Kalman filter

 denotes the estimate of the system's state at time step k before the k-th measurement yk has been taken into account;
denotes the estimate of the system's state at time step k before the k-th measurement yk has been taken into account; 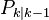 is the corresponding uncertainty.
is the corresponding uncertainty.Kalman filtering, also known as linear quadratic estimation (LQE), is an algorithm that uses a series of measurements observed over time, containing statistical noise and other inaccuracies, and produces estimates of unknown variables that tend to be more precise than those based on a single measurement alone. The filter is named after Rudolf E. Kálmán, one of the primary developers of its theory.
The Kalman filter has numerous applications in technology. A common application is for guidance, navigation and control of vehicles, particularly aircraft and spacecraft. Furthermore, the Kalman filter is a widely applied concept in time series analysis used in fields such as signal processing and econometrics. Kalman filters also are one of the main topics in the field of robotic motion planning and control, and they are sometimes included in trajectory optimization. The Kalman filter has also found use in modeling the central nervous system's control of movement. Due to the time delay between issuing motor commands and receiving sensory feedback, use of the Kalman filter provides the needed model for making estimates of the current state of the motor system and issuing updated commands. [1]
The algorithm works in a two-step process. In the prediction step, the Kalman filter produces estimates of the current state variables, along with their uncertainties. Once the outcome of the next measurement (necessarily corrupted with some amount of error, including random noise) is observed, these estimates are updated using a weighted average, with more weight being given to estimates with higher certainty. The algorithm is recursive. It can run in real time, using only the present input measurements and the previously calculated state and its uncertainty matrix; no additional past information is required.
The Kalman filter does not require any assumption that the errors are Gaussian.[2] However, the filter yields the exact conditional probability estimate in the special case that all errors are Gaussian-distributed.
Extensions and generalizations to the method have also been developed, such as the extended Kalman filter and the unscented Kalman filter which work on nonlinear systems. The underlying model is a Bayesian model similar to a hidden Markov model but where the state space of the latent variables is continuous and where all latent and observed variables have Gaussian distributions.
Naming and historical development

The filter is named after Hungarian émigré Rudolf E. Kálmán, although Thorvald Nicolai Thiele[3][4] and Peter Swerling developed a similar algorithm earlier. Richard S. Bucy of the University of Southern California contributed to the theory, leading to it often being called the Kalman–Bucy filter. Stanley F. Schmidt is generally credited with developing the first implementation of a Kalman filter. He realized that the filter could be divided into two distinct parts, with one part for time periods between sensor outputs and another part for incorporating measurements.[5] It was during a visit by Kálmán to the NASA Ames Research Center that he saw the applicability of his ideas to the problem of trajectory estimation for the Apollo program, leading to its incorporation in the Apollo navigation computer. This Kalman filter was first described and partially developed in technical papers by Swerling (1958), Kalman (1960) and Kalman and Bucy (1961).
Kalman filters have been vital in the implementation of the navigation systems of U.S. Navy nuclear ballistic missile submarines, and in the guidance and navigation systems of cruise missiles such as the U.S. Navy's Tomahawk missile and the U.S. Air Force's Air Launched Cruise Missile. It is also used in the guidance and navigation systems of the NASA Space Shuttle and the attitude control and navigation systems of the International Space Station.
This digital filter is sometimes called the Stratonovich–Kalman–Bucy filter because it is a special case of a more general, non-linear filter developed somewhat earlier by the Soviet mathematician Ruslan Stratonovich.[6][7][8][9] In fact, some of the special case linear filter's equations appeared in these papers by Stratonovich that were published before summer 1960, when Kalman met with Stratonovich during a conference in Moscow.
Overview of the calculation
The Kalman filter uses a system's dynamics model (e.g., physical laws of motion), known control inputs to that system, and multiple sequential measurements (such as from sensors) to form an estimate of the system's varying quantities (its state) that is better than the estimate obtained by using any one measurement alone. As such, it is a common sensor fusion and data fusion algorithm.
All measurements and calculations based on models are estimated to some degree. Noisy sensor data, approximations in the equations that describe how a system changes, and external factors that are not accounted for introduce some uncertainty about the inferred values for a system's state. The Kalman filter averages a prediction of a system's state with a new measurement using a weighted average. The purpose of the weights is that values with better (i.e., smaller) estimated uncertainty are "trusted" more. The weights are calculated from the covariance, a measure of the estimated uncertainty of the prediction of the system's state. The result of the weighted average is a new state estimate that lies between the predicted and measured state, and has a better estimated uncertainty than either alone. This process is repeated every time step, with the new estimate and its covariance informing the prediction used in the following iteration. This means that the Kalman filter works recursively and requires only the last "best guess", rather than the entire history, of a system's state to calculate a new state.
Because the certainty of the measurements is often difficult to measure precisely, it is common to discuss the filter's behavior in terms of gain. The Kalman gain is a function of the relative certainty of the measurements and current state estimate, and can be "tuned" to achieve particular performance. With a high gain, the filter places more weight on the measurements, and thus follows them more closely. With a low gain, the filter follows the model predictions more closely, smoothing out noise but decreasing the responsiveness. At the extremes, a gain of one causes the filter to ignore the state estimate entirely, while a gain of zero causes the measurements to be ignored.
When performing the actual calculations for the filter (as discussed below), the state estimate and covariances are coded into matrices to handle the multiple dimensions involved in a single set of calculations. This allows for a representation of linear relationships between different state variables (such as position, velocity, and acceleration) in any of the transition models or covariances.
Example application
As an example application, consider the problem of determining the precise location of a truck. The truck can be equipped with a GPS unit that provides an estimate of the position within a few meters. The GPS estimate is likely to be noisy; readings 'jump around' rapidly, though always remaining within a few meters of the real position. In addition, since the truck is expected to follow the laws of physics, its position can also be estimated by integrating its velocity over time, determined by keeping track of wheel revolutions and the angle of the steering wheel. This is a technique known as dead reckoning. Typically, the dead reckoning will provide a very smooth estimate of the truck's position, but it will drift over time as small errors accumulate.
In this example, the Kalman filter can be thought of as operating in two distinct phases: predict and update. In the prediction phase, the truck's old position will be modified according to the physical laws of motion (the dynamic or "state transition" model) plus any changes produced by the accelerator pedal and steering wheel. Not only will a new position estimate be calculated, but a new covariance will be calculated as well. Perhaps the covariance is proportional to the speed of the truck because we are more uncertain about the accuracy of the dead reckoning position estimate at high speeds but very certain about the position estimate when moving slowly. Next, in the update phase, a measurement of the truck's position is taken from the GPS unit. Along with this measurement comes some amount of uncertainty, and its covariance relative to that of the prediction from the previous phase determines how much the new measurement will affect the updated prediction. Ideally, if the dead reckoning estimates tend to drift away from the real position, the GPS measurement should pull the position estimate back towards the real position but not disturb it to the point of becoming rapidly changing and noisy.
Technical description and context
The Kalman filter is an efficient recursive filter that estimates the internal state of a linear dynamic system from a series of noisy measurements. It is used in a wide range of engineering and econometric applications from radar and computer vision to estimation of structural macroeconomic models,[10][11] and is an important topic in control theory and control systems engineering. Together with the linear-quadratic regulator (LQR), the Kalman filter solves the linear-quadratic-Gaussian control problem (LQG). The Kalman filter, the linear-quadratic regulator and the linear-quadratic-Gaussian controller are solutions to what arguably are the most fundamental problems in control theory.
In most applications, the internal state is much larger (more degrees of freedom) than the few "observable" parameters which are measured. However, by combining a series of measurements, the Kalman filter can estimate the entire internal state.
In Dempster–Shafer theory, each state equation or observation is considered a special case of a linear belief function and the Kalman filter is a special case of combining linear belief functions on a join-tree or Markov tree. Additional approaches include belief filters which use Bayes or evidential updates to the state equations.
A wide variety of Kalman filters have now been developed, from Kalman's original formulation, now called the "simple" Kalman filter, the Kalman–Bucy filter, Schmidt's "extended" filter, the information filter, and a variety of "square-root" filters that were developed by Bierman, Thornton and many others. Perhaps the most commonly used type of very simple Kalman filter is the phase-locked loop, which is now ubiquitous in radios, especially frequency modulation (FM) radios, television sets, satellite communications receivers, outer space communications systems, and nearly any other electronic communications equipment.
Underlying dynamic system model
The Kalman filters are based on linear dynamic systems discretized in the time domain. They are modelled on a Markov chain built on linear operators perturbed by errors that may include Gaussian noise. The state of the system is represented as a vector of real numbers. At each discrete time increment, a linear operator is applied to the state to generate the new state, with some noise mixed in, and optionally some information from the controls on the system if they are known. Then, another linear operator mixed with more noise generates the observed outputs from the true ("hidden") state. The Kalman filter may be regarded as analogous to the hidden Markov model, with the key difference that the hidden state variables take values in a continuous space (as opposed to a discrete state space as in the hidden Markov model). There is a strong duality between the equations of the Kalman Filter and those of the hidden Markov model. A review of this and other models is given in Roweis and Ghahramani (1999)[12] and Hamilton (1994), Chapter 13.[13]
In order to use the Kalman filter to estimate the internal state of a process given only a sequence of noisy observations, one must model the process in accordance with the framework of the Kalman filter. This means specifying the following matrices: Fk, the state-transition model; Hk, the observation model; Qk, the covariance of the process noise; Rk, the covariance of the observation noise; and sometimes Bk, the control-input model, for each time-step, k, as described below.

The Kalman filter model assumes the true state at time k is evolved from the state at (k − 1) according to
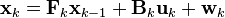
where
- Fk is the state transition model which is applied to the previous state xk−1;
- Bk is the control-input model which is applied to the control vector uk;
- wk is the process noise which is assumed to be drawn from a zero mean multivariate normal distribution with covariance Qk.
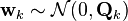
At time k an observation (or measurement) zk of the true state xk is made according to
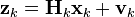
where Hk is the observation model which maps the true state space into the observed space and vk is the observation noise which is assumed to be zero mean Gaussian white noise with covariance Rk.
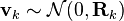
The initial state, and the noise vectors at each step {x0, w1, …, wk, v1 … vk} are all assumed to be mutually independent.
Many real dynamical systems do not exactly fit this model. In fact, unmodelled dynamics can seriously degrade the filter performance, even when it was supposed to work with unknown stochastic signals as inputs. The reason for this is that the effect of unmodelled dynamics depends on the input, and, therefore, can bring the estimation algorithm to instability (it diverges). On the other hand, independent white noise signals will not make the algorithm diverge. The problem of separating between measurement noise and unmodelled dynamics is a difficult one and is treated in control theory under the framework of robust control.[14][15]
Details
The Kalman filter is a recursive estimator. This means that only the estimated state from the previous time step and the current measurement are needed to compute the estimate for the current state. In contrast to batch estimation techniques, no history of observations and/or estimates is required. In what follows, the notation 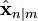 represents the estimate of
represents the estimate of 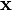 at time n given observations up to, and including at time m ≤ n.
at time n given observations up to, and including at time m ≤ n.
The state of the filter is represented by two variables:
-
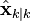 , the a posteriori state estimate at time k given observations up to and including at time k;
, the a posteriori state estimate at time k given observations up to and including at time k; -
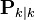 , the a posteriori error covariance matrix (a measure of the estimated accuracy of the state estimate).
, the a posteriori error covariance matrix (a measure of the estimated accuracy of the state estimate).
The Kalman filter can be written as a single equation, however it is most often conceptualized as two distinct phases: "Predict" and "Update". The predict phase uses the state estimate from the previous timestep to produce an estimate of the state at the current timestep. This predicted state estimate is also known as the a priori state estimate because, although it is an estimate of the state at the current timestep, it does not include observation information from the current timestep. In the update phase, the current a priori prediction is combined with current observation information to refine the state estimate. This improved estimate is termed the a posteriori state estimate.
Typically, the two phases alternate, with the prediction advancing the state until the next scheduled observation, and the update incorporating the observation. However, this is not necessary; if an observation is unavailable for some reason, the update may be skipped and multiple prediction steps performed. Likewise, if multiple independent observations are available at the same time, multiple update steps may be performed (typically with different observation matrices Hk).[16][17]
Predict
| Predicted (a priori) state estimate | 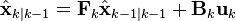 |
| Predicted (a priori) estimate covariance | 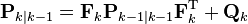 |
Update
| Innovation or measurement residual | 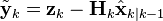 |
| Innovation (or residual) covariance |  |
| Optimal Kalman gain | 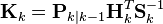 |
| Updated (a posteriori) state estimate |  |
| Updated (a posteriori) estimate covariance | 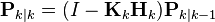 |
The formula for the updated estimate covariance above is only valid for the optimal Kalman gain. Usage of other gain values requires a more complex formula found in the derivations section.
Invariants
If the model is accurate, and the values for  and
and 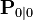 accurately reflect the distribution of the initial state values, then the following invariants are preserved: (all estimates have a mean error of zero)
accurately reflect the distribution of the initial state values, then the following invariants are preserved: (all estimates have a mean error of zero)
![\mathbf{E}[\mathbf{x}_k - \hat{\mathbf{x}}_{k\mid k}] = \textrm{E}[\mathbf{x}_k - \hat{\mathbf{x}}_{k\mid k-1}] = 0](../I/m/ef8ed0b123b3b4c079ec49bbe54af318.png)
![\textrm{E}[\tilde{\mathbf{y}}_k] = 0](../I/m/d0a795fa05ba338eccafdb8d326af328.png)
where ![\textrm{E}[\xi]](../I/m/622bdf3feac7f49bbef4950f48b8fd45.png) is the expected value of
is the expected value of  , and covariance matrices accurately reflect the covariance of estimates
, and covariance matrices accurately reflect the covariance of estimates

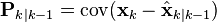
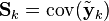
Optimality and performance
It follows from theory that the Kalman filter is optimal in cases where a) the model perfectly matches the real system, b) the entering noise is white and c) the covariances of the noise are exactly known. Several methods for the noise covariance estimation have been proposed during past decades. After the covariances are estimated, it is useful to evaluate the performance of the filter, i.e. whether it is possible to improve the state estimation quality. If the Kalman filter works optimally, the innovation sequence (the output prediction error) is a white noise, therefore the whiteness property of the innovations measures filter performance. Several different methods can be used for this purpose.[18]
Example application, technical
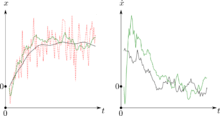
Consider a truck on frictionless, straight rails. Initially, the truck is stationary at position 0, but it is buffeted this way and that by random uncontrolled forces. We measure the position of the truck every Δt seconds, but these measurements are imprecise; we want to maintain a model of where the truck is and what its velocity is. We show here how we derive the model from which we create our Kalman filter.
Since 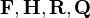 are constant, their time indices are dropped.
are constant, their time indices are dropped.
The position and velocity of the truck are described by the linear state space
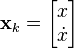
where 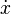 is the velocity, that is, the derivative of position with respect to time.
is the velocity, that is, the derivative of position with respect to time.
We assume that between the (k − 1) and k timestep uncontrolled forces cause a constant acceleration of ak that is normally distributed, with mean 0 and standard deviation σa. From Newton's laws of motion we conclude that
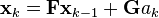
(note that there is no 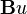 term since we have no known control inputs. Instead, we assume that ak is the effect of an unknown input and
term since we have no known control inputs. Instead, we assume that ak is the effect of an unknown input and  applies that effect to the state vector) where
applies that effect to the state vector) where
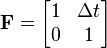
and
![\mathbf{G} = \begin{bmatrix} \frac{\Delta t^2}{2} \\[6pt] \Delta t \end{bmatrix}](../I/m/92d88df42ed15b0c57511f39ff1fb258.png)
so that
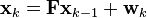
where 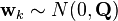 and
and
![\mathbf{Q}=\mathbf{G}\mathbf{G}^{\text{T}}\sigma_a^2 =\begin{bmatrix} \frac{\Delta t^4}{4} & \frac{\Delta t^3}{2} \\[6pt] \frac{\Delta t^3}{2} & \Delta t^2 \end{bmatrix}\sigma_a^2.](../I/m/a189db8d8f2fca5065335d7bf92b0563.png)
At each time step, a noisy measurement of the true position of the truck is made. Let us suppose the measurement noise vk is also normally distributed, with mean 0 and standard deviation σz.
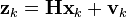
where
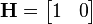
and
![\mathbf{R} = \textrm{E}[\mathbf{v}_k \mathbf{v}_k^{\text{T}}] = \begin{bmatrix} \sigma_z^2 \end{bmatrix}](../I/m/a308c849eb4941a4702e8587fdd0da3b.png)
We know the initial starting state of the truck with perfect precision, so we initialize
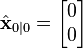
and to tell the filter that we know the exact position and velocity, we give it a zero covariance matrix:

If the initial position and velocity are not known perfectly the covariance matrix should be initialized with a suitably large number, say L, on its diagonal.
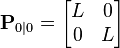
The filter will then prefer the information from the first measurements over the information already in the model.
Derivations
Deriving the a posteriori estimate covariance matrix
Starting with our invariant on the error covariance Pk | k as above
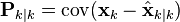
substitute in the definition of

and substitute 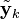
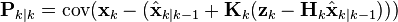
and 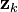
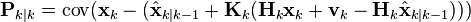
and by collecting the error vectors we get
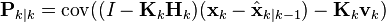
Since the measurement error vk is uncorrelated with the other terms, this becomes
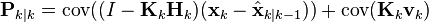
by the properties of vector covariance this becomes
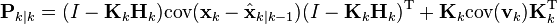
which, using our invariant on Pk | k−1 and the definition of Rk becomes
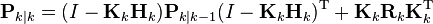
This formula (sometimes known as the "Joseph form" of the covariance update equation) is valid for any value of Kk. It turns out that if Kk is the optimal Kalman gain, this can be simplified further as shown below.
Kalman gain derivation
The Kalman filter is a minimum mean-square error estimator. The error in the a posteriori state estimation is
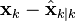
We seek to minimize the expected value of the square of the magnitude of this vector, ![\textrm{E}[\|\mathbf{x}_{k} - \hat{\mathbf{x}}_{k|k}\|^2]](../I/m/4e871ab0558b92db060be2895c1ccbc3.png) . This is equivalent to minimizing the trace of the a posteriori estimate covariance matrix
. This is equivalent to minimizing the trace of the a posteriori estimate covariance matrix 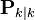 . By expanding out the terms in the equation above and collecting, we get:
. By expanding out the terms in the equation above and collecting, we get:
![\begin{align}
\mathbf{P}_{k\mid k} & = \mathbf{P}_{k\mid k-1} - \mathbf{K}_k \mathbf{H}_k \mathbf{P}_{k\mid k-1} - \mathbf{P}_{k\mid k-1} \mathbf{H}_k^\text{T} \mathbf{K}_k^\text{T} + \mathbf{K}_k (\mathbf{H}_k \mathbf{P}_{k\mid k-1} \mathbf{H}_k^\text{T} + \mathbf{R}_k) \mathbf{K}_k^\text{T} \\[6pt]
& = \mathbf{P}_{k\mid k-1} - \mathbf{K}_k \mathbf{H}_k \mathbf{P}_{k\mid k-1} - \mathbf{P}_{k\mid k-1} \mathbf{H}_k^\text{T} \mathbf{K}_k^\text{T} + \mathbf{K}_k \mathbf{S}_k\mathbf{K}_k^\text{T}
\end{align}](../I/m/f4d91b9bbe31ce2392b2a4489b4bd7e2.png)
The trace is minimized when its matrix derivative with respect to the gain matrix is zero. Using the gradient matrix rules and the symmetry of the matrices involved we find that

Solving this for Kk yields the Kalman gain:
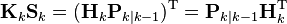
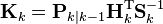
This gain, which is known as the optimal Kalman gain, is the one that yields MMSE estimates when used.
Simplification of the a posteriori error covariance formula
The formula used to calculate the a posteriori error covariance can be simplified when the Kalman gain equals the optimal value derived above. Multiplying both sides of our Kalman gain formula on the right by SkKkT, it follows that
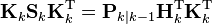
Referring back to our expanded formula for the a posteriori error covariance,
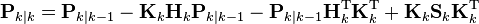
we find the last two terms cancel out, giving
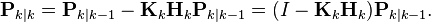
This formula is computationally cheaper and thus nearly always used in practice, but is only correct for the optimal gain. If arithmetic precision is unusually low causing problems with numerical stability, or if a non-optimal Kalman gain is deliberately used, this simplification cannot be applied; the a posteriori error covariance formula as derived above (Joseph form) must be used.
Sensitivity analysis
The Kalman filtering equations provide an estimate of the state and its error covariance recursively. The estimate and its quality depend on the system parameters and the noise statistics fed as inputs to the estimator. This section analyzes the effect of uncertainties in the statistical inputs to the filter.[19] In the absence of reliable statistics or the true values of noise covariance matrices 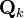 and
and  , the expression
, the expression
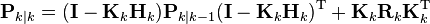
no longer provides the actual error covariance. In other words, ![\mathbf{P}_{k\mid k} \neq E[(\mathbf{x}_k - \hat{\mathbf{x}}_{k\mid k})(\mathbf{x}_k - \hat{\mathbf{x}}_{k\mid k})^\mathrm{T}]](../I/m/3a11f5a2b6ff9aca834b9cc889f6c5a1.png) . In most real-time applications, the covariance matrices that are used in designing the Kalman filter are different from the actual (true) noise covariances matrices. This sensitivity analysis describes the behavior of the estimation error covariance when the noise covariances as well as the system matrices
. In most real-time applications, the covariance matrices that are used in designing the Kalman filter are different from the actual (true) noise covariances matrices. This sensitivity analysis describes the behavior of the estimation error covariance when the noise covariances as well as the system matrices  and
and 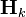 that are fed as inputs to the filter are incorrect. Thus, the sensitivity analysis describes the robustness (or sensitivity) of the estimator to misspecified statistical and parametric inputs to the estimator.
that are fed as inputs to the filter are incorrect. Thus, the sensitivity analysis describes the robustness (or sensitivity) of the estimator to misspecified statistical and parametric inputs to the estimator.
This discussion is limited to the error sensitivity analysis for the case of statistical uncertainties. Here the actual noise covariances are denoted by  and
and 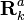 respectively, whereas the design values used in the estimator are
respectively, whereas the design values used in the estimator are 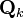 and
and 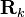 respectively. The actual error covariance is denoted by
respectively. The actual error covariance is denoted by  and as computed by the Kalman filter is referred to as the Riccati variable. When
and as computed by the Kalman filter is referred to as the Riccati variable. When  and
and  , this means that
, this means that  . While computing the actual error covariance using
. While computing the actual error covariance using ![\mathbf{P}_{k\mid k}^a = E[(\mathbf{x}_k - \hat{\mathbf{x}}_{k\mid k})(\mathbf{x}_k - \hat{\mathbf{x}}_{k\mid k})^\mathrm{T}]](../I/m/3eb5b9df7840875039758e133bcca2ba.png) , substituting for
, substituting for 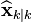 and using the fact that
and using the fact that ![E[\mathbf{w}_k\mathbf{w}_k^\mathrm{T}] = \mathbf{Q}_{k}^a](../I/m/236aafbd105ed94d3ae68066e213fe06.png) and
and ![E[\mathbf{v}_k\mathbf{v}_k^\mathrm{T}] = \mathbf{R}_{k}^a](../I/m/0fa8c7b434aa9b28c9a81e9363a720a2.png) , results in the following recursive equations for :
, results in the following recursive equations for :
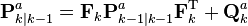
and
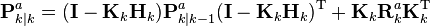
While computing , by design the filter implicitly assumes that ![E[\mathbf{w}_k\mathbf{w}_k^\mathrm{T}] = \mathbf{Q}_{k}](../I/m/81cb9dd4e3d78034f12a7ea37592fcf4.png) and
and ![E[\mathbf{v}_k\mathbf{v}_k^\mathrm{T}] = \mathbf{R}_{k}](../I/m/92d081ed0f565586348af79f0f2ec9ad.png) . Note that the recursive expressions for and are identical except for the presence of
. Note that the recursive expressions for and are identical except for the presence of 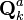 and
and 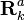 in place of the design values and respectively.
in place of the design values and respectively.
Square root form
One problem with the Kalman filter is its numerical stability. If the process noise covariance Qk is small, round-off error often causes a small positive eigenvalue to be computed as a negative number. This renders the numerical representation of the state covariance matrix P indefinite, while its true form is positive-definite.
Positive definite matrices have the property that they have a triangular matrix square root P = S·ST. This can be computed efficiently using the Cholesky factorization algorithm, but more importantly, if the covariance is kept in this form, it can never have a negative diagonal or become asymmetric. An equivalent form, which avoids many of the square root operations required by the matrix square root yet preserves the desirable numerical properties, is the U-D decomposition form, P = U·D·UT, where U is a unit triangular matrix (with unit diagonal), and D is a diagonal matrix.
Between the two, the U-D factorization uses the same amount of storage, and somewhat less computation, and is the most commonly used square root form. (Early literature on the relative efficiency is somewhat misleading, as it assumed that square roots were much more time-consuming than divisions,[20]:69 while on 21-st century computers they are only slightly more expensive.)
Efficient algorithms for the Kalman prediction and update steps in the square root form were developed by G. J. Bierman and C. L. Thornton.[20][21]
The L·D·LT decomposition of the innovation covariance matrix Sk is the basis for another type of numerically efficient and robust square root filter.[22] The algorithm starts with the LU decomposition as implemented in the Linear Algebra PACKage (LAPACK). These results are further factored into the L·D·LT structure with methods given by Golub and Van Loan (algorithm 4.1.2) for a symmetric nonsingular matrix.[23] Any singular covariance matrix is pivoted so that the first diagonal partition is nonsingular and well-conditioned. The pivoting algorithm must retain any portion of the innovation covariance matrix directly corresponding to observed state-variables Hk·xk|k-1 that are associated with auxiliary observations in yk. the l·d·lt square-root filter requires orthogonalization of the observation vector.[21][22] This may be done with the inverse square-root of the covariance matrix for the auxiliary variables using Method 2 in Higham (2002, p. 263).[24]
Relationship to recursive Bayesian estimation
The Kalman filter can be presented as one of the simplest dynamic Bayesian networks. The Kalman filter calculates estimates of the true values of states recursively over time using incoming measurements and a mathematical process model. Similarly, recursive Bayesian estimation calculates estimates of an unknown probability density function (PDF) recursively over time using incoming measurements and a mathematical process model.[25]
In recursive Bayesian estimation, the true state is assumed to be an unobserved Markov process, and the measurements are the observed states of a hidden Markov model (HMM).

because of the Markov assumption, the true state is conditionally independent of all earlier states given the immediately previous state.
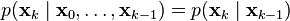
Similarly, the measurement at the k-th timestep is dependent only upon the current state and is conditionally independent of all other states given the current state.
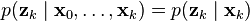
Using these assumptions the probability distribution over all states of the hidden Markov model can be written simply as:
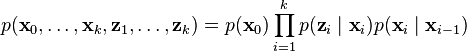
However, when the Kalman filter is used to estimate the state x, the probability distribution of interest is that associated with the current states conditioned on the measurements up to the current timestep. This is achieved by marginalizing out the previous states and dividing by the probability of the measurement set.
This leads to the predict and update steps of the Kalman filter written probabilistically. The probability distribution associated with the predicted state is the sum (integral) of the products of the probability distribution associated with the transition from the (k − 1)-th timestep to the k-th and the probability distribution associated with the previous state, over all possible  .
.

The measurement set up to time t is
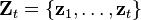
The probability distribution of the update is proportional to the product of the measurement likelihood and the predicted state.
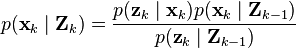
The denominator

is a normalization term.
The remaining probability density functions are
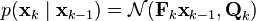
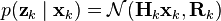
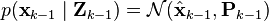
Note that the PDF at the previous timestep is inductively assumed to be the estimated state and covariance. This is justified because, as an optimal estimator, the Kalman filter makes best use of the measurements, therefore the PDF for 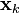 given the measurements
given the measurements 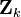 is the Kalman filter estimate.
is the Kalman filter estimate.
Marginal likelihood
Related to the recursive Bayesian interpretation described above, the Kalman filter can be viewed as a generative model, i.e., a process for generating a stream of random observations z = (z0, z1, z2, …). Specifically, the process is
- Sample a hidden state
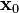 from the Gaussian prior distribution
from the Gaussian prior distribution 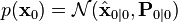 .
. - Sample an observation
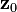 from the observation model
from the observation model 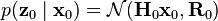 .
. - For
 , do
, do
- Sample the next hidden state from the transition model
 .
. - Sample an observation
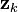 from the observation model
from the observation model 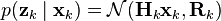 .
.
- Sample the next hidden state
Note that this process has identical structure to the hidden Markov model, except that the discrete state and observations are replaced with continuous variables sampled from Gaussian distributions.
In some applications, it is useful to compute the probability that a Kalman filter with a given set of parameters (prior distribution, transition and observation models, and control inputs) would generate a particular observed signal. This probability is known as the marginal likelihood because it integrates over ("marginalizes out") the values of the hidden state variables, so it can be computed using only the observed signal. The marginal likelihood can be useful to evaluate different parameter choices, or to compare the Kalman filter against other models using Bayesian model comparison.
It is straightforward to compute the marginal likelihood as a side effect of the recursive filtering computation. By the chain rule, the likelihood can be factored as the product of the probability of each observation given previous observations,
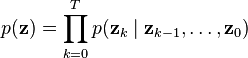 ,
,
and because the Kalman filter describes a Markov process, all relevant information from previous observations is contained in the current state estimate 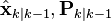 . Thus the marginal likelihood is given by
. Thus the marginal likelihood is given by
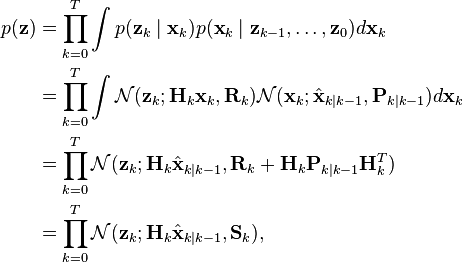
i.e., a product of Gaussian densities, each corresponding to the density of one observation zk under the current filtering distribution 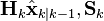 . This can easily be computed as a simple recursive update; however, to avoid numeric underflow, in a practical implementation it is usually desirable to compute the log marginal likelihood
. This can easily be computed as a simple recursive update; however, to avoid numeric underflow, in a practical implementation it is usually desirable to compute the log marginal likelihood 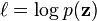 instead. Adopting the convention
instead. Adopting the convention  , this can be done via the recursive update rule
, this can be done via the recursive update rule
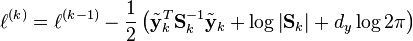 ,
,
where 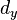 is the dimension of the measurement vector.
[26]
is the dimension of the measurement vector.
[26]
An important application where such a (log) likelihood of the observations (given the filter parameters) is used is multi-target tracking. For example, consider an object tracking scenario where a stream of observations is the input, however, it is unknown how many objects are in the scene (or, the number of objects is known but is greater than one). In such a scenario, it can be unknown apriori which observations/measurements were generated by which object. A multiple hypothesis tracker (MHT) typically will form different track association hypotheses, where each hypothesis can be viewed as a Kalman filter (in the linear Gaussian case) with a specific set of parameters associated with the hypothesized object. Thus, it is important to compute the likelihood of the observations for the different hypotheses under consideration, such that the most-likely one can be found.
Information filter
In the information filter, or inverse covariance filter, the estimated covariance and estimated state are replaced by the information matrix and information vector respectively. These are defined as:
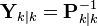
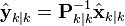
Similarly the predicted covariance and state have equivalent information forms, defined as:

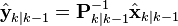
as have the measurement covariance and measurement vector, which are defined as:
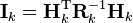

The information update now becomes a trivial sum.

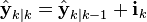
The main advantage of the information filter is that N measurements can be filtered at each timestep simply by summing their information matrices and vectors.
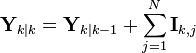
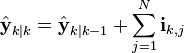
To predict the information filter the information matrix and vector can be converted back to their state space equivalents, or alternatively the information space prediction can be used.
![\textbf{M}_{k} =
[\textbf{F}_{k}^{-1}]^{\text{T}} \textbf{Y}_{k-1\mid k-1} \textbf{F}_{k}^{-1}](../I/m/b575f19b3cb3bb5c9c3d113187a1a8c2.png)
![\textbf{C}_{k} =
\textbf{M}_{k} [\textbf{M}_{k}+\textbf{Q}_{k}^{-1}]^{-1}](../I/m/baba972b698cfcfce00c6fdb6c3c52e9.png)


![\hat{\textbf{y}}_{k\mid k-1} =
\textbf{L}_{k} [\textbf{F}_{k}^{-1}]^{\text{T}}\hat{\textbf{y}}_{k-1\mid k-1}](../I/m/a3bc005ecceb1f0d83435ca25910deff.png)
Note that if F and Q are time invariant these values can be cached. Note also that F and Q need to be invertible.
Fixed-lag smoother
The optimal fixed-lag smoother provides the optimal estimate of  for a given fixed-lag
for a given fixed-lag 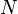 using the measurements from
using the measurements from 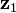 to
to 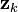 . It can be derived using the previous theory via an augmented state, and the main equation of the filter is the following:
. It can be derived using the previous theory via an augmented state, and the main equation of the filter is the following:
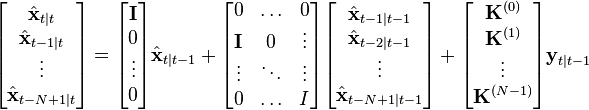
where:
-
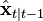 is estimated via a standard Kalman filter;
is estimated via a standard Kalman filter; -
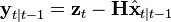 is the innovation produced considering the estimate of the standard Kalman filter;
is the innovation produced considering the estimate of the standard Kalman filter; - the various
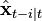 with
with  are new variables, i.e. they do not appear in the standard Kalman filter;
are new variables, i.e. they do not appear in the standard Kalman filter; - the gains are computed via the following scheme:
- and
- where
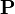 and
and  are the prediction error covariance and the gains of the standard Kalman filter (i.e.,
are the prediction error covariance and the gains of the standard Kalman filter (i.e., 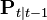 ).
).
![\textbf{K}^{(i)} =
\textbf{P}^{(i)} \textbf{H}^{T}
\left[
\textbf{H} \textbf{P} \textbf{H}^\mathrm{T} + \textbf{R}
\right]^{-1}](../I/m/9e2e6fb80d9f2c14825de3b0ce76c82a.png)
![\textbf{P}^{(i)} =
\textbf{P}
\left[
\left[
\textbf{F} - \textbf{K} \textbf{H}
\right]^{T}
\right]^{i}](../I/m/2a00ecadb4023fcc4909cea20e6cc0d5.png)
If the estimation error covariance is defined so that
![\textbf{P}_{i} :=
E
\left[
\left(
\textbf{x}_{t-i} - \hat{\textbf{x}}_{t-i\mid t}
\right)^{*}
\left(
\textbf{x}_{t-i} - \hat{\textbf{x}}_{t-i\mid t}
\right)
\mid
z_{1} \ldots z_{t}
\right],](../I/m/62a8e19824f7bf329964a9671350dac5.png)
then we have that the improvement on the estimation of 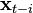 is given by:
is given by:
![\textbf{P}-\textbf{P}_{i} =
\sum_{j = 0}^{i}
\left[
\textbf{P}^{(j)} \textbf{H}^{T}
\left[
\textbf{H} \textbf{P} \textbf{H}^\mathrm{T} + \textbf{R}
\right]^{-1}
\textbf{H} \left( \textbf{P}^{(i)} \right)^\mathrm{T}
\right]](../I/m/5c2d9a72cd887cd3a5d66103a8852897.png)
Fixed-interval smoothers
The optimal fixed-interval smoother provides the optimal estimate of 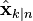 (
( ) using the measurements from a fixed interval to
) using the measurements from a fixed interval to 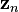 . This is also called "Kalman Smoothing". There are several smoothing algorithms in common use.
. This is also called "Kalman Smoothing". There are several smoothing algorithms in common use.
Rauch–Tung–Striebel
The Rauch–Tung–Striebel (RTS) smoother is an efficient two-pass algorithm for fixed interval smoothing.[27]
The forward pass is the same as the regular Kalman filter algorithm. These filtered a-priori and a-posteriori state estimates 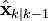 ,
,  and covariances
and covariances  ,
, 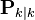 are saved for use in the backwards pass.
are saved for use in the backwards pass.
In the backwards pass, we compute the smoothed state estimates and covariances  . We start at the last time step and proceed backwards in time using the following recursive equations:
. We start at the last time step and proceed backwards in time using the following recursive equations:


where
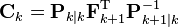 .
.
Note that 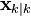 is the a-posteriori state estimate of timestep
is the a-posteriori state estimate of timestep  and
and 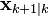 is the a-priori state estimate of timestep
is the a-priori state estimate of timestep 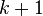 . The same notation applies to the covariance.
. The same notation applies to the covariance.
Modified Bryson–Frazier smoother
An alternative to the RTS algorithm is the modified Bryson–Frazier (MBF) fixed interval smoother developed by Bierman.[21] This also uses a backward pass that processes data saved from the Kalman filter forward pass. The equations for the backward pass involve the recursive computation of data which are used at each observation time to compute the smoothed state and covariance.
The recursive equations are
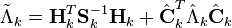


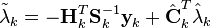


where 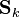 is the residual covariance and
is the residual covariance and 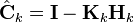 . The smoothed state and covariance can then be found by substitution in the equations
. The smoothed state and covariance can then be found by substitution in the equations
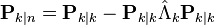

or
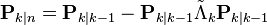

An important advantage of the MBF is that it does not require finding the inverse of the covariance matrix.
Minimum-variance smoother
The minimum-variance smoother can attain the best-possible error performance, provided that the models are linear, their parameters and the noise statistics are known precisely.[28] This smoother is a time-varying state-space generalization of the optimal non-causal Wiener filter.
The smoother calculations are done in two passes. The forward calculations involve a one-step-ahead predictor and are given by
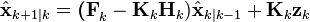

The above system is known as the inverse Wiener-Hopf factor. The backward recursion is the adjoint of the above forward system. The result of the backward pass 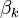 may be calculated by operating the forward equations on the time-reversed
may be calculated by operating the forward equations on the time-reversed 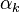 and time reversing the result. In the case of output estimation, the smoothed estimate is given by
and time reversing the result. In the case of output estimation, the smoothed estimate is given by
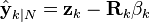
Taking the causal part of this minimum-variance smoother yields

which is identical to the minimum-variance Kalman filter. The above solutions minimize the variance of the output estimation error. Note that the Rauch–Tung–Striebel smoother derivation assumes that the underlying distributions are Gaussian, whereas the minimum-variance solutions do not. Optimal smoothers for state estimation and input estimation can be constructed similarly.
A continuous-time version of the above smoother is described in.[29][30]
Expectation-maximization algorithms may be employed to calculate approximate maximum likelihood estimates of unknown state-space parameters within minimum-variance filters and smoothers. Often uncertainties remain within problem assumptions. A smoother that accommodates uncertainties can be designed by adding a positive definite term to the Riccati equation.[31]
In cases where the models are nonlinear, step-wise linearizations may be within the minimum-variance filter and smoother recursions (extended Kalman filtering).
Accommodating Poisson noise
The Kalman filter is the optimum estimator from the set of all causal linear estimators when the underlying noise processes are zero-mean white processes. In some applications, the measurement noise may be Poisson-distributed. The filter recursions may be generalized to include a Poisson measurement noise component by adding the Poisson intensity 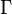 to the innovation (or residual) covariance:
to the innovation (or residual) covariance:

An expectation-maximization algorithm may be employed to iteratively estimate an unknown Poisson noise intensity.[32]
Frequency-weighted Kalman filters
Pioneering research on the perception of sounds at different frequencies was conducted by Fletcher and Munson in the 1930s. Their work led to a standard way of weighting measured sound levels within investigations of industrial noise and hearing loss. Frequency weightings have since been used within filter and controller designs to manage performance within bands of interest.
Typically, a frequency shaping function is used to weight the average power of the error spectral density in a specified frequency band. Let 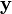 -
-  denote the output estimation error exhibited by a conventional Kalman filter. Also, let
denote the output estimation error exhibited by a conventional Kalman filter. Also, let 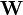 denote a causal frequency weighting transfer function. The optimum solution which minimizes the variance of ( - ) arises by simply constructing
denote a causal frequency weighting transfer function. The optimum solution which minimizes the variance of ( - ) arises by simply constructing 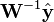 .
.
The design of remains an open question. One way of proceeding is to identify a system which generates the estimation error and setting equal to the inverse of that system.[33] This procedure may be iterated to obtain mean-square error improvement at the cost of increased filter order. The same technique can be applied to smoothers.
Non-linear filters
The basic Kalman filter is limited to a linear assumption. More complex systems, however, can be nonlinear. The non-linearity can be associated either with the process model or with the observation model or with both.
Extended Kalman filter
In the extended Kalman filter (EKF), the state transition and observation models need not be linear functions of the state but may instead be non-linear functions. These functions are of differentiable type.

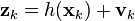
The function f can be used to compute the predicted state from the previous estimate and similarly the function h can be used to compute the predicted measurement from the predicted state. However, f and h cannot be applied to the covariance directly. Instead a matrix of partial derivatives (the Jacobian) is computed.
At each timestep the Jacobian is evaluated with current predicted states. These matrices can be used in the Kalman filter equations. This process essentially linearizes the non-linear function around the current estimate.
Unscented Kalman filter
When the state transition and observation models—that is, the predict and update functions 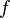 and
and  —are highly non-linear, the extended Kalman filter can give particularly poor performance.[34] This is because the covariance is propagated through linearization of the underlying non-linear model. The unscented Kalman filter (UKF) [34] uses a deterministic sampling technique known as the unscented transform to pick a minimal set of sample points (called sigma points) around the mean. These sigma points are then propagated through the non-linear functions, from which the mean and covariance of the estimate are then recovered. The result is a filter which more accurately captures the true mean and covariance. (This can be verified using Monte Carlo sampling or through a Taylor series expansion of the posterior statistics.) In addition, this technique removes the requirement to explicitly calculate Jacobians, which for complex functions can be a difficult task in itself (i.e., requiring complicated derivatives if done analytically or being computationally costly if done numerically).
—are highly non-linear, the extended Kalman filter can give particularly poor performance.[34] This is because the covariance is propagated through linearization of the underlying non-linear model. The unscented Kalman filter (UKF) [34] uses a deterministic sampling technique known as the unscented transform to pick a minimal set of sample points (called sigma points) around the mean. These sigma points are then propagated through the non-linear functions, from which the mean and covariance of the estimate are then recovered. The result is a filter which more accurately captures the true mean and covariance. (This can be verified using Monte Carlo sampling or through a Taylor series expansion of the posterior statistics.) In addition, this technique removes the requirement to explicitly calculate Jacobians, which for complex functions can be a difficult task in itself (i.e., requiring complicated derivatives if done analytically or being computationally costly if done numerically).
- Predict
As with the EKF, the UKF prediction can be used independently from the UKF update, in combination with a linear (or indeed EKF) update, or vice versa.
The estimated state and covariance are augmented with the mean and covariance of the process noise.
![\textbf{x}_{k-1\mid k-1}^{a} = [ \hat{\textbf{x}}_{k-1\mid k-1}^\mathrm{T} \quad E[\textbf{w}_{k}^\mathrm{T}] \ ]^\mathrm{T}](../I/m/8d1e669dd983c763464a45fff2ab356e.png)
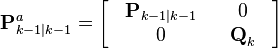
A set of 2L + 1 sigma points is derived from the augmented state and covariance where L is the dimension of the augmented state.
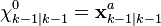
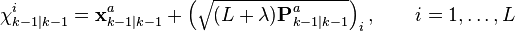
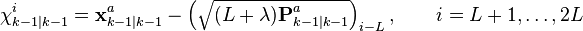
where

is the ith column of the matrix square root of
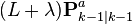
using the definition: square root  of matrix
of matrix  satisfies
satisfies
The matrix square root should be calculated using numerically efficient and stable methods such as the Cholesky decomposition.
The sigma points are propagated through the transition function f.
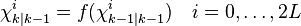
where 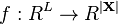 . The weighted sigma points are recombined to produce the predicted state and covariance.
. The weighted sigma points are recombined to produce the predicted state and covariance.
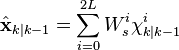
![\textbf{P}_{k\mid k-1} = \sum_{i=0}^{2L} W_{c}^{i}\ [\chi_{k\mid k-1}^{i} - \hat{\textbf{x}}_{k\mid k-1}] [\chi_{k\mid k-1}^{i} - \hat{\textbf{x}}_{k\mid k-1}]^\mathrm{T}](../I/m/bef2e676f6d04fe19ade12cd94c919fb.png)
where the weights for the state and covariance are given by:
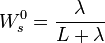
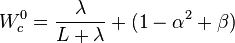
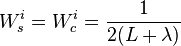
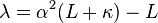
 and
and 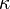 control the spread of the sigma points.
control the spread of the sigma points. 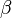 is related to the distribution of
is related to the distribution of  .
Normal values are
.
Normal values are 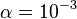 ,
, 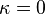 and
and 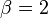 . If the true distribution of is Gaussian, is optimal.[35]
. If the true distribution of is Gaussian, is optimal.[35]
- Update
The predicted state and covariance are augmented as before, except now with the mean and covariance of the measurement noise.
![\textbf{x}_{k\mid k-1}^{a} = [ \hat{\textbf{x}}_{k\mid k-1}^\mathrm{T} \quad E[\textbf{v}_{k}^\mathrm{T}] \ ]^\mathrm{T}](../I/m/0995fe0f1b04fdd74be8f382d24578df.png)
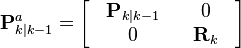
As before, a set of 2L + 1 sigma points is derived from the augmented state and covariance where L is the dimension of the augmented state.
![\begin{align}
\chi_{k\mid k-1}^{0} & = \textbf{x}_{k\mid k-1}^{a} \\[6pt]
\chi_{k\mid k-1}^{i} & = \textbf{x}_{k\mid k-1}^{a} + \left ( \sqrt{ (L + \lambda) \textbf{P}_{k\mid k-1}^{a} } \right )_{i}, \qquad i = 1,\dots,L \\[6pt]
\chi_{k\mid k-1}^{i} & = \textbf{x}_{k\mid k-1}^{a} - \left ( \sqrt{ (L + \lambda) \textbf{P}_{k\mid k-1}^{a} } \right )_{i-L}, \qquad i = L+1,\dots,2L
\end{align}](../I/m/bd992011a0b8fd79ab4eb08699bc26c4.png)
Alternatively if the UKF prediction has been used the sigma points themselves can be augmented along the following lines
![\chi_{k\mid k-1} := [ \chi_{k\mid k-1}^\mathrm{T} \quad E[\textbf{v}_{k}^\mathrm{T}] \ ]^\mathrm{T} \pm \sqrt{ (L + \lambda) \textbf{R}_{k}^{a} }](../I/m/513b7fe41c68d1e6a928274c8b3aad44.png)
where
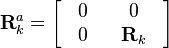
The sigma points are projected through the observation function h.
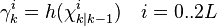
The weighted sigma points are recombined to produce the predicted measurement and predicted measurement covariance.
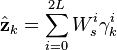
![\textbf{P}_{z_{k}z_{k}} = \sum_{i=0}^{2L} W_{c}^{i}\ [\gamma_{k}^{i} - \hat{\textbf{z}}_{k}] [\gamma_{k}^{i} - \hat{\textbf{z}}_{k}]^\mathrm{T}](../I/m/5a45ba322e8fdf3bf7b831676b1cb3cb.png)
The state-measurement cross-covariance matrix,
![\textbf{P}_{x_{k}z_{k}} = \sum_{i=0}^{2L} W_{c}^{i}\ [\chi_{k\mid k-1}^{i} - \hat{\textbf{x}}_{k\mid k-1}] [\gamma_{k}^{i} - \hat{\textbf{z}}_{k}]^\mathrm{T}](../I/m/a0dac7bc3858b91539a9b29ae4428695.png)
is used to compute the UKF Kalman gain.

As with the Kalman filter, the updated state is the predicted state plus the innovation weighted by the Kalman gain,
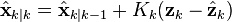
And the updated covariance is the predicted covariance, minus the predicted measurement covariance, weighted by the Kalman gain.
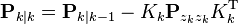
Kalman–Bucy filter
The Kalman–Bucy filter (named after Richard Snowden Bucy) is a continuous time version of the Kalman filter.[36][37]
It is based on the state space model
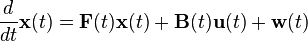
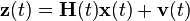
where  and
and  represent the intensities of the two white noise terms
represent the intensities of the two white noise terms 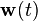 and
and 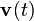 , respectively.
, respectively.
The filter consists of two differential equations, one for the state estimate and one for the covariance:
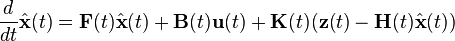
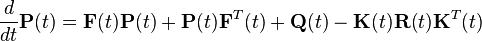
where the Kalman gain is given by
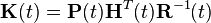
Note that in this expression for 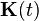 the covariance of the observation noise represents at the same time the covariance of the prediction error (or innovation)
the covariance of the observation noise represents at the same time the covariance of the prediction error (or innovation)  ; these covariances are equal only in the case of continuous time.[38]
; these covariances are equal only in the case of continuous time.[38]
The distinction between the prediction and update steps of discrete-time Kalman filtering does not exist in continuous time.
The second differential equation, for the covariance, is an example of a Riccati equation.
Hybrid Kalman filter
Most physical systems are represented as continuous-time models while discrete-time measurements are frequently taken for state estimation via a digital processor. Therefore, the system model and measurement model are given by
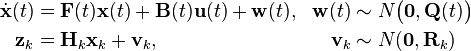
where
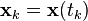 .
.
- Initialize
![\hat{\mathbf{x}}_{0\mid 0}=E\bigl[\mathbf{x}(t_0)\bigr], \mathbf{P}_{0\mid 0}=Var\bigl[\mathbf{x}(t_0)\bigr]](../I/m/08ead48e80d8cdc6dcc627fdaa7a87c5.png)
- Predict
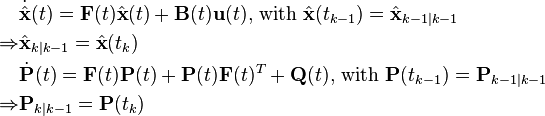
The prediction equations are derived from those of continuous-time Kalman filter without update from measurements, i.e., 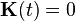 . The predicted state and covariance are calculated respectively by solving a set of differential equations with the initial value equal to the estimate at the previous step.
. The predicted state and covariance are calculated respectively by solving a set of differential equations with the initial value equal to the estimate at the previous step.
- Update

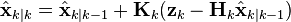
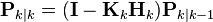
The update equations are identical to those of the discrete-time Kalman filter.
Variants for the recovery of sparse signals
The traditional Kalman filter has also been employed for the recovery of sparse, possibly dynamic, signals from noisy observations. Recent works[39][40][41] utilize notions from the theory of compressed sensing/sampling, such as the restricted isometry property and related probabilistic recovery arguments, for sequentially estimating the sparse state in intrinsically low-dimensional systems.
Applications
- Attitude and heading reference systems
- Autopilot
- Battery state of charge (SoC) estimation[42][43]
- Brain-computer interface
- Chaotic signals
- Tracking and vertex fitting of charged particles in particle detectors[44]
- Tracking of objects in computer vision
- Dynamic positioning
- Economics, in particular macroeconomics, time series analysis, and econometrics[45]
- Inertial guidance system
- Nuclear medicine – single photon emission computed tomography image restoration[46]
- Orbit Determination
- Power system state estimation
- Radar tracker
- Satellite navigation systems
- Seismology[47]
- Sensorless control of AC motor variable-frequency drives
- Simultaneous localization and mapping
- Speech enhancement
- Visual odometry
- Weather forecasting
- Navigation system
- 3D modeling
- Structural health monitoring
- Human sensorimotor processing[48]
See also
- Alpha beta filter
- Bayesian MMSE estimator
- Covariance intersection
- Data assimilation
- Ensemble Kalman filter
- Extended Kalman filter
- Fast Kalman filter
- Filtering problem (stochastic processes)
- Generalized filtering
- Invariant extended Kalman filter
- Kernel adaptive filter
- Linear-quadratic-Gaussian control
- Moving horizon estimation
- Non-linear filter
- Particle filter estimator
- Predictor corrector
- Recursive least squares
- Schmidt–Kalman filter
- Separation principle
- Sliding mode control
- Stochastic differential equations
- Volterra series
- Wiener filter
- Zakai equation
References
- ↑ Wolpert, Daniel; Ghahramani, Zoubin (2000). "Computational principles of movement neuroscience". Nature Neuroscience 3: 1212–7. doi:10.1038/81497. PMID 11127840.
- ↑ Kalman, R. E. (1960). "A New Approach to Linear Filtering and Prediction Problems". Journal of Basic Engineering 82: 35. doi:10.1115/1.3662552.
- ↑ Steffen L. Lauritzen. "Time series analysis in 1880. A discussion of contributions made by T.N. Thiele". International Statistical Review 49, 1981, 319–333. JSTOR 1402616
- ↑ Steffen L. Lauritzen, Thiele: Pioneer in Statistics, Oxford University Press, 2002. ISBN 0-19-850972-3.
- ↑ Mohinder S. Grewal and Angus P. Andrews
- ↑ Stratonovich, R. L. (1959). Optimum nonlinear systems which bring about a separation of a signal with constant parameters from noise. Radiofizika, 2:6, pp. 892–901.
- ↑ Stratonovich, R. L. (1959). On the theory of optimal non-linear filtering of random functions. Theory of Probability and its Applications, 4, pp. 223–225.
- ↑ Stratonovich, R. L. (1960) Application of the Markov processes theory to optimal filtering. Radio Engineering and Electronic Physics, 5:11, pp. 1–19.
- ↑ Stratonovich, R. L. (1960). Conditional Markov Processes. Theory of Probability and its Applications, 5, pp. 156–178.
- ↑ Ingvar Strid; Karl Walentin (April 2009). "Block Kalman Filtering for Large-Scale DSGE Models". Computational Economics (Springer) 33 (3): 277–304. doi:10.1007/s10614-008-9160-4.
- ↑ Martin Møller Andreasen (2008). "Non-linear DSGE Models, The Central Difference Kalman Filter, and The Mean Shifted Particle Filter" (PDF).
- ↑ Roweis, S; Ghahramani, Z (1999). "A unifying review of linear gaussian models". Neural computation 11 (2): 305–45. doi:10.1162/089976699300016674. PMID 9950734.
- ↑ Hamilton, J. (1994), Time Series Analysis, Princeton University Press. Chapter 13, 'The Kalman Filter'.
- ↑ Ishihara, J.Y.; Terra, M.H.; Campos, J.C.T. (2006). "Robust Kalman Filter for Descriptor Systems". IEEE Transactions on Automatic Control 51 (8): 1354. doi:10.1109/TAC.2006.878741.
- ↑ Terra, Marco H.; Cerri, Joao P.; Ishihara, Joao Y. (2014). "Optimal Robust Linear Quadratic Regulator for Systems Subject to Uncertainties". IEEE Transactions on Automatic Control 59 (9): 2586–2591. doi:10.1109/TAC.2014.2309282.
- ↑ Kelly, Alonzo (1994). "A 3D state space formulation of a navigation Kalman filter for autonomous vehicles" (PDF). DTIC Document: 13. 2006 Corrected Version
- ↑ Reid, Ian; Term, Hilary. "Estimation II" (PDF). www.robots.ox.ac.uk. Oxford University. Retrieved 6 August 2014.
- ↑ Three optimality tests with numerical examples are described in Peter, Matisko, (2012). "Optimality Tests and Adaptive Kalman Filter". 16th IFAC Symposium on System Identification. 16th IFAC Symposium on System Identification. p. 1523. doi:10.3182/20120711-3-BE-2027.00011. ISBN 978-3-902823-06-9.
- ↑ Anderson, Brian D. O.; Moore, John B. (1979). Optimal Filtering. New York: Prentice Hall. pp. 129–133. ISBN 0-13-638122-7.
- 1 2 Thornton, Catherine L. (15 October 1976). "Triangular Covariance Factorizations for Kalman Filtering" (PDF). (PhD thesis). NASA. NASA Technical Memorandum 33-798.
- 1 2 3 Bierman, G.J. (1977). "Factorization Methods for Discrete Sequential Estimation". Factorization Methods for Discrete Sequential Estimation (Academic Press). Bibcode:1977fmds.book.....B.
- 1 2 Bar-Shalom, Yaakov; Li, X. Rong; Kirubarajan, Thiagalingam (July 2001). Estimation with Applications to Tracking and Navigation. New York: John Wiley & Sons. pp. 308–317. ISBN 978-0-471-41655-5.
- ↑ Golub, Gene H.; Van Loan, Charles F. (1996). Matrix Computations. Johns Hopkins Studies in the Mathematical Sciences (Third ed.). Baltimore, Maryland: Johns Hopkins University. p. 139. ISBN 978-0-8018-5414-9.
- ↑ Higham, Nicholas J. (2002). Accuracy and Stability of Numerical Algorithms (Second ed.). Philadelphia, PA: Society for Industrial and Applied Mathematics. p. 680. ISBN 978-0-89871-521-7.
- ↑ Masreliez, C. Johan; Martin, R D (1977). "Robust Bayesian estimation for the linear model and robustifying the Kalman filter". IEEE Transactions on Automatic Control 22 (3): 361–371. doi:10.1109/TAC.1977.1101538.
- ↑ Lütkepohl, Helmut (1991). Introduction to Multiple Time Series Analysis. Heidelberg: Springer-Verlag Berlin,. p. 435.
- ↑ Rauch, H.E.; Tung, F.; Striebel, C. T. (August 1965). "Maximum likelihood estimates of linear dynamic systems". AIAA J 3 (8): 1445–1450. Bibcode:1965AIAAJ...3.1445. doi:10.2514/3.3166.
- ↑ Einicke, G.A. (March 2006). "Optimal and Robust Noncausal Filter Formulations". IEEE Trans. Signal Processing 54 (3): 1069–1077. Bibcode:2006ITSP...54.1069E. doi:10.1109/TSP.2005.863042.
- ↑ Einicke, G.A. (April 2007). "Asymptotic Optimality of the Minimum-Variance Fixed-Interval Smoother". IEEE Trans. Signal Processing 55 (4): 1543–1547. Bibcode:2007ITSP...55.1543E. doi:10.1109/TSP.2006.889402.
- ↑ Einicke, G.A.; Ralston, J.C.; Hargrave, C.O.; Reid, D.C.; Hainsworth, D.W. (December 2008). "Longwall Mining Automation. An Application of Minimum-Variance Smoothing". IEEE Control Systems Magazine 28 (6): 28–37. doi:10.1109/MCS.2008.929281.
- ↑ Einicke, G.A. (December 2009). "Asymptotic Optimality of the Minimum-Variance Fixed-Interval Smoother". IEEE Trans. Automatic Control 54 (12): 2904–2908. Bibcode:2007ITSP...55.1543E. doi:10.1109/TSP.2006.889402.
- ↑ Einicke, G.A. (July 2015). "Iterative Filtering and Smoothing of Measurements Possessing Poisson Measurement Noise". IEEE Transactions on Aerospace and Electronic Systems 51 (3): 2205–2211. doi:10.1109/TAES.2015.140843.
- ↑ Einicke, G.A. (December 2014). "Iterative Frequency-Weighted Filtering and Smoothing Procedures". IEEE Signal Processing Letters 21 (12): 1467–1470. doi:10.1109/LSP.2014.2341641.
- 1 2 Julier, Simon J.; Uhlmann, Jeffrey K. (1997). "A new extension of the Kalman filter to nonlinear systems" (PDF). Int. Symp. Aerospace/Defense Sensing, Simul. and Controls. Signal Processing, Sensor Fusion, and Target Recognition VI 3: 182. Bibcode:1997SPIE.3068..182J. doi:10.1117/12.280797. Retrieved 2008-05-03.
- ↑ Wan, E.A.; Van Der Merwe, R. (2000). "The unscented Kalman filter for nonlinear estimation". Proceedings of the IEEE 2000 Adaptive Systems for Signal Processing, Communications, and Control Symposium (Cat. No.00EX373) (PDF). p. 153. doi:10.1109/ASSPCC.2000.882463. ISBN 0-7803-5800-7.
- ↑ Bucy, R.S. and Joseph, P.D., Filtering for Stochastic Processes with Applications to Guidance, John Wiley & Sons, 1968; 2nd Edition, AMS Chelsea Publ., 2005. ISBN 0-8218-3782-6
- ↑ Jazwinski, Andrew H., Stochastic processes and filtering theory, Academic Press, New York, 1970. ISBN 0-12-381550-9
- ↑ Kailath, T. (1968). "An innovations approach to least-squares estimation--Part I: Linear filtering in additive white noise". IEEE Transactions on Automatic Control 13 (6): 646–655. doi:10.1109/TAC.1968.1099025.
- ↑ Vaswani, Namrata (2008). "Kalman filtered Compressed Sensing". 2008 15th IEEE International Conference on Image Processing. p. 893. doi:10.1109/ICIP.2008.4711899. ISBN 978-1-4244-1765-0.
- ↑ Carmi, Avishy; Gurfil, Pini; Kanevsky, Dimitri (2010). "Methods for sparse signal recovery using Kalman filtering with embedded pseudo-measurement norms and quasi-norms". IEEE Transactions on Signal Processing 58 (4): 2405–2409. Bibcode:2010ITSP...58.2405C. doi:10.1109/TSP.2009.2038959.
- ↑ Zachariah, Dave; Chatterjee, Saikat; Jansson, Magnus (2012). "Dynamic Iterative Pursuit". IEEE Transactions on Signal Processing 60 (9): 4967–4972. doi:10.1109/TSP.2012.2203813.
- ↑ Vasebi, Amir; Partovibakhsh, Maral; Bathaee, S. Mohammad Taghi (2007). "A novel combined battery model for state-of-charge estimation in lead-acid batteries based on extended Kalman filter for hybrid electric vehicle applications". Journal of Power Sources 174: 30–40. doi:10.1016/j.jpowsour.2007.04.011.
- ↑ Vasebi, A.; Bathaee, S.M.T.; Partovibakhsh, M. (2008). "Predicting state of charge of lead-acid batteries for hybrid electric vehicles by extended Kalman filter". Energy Conversion and Management 49: 75–82. doi:10.1016/j.enconman.2007.05.017.
- ↑ Fruhwirth, R. (1987). "Application of Kalman filtering to track and vertex fitting". Nucl. Instrum. Meth. A262 (2–3): 444–450. Bibcode:1987NIMPA.262..444F. doi:10.1016/0168-9002(87)90887-4.
- ↑ Harvey, Andrew C. (1994). "Applications of the Kalman filter in econometrics". In Bewley, Truman. Advances in Econometrics. New York: Cambridge University Press. pp. 285f. ISBN 0-521-46726-8.
- ↑ D. Boulfelfel, R.M. Rangayyan, L.J. Hahn, R. Kloiber, and G.R. Kuduvalli (1994). "Restoration of single photon emission computed tomography images by the Kalman filter". IEEE Transactions on Medical Imaging 13(1): 102–109
- ↑ Bock, Y.; Crowell, B.; Webb, F.; Kedar, S.; Clayton, R.; Miyahara, B. (2008). "Fusion of High-Rate GPS and Seismic Data: Applications to Early Warning Systems for Mitigation of Geological Hazards". American Geophysical Union 43: 01. Bibcode:2008AGUFM.G43B..01B.
- ↑ Wolpert, D. M.; Miall, R. C. (1996). "Forward Models for Physiological Motor Control". Neural Netw. 9 (8): 1265–1279. doi:10.1016/S0893-6080(96)00035-4. PMID 12662535.
Further reading
- Einicke, G.A. (2012). Smoothing, Filtering and Prediction: Estimating the Past, Present and Future. Rijeka, Croatia: Intech. ISBN 978-953-307-752-9.
- Jinya Su; Baibing Li; Wen-Hua Chen (2015). "On existence, optimality and asymptotic stability of the Kalman filter with partially observed inputs". Automatica 53: 149–154. doi:10.1016/j.automatica.2014.12.044.
- Gelb, A. (1974). Applied Optimal Estimation. MIT Press.
- Kalman, R.E. (1960). "A new approach to linear filtering and prediction problems" (PDF). Journal of Basic Engineering 82 (1): 35–45. doi:10.1115/1.3662552. Retrieved 2008-05-03.
- Kalman, R.E.; Bucy, R.S. (1961). "New Results in Linear Filtering and Prediction Theory". Retrieved 2008-05-03.
- Harvey, A.C. (1990). Forecasting, Structural Time Series Models and the Kalman Filter. Cambridge University Press.
- Roweis, S.; Ghahramani, Z. (1999). "A Unifying Review of Linear Gaussian Models". Neural Computation 11 (2): 305–345. doi:10.1162/089976699300016674. PMID 9950734.
- Simon, D. (2006). Optimal State Estimation: Kalman, H Infinity, and Nonlinear Approaches. Wiley-Interscience.
- Stengel, R.F. (1994). Optimal Control and Estimation. Dover Publications. ISBN 0-486-68200-5.
- Warwick, K. (1987). "Optimal observers for ARMA models" (PDF). International Journal of Control 46 (5): 1493–1503. doi:10.1080/00207178708933989. Retrieved 2008-05-03.
- Bierman, G.J. (1977). Factorization Methods for Discrete Sequential Estimation. Mathematics in Science and Engineering 128 (Mineola, N.Y.: Dover Publications). ISBN 978-0-486-44981-4.
- Bozic, S.M. (1994). Digital and Kalman filtering. Butterworth–Heinemann.
- Haykin, S. (2002). Adaptive Filter Theory. Prentice Hall.
- Liu, W.; Principe, J.C. and Haykin, S. (2010). Kernel Adaptive Filtering: A Comprehensive Introduction. John Wiley.
- Manolakis, D.G. (1999). Statistical and Adaptive signal processing. Artech House.
- Welch, Greg; Bishop, Gary (1997). "SCAAT: incremental tracking with incomplete information" (PDF). SIGGRAPH '97 Proceedings of the 24th annual conference on Computer graphics and interactive techniques. ACM Press/Addison-Wesley Publishing Co. pp. 333–344. doi:10.1145/258734.258876. ISBN 0-89791-896-7.
- Jazwinski, Andrew H. (1970). Stochastic Processes and Filtering. Mathematics in Science and Engineering. New York: Academic Press. p. 376. ISBN 0-12-381550-9.
- Maybeck, Peter S. (1979). Stochastic Models, Estimation, and Control. Mathematics in Science and Engineering. 141-1. New York: Academic Press. p. 423. ISBN 0-12-480701-1.
- Moriya, N. (2011). Primer to Kalman Filtering: A Physicist Perspective. New York: Nova Science Publishers, Inc. ISBN 978-1-61668-311-5.
- Dunik, J.; Simandl M.; Straka O. (2009). "Methods for estimating state and measurement noise covariance matrices: Aspects and comparisons". Proceedings of 15th IFAC Symposium on System Identification (France): 372–377.
- Chui, Charles K.; Chen, Guanrong (2009). Kalman Filtering with Real-Time Applications. Springer Series in Information Sciences 17 (4th ed.). New York: Springer. p. 229. ISBN 978-3-540-87848-3.
- Spivey, Ben; Hedengren, J. D. and Edgar, T. F. (2010). "Constrained Nonlinear Estimation for Industrial Process Fouling". Industrial & Engineering Chemistry Research 49 (17): 7824–7831. doi:10.1021/ie9018116.
- Thomas Kailath; Ali H. Sayed; Babak Hassibi (2000). Linear Estimation. NJ: Prentice–Hall. ISBN 978-0-13-022464-4.
- Ali H. Sayed (2008). Adaptive Filters. NJ: Wiley. ISBN 978-0-470-25388-5.
External links
- A New Approach to Linear Filtering and Prediction Problems, by R. E. Kalman, 1960
- Kalman–Bucy Filter, a good derivation of the Kalman–Bucy Filter
- MIT Video Lecture on the Kalman filter on YouTube
- An Introduction to the Kalman Filter, SIGGRAPH 2001 Course, Greg Welch and Gary Bishop
- Kalman filtering chapter from Stochastic Models, Estimation, and Control, vol. 1, by Peter S. Maybeck
- Kalman Filter webpage, with lots of links
- "Kalman Filtering". Archived from the original on 2013-06-23.
- Kalman Filters, thorough introduction to several types, together with applications to Robot Localization
- Kalman filters used in Weather models, SIAM News, Volume 36, Number 8, October 2003.
- Critical Evaluation of Extended Kalman Filtering and Moving-Horizon Estimation, Ind. Eng. Chem. Res., 44 (8), 2451–2460, 2005.
- Kalman and Bayesian Filters in Python Free book on Kalman Filtering implemented in IPython Notebook.
- Source code for the propeller microprocessor: Well documented source code written for the Parallax propeller processor.
- Gerald J. Bierman's Estimation Subroutine Library: Corresponds to the code in the research monograph "Factorization Methods for Discrete Sequential Estimation" originally published by Academic Press in 1977. Republished by Dover.
- Matlab Toolbox implementing parts of Gerald J. Bierman's Estimation Subroutine Library: UD / UDU' and LD / LDL' factorization with associated time and measurement updates making up the Kalman filter.
- Matlab Toolbox of Kalman Filtering applied to Simultaneous Localization and Mapping: Vehicle moving in 1D, 2D and 3D
- Derivation of a 6D EKF solution to Simultaneous Localization and Mapping (In old version PDF). See also the tutorial on implementing a Kalman Filter with the MRPT C++ libraries.
- The Kalman Filter Explained A very simple tutorial.
- The Kalman Filter in Reproducing Kernel Hilbert Spaces A comprehensive introduction.
- Matlab code to estimate Cox–Ingersoll–Ross interest rate model with Kalman Filter: Corresponds to the paper "estimating and testing exponential-affine term structure models by kalman filter" published by Review of Quantitative Finance and Accounting in 1999.
- Extended Kalman Filters explained in the context of Simulation, Estimation, Control, and Optimization
- Online demo of the Kalman Filter. Demonstration of Kalman Filter (and other data assimilation methods) using twin experiments.
- Botella, Guillermo; Martín h., José Antonio; Santos, Matilde; Meyer-Baese, Uwe (2011). "FPGA-Based Multimodal Embedded Sensor System Integrating Low- and Mid-Level Vision". Sensors 11 (12): 1251–1259. doi:10.3390/s110808164.
- Hookes Law and the Kalman Filter A little "spring theory" emphasizing the connection between statistics and physics.
- Examples and how-to on using Kalman Filters with MATLAB A Tutorial on Filtering and Estimation
- Explaining Filtering (Estimation) in One Hour, Ten Minutes, One Minute, and One Sentence by Yu-Chi Ho
|