August 29, 2013.[US5446747][4]
LDPC codes are also known as Gallager codes, in honor of Robert G. Gallager, who developed the LDPC concept in his doctoral dissertation at the Massachusetts Institute of Technology in 1960.[5]
History
Impractical to implement when first developed by Gallager in 1963,[6] LDPC codes were forgotten until his work was rediscovered in 1996.[7] Turbo codes, another class of capacity-approaching codes discovered in 1993, became the coding scheme of choice in the late 1990s, used for applications such as the Deep Space Network and satellite communications. However, in the last few years, the advances in low-density parity-check codes have seen them surpass turbo codes in terms of error floor and performance in the higher code rate range, leaving turbo codes better suited for the lower code rates only.[8]
Applications
In 2003, an irregular repeat accumulate (IRA) style LDPC code beat six turbo codes to become the error correcting code in the new DVB-S2 standard for the satellite transmission of digital television. [9] The DVB-S2 selection committee made decoder complexity estimates for the Turbo Code proposals using a much less efficient serial decoder architecture rather than a parallel decoder architecture.
This forced the Turbo Code proposals to use frame sizes on the order of one half the frame size of the LDPC proposals. In 2008, LDPC beat convolutional turbo codes as the forward error correction (FEC) system for the ITU-T G.hn standard.[10] G.hn chose LDPC codes over turbo codes because of their lower decoding complexity (especially when operating at data rates close to 1.0 Gbit/s) and because the proposed turbo codes exhibited a significant error floor at the desired range of operation.[11]
LDPC codes are also used for 10GBase-T Ethernet, which sends data at 10 gigabits per second over twisted-pair cables. As of 2009, LDPC codes are also part of the Wi-Fi 802.11 standard as an optional part of 802.11n and 802.11ac, in the High Throughput (HT) PHY specification.[12]
Some OFDM systems add an additional outer error correction that fixes the occasional errors (the "error floor") that get past the LDPC correction inner code even at low bit error rates. For example: The Reed-Solomon code with LDPC Coded Modulation (RS-LCM) uses a Reed-Solomon outer code.[13] The DVB-S2, the DVB-T2 and the DVB-C2 standards all use a BCH code outer code to mop up residual errors after LDPC decoding.[14]
Operational use
LDPC codes functionally are defined by a sparse parity-check matrix. This sparse matrix is often randomly generated, subject to the sparsity constraints—LDPC code construction is discussed later. These codes were first designed by Robert Gallager in 1962.
Below is a graph fragment of an example LDPC code using Forney's factor graph notation. In this graph, n variable nodes in the top of the graph are connected to (n−k) constraint nodes in the bottom of the graph.
This is a popular way of graphically representing an (n, k) LDPC code. The bits of a valid message, when placed on the T's at the top of the graph, satisfy the graphical constraints. Specifically, all lines connecting to a variable node (box with an '=' sign) have the same value, and all values connecting to a factor node (box with a '+' sign) must sum, modulo two, to zero (in other words, they must sum to an even number; or there must be an even number of odd values).

Ignoring any lines going out of the picture, there are eight possible six-bit strings corresponding to valid codewords: (i.e., 000000, 011001, 110010, 101011, 111100, 100101, 001110, 010111). This LDPC code fragment represents a three-bit message encoded as six bits. Redundancy is used, here, to increase the chance of recovering from channel errors. This is a (6, 3) linear code, with n = 6 and k = 3.
Once again ignoring lines going out of the picture, the parity-check matrix representing this graph fragment is
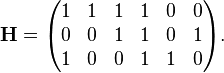
In this matrix, each row represents one of the three parity-check constraints, while each column represents one of the six bits in the received codeword.
In this example, the eight codewords can be obtained by putting the parity-check matrix H into this form 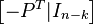 through basic row operations in GF(2):
through basic row operations in GF(2):
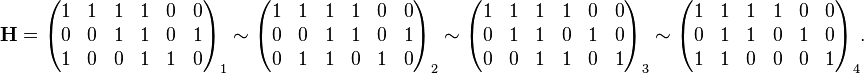
Step 1: H.
Step 2: Row 1 is added to row 3.
Step 3: Row 2 and 3 are swapped.
Step 4: Row 1 is added to row 3.
From this, the generator matrix G can be obtained as 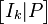 (noting that in the special case of this being a binary code
(noting that in the special case of this being a binary code 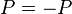 ), or specifically:
), or specifically:
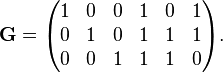
Finally, by multiplying all eight possible 3-bit strings by G, all eight valid codewords are obtained. For example, the codeword for the bit-string '101' is obtained by:
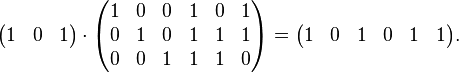
As a check, the row space of G is orthogonal to H such that 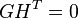
The the bit-string '101' is found in as the first 3 bits of the codeword '101011'.
Example Encoder
Figure 1 illustrates the functional components of most LDPC encoders.
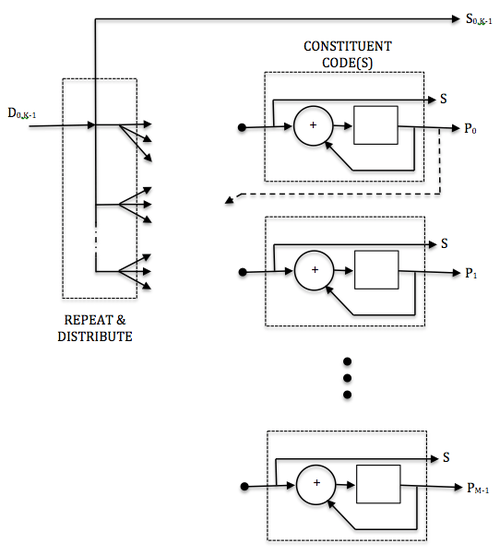
During the encoding of a frame, the input data bits (D) are repeated and distributed to a set of constituent encoders. The constituent encoders are typically accumulators and each accumulator is used to generate a parity symbol. A single copy of the original data (S0,K-1) is transmitted with the parity bits (P) to make up the code symbols. The S bits from each constituent encoder are discarded.
The parity bit may be used within another constituent code.
In an example using the DVB-S2 rate 2/3 code the encoded block size is 64800 symbols (N=64800) with 43200 data bits (K=43200) and 21600 parity bits (M=21600). Each constituent code (check node) encodes 16 data bits except for the first parity bit which encodes 8 data bits. The first 4680 data bits are repeated 13 times (used in 13 parity codes), while the remaining data bits are used in 3 parity codes (irregular LDPC code).
For comparison, classic turbo codes typically use two constituent codes configured in parallel, each of which encodes the entire input block (K) of data bits. These constituent encoders are recursive convolutional codes (RSC) of moderate depth (8 or 16 states) that are separated by a code interleaver which interleaves one copy of the frame.
The LDPC code, in contrast, uses many low depth constituent codes (accumulators) in parallel, each of which encode only a small portion of the input frame. The many constituent codes can be viewed as many low depth (2 state) 'convolutional codes' that are connected via the repeat and distribute operations. The repeat and distribute operations perform the function of the interleaver in the turbo code.
The ability to more precisely manage the connections of the various constituent codes and the level of redundancy for each input bit give more flexibility in the design of LDPC codes, which can lead to better performance than turbo codes in some instances. Turbo codes still seem to perform better than LDPCs at low code rates, or at least the design of well performing low rate codes is easier for Turbo Codes.
As a practical matter, the hardware that forms the accumulators is reused during the encoding process. That is, once a first set of parity bits are generated and the parity bits stored, the same accumulator hardware is used to generate a next set of parity bits.
Decoding
As with other codes, the maximum likelihood decoding of an LDPC code on the binary symmetric channel is an NP-complete problem. Performing optimal decoding for a NP-complete code of any useful size is not practical.
However, sub-optimal techniques based on iterative belief propagation decoding give excellent results and can be practically implemented. The sub-optimal decoding techniques view each parity check that makes up the LDPC as an independent single parity check (SPC) code. Each SPC code is decoded separately using soft-in-soft-out (SISO) techniques such as SOVA, BCJR, MAP, and other derivates thereof. The soft decision information from each SISO decoding is cross-checked and updated with other redundant SPC decodings of the same information bit. Each SPC code is then decoded again using the updated soft decision information. This process is iterated until a valid code word is achieved or decoding is exhausted. This type of decoding is often referred to as sum-product decoding.
The decoding of the SPC codes is often referred to as the "check node" processing, and the cross-checking of the variables is often referred to as the "variable-node" processing.
In a practical LDPC decoder implementation, sets of SPC codes are decoded in parallel to increase throughput.
In contrast, belief propagation on the binary erasure channel is particularly simple where it consists of iterative constraint satisfaction.
For example, consider that the valid codeword, 101011, from the example above, is transmitted across a binary erasure channel and received with the first and fourth bit erased to yield ?01?11. Since the transmitted message must have satisfied the code constraints, the message can be represented by writing the received message on the top of the factor graph.
In this example, the first bit cannot yet be recovered, because all of the constraints connected to it have more than one unknown bit. In order to proceed with decoding the message, constraints connecting to only one of the erased bits must be identified. In this example, only the second constraint suffices. Examining the second constraint, the fourth bit must have been zero, since only a zero in that position would satisfy the constraint.
This procedure is then iterated. The new value for the fourth bit can now be used in conjunction with the first constraint to recover the first bit as seen below. This means that the first bit must be a one to satisfy the leftmost constraint.

Thus, the message can be decoded iteratively. For other channel models, the messages passed between the variable nodes and check nodes are real numbers, which express probabilities and likelihoods of belief.
This result can be validated by multiplying the corrected codeword r by the parity-check matrix H:
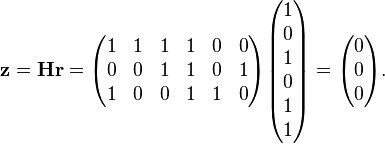
Because the outcome z (the syndrome) of this operation is the three × one zero vector, the resulting codeword r is successfully validated.
After the decoding is completed, the original message bits '101' can be extracted by looking at the first 3 bits of the codeword.
While illustrative, this erasure example does not show the use of soft-decision decoding or soft-decision message passing, which is used in virtually all commercial LDPC decoders.
Updating node information
In recent years, there has also been a great deal of work spent studying the effects of alternative schedules for variable-node and constraint-node update. The original technique that was used for decoding LDPC codes was known as flooding. This type of update required that, before updating a variable node, all constraint nodes needed to be updated and vice versa. In later work by Vila Casado et al.,[15] alternative update techniques were studied, in which variable nodes are updated with the newest available check-node information.
The intuition behind these algorithms is that variable nodes whose values vary the most are the ones that need to be updated first. Highly reliable nodes, whose log-likelihood ratio (LLR) magnitude is large and does not change significantly from one update to the next, do not require updates with the same frequency as other nodes, whose sign and magnitude fluctuate more widely. These scheduling algorithms show greater speed of convergence and lower error floors than those that use flooding. These lower error floors are achieved by the ability of the Informed Dynamic Scheduling (IDS)[15] algorithm to overcome trapping sets of near codewords.[16]
When nonflooding scheduling algorithms are used, an alternative definition of iteration is used. For an (n, k) LDPC code of rate k/n, a full iteration occurs when n variable and n − k constraint nodes have been updated, no matter the order in which they were updated.
Lookup table decoding
It is possible to decode LDPC codes on a relatively low-power microprocessor by the use of lookup tables.
While codes such as the LDPC are generally implemented on high-power processors, with long block lengths, there are also applications which use lower-power processors and short block lengths (1024).
Therefore, it is possible to precalculate the output bit based upon predetermined input bits. A table is generated which contains n entries (for a block length of 1024 bits, this would be 1024 bits long), and contains all possible entries for different input states (both errored and nonerrored).
As a bit is input, it is then added to a FIFO register, and the value of the FIFO register is then used to look up in the table the relevant output from the precalculated values.
By this method, very high iterations can be used, with little processor overhead, the only cost being that of the memory for the lookup table, such that LDPC decoding is possible even on a 4.0 MHz PIC chip.
Code construction
For large block sizes, LDPC codes are commonly constructed by first studying the behaviour of decoders. As the block size tends to infinity, LDPC decoders can be shown to have a noise threshold below which decoding is reliably achieved, and above which decoding is not achieved,[17] colloquially referred to as the cliff effect. This threshold can be optimised by finding the best proportion of arcs from check nodes and arcs from variable nodes. An approximate graphical approach to visualising this threshold is an EXIT chart.
The construction of a specific LDPC code after this optimization falls into two main types of techniques:
- Pseudorandom approaches
- Combinatorial approaches
Construction by a pseudo-random approach builds on theoretical results that, for large block size, a random construction gives good decoding performance.[7] In general, pseudorandom codes have complex encoders, but pseudorandom codes with the best decoders can have simple encoders.[18] Various constraints are often applied to help ensure that the desired properties expected at the theoretical limit of infinite block size occur at a finite block size.
Combinatorial approaches can be used to optimize the properties of small block-size LDPC codes or to create codes with simple encoders.
Some LDPC codes are based on Reed–Solomon codes, such as the RS-LDPC code used in the 10 Gigabit Ethernet standard.[19] Compared to randomly generated LDPC codes, structured LDPC codes—such as the LDPC code used in the DVB-S2 standard—can have simpler and therefore lower-cost hardware—in particular, codes constructed such that the H matrix is a circulant matrix.[20]
Yet another way of constructing LDPC codes is to use finite geometries. This method was proposed by Y. Kou et al. in 2001.[21]
See also
People
Theory
Applications
- G.hn/G.9960 (ITU-T Standard for networking over power lines, phone lines and coaxial cable)
- 802.3an (10 Giga-bit/s Ethernet over Twisted pair)
- CMMB(China Multimedia Mobile Broadcasting)
- DVB-S2 / DVB-T2 / DVB-C2 (Digital video broadcasting, 2nd Generation)
- DMB-T/H (Digital video broadcasting)[22]
- WiMAX (IEEE 802.16e standard for microwave communications)
- IEEE 802.11n-2009 (Wi-Fi standard)
- DOCSIS 3.1
Other capacity-approaching codes
- Turbo codes
- Serial concatenated convolutional codes
- Online codes
- Fountain codes
- LT codes
- Raptor codes
- Repeat-accumulate codes (a class of simple turbo codes)
- Tornado codes (LDPC codes designed for erasure decoding)
- Polar codes
References
- ↑ David J.C. MacKay (2003) Information theory, Inference and Learning Algorithms, CUP, ISBN 0-521-64298-1, (also available online)
- ↑ Todd K. Moon (2005) Error Correction Coding, Mathematical Methods and Algorithms. Wiley, ISBN 0-471-64800-0 (Includes code)
- ↑ Amin Shokrollahi (2003) LDPC Codes: An Introduction
- ↑ NewScientist, Communication speed nears terminal velocity, by Dana Mackenzie, 9 July 2005
- ↑ Larry Hardesty (January 21, 2010). "Explained: Gallager codes". MIT News. Retrieved August 7, 2013.
- ↑ Robert G. Gallager (1963). Low Density Parity Check Codes (PDF). Monograph, M.I.T. Press. Retrieved August 7, 2013.
- 1 2 David J.C. MacKay and Radford M. Neal, "Near Shannon Limit Performance of Low Density Parity Check Codes," Electronics Letters, July 1996
- ↑ Telemetry Data Decoding, Design Handbook
- ↑ Presentation by Hughes Systems
- ↑ HomePNA Blog: G.hn, a PHY For All Seasons
- ↑ IEEE Communications Magazine paper on G.hn
- ↑ IEEE Standard, section 20.3.11.6 "802.11n-2009", IEEE, October 29, 2009, accessed March 21, 2011.
- ↑ Chih-Yuan Yang, Mong-Kai Ku. http://123seminarsonly.com/Seminar-Reports/029/26540350-Ldpc-Coded-Ofdm-Modulation.pdf "LDPC coded OFDM modulation for high spectral efficiency transmission"
- ↑ Nick Wells. "DVB-T2 in relation to the DVB-x2 Family of Standards"
- 1 2 A.I. Vila Casado, M. Griot, and R.Wesel, “Informed dynamic scheduling for belief propagation decoding of LDPC codes,” Proc. IEEE Int. Conf. on Comm. (ICC), June 2007.
- ↑ T. Richardson, “Error floors of LDPC codes,” in Proc. 41st Allerton Conf. Comm., Control, and Comput., Monticello, IL, 2003.
- ↑ Thomas J. Richardson and M. Amin Shokrollahi and Rüdiger L. Urbanke, "Design of Capacity-Approaching Irregular Low-Density Parity-Check Codes," IEEE Transactions in Information Theory, 47(2), February 2001
- ↑ Thomas J. Richardson and Rüdiger L. Urbanke, "Efficient Encoding of Low-Density Parity-Check Codes," IEEE Transactions in Information Theory, 47(2), February 2001
- ↑ Ahmad Darabiha, Anthony Chan Carusone, Frank R. Kschischang. "Power Reduction Techniques for LDPC Decoders"
- ↑ Zhengya Zhang, Venkat Anantharam, Martin J. Wainwright, and Borivoje Nikolic. "An Efficient 10GBASE-T Ethernet LDPC Decoder Design With Low Error Floors".
- ↑ Y. Kou, S. Lin and M. Fossorier, "Low-Density Parity-Check Codes Based on Finite Geometries: A Rediscovery and New Results," IEEE Transactions on Information Theory, vol. 47, no. 7, November 2001, pp. 2711- 2736.
- ↑ http://spectrum.ieee.org/consumer-electronics/standards/does-china-have-the-best-digital-television-standard-on-the-planet/2
External links
- The on-line textbook: Information Theory, Inference, and Learning Algorithms, by David J.C. MacKay, discusses LDPC codes in Chapter 47.
- LDPC Codes: An Introduction
- LDPC codes and performance results
- Online density evolution for LDPC codes
- LDPC Codes – a brief Tutorial (by Bernhard Leiner, 2005)
- Iterative Error Correction: Turbo, Low-Density Parity-Check and Repeat-Accumulate Codes
- Source code for encoding, decoding, and simulating LDPC codes is available from a variety of locations:
- Binary LDPC codes in C
- Binary LDPC codes for Python (core algorithm in C)
- LDPC codes over GF(q) in MATLAB
- LDPC encoder and LDPC decoder in MATLAB
| ||||||||||||||||||||||||||||||||||