Kernel embedding of distributions
In machine learning, the kernel embedding of distributions (also called the kernel mean or mean map) comprises a class of nonparametric methods in which a probability distribution is represented as an element of a reproducing kernel Hilbert space (RKHS).[1] A generalization of the individual data-point feature mapping done in classical kernel methods, the embedding of distributions into infinite-dimensional feature spaces can preserve all of the statistical features of arbitrary distributions, while allowing one to compare and manipulate distributions using Hilbert space operations such as inner products, distances, projections, linear transformations, and spectral analysis.[2] This learning framework is very general and can be applied to distributions over any space  on which a sensible kernel function (measuring similarity between elements of ) may be defined. For example, various kernels have been proposed for learning from data which are: vectors in
on which a sensible kernel function (measuring similarity between elements of ) may be defined. For example, various kernels have been proposed for learning from data which are: vectors in  , discrete classes/categories, strings, graphs/networks, images, time series, manifolds, dynamical systems, and other structured objects.[3][4] The theory behind kernel embeddings of distributions has been primarily developed by Alex Smola, Le Song , Arthur Gretton, and Bernhard Schölkopf.
, discrete classes/categories, strings, graphs/networks, images, time series, manifolds, dynamical systems, and other structured objects.[3][4] The theory behind kernel embeddings of distributions has been primarily developed by Alex Smola, Le Song , Arthur Gretton, and Bernhard Schölkopf.
The analysis of distributions is fundamental in machine learning and statistics, and many algorithms in these fields rely on information theoretic approaches such as entropy, mutual information, or Kullback–Leibler divergence. However, to estimate these quantities, one must first either perform density estimation, or employ sophisticated space-partitioning/bias-correction strategies which are typically infeasible for high-dimensional data.[5] Commonly, methods for modeling complex distributions rely on parametric assumptions that may be unfounded or computationally challenging (e.g. Gaussian mixture models), while nonparametric methods like kernel density estimation (Note: the smoothing kernels in this context have a different interpretation than the kernels discussed here) or characteristic function representation (via the Fourier transform of the distribution) break down in high-dimensional settings.[2]
Methods based on the kernel embedding of distributions sidestep these problems and also possess the following advantages:[5]
- Data may be modeled without restrictive assumptions about the form of the distributions and relationships between variables
- Intermediate density estimation is not needed
- Practitioners may specify the properties of a distribution most relevant for their problem (incorporating prior knowledge via choice of the kernel)
- If a characteristic kernel is used, then the embedding can uniquely preserve all information about a distribution, while thanks to the kernel trick, computations on the potentially infinite-dimensional RKHS can be implemented in practice as simple Gram matrix operations
- Dimensionality-independent rates of convergence for the empirical kernel mean (estimated using samples from the distribution) to the kernel embedding of the true underlying distribution can be proven.
- Learning algorithms based on this framework exhibit good generalization ability and finite sample convergence, while often being simpler and more effective than information theoretic methods
Thus, learning via the kernel embedding of distributions offers a principled drop-in replacement for information theoretic approaches and is a framework which not only subsumes many popular methods in machine learning and statistics as special cases, but also can lead to entirely new learning algorithms.
Definitions
Let 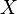 denote a random variable with codomain and distribution
denote a random variable with codomain and distribution  . Given a kernel
. Given a kernel  on
on 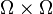 , the Moore-Aronszajn Theorem asserts the existence of a RKHS
, the Moore-Aronszajn Theorem asserts the existence of a RKHS  (a Hilbert space of functions
(a Hilbert space of functions 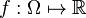 equipped with inner products
equipped with inner products 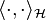 and norms
and norms 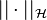 ) in which the element
) in which the element 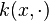 satisfies the reproducing property
satisfies the reproducing property 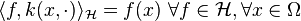 . One may alternatively consider an implicit feature mapping
. One may alternatively consider an implicit feature mapping  from to (which is therefore also called the feature space), so that
from to (which is therefore also called the feature space), so that 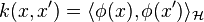 can be viewed as a measure of similarity between points
can be viewed as a measure of similarity between points 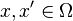 . While the similarity measure is linear in the feature space, it may be highly nonlinear in the original space depending on the choice of kernel.
. While the similarity measure is linear in the feature space, it may be highly nonlinear in the original space depending on the choice of kernel.
Kernel embedding
The kernel embedding of the distribution in (also called the kernel mean or mean map) is given by:[1]
![\mu_X := \mathbb{E}_X [k(X, \cdot) ] = \mathbb{E}_X [\phi(X) ] = \int_\Omega \phi(x) \ \mathrm{d}P(x)](../I/m/9c3a63b4068411d74bda9969a2c3e06c.png)
A kernel is characteristic if the mean embedding 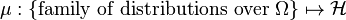 is injective.[6] Each distribution can thus be uniquely represented in the RKHS and all statistical features of distributions are preserved by the kernel embedding if a characteristic kernel is used.
is injective.[6] Each distribution can thus be uniquely represented in the RKHS and all statistical features of distributions are preserved by the kernel embedding if a characteristic kernel is used.
Empirical kernel embedding
Given  training examples
training examples 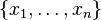 drawn independently and identically distributed (i.i.d.) from
drawn independently and identically distributed (i.i.d.) from  , the kernel embedding of can be empirically estimated as
, the kernel embedding of can be empirically estimated as
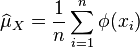
Joint distribution embedding
If 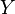 denotes another random variable (for simplicity, assume the domain of is also with the same kernel which satisfies
denotes another random variable (for simplicity, assume the domain of is also with the same kernel which satisfies 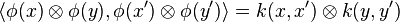 ), then the joint distribution
), then the joint distribution 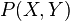 can be mapped into a tensor product feature space
can be mapped into a tensor product feature space 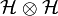 via [2]
via [2]
![\mathcal{C}_{XY} = \mathbb{E}_{XY} [\phi(X) \otimes \phi(Y)] = \int_{\Omega \times \Omega} \phi(x) \otimes \phi(y) \ \mathrm{d} P(x,y)](../I/m/799ed1705f7ccaadf28b32d4bdcaf166.png)
By the equivalence between a tensor and a linear map, this joint embedding may be interpreted as an uncentered cross-covariance operator 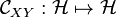 from which the cross-covariance of mean-zero functions
from which the cross-covariance of mean-zero functions 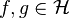 can be computed as [7]
can be computed as [7]
![\text{Cov}_{XY} (f(X), g(Y)) := \mathbb{E}_{XY} [f(X) g(Y)] = \langle f , \mathcal{C}_{XY} g \rangle_{\mathcal{H}} = \langle f \otimes g , \mathcal{C}_{XY} \rangle_{\mathcal{H} \otimes \mathcal{H}}](../I/m/6413b850453988193ef33a992598d43a.png)
Given pairs of training examples  drawn i.i.d. from , we can also empirically estimate the joint distribution kernel embedding via
drawn i.i.d. from , we can also empirically estimate the joint distribution kernel embedding via
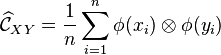
Conditional distribution embedding
Given a conditional distribution 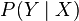 , one can define the corresponding RKHS embedding as [2]
, one can define the corresponding RKHS embedding as [2]
![\mu_{Y \mid x} = \mathbb{E}_{Y \mid x} [ \phi(Y) ] = \int_\Omega \phi(y) \ \mathrm{d}P(y \mid x)](../I/m/a9ab1396e542a724c0fc97e6b9bf7c98.png)
Note that the embedding of thus defines a family of points in the RKHS indexed by the values  taken by conditioning variable . By fixing to a particular value, we obtain a single element in , and thus it is natural to define the operator
taken by conditioning variable . By fixing to a particular value, we obtain a single element in , and thus it is natural to define the operator
-
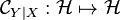 as
as 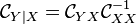
-
which given the feature mapping of outputs the conditional embedding of given 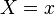 . Assuming that for all
. Assuming that for all ![g \in \mathcal{H}: \ \mathbb{E}_{Y \mid X} [g(Y)] \in \mathcal{H}](../I/m/5009cefee47204555f35cc23d1a4a94b.png) , it can be shown that [7]
, it can be shown that [7]
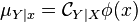
This assumption is always true for finite domains with characteristic kernels, but may not necessarily hold for continuous domains.[2] Nevertheless, even in cases where the assumption fails, 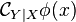 may still be used to approximate the conditional kernel embedding
may still be used to approximate the conditional kernel embedding 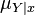 , and in practice, the inversion operator is replaced with a regularized version of itself
, and in practice, the inversion operator is replaced with a regularized version of itself 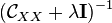 (where
(where  denotes the identity matrix).
denotes the identity matrix).
Given training examples , the empirical kernel conditional embedding operator may be estimated as [2]
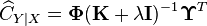
where 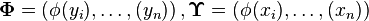 are implicitly formed feature matrices,
are implicitly formed feature matrices, 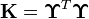 is the Gram matrix for samples of , and
is the Gram matrix for samples of , and  is a regularization parameter needed to avoid overfitting.
is a regularization parameter needed to avoid overfitting.
Thus, the empirical estimate of the kernel conditional embedding is given by a weighted sum of samples of in the feature space:
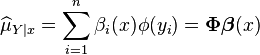 where
where 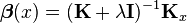 and
and 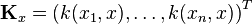
Properties
- The expectation of any function
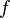 in the RKHS can be computed as an inner product with the kernel embedding:
in the RKHS can be computed as an inner product with the kernel embedding:
![\mathbb{E}_X [f(X)] = \langle f, \mu_X \rangle_\mathcal{H}](../I/m/c61589cd1aa65e184886702ea654f279.png)
- In the presence of large sample sizes, manipulations of the
 Gram matrix may be computationally demanding. Through use of a low-rank approximation of the Gram matrix (such as the incomplete Cholesky factorization), running time and memory requirements of kernel-embedding-based learning algorithms can be drastically reduced without suffering much loss in approximation accuracy.[2]
Gram matrix may be computationally demanding. Through use of a low-rank approximation of the Gram matrix (such as the incomplete Cholesky factorization), running time and memory requirements of kernel-embedding-based learning algorithms can be drastically reduced without suffering much loss in approximation accuracy.[2]
Convergence of empirical kernel mean to the true distribution embedding
- If is defined such that
![f \in [0, 1]](../I/m/163e77cbb453d30858045840b6cc429b.png) for all
for all 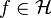 with
with 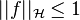 (as is the case for the widely used radial basis function kernels), then with probability at least
(as is the case for the widely used radial basis function kernels), then with probability at least 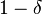 :[5]
:[5]
![||\mu_X - \widehat{\mu}_X ||_\mathcal{H} = \sup_{f \in \mathcal{B}(0,1)} \left| \mathbb{E}_X[f(X)] - \frac{1}{n} \sum_{i=1}^n f(x_i) \right| \le \frac{2}{n} \mathbb{E}_X \left[ \sqrt{\text{tr} K} \right] + \sqrt{\frac{\log (2/\delta)}{2n}}](../I/m/d91d669df4ab25b0cf7320cc7da774e1.png)
where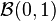 denotes the unit ball in and
denotes the unit ball in and 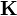 is the Gram matrix whose
is the Gram matrix whose  th entry is
th entry is 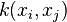 .
. - The rate of convergence (in RKHS norm) of the empirical kernel embedding to its distribution counterpart is
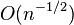 and does not depend on the dimension of .
and does not depend on the dimension of . - Statistics based on kernel embeddings thus avoid the curse of dimensionality, and though the true underlying distribution is unknown in practice, one can (with high probability) obtain an approximation within of the true kernel embedding based on a finite sample of size .
- For the embedding of conditional distributions, the empirical estimate can be seen as a weighted average of feature mappings (where the weights
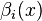 depend on the value of the conditioning variable and capture the effect of the conditioning on the kernel embedding). In this case, the empirical estimate converges to the conditional distribution RKHS embedding with rate
depend on the value of the conditioning variable and capture the effect of the conditioning on the kernel embedding). In this case, the empirical estimate converges to the conditional distribution RKHS embedding with rate 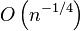 if the regularization parameter is decreased as
if the regularization parameter is decreased as 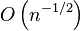 , though faster rates of convergence may be achieved by placing additional assumptions on the joint distribution.[2]
, though faster rates of convergence may be achieved by placing additional assumptions on the joint distribution.[2]
Universal kernels
- Letting
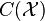 denote the space of continuous bounded functions on compact domain
denote the space of continuous bounded functions on compact domain  , we call a kernel universal if
, we call a kernel universal if 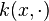 is continuous for all and the RKHS induced by is dense in .
is continuous for all and the RKHS induced by is dense in .
- If induces a strictly positive definite kernel matrix for any set of distinct points, then it is a universal kernel.[5] For example, the widely used Gaussian RBF kernel
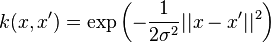
on compact subsets of is universal.
- If is universal, then it is characteristic, i.e. the kernel embedding is one-to-one.[8]
Parameter selection for conditional distribution kernel embeddings
- The empirical kernel conditional distribution embedding operator
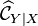 can alternatively be viewed as the solution of the following regularized least squares (function-valued) regression problem [9]
can alternatively be viewed as the solution of the following regularized least squares (function-valued) regression problem [9]
-
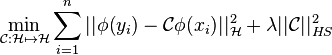 where
where 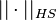 is the Hilbert-Schmidt norm.
is the Hilbert-Schmidt norm.
-
- One can thus select the regularization parameter by performing cross-validation based on the squared loss function of the regression problem.
Rules of probability as operations in the RKHS
This section illustrates how basic probabilistic rules may be reformulated as (multi)linear algebraic operations in the kernel embedding framework and is primarily based on the work of Song et al.[2][7] The following notation is adopted:
-
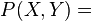 joint distribution over random variables
joint distribution over random variables 
-
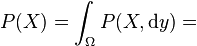 marginal distribution of ;
marginal distribution of ; 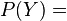 marginal distribution of
marginal distribution of -
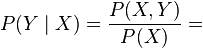 conditional distribution of given with corresponding conditional embedding operator
conditional distribution of given with corresponding conditional embedding operator 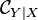
-
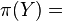 prior distribution over
prior distribution over -
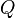 is used to distinguish distributions which incorporate the prior from distributions which do not rely on the prior
is used to distinguish distributions which incorporate the prior from distributions which do not rely on the prior
In practice, all embeddings are empirically estimated from data and it assumed that a set of samples 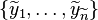 may be used to estimate the kernel embedding of the prior distribution
may be used to estimate the kernel embedding of the prior distribution 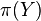 .
.
Kernel sum rule
In probability theory, the marginal distribution of can be computed by integrating out from the joint density (including the prior distribution on )
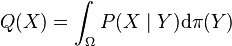
The analog of this rule in the kernel embedding framework states that 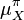 , the RKHS embedding of
, the RKHS embedding of 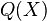 , can be computed via
, can be computed via
-
![\mu_X^\pi = \mathbb{E}_{Y} [\mathcal{C}_{X \mid Y} \phi(Y) ] = \mathcal{C}_{X\mid Y} \mathbb{E}_{Y} [\phi(Y)] = \mathcal{C}_{X\mid Y} \mu_Y^\pi](../I/m/1d9fe86137dbe1eb13a0b471d8489e7d.png) where
where 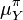 is the kernel embedding of
is the kernel embedding of
-
In practical implementations, the kernel sum rule takes the following form
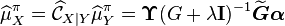
where 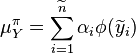 is the empirical kernel embedding of the prior distribution,
is the empirical kernel embedding of the prior distribution, 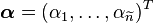 ,
, 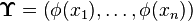 , and
, and 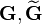 are Gram matrices with entries
are Gram matrices with entries 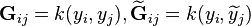 respectively.
respectively.
Kernel chain rule
In probability theory, a joint distribution can be factorized into a product between conditional and marginal distributions
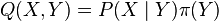
The analog of this rule in the kernel embedding framework states that 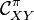 , the joint embedding of
, the joint embedding of 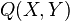 , can be factorized as a composition of conditional embedding operator with the auto-covariance operator associated with
, can be factorized as a composition of conditional embedding operator with the auto-covariance operator associated with
-
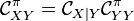 where
where ![\mathcal{C}_{XY}^\pi = \mathbb{E}_{XY} [\phi(X) \otimes \phi(Y) ]](../I/m/663f2f5d45c8c9de4311616e0a7ef843.png) and
and ![\mathcal{C}_{YY}^\pi = \mathbb{E}_Y [\phi(Y) \otimes \phi(Y)]](../I/m/03b0f2642fd5a97935ed6fca89202f13.png)
-
In practical implementations, the kernel chain rule takes the following form
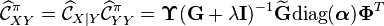
Kernel Bayes' rule
In probability theory, a posterior distribution can be expressed in terms of a prior distribution and a likelihood function as
-
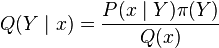 where
where 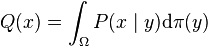
-
The analog of this rule in the kernel embedding framework expresses the kernel embedding of the conditional distribution in terms of conditional embedding operators which are modified by the prior distribution
-
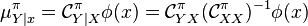 where from the chain rule:
where from the chain rule: 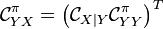 .
.
-
In practical implementations, the kernel Bayes' rule takes the following form
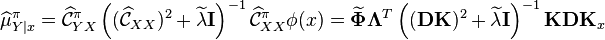
where 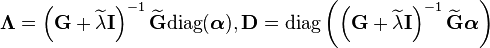 .
Two regularization parameters are used in this framework: for the estimation of
.
Two regularization parameters are used in this framework: for the estimation of 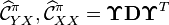 and
and 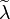 for the estimation of the final conditional embedding operator
for the estimation of the final conditional embedding operator 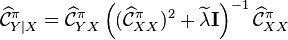 . The latter regularization is done on square of
. The latter regularization is done on square of 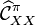 because
because  may not be positive definite.
may not be positive definite.
Applications
Measuring distance between distributions
The maximum mean discrepancy (MMD) is a distance-measure between distributions and 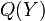 which is defined as the squared distance between their embeddings in the RKHS [5]
which is defined as the squared distance between their embeddings in the RKHS [5]
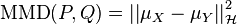
While most distance-measures between distributions such as the widely used Kullback–Leibler divergence either require density estimation (either parametrically or nonparametrically) or space partitioning/bias correction strategies,[5] the MMD is easily estimated as an empirical mean which is concentrated around the true value of the MMD. The characterization of this distance as the maximum mean discrepancy refers to the fact that computing the MMD is equivalent to finding the RKHS function that maximizes the difference in expectations between the two probability distributions
![\text{MMD}(P,Q) = \sup_{||f ||_\mathcal{H} \le 1} \left( \mathbb{E}_X[f(X)] - \mathbb{E}_Y[f(Y)] \right)](../I/m/0f85ad0f27fb8968d5599b6d59914704.png)
Kernel two sample test
Given n training examples from and m samples from , one can formulate a test statistic based on the empirical estimate of the MMD
![\widehat{\text{MMD}}(P,Q) = \left| \left| \frac{1}{n}\sum_{i=1}^n \phi(x_i) - \frac{1}{m}\sum_{i=1}^m \phi(y_i) \right| \right|_{\mathcal{H}}^2 = \frac{1}{nm} \sum_{i=1}^n\sum_{j=1}^m \left[ k(x_i, x_j) + k(y_i, y_j) - 2 k(x_i, y_j) \right]](../I/m/2ae83f286b81eb3945fc43bc275d1a40.png)
to obtain a two-sample test [10] of the null hypothesis that both samples stem from the same distribution (i.e. 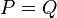 ) against the broad alternative
) against the broad alternative 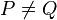 .
.
Density estimation via kernel embeddings
Although learning algorithms in the kernel embedding framework circumvent the need for intermediate density estimation, one may nonetheless use the empirical embedding to perform density estimation based on n samples drawn from an underlying distribution 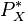 . This can be done by solving the following optimization problem [5][11]
. This can be done by solving the following optimization problem [5][11]
-
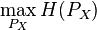 subject to
subject to ![||\widehat{\mu}_X - \mu_X[P_X] ||_\mathcal{H} \le \epsilon](../I/m/2ffb71d70359b089214760bd8ac26c49.png)
-
where the maximization is done over the entire space of distributions on . Here, ![\mu_X[P_X]](../I/m/c7928f3dff69915a8053f202e9dafb06.png) is the kernel embedding of the proposed density
is the kernel embedding of the proposed density 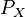 and
and 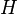 is an entropy-like quantity (e.g. Entropy, KL divergence, Bregman divergence). The distribution which solves this optimization may be interpreted as a compromise between fitting the empirical kernel means of the samples well, while still allocating a substantial portion of the probability mass to all regions of the probability space (much of which may not be represented in the training examples). In practice, a good approximate solution of the difficult optimization may be found by restricting the space of candidate densities to a mixture of M candidate distributions with regularized mixing proportions. Connections between the ideas underlying Gaussian processes and conditional random fields may be drawn with the estimation of conditional probability distributions in this fashion, if one views the feature mappings associated with the kernel as sufficient statistics in generalized (possibly infinite-dimensional) exponential families.[5]
is an entropy-like quantity (e.g. Entropy, KL divergence, Bregman divergence). The distribution which solves this optimization may be interpreted as a compromise between fitting the empirical kernel means of the samples well, while still allocating a substantial portion of the probability mass to all regions of the probability space (much of which may not be represented in the training examples). In practice, a good approximate solution of the difficult optimization may be found by restricting the space of candidate densities to a mixture of M candidate distributions with regularized mixing proportions. Connections between the ideas underlying Gaussian processes and conditional random fields may be drawn with the estimation of conditional probability distributions in this fashion, if one views the feature mappings associated with the kernel as sufficient statistics in generalized (possibly infinite-dimensional) exponential families.[5]
Measuring dependence of random variables
A measure of the statistical dependence between random variables and (from any domains on which sensible kernels can be defined) can be formulated based on the Hilbert–Schmidt Independence Criterion [12]
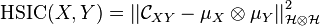
and can be used as a principled replacement for mutual information, Pearson correlation or any other dependence measure used in learning algorithms. Most notably, HSIC can detect arbitrary dependencies (when a characteristic kernel is used in the embeddings, HSIC is zero if and only if the variables are independent), and can be used to measure dependence between different types of data (e.g. images and text captions). Given n i.i.d. samples of each random variable, a simple parameter-free unbiased estimator of HSIC which exhibits concentration about the true value can be computed in 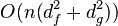 time,[5] where the Gram matrices of the two datasets are approximated using
time,[5] where the Gram matrices of the two datasets are approximated using 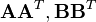 with
with 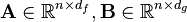 . The desirable properties of HSIC have led to the formulation of numerous algorithms which utilize this dependence measure for a variety of common machine learning tasks such as: feature selection (BAHSIC [13]), clustering (CLUHSIC [14]), and dimensionality reduction (MUHSIC [15]).
. The desirable properties of HSIC have led to the formulation of numerous algorithms which utilize this dependence measure for a variety of common machine learning tasks such as: feature selection (BAHSIC [13]), clustering (CLUHSIC [14]), and dimensionality reduction (MUHSIC [15]).
Kernel belief propagation
Belief propagation is a fundamental algorithm for inference in graphical models in which nodes repeatedly pass and receive messages corresponding to the evaluation of conditional expectations. In the kernel embedding framework, the messages may be represented as RKHS functions and the conditional distribution embeddings can be applied to efficiently compute message updates. Given n samples of random variables represented by nodes in a Markov Random Field, the incoming message to node t from node u can be expressed as 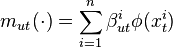 if it assumed to lie in the RKHS. The kernel belief propagation update message from t to node s is then given by [2]
if it assumed to lie in the RKHS. The kernel belief propagation update message from t to node s is then given by [2]
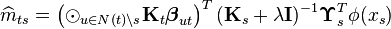
where 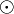 denotes the element-wise vector product,
denotes the element-wise vector product, 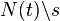 is the set of nodes connected to t excluding node s,
is the set of nodes connected to t excluding node s, 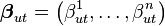 ,
, 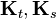 are the Gram matrices of the samples from variables
are the Gram matrices of the samples from variables 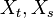 , respectively, and
, respectively, and 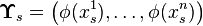 is the feature matrix for the samples from
is the feature matrix for the samples from  .
.
Thus, if the incoming messages to node t are linear combinations of feature mapped samples from  , then the outgoing message from this node is also a linear combination of feature mapped samples from . This RKHS function representation of message-passing updates therefore produces an efficient belief propagation algorithm in which the potentials are nonparametric functions inferred from the data so that arbitrary statistical relationships may be modeled.[2]
, then the outgoing message from this node is also a linear combination of feature mapped samples from . This RKHS function representation of message-passing updates therefore produces an efficient belief propagation algorithm in which the potentials are nonparametric functions inferred from the data so that arbitrary statistical relationships may be modeled.[2]
Nonparametric filtering in hidden Markov models
In the hidden Markov model (HMM), two key quantities of interest are the transition probabilities between hidden states 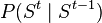 and the emission probabilities
and the emission probabilities 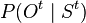 for observations. Using the kernel conditional distribution embedding framework, these quantities may be expressed in terms of samples from the HMM. A serious limitation of the embedding methods in this domain is the need for training samples containing hidden states, as otherwise inference with arbitrary distributions in the HMM is not possible.
for observations. Using the kernel conditional distribution embedding framework, these quantities may be expressed in terms of samples from the HMM. A serious limitation of the embedding methods in this domain is the need for training samples containing hidden states, as otherwise inference with arbitrary distributions in the HMM is not possible.
One common use of HMMs is filtering in which the goal is to estimate posterior distribution over the hidden state 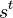 at time step t given a history of previous observations
at time step t given a history of previous observations 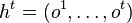 from the system. In filtering, a belief state
from the system. In filtering, a belief state 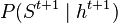 is recursively maintained via a prediction step (where updates
is recursively maintained via a prediction step (where updates ![P(S^{t+1} \mid h^t) = \mathbb{E}_{S^t \mid h^t} [P(S^{t+1} \mid S^t)]](../I/m/cb7c027c81987dac19029174d527499a.png) are computed by marginalizing out the previous hidden state) followed by a conditioning step (where updates
are computed by marginalizing out the previous hidden state) followed by a conditioning step (where updates 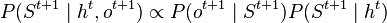 are computed by applying Bayes' rule to condition on a new observation).[2] The RKHS embedding of the belief state at time t+1 can be recursively expressed as
are computed by applying Bayes' rule to condition on a new observation).[2] The RKHS embedding of the belief state at time t+1 can be recursively expressed as
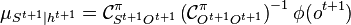
by computing the embeddings of the prediction step via the kernel sum rule and the embedding of the conditioning step via kernel Bayes' rule. Assuming a training sample 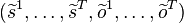 is given, one can in practice estimate
is given, one can in practice estimate 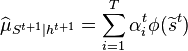 and filtering with kernel embeddings is thus implemented recursively using the following updates for the weights
and filtering with kernel embeddings is thus implemented recursively using the following updates for the weights 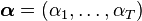 [2]
[2]
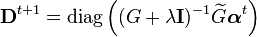
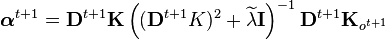
where 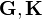 denote the Gram matrices of
denote the Gram matrices of 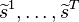 and
and 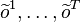 respectively,
respectively, 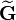 is a transfer Gram matrix defined as
is a transfer Gram matrix defined as 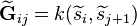 , and
, and 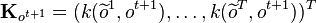 .
.
Support measure machines
The support measure machine (SMM) is a generalization of the support vector machine (SVM) in which the training examples are probability distributions paired with labels 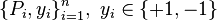 .[16]
SMMs solve the standard SVM dual optimization problem using the following expected kernel
.[16]
SMMs solve the standard SVM dual optimization problem using the following expected kernel
![K\left(P(X), Q(Z)\right) = \langle \mu_X , \mu_Z \rangle_\mathcal{H} = \mathbb{E}_{XZ} [k(x,z)]](../I/m/36f8d44720dd75253679c88f6b824c23.png)
which is computable in closed form for many common specific distributions 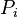 (such as the Gaussian distribution) combined with popular embedding kernels (e.g. the Gaussian kernel or polynomial kernel), or can be accurately empirically estimated from i.i.d. samples
(such as the Gaussian distribution) combined with popular embedding kernels (e.g. the Gaussian kernel or polynomial kernel), or can be accurately empirically estimated from i.i.d. samples 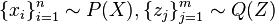 via
via
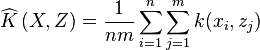
Under certain choices of the embedding kernel , the SMM applied to training examples 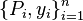 is equivalent to a SVM trained on samples
is equivalent to a SVM trained on samples 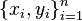 , and thus the SMM can be viewed as a flexible SVM in which a different data-dependent kernel (specified by the assumed form of the distribution ) may be placed on each training point.[16]
, and thus the SMM can be viewed as a flexible SVM in which a different data-dependent kernel (specified by the assumed form of the distribution ) may be placed on each training point.[16]
Domain adaptation under covariate, target, and conditional shift
The goal of domain adaptation is the formulation of learning algorithms which generalize well when the training and test data have different distributions. Given training examples 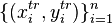 and a test set
and a test set 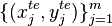 where the
where the 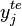 are unknown, three types of differences are commonly assumed between the distribution of the training examples
are unknown, three types of differences are commonly assumed between the distribution of the training examples 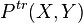 and the test distribution
and the test distribution 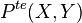 :[17][18]
:[17][18]
- Covariate Shift in which the marginal distribution of the covariates changes across domains:
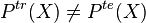
- Target Shift in which the marginal distribution of the outputs changes across domains:
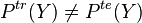
- Conditional Shift in which
 remains the same across domains, but the conditional distributions differ:
remains the same across domains, but the conditional distributions differ: 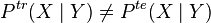 . In general, the presence of conditional shift leads to an ill-posed problem, and the additional assumption that
. In general, the presence of conditional shift leads to an ill-posed problem, and the additional assumption that 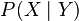 changes only under location-scale (LS) transformations on is commonly imposed to make the problem tractable.
changes only under location-scale (LS) transformations on is commonly imposed to make the problem tractable.
By utilizing the kernel embedding of marginal and conditional distributions, practical approaches to deal with the presence of these types of differences between training and test domains can be formulated. Covariate shift may be accounted for by reweighting examples via estimates of the ratio 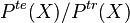 obtained directly from the kernel embeddings of the marginal distributions of in each domain without any need for explicit estimation of the distributions.[18] Target shift, which cannot be similarly dealt with since no samples from are available in the test domain, is accounted for by weighting training examples using the vector
obtained directly from the kernel embeddings of the marginal distributions of in each domain without any need for explicit estimation of the distributions.[18] Target shift, which cannot be similarly dealt with since no samples from are available in the test domain, is accounted for by weighting training examples using the vector 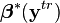 which solves the following optimization problem (where in practice, empirical approximations must be used) [17]
which solves the following optimization problem (where in practice, empirical approximations must be used) [17]
-
![\min_{\boldsymbol{\beta}(y)} \left|\left|\mathcal{C}_{{(X \mid Y)}^{tr}} \mathbb{E}_{Y^{tr}} [ \boldsymbol{\beta}(y) \phi(y)] - \mu_{X^{te}} \right|\right|_\mathcal{H}^2](../I/m/537f0f6d1c52d42cbd46a5ed5205c5ac.png) subject to
subject to ![\boldsymbol{\beta}(y) \ge 0, \mathbb{E}_{Y^{tr}} [ \boldsymbol{\beta}(y)] = 1](../I/m/cb05346d8fb637a908d851654600cd5f.png)
-
To deal with location scale conditional shift, one can perform a LS transformation of the training points to obtain new transformed training data 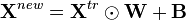 (where denotes the element-wise vector product). To ensure similar distributions between the new transformed training samples and the test data,
(where denotes the element-wise vector product). To ensure similar distributions between the new transformed training samples and the test data, 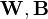 are estimated by minimizing the following empirical kernel embedding distance [17]
are estimated by minimizing the following empirical kernel embedding distance [17]
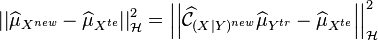
In general, the kernel embedding methods for dealing with LS conditional shift and target shift may be combined to find a reweighted transformation of the training data which mimics the test distribution, and these methods may perform well even in the presence of conditional shifts other than location-scale changes.[17]
Domain generalization via invariant feature representation
Given N sets of training examples sampled i.i.d. from distributions 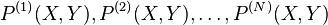 , the goal of domain generalization is to formulate learning algorithms which perform well on test examples sampled from a previously unseen domain
, the goal of domain generalization is to formulate learning algorithms which perform well on test examples sampled from a previously unseen domain 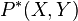 where no data from the test domain is available at training time. If conditional distributions are assumed to be relatively similar across all domains, then a learner capable of domain generalization must estimate a functional relationship between the variables which is robust to changes in the marginals . Based on kernel embeddings of these distributions, Domain Invariant Component Analysis (DICA) is a method which determines the transformation of the training data that minimizes the difference between marginal distributions while preserving a common conditional distribution shared between all training domains.[19] DICA thus extracts invariants, features that transfer across domains, and may be viewed as a generalization of many popular dimension-reduction methods such as kernel principal component analysis, transfer component analysis, and covariance operator inverse regression.[19]
where no data from the test domain is available at training time. If conditional distributions are assumed to be relatively similar across all domains, then a learner capable of domain generalization must estimate a functional relationship between the variables which is robust to changes in the marginals . Based on kernel embeddings of these distributions, Domain Invariant Component Analysis (DICA) is a method which determines the transformation of the training data that minimizes the difference between marginal distributions while preserving a common conditional distribution shared between all training domains.[19] DICA thus extracts invariants, features that transfer across domains, and may be viewed as a generalization of many popular dimension-reduction methods such as kernel principal component analysis, transfer component analysis, and covariance operator inverse regression.[19]
Defining a probability distribution 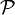 on the RKHS with
on the RKHS with 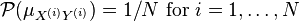 , DICA measures dissimilarity between domains via distributional variance which is computed as
, DICA measures dissimilarity between domains via distributional variance which is computed as
-
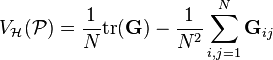 where
where 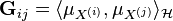
-
so  is a
is a  Gram matrix over the distributions from which the training data are sampled. Finding an orthogonal transform onto a low-dimensional subspace B (in the feature space) which minimizes the distributional variance, DICA simultaneously ensures that B aligns with the bases of a central subspace C for which becomes independent of given
Gram matrix over the distributions from which the training data are sampled. Finding an orthogonal transform onto a low-dimensional subspace B (in the feature space) which minimizes the distributional variance, DICA simultaneously ensures that B aligns with the bases of a central subspace C for which becomes independent of given 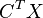 across all domains. In the absence of target values , an unsupervised version of DICA may be formulated which finds a low-dimensional subspace that minimizes distributional variance while simultaneously maximizing the variance of (in the feature space) across all domains (rather than preserving a central subspace).[19]
across all domains. In the absence of target values , an unsupervised version of DICA may be formulated which finds a low-dimensional subspace that minimizes distributional variance while simultaneously maximizing the variance of (in the feature space) across all domains (rather than preserving a central subspace).[19]
Example
In this simple example, which is taken from Song et al.,[2] are assumed to be discrete random variables which take values in the set 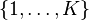 and the kernel is chosen to be the Kronecker delta function, so
and the kernel is chosen to be the Kronecker delta function, so 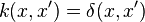 . The feature map corresponding to this kernel is the standard basis vector
. The feature map corresponding to this kernel is the standard basis vector 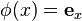 . The kernel embeddings of such a distributions are thus vectors of marginal probabilities while the embeddings of joint distributions in this setting are
. The kernel embeddings of such a distributions are thus vectors of marginal probabilities while the embeddings of joint distributions in this setting are 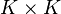 matrices specifying joint probability tables, and the explicit form of these embeddings is
matrices specifying joint probability tables, and the explicit form of these embeddings is
![\mu_X = \mathbb{E}_X [\mathbf{e}_x] = \left(
\begin{array}{c}
P(X=1) \\
\vdots \\
P(X=K) \\
\end{array}
\right)](../I/m/6369bb852e0eba8eb31f1aeba8ca7c79.png)
![\mathcal{C}_{XY} = \mathbb{E}_{XY} [\mathbf{e}_X \otimes e_Y] = \bigg( P(X=s, Y=t) \bigg)_{s,t \in \{1,\dots,K\}}](../I/m/1ae3722d6eef87934092961abece840b.png)
The conditional distribution embedding operator is in this setting a conditional probability table
-
- and
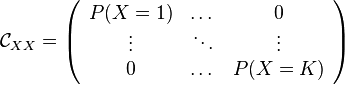
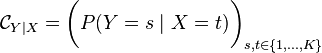
Thus, the embeddings of the conditional distribution under a fixed value of may be computed as
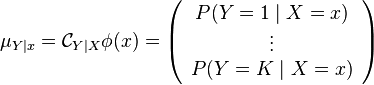
In this discrete-valued setting with the Kronecker delta kernel, the kernel sum rule becomes
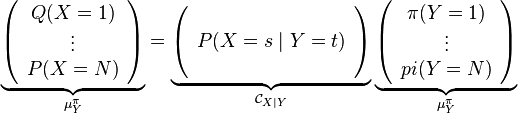
The kernel chain rule in this case is given by
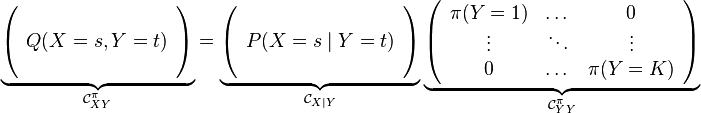
References
- 1 2 A. Smola, A. Gretton, L. Song, B. Schölkopf. (2007). A Hilbert Space Embedding for Distributions. Algorithmic Learning Theory: 18th International Conference. Springer: 13–31.
- 1 2 3 4 5 6 7 8 9 10 11 12 13 14 L. Song, K. Fukumizu, F. Dinuzzo, A. Gretton (2013). Kernel Embeddings of Conditional Distributions: A unified kernel framework for nonparametric inference in graphical models. IEEE Signal Processing Magazine 30: 98–111.
- ↑ J. Shawe-Taylor, N. Christianini. (2004). Kernel Methods for Pattern Analysis. Cambridge University Press, Cambridge, UK.
- ↑ T. Hofmann, B. Schölkopf, A. Smola. (2008). Kernel Methods in Machine Learning. The Annals of Statistics 36(3):1171–1220.
- 1 2 3 4 5 6 7 8 9 L. Song. (2008) Learning via Hilbert Space Embedding of Distributions. PhD Thesis, University of Sydney.
- ↑ K. Fukumizu, A. Gretton, X. Sun, and B. Schölkopf (2008). Kernel measures of conditional independence. Advances in Neural Information Processing Systems 20, MIT Press, Cambridge, MA.
- 1 2 3 L. Song, J. Huang, A. J. Smola, K. Fukumizu. (2009). Hilbert space embeddings of conditional distributions. Proc. Int. Conf. Machine Learning. Montreal, Canada: 961-968.
- ↑ A. Gretton, K. Borgwardt, M. Rasch, B. Schölkopf, A. Smola. (2007). A kernel method for the two-sample-problem. Advances in Neural Information Processing Systems 19, MIT Press, Cambridge, MA.
- ↑ S. Grunewalder, G. Lever, L. Baldassarre, S. Patterson, A. Gretton, M. Pontil. (2012). Conditional mean embeddings as regressors. Proc. Int. Conf. Machine Learning: 1823–1830.
- ↑ A. Gretton, K. Borgwardt, M. Rasch, B. Schölkopf, A. Smola. (2012). A kernel two-sample test. Journal of Machine Learning Research, 13: 723-773.
- ↑ M. Dudík, S. J. Phillips, R. E. Schapire. (2007). Maximum Entropy Distribution Estimation with Generalized Regularization and an Application to Species Distribution Modeling. Journal of Machine Learning Research, 8: 1217-1260.
- ↑ A. Gretton, O. Bousquet, A. Smola, B. Schölkopf. (2005). Measuring statistical dependence with Hilbert–Schmidt norms. Proc. Intl. Conf. on Algorithmic Learning Theory: 63–78.
- ↑ L. Song, A. Smola , A. Gretton, K. Borgwardt, J. Bedo. (2007). Supervised feature selection via dependence estimation. Proc. Intl. Conf. Machine Learning, Omnipress: 823–830.
- ↑ L. Song, A. Smola, A. Gretton, K. Borgwardt. (2007). A dependence maximization view of clustering. Proc. Intl. Conf. Machine Learning. Omnipress: 815–822.
- ↑ L. Song, A. Smola, K. Borgwardt, A. Gretton. (2007). Colored maximum variance unfolding. Neural Information Processing Systems.
- 1 2 K. Muandet, K. Fukumizu, F. Dinuzzo, B. Schölkopf. (2012). Learning from Distributions via Support Measure Machines. Advances in Neural Information Processing Systems: 10–18.
- 1 2 3 4 K. Zhang, B. Schölkopf, K. Muandet, Z. Wang. (2013). Domain adaptation under target and conditional shift. Journal of Machine Learning Research, 28(3): 819–827.
- 1 2 A. Gretton, A. Smola, J. Huang, M. Schmittfull, K. Borgwardt, B. Schölkopf. (2008). Covariate shift and local learning by distribution matching. In J. Quinonero-Candela, M. Sugiyama, A. Schwaighofer, N. Lawrence (eds.). Dataset shift in machine learning, MIT Press, Cambridge, MA: 131–160.
- 1 2 3 K. Muandet, D. Balduzzi, B. Schölkopf. (2013).Domain Generalization Via Invariant Feature Representation. 30th International Conference on Machine Learning.