Natural deduction
In logic and proof theory, natural deduction is a kind of proof calculus in which logical reasoning is expressed by inference rules closely related to the "natural" way of reasoning. This contrasts with the axiomatic systems which instead use axioms as much as possible to express the logical laws of deductive reasoning.
Motivation
Natural deduction grew out of a context of dissatisfaction with the axiomatizations of deductive reasoning common to the systems of Hilbert, Frege, and Russell (see, e.g., Hilbert system). Such axiomatizations were most famously used by Russell and Whitehead in their mathematical treatise Principia Mathematica. Spurred on by a series of seminars in Poland in 1926 by Łukasiewicz that advocated a more natural treatment of logic, Jaśkowski made the earliest attempts at defining a more natural deduction, first in 1929 using a diagrammatic notation, and later updating his proposal in a sequence of papers in 1934 and 1935.[1] His proposals led to different notations such as Fitch-style calculus (or Fitch's diagrams) or Suppes' method of which e.g. Lemmon gave a variant called system L.
Natural deduction in its modern form was independently proposed by the German mathematician Gentzen in 1934, in a dissertation delivered to the faculty of mathematical sciences of the University of Göttingen.[2] The term natural deduction (or rather, its German equivalent natürliches Schließen) was coined in that paper:
Ich wollte nun zunächst einmal einen Formalismus aufstellen, der dem wirklichen Schließen möglichst nahe kommt. So ergab sich ein "Kalkül des natürlichen Schließens".[3]
(First I wished to construct a formalism that comes as close as possible to actual reasoning. Thus arose a "calculus of natural deduction".)
Gentzen was motivated by a desire to establish the consistency of number theory. He was unable to prove the main result required for the consistency result, the cut elimination theorem — the Hauptsatz — directly for Natural Deduction. For this reason he introduced his alternative system, the sequent calculus, for which he proved the Hauptsatz both for classical and intuitionistic logic. In a series of seminars in 1961 and 1962 Prawitz gave a comprehensive summary of natural deduction calculi, and transported much of Gentzen's work with sequent calculi into the natural deduction framework. His 1965 monograph Natural deduction: a proof-theoretical study[4] was to become a reference work on natural deduction, and included applications for modal and second-order logic.
In natural deduction, a proposition is deduced from a collection of premises by applying inference rules repeatedly. The system presented in this article is a minor variation of Gentzen's or Prawitz's formulation, but with a closer adherence to Martin-Löf's description of logical judgments and connectives.[5]
Judgments and propositions
A judgment is something that is knowable, that is, an object of knowledge. It is evident if one in fact knows it.[6] Thus "it is raining" is a judgment, which is evident for the one who knows that it is actually raining; in this case one may readily find evidence for the judgment by looking outside the window or stepping out of the house. In mathematical logic however, evidence is often not as directly observable, but rather deduced from more basic evident judgments. The process of deduction is what constitutes a proof; in other words, a judgment is evident if one has a proof for it.
The most important judgments in logic are of the form "A is true". The letter A stands for any expression representing a proposition; the truth judgments thus require a more primitive judgment: "A is a proposition". Many other judgments have been studied; for example, "A is false" (see classical logic), "A is true at time t" (see temporal logic), "A is necessarily true" or "A is possibly true" (see modal logic), "the program M has type τ" (see programming languages and type theory), "A is achievable from the available resources" (see linear logic), and many others. To start with, we shall concern ourselves with the simplest two judgments "A is a proposition" and "A is true", abbreviated as "A prop" and "A true" respectively.
The judgment "A prop" defines the structure of valid proofs of A, which in turn defines the structure of propositions. For this reason, the inference rules for this judgment are sometimes known as formation rules. To illustrate, if we have two propositions A and B (that is, the judgments "A prop" and "B prop" are evident), then we form the compound proposition A and B, written symbolically as " ". We can write this in the form of an inference rule:
". We can write this in the form of an inference rule:
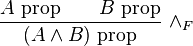
where the parentheses are omitted to make the inference rule more succinct:
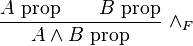
This inference rule is schematic: A and B can be instantiated with any expression. The general form of an inference rule is:
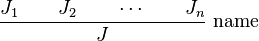
where each  is a judgment and the inference rule is named "name". The judgments above the line are known as premises, and those below the line are conclusions. Other common logical propositions are disjunction (
is a judgment and the inference rule is named "name". The judgments above the line are known as premises, and those below the line are conclusions. Other common logical propositions are disjunction (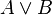 ), negation (
), negation ( ), implication (
), implication (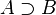 ), and the logical constants truth (
), and the logical constants truth ( ) and falsehood (
) and falsehood (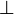 ). Their formation rules are below.
). Their formation rules are below.
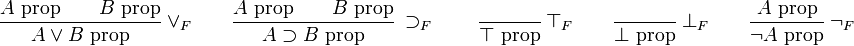
Introduction and elimination
Now we discuss the "A true" judgment. Inference rules that introduce a logical connective in the conclusion are known as introduction rules. To introduce conjunctions, i.e., to conclude "A and B true" for propositions A and B, one requires evidence for "A true" and "B true". As an inference rule:
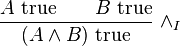
It must be understood that in such rules the objects are propositions. That is, the above rule is really an abbreviation for:
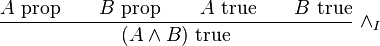
This can also be written:
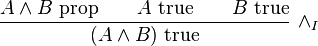
In this form, the first premise can be satisfied by the 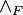 formation rule, giving the first two premises of the previous form. In this article we shall elide the "prop" judgments where they are understood. In the nullary case, one can derive truth from no premises.
formation rule, giving the first two premises of the previous form. In this article we shall elide the "prop" judgments where they are understood. In the nullary case, one can derive truth from no premises.
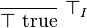
If the truth of a proposition can be established in more than one way, the corresponding connective has multiple introduction rules.

Note that in the nullary case, i.e., for falsehood, there are no introduction rules. Thus one can never infer falsehood from simpler judgments.
Dual to introduction rules are elimination rules to describe how to de-construct information about a compound proposition into information about its constituents. Thus, from "A ∧ B true", we can conclude "A true" and "B true":

As an example of the use of inference rules, consider commutativity of conjunction. If A ∧ B is true, then B ∧ A is true; This derivation can be drawn by composing inference rules in such a fashion that premises of a lower inference match the conclusion of the next higher inference.
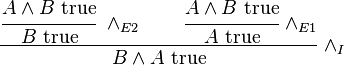
The inference figures we have seen so far are not sufficient to state the rules of implication introduction or disjunction elimination; for these, we need a more general notion of hypothetical derivation.
Hypothetical derivations
A pervasive operation in mathematical logic is reasoning from assumptions. For example, consider the following derivation:
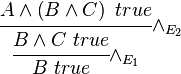
This derivation does not establish the truth of B as such; rather, it establishes the following fact:
- If A ∧ (B ∧ C) is true then B is true.
In logic, one says "assuming A ∧ (B ∧ C) is true, we show that B is true"; in other words, the judgment "B true" depends on the assumed judgment "A ∧ (B ∧ C) true". This is a hypothetical derivation, which we write as follows:
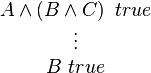
The interpretation is: "B true is derivable from A ∧ (B ∧ C) true". Of course, in this specific example we actually know the derivation of "B true" from "A ∧ (B ∧ C) true", but in general we may not a-priori know the derivation. The general form of a hypothetical derivation is:
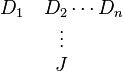
Each hypothetical derivation has a collection of antecedent derivations (the Di) written on the top line, and a succedent judgment (J) written on the bottom line. Each of the premises may itself be a hypothetical derivation. (For simplicity, we treat a judgment as a premise-less derivation.)
The notion of hypothetical judgment is internalised as the connective of implication. The introduction and elimination rules are as follows.
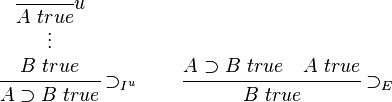
In the introduction rule, the antecedent named u is discharged in the conclusion. This is a mechanism for delimiting the scope of the hypothesis: its sole reason for existence is to establish "B true"; it cannot be used for any other purpose, and in particular, it cannot be used below the introduction. As an example, consider the derivation of "A ⊃ (B ⊃ (A ∧ B)) true":
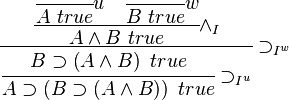
This full derivation has no unsatisfied premises; however, sub-derivations are hypothetical. For instance, the derivation of "B ⊃ (A ∧ B) true" is hypothetical with antecedent "A true" (named u).
With hypothetical derivations, we can now write the elimination rule for disjunction:
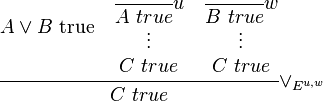
In words, if A ∨ B is true, and we can derive C true both from A true and from B true, then C is indeed true. Note that this rule does not commit to either A true or B true. In the zero-ary case, i.e. for falsehood, we obtain the following elimination rule:
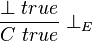
This is read as: if falsehood is true, then any proposition C is true.
Negation is similar to implication.
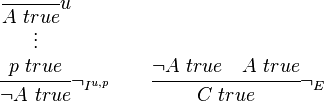
The introduction rule discharges both the name of the hypothesis u, and the succedent p, i.e., the proposition p must not occur in the conclusion A. Since these rules are schematic, the interpretation of the introduction rule is: if from "A true" we can derive for every proposition p that "p true", then A must be false, i.e., "not A true". For the elimination, if both A and not A are shown to be true, then there is a contradiction, in which case every proposition C is true. Because the rules for implication and negation are so similar, it should be fairly easy to see that not A and A ⊃ ⊥ are equivalent, i.e., each is derivable from the other.
Consistency, completeness, and normal forms
A theory is said to be consistent if falsehood is not provable (from no assumptions) and is complete if every theorem is provable using the inference rules of the logic. These are statements about the entire logic, and are usually tied to some notion of a model. However, there are local notions of consistency and completeness that are purely syntactic checks on the inference rules, and require no appeals to models. The first of these is local consistency, also known as local reducibility, which says that any derivation containing an introduction of a connective followed immediately by its elimination can be turned into an equivalent derivation without this detour. It is a check on the strength of elimination rules: they must not be so strong that they include knowledge not already contained in its premises. As an example, consider conjunctions.
------ u ------ w
A true B true
------------------ ∧I
A ∧ B true
---------- ∧E1
A true |
⇒ |
------ u A true |
Dually, local completeness says that the elimination rules are strong enough to decompose a connective into the forms suitable for its introduction rule. Again for conjunctions:
---------- u A ∧ B true |
⇒ |
---------- u ---------- u
A ∧ B true A ∧ B true
---------- ∧E1 ---------- ∧E2
A true B true
----------------------- ∧I
A ∧ B true |
These notions correspond exactly to β-reduction (beta reduction) and η-conversion (eta conversion) in the lambda calculus, using the Curry–Howard isomorphism. By local completeness, we see that every derivation can be converted to an equivalent derivation where the principal connective is introduced. In fact, if the entire derivation obeys this ordering of eliminations followed by introductions, then it is said to be normal. In a normal derivation all eliminations happen above introductions. In most logics, every derivation has an equivalent normal derivation, called a normal form. The existence of normal forms is generally hard to prove using natural deduction alone, though such accounts do exist in the literature, most notably by Dag Prawitz in 1961.[7] It is much easier to show this indirectly by means of a cut-free sequent calculus presentation.
First and higher-order extensions

The logic of the earlier section is an example of a single-sorted logic, i.e., a logic with a single kind of object: propositions. Many extensions of this simple framework have been proposed; in this section we will extend it with a second sort of individuals or terms. More precisely, we will add a new kind of judgment, "t is a term" (or "t term") where t is schematic. We shall fix a countable set V of variables, another countable set F of function symbols, and construct terms as follows:
v ∈ V ------ var-F v term |
f ∈ F t1 term t2 term ... tn term
------------------------------------------ app-F
f (t1, t2, ..., tn) term |
For propositions, we consider a third countable set P of predicates, and define atomic predicates over terms with the following formation rule:
φ ∈ P t1 term t2 term ... tn term
------------------------------------------ pred-F
φ (t1, t2, ..., tn) prop |
In addition, we add a pair of quantified propositions: universal (∀) and existential (∃):
------ u
x term
⋮
A prop
---------- ∀Fu
∀x. A prop |
------ u
x term
⋮
A prop
---------- ∃Fu
∃x. A prop |
These quantified propositions have the following introduction and elimination rules.
------ u
a term
⋮
[a/x] A true
------------ ∀Iu, a
∀x. A true |
∀x. A true t term -------------------- ∀E [t/x] A true | |
[t/x] A true ------------ ∃I ∃x. A true |
------ u ------------ v
a term [a/x] A true
⋮
∃x. A true C true
-------------------------- ∃Ea, u,v
C true |
In these rules, the notation [t/x] A stands for the substitution of t for every (visible) instance of x in A, avoiding capture; see the article on lambda calculus for more detail about this standard operation. As before the superscripts on the name stand for the components that are discharged: the term a cannot occur in the conclusion of ∀I (such terms are known as eigenvariables or parameters), and the hypotheses named u and v in ∃E are localised to the second premise in a hypothetical derivation. Although the propositional logic of earlier sections was decidable, adding the quantifiers makes the logic undecidable.
So far the quantified extensions are first-order: they distinguish propositions from the kinds of objects quantified over. Higher-order logic takes a different approach and has only a single sort of propositions. The quantifiers have as the domain of quantification the very same sort of propositions, as reflected in the formation rules:
------ u
p prop
⋮
A prop
---------- ∀Fu
∀p. A prop |
------ u
p prop
⋮
A prop
---------- ∃Fu
∃p. A prop |
A discussion of the introduction and elimination forms for higher-order logic is beyond the scope of this article. It is possible to be in between first-order and higher-order logics. For example, second-order logic has two kinds of propositions, one kind quantifying over terms, and the second kind quantifying over propositions of the first kind.
Different presentations of natural deduction
Tree-like presentations
Gentzen's discharging annotations used to internalise hypothetical judgments can be avoided by representing proofs as a tree of sequents Γ ⊢A instead of a tree of A true judgments.
Sequential presentations
Jaśkowski's representations of natural deduction led to different notations such as Fitch-style calculus (or Fitch's diagrams) or Suppes' method, of which Lemmon gave a variant called system L. Such presentation systems, which are more accurately described as tabular, include the following.
- 1940: In a textbook, Quine[8] indicated antecedent dependencies by line numbers in square brackets, anticipating Suppes' 1957 line-number notation.
- 1950: In a textbook, Quine (1982, pp. 241–255) demonstrated a method of using one or more asterisks to the left of each line of proof to indicate dependencies. This is equivalent to Kleene's vertical bars. (It is not totally clear if Quine's asterisk notation appeared in the original 1950 edition or was added in a later edition.)
- 1957: An introduction to practical logic theorem proving in a textbook by Suppes (1999, pp. 25–150). This indicated dependencies (i.e. antecedent propositions) by line numbers at the left of each line.
- 1963: Stoll (1979, pp. 183–190, 215–219) uses sets of line numbers to indicate antecedent dependencies of the lines of sequential logical arguments based on natural deduction inference rules.
- 1965: The entire textbook by Lemmon (1965) is an introduction to logic proofs using a method based on that of Suppes.
- 1967: In a textbook, Kleene (2002, pp. 50–58, 128–130) briefly demonstrated two kinds of practical logic proofs, one system using explicit quotations of antecedent propositions on the left of each line, the other system using vertical bar-lines on the left to indicate dependencies.[9]
Proofs and type-theory
The presentation of natural deduction so far has concentrated on the nature of propositions without giving a formal definition of a proof. To formalise the notion of proof, we alter the presentation of hypothetical derivations slightly. We label the antecedents with proof variables (from some countable set V of variables), and decorate the succedent with the actual proof. The antecedents or hypotheses are separated from the succedent by means of a turnstile (⊢). This modification sometimes goes under the name of localised hypotheses. The following diagram summarises the change.
---- u1 ---- u2 ... ---- un
J1 J2 Jn
⋮
J |
⇒ |
u1:J1, u2:J2, ..., un:Jn ⊢ J |
The collection of hypotheses will be written as Γ when their exact composition is not relevant. To make proofs explicit, we move from the proof-less judgment "A true" to a judgment: "π is a proof of (A true)", which is written symbolically as "π : A true". Following the standard approach, proofs are specified with their own formation rules for the judgment "π proof". The simplest possible proof is the use of a labelled hypothesis; in this case the evidence is the label itself.
u ∈ V ------- proof-F u proof |
--------------------- hyp u:A true ⊢ u : A true |
For brevity, we shall leave off the judgmental label true in the rest of this article, i.e., write "Γ ⊢ π : A". Let us re-examine some of the connectives with explicit proofs. For conjunction, we look at the introduction rule ∧I to discover the form of proofs of conjunction: they must be a pair of proofs of the two conjuncts. Thus:
π1 proof π2 proof -------------------- pair-F (π1, π2) proof |
Γ ⊢ π1 : A Γ ⊢ π2 : B ------------------------ ∧I Γ ⊢ (π1, π2) : A ∧ B |
The elimination rules ∧E1 and ∧E2 select either the left or the right conjunct; thus the proofs are a pair of projections — first (fst) and second (snd).
π proof ----------- fst-F fst π proof |
Γ ⊢ π : A ∧ B ------------- ∧E1 Γ ⊢ fst π : A | |
π proof ----------- snd-F snd π proof |
Γ ⊢ π : A ∧ B ------------- ∧E2 Γ ⊢ snd π : B |
For implication, the introduction form localises or binds the hypothesis, written using a λ; this corresponds to the discharged label. In the rule, "Γ, u:A" stands for the collection of hypotheses Γ, together with the additional hypothesis u.
π proof ------------ λ-F λu. π proof |
Γ, u:A ⊢ π : B ----------------- ⊃I Γ ⊢ λu. π : A ⊃ B | |
π1 proof π2 proof ------------------- app-F π1 π2 proof |
Γ ⊢ π1 : A ⊃ B Γ ⊢ π2 : A ---------------------------- ⊃E Γ ⊢ π1 π2 : B |
With proofs available explicitly, one can manipulate and reason about proofs. The key operation on proofs is the substitution of one proof for an assumption used in another proof. This is commonly known as a substitution theorem, and can be proved by induction on the depth (or structure) of the second judgment.
- Substitution theorem
- If Γ ⊢ π1 : A and Γ, u:A ⊢ π2 : B, then Γ ⊢ [π1/u] π2 : B.
So far the judgment "Γ ⊢ π : A" has had a purely logical interpretation. In type theory, the logical view is exchanged for a more computational view of objects. Propositions in the logical interpretation are now viewed as types, and proofs as programs in the lambda calculus. Thus the interpretation of "π : A" is "the program π has type A". The logical connectives are also given a different reading: conjunction is viewed as product (×), implication as the function arrow (→), etc. The differences are only cosmetic, however. Type theory has a natural deduction presentation in terms of formation, introduction and elimination rules; in fact, the reader can easily reconstruct what is known as simple type theory from the previous sections.
The difference between logic and type theory is primarily a shift of focus from the types (propositions) to the programs (proofs). Type theory is chiefly interested in the convertibility or reducibility of programs. For every type, there are canonical programs of that type which are irreducible; these are known as canonical forms or values. If every program can be reduced to a canonical form, then the type theory is said to be normalising (or weakly normalising). If the canonical form is unique, then the theory is said to be strongly normalising. Normalisability is a rare feature of most non-trivial type theories, which is a big departure from the logical world. (Recall that almost every logical derivation has an equivalent normal derivation.) To sketch the reason: in type theories that admit recursive definitions, it is possible to write programs that never reduce to a value; such looping programs can generally be given any type. In particular, the looping program has type ⊥, although there is no logical proof of "⊥ true". For this reason, the propositions as types; proofs as programs paradigm only works in one direction, if at all: interpreting a type theory as a logic generally gives an inconsistent logic.
Like logic, type theory has many extensions and variants, including first-order and higher-order versions. An interesting branch of type theory, known as dependent type theory, allows quantifiers to range over programs themselves. These quantified types are written as Π and Σ instead of ∀ and ∃, and have the following formation rules:
Γ ⊢ A type Γ, x:A ⊢ B type ----------------------------- Π-F Γ ⊢ Πx:A. B type |
Γ ⊢ A type Γ, x:A ⊢ B type ---------------------------- Σ-F Γ ⊢ Σx:A. B type |
These types are generalisations of the arrow and product types, respectively, as witnessed by their introduction and elimination rules.
Γ, x:A ⊢ π : B -------------------- ΠI Γ ⊢ λx. π : Πx:A. B |
Γ ⊢ π1 : Πx:A. B Γ ⊢ π2 : A ----------------------------- ΠE Γ ⊢ π1 π2 : [π2/x] B |
Γ ⊢ π1 : A Γ, x:A ⊢ π2 : B ----------------------------- ΣI Γ ⊢ (π1, π2) : Σx:A. B |
Γ ⊢ π : Σx:A. B ---------------- ΣE1 Γ ⊢ fst π : A |
Γ ⊢ π : Σx:A. B ------------------------ ΣE2 Γ ⊢ snd π : [fst π/x] B |
Dependent type theory in full generality is very powerful: it is able to express almost any conceivable property of programs directly in the types of the program. This generality comes at a steep price — either typechecking is undecidable (extensional type theory), or extensional reasoning is more difficult (intensional type theory). For this reason, some dependent type theories do not allow quantification over arbitrary programs, but rather restrict to programs of a given decidable index domain, for example integers, strings, or linear programs.
Since dependent type theories allow types to depend on programs, a natural question to ask is whether it is possible for programs to depend on types, or any other combination. There are many kinds of answers to such questions. A popular approach in type theory is to allow programs to be quantified over types, also known as parametric polymorphism; of this there are two main kinds: if types and programs are kept separate, then one obtains a somewhat more well-behaved system called predicative polymorphism; if the distinction between program and type is blurred, one obtains the type-theoretic analogue of higher-order logic, also known as impredicative polymorphism. Various combinations of dependency and polymorphism have been considered in the literature, the most famous being the lambda cube of Henk Barendregt.
The intersection of logic and type theory is a vast and active research area. New logics are usually formalised in a general type theoretic setting, known as a logical framework. Popular modern logical frameworks such as the calculus of constructions and LF are based on higher-order dependent type theory, with various trade-offs in terms of decidability and expressive power. These logical frameworks are themselves always specified as natural deduction systems, which is a testament to the versatility of the natural deduction approach.
Classical and modal logics
For simplicity, the logics presented so far have been intuitionistic. Classical logic extends intuitionistic logic with an additional axiom or principle of excluded middle:
- For any proposition p, the proposition p ∨ ¬p is true.
This statement is not obviously either an introduction or an elimination; indeed, it involves two distinct connectives. Gentzen's original treatment of excluded middle prescribed one of the following three (equivalent) formulations, which were already present in analogous forms in the systems of Hilbert and Heyting:
-------------- XM1 A ∨ ¬A true |
¬¬A true ---------- XM2 A true |
-------- u
¬A true
⋮
p true
------ XM3u, p
A true |
(XM3 is merely XM2 expressed in terms of E.) This treatment of excluded middle, in addition to being objectionable from a purist's standpoint, introduces additional complications in the definition of normal forms.
A comparatively more satisfactory treatment of classical natural deduction in terms of introduction and elimination rules alone was first proposed by Parigot in 1992 in the form of a classical lambda calculus called λμ. The key insight of his approach was to replace a truth-centric judgment A true with a more classical notion, reminiscent of the sequent calculus: in localised form, instead of Γ ⊢ A, he used Γ ⊢ Δ, with Δ a collection of propositions similar to Γ. Γ was treated as a conjunction, and Δ as a disjunction. This structure is essentially lifted directly from classical sequent calculi, but the innovation in λμ was to give a computational meaning to classical natural deduction proofs in terms of a callcc or a throw/catch mechanism seen in LISP and its descendants. (See also: first class control.)
Another important extension was for modal and other logics that need more than just the basic judgment of truth. These were first described, for the alethic modal logics S4 and S5, in a natural deduction style by Prawitz in 1965,[4] and have since accumulated a large body of related work. To give a simple example, the modal logic S4 requires one new judgment, "A valid", that is categorical with respect to truth:
- If "A true" under no assumptions of the form "B true", then "A valid".
This categorical judgment is internalised as a unary connective ◻A (read "necessarily A") with the following introduction and elimination rules:
A valid -------- ◻I ◻ A true |
◻ A true -------- ◻E A true |
Note that the premise "A valid" has no defining rules; instead, the categorical definition of validity is used in its place. This mode becomes clearer in the localised form when the hypotheses are explicit. We write "Ω;Γ ⊢ A true" where Γ contains the true hypotheses as before, and Ω contains valid hypotheses. On the right there is just a single judgment "A true"; validity is not needed here since "Ω ⊢ A valid" is by definition the same as "Ω;⋅ ⊢ A true". The introduction and elimination forms are then:
Ω;⋅ ⊢ π : A true -------------------- ◻I Ω;⋅ ⊢ box π : ◻ A true |
Ω;Γ ⊢ π : ◻ A true ---------------------- ◻E Ω;Γ ⊢ unbox π : A true |
The modal hypotheses have their own version of the hypothesis rule and substitution theorem.
------------------------------- valid-hyp Ω, u: (A valid) ; Γ ⊢ u : A true |
- Modal substitution theorem
- If Ω;⋅ ⊢ π1 : A true and Ω, u: (A valid) ; Γ ⊢ π2 : C true, then Ω;Γ ⊢ [π1/u] π2 : C true.
This framework of separating judgments into distinct collections of hypotheses, also known as multi-zoned or polyadic contexts, is very powerful and extensible; it has been applied for many different modal logics, and also for linear and other substructural logics, to give a few examples. However, relatively few systems of modal logic can be formalised directly in natural deduction. To give proof-theoretic characterisations of these systems, extensions such as labelling or systems of deep inference.
The addition of labels to formulae permits much finer control of the conditions under which rules apply, allowing the more flexible techniques of analytic tableaux to be applied, as has been done in the case of labelled deduction. Labels also allow the naming of worlds in Kripke semantics; Simpson (1993) presents an influential technique for converting frame conditions of modal logics in Kripke semantics into inference rules in a natural deduction formalisation of hybrid logic. Stouppa (2004) surveys the application of many proof theories, such as Avron and Pottinger's hypersequents and Belnap's display logic to such modal logics as S5 and B.
Comparison with other foundational approaches
Sequent calculus
The sequent calculus is the chief alternative to natural deduction as a foundation of mathematical logic. In natural deduction the flow of information is bi-directional: elimination rules flow information downwards by deconstruction, and introduction rules flow information upwards by assembly. Thus, a natural deduction proof does not have a purely bottom-up or top-down reading, making it unsuitable for automation in proof search. To address this fact, Gentzen in 1935 proposed his sequent calculus, though he initially intended it as a technical device for clarifying the consistency of predicate logic. Kleene, in his seminal 1952 book Introduction to Metamathematics, gave the first formulation of the sequent calculus in the modern style.[10]
In the sequent calculus all inference rules have a purely bottom-up reading. Inference rules can apply to elements on both sides of the turnstile. (To differentiate from natural deduction, this article uses a double arrow ⇒ instead of the right tack ⊢ for sequents.) The introduction rules of natural deduction are viewed as right rules in the sequent calculus, and are structurally very similar. The elimination rules on the other hand turn into left rules in the sequent calculus. To give an example, consider disjunction; the right rules are familiar:
Γ ⇒ A --------- ∨R1 Γ ⇒ A ∨ B |
Γ ⇒ B --------- ∨R2 Γ ⇒ A ∨ B |
On the left:
Γ, u:A ⇒ C Γ, v:B ⇒ C --------------------------- ∨L Γ, w: (A ∨ B) ⇒ C |
Recall the ∨E rule of natural deduction in localised form:
Γ ⊢ A ∨ B Γ, u:A ⊢ C Γ, v:B ⊢ C --------------------------------------- ∨E Γ ⊢ C |
The proposition A ∨ B, which is the succedent of a premise in ∨E, turns into a hypothesis of the conclusion in the left rule ∨L. Thus, left rules can be seen as a sort of inverted elimination rule. This observation can be illustrated as follows:
| natural deduction | sequent calculus | |
|---|---|---|
------ hyp | | elim. rules | ↓ ---------------------- ↑↓ meet ↑ | | intro. rules | conclusion |
⇒ | --------------------------- init ↑ ↑ | | | left rules | right rules | | conclusion |
In the sequent calculus, the left and right rules are performed in lock-step until one reaches the initial sequent, which corresponds to the meeting point of elimination and introduction rules in natural deduction. These initial rules are superficially similar to the hypothesis rule of natural deduction, but in the sequent calculus they describe a transposition or a handshake of a left and a right proposition:
---------- init Γ, u:A ⇒ A |
The correspondence between the sequent calculus and natural deduction is a pair of soundness and completeness theorems, which are both provable by means of an inductive argument.
- Soundness of ⇒ wrt. ⊢
- If Γ ⇒ A, then Γ ⊢ A.
- Completeness of ⇒ wrt. ⊢
- If Γ ⊢ A, then Γ ⇒ A.
It is clear by these theorems that the sequent calculus does not change the notion of truth, because the same collection of propositions remain true. Thus, one can use the same proof objects as before in sequent calculus derivations. As an example, consider the conjunctions. The right rule is virtually identical to the introduction rule
| sequent calculus | natural deduction | |
|---|---|---|
Γ ⇒ π1 : A Γ ⇒ π2 : B --------------------------- ∧R Γ ⇒ (π1, π2) : A ∧ B |
Γ ⊢ π1 : A Γ ⊢ π2 : B ------------------------- ∧I Γ ⊢ (π1, π2) : A ∧ B |
The left rule, however, performs some additional substitutions that are not performed in the corresponding elimination rules.
| sequent calculus | natural deduction | |
|---|---|---|
Γ, v: (A ∧ B), u:A ⇒ π : C -------------------------------- ∧L1 Γ, v: (A ∧ B) ⇒ [fst v/u] π : C |
Γ ⊢ π : A ∧ B ------------- ∧E1 Γ ⊢ fst π : A | |
Γ, v: (A ∧ B), u:B ⇒ π : C -------------------------------- ∧L2 Γ, v: (A ∧ B) ⇒ [snd v/u] π : C |
Γ ⊢ π : A ∧ B ------------- ∧E2 Γ ⊢ snd π : B |
The kinds of proofs generated in the sequent calculus are therefore rather different from those of natural deduction. The sequent calculus produces proofs in what is known as the β-normal η-long form, which corresponds to a canonical representation of the normal form of the natural deduction proof. If one attempts to describe these proofs using natural deduction itself, one obtains what is called the intercalation calculus (first described by John Byrnes), which can be used to formally define the notion of a normal form for natural deduction.
The substitution theorem of natural deduction takes the form of a structural rule or structural theorem known as cut in the sequent calculus.
- Cut (substitution)
- If Γ ⇒ π1 : A and Γ, u:A ⇒ π2 : C, then Γ ⇒ [π1/u] π2 : C.
In most well behaved logics, cut is unnecessary as an inference rule, though it remains provable as a meta-theorem; the superfluousness of the cut rule is usually presented as a computational process, known as cut elimination. This has an interesting application for natural deduction; usually it is extremely tedious to prove certain properties directly in natural deduction because of an unbounded number of cases. For example, consider showing that a given proposition is not provable in natural deduction. A simple inductive argument fails because of rules like ∨E or E which can introduce arbitrary propositions. However, we know that the sequent calculus is complete with respect to natural deduction, so it is enough to show this unprovability in the sequent calculus. Now, if cut is not available as an inference rule, then all sequent rules either introduce a connective on the right or the left, so the depth of a sequent derivation is fully bounded by the connectives in the final conclusion. Thus, showing unprovability is much easier, because there are only a finite number of cases to consider, and each case is composed entirely of sub-propositions of the conclusion. A simple instance of this is the global consistency theorem: "⋅ ⊢ ⊥ true" is not provable. In the sequent calculus version, this is manifestly true because there is no rule that can have "⋅ ⇒ ⊥" as a conclusion! Proof theorists often prefer to work on cut-free sequent calculus formulations because of such properties.
See also
- Mathematical logic
- Sequent calculus
- Gerhard Gentzen
- System L (tabular natural deduction)
Notes
- ↑ Jaśkowski 1934.
- ↑ Gentzen 1934, Gentzen 1935.
- ↑ Gentzen 1934, p. 176.
- 1 2 Prawitz 1965, Prawitz 2006.
- ↑ Martin-Löf 1996.
- ↑ This is due to Bolzano, as cited by Martin-Löf 1996, p. 15.
- ↑ See also his book Prawitz 1965, Prawitz 2006.
- ↑ Quine (1981). See particularly pages 91–93 for Quine's line-number notation for antecedent dependencies.
- ↑ A particular advantage of Kleene's tabular natural deduction systems is that he proves the validity of the inference rules for both propositional calculus and predicate calculus. See Kleene 2002, pp. 44–45, 118–119.
- ↑ Kleene 2009, pp. 440–516. See also Kleene 1980.
References
- Barker-Plummer, Dave; Barwise, Jon; Etchemendy, John (2011). Language Proof and Logic (2nd ed.). CSLI Publications. ISBN 978-1575866321.
- Gallier, Jean (2005). "Constructive Logics. Part I: A Tutorial on Proof Systems and Typed λ-Calculi". Retrieved 12 June 2014.
- Gentzen, Gerhard Karl Erich (1934). "Untersuchungen über das logische Schließen. I". Mathematische Zeitschrift 39 (2): 176–210. doi:10.1007/BF01201353. (English translation Investigations into Logical Deduction in M. E. Szabo. The Collected Works of Gerhard Gentzen. North-Holland Publishing Company, 1969.)
- Gentzen, Gerhard Karl Erich (1935). "Untersuchungen über das logische Schließen. II". Mathematische Zeitschrift 39 (3): 405–431. doi:10.1007/bf01201363.
- Girard, Jean-Yves (1990). Proofs and Types. Cambridge Tracts in Theoretical Computer Science. Cambridge University Press, Cambridge, England. Translated and with appendices by Paul Taylor and Yves Lafont.
- Jaśkowski, Stanisław (1934). On the rules of suppositions in formal logic. Reprinted in Polish logic 1920–39, ed. Storrs McCall.
- Kleene, Stephen Cole (1980) [1952]. Introduction to metamathematics (Eleventh ed.). North-Holland. ISBN 978-0-7204-2103-3.
- Kleene, Stephen Cole (2009) [1952]. Introduction to metamathematics. Ishi Press International. ISBN 978-0-923891-57-2.
- Kleene, Stephen Cole (2002) [1967]. Mathematical logic. Mineola, New York: Dover Publications. ISBN 978-0-486-42533-7.
- Lemmon, Edward John (1965). Beginning logic. Thomas Nelson. ISBN 0-17-712040-1.
- Martin-Löf, Per (1996). "On the meanings of the logical constants and the justifications of the logical laws" (PDF). Nordic Journal of Philosophical Logic 1 (1): 11–60. Lecture notes to a short course at Università degli Studi di Siena, April 1983.
- Pfenning, Frank; Davies, Rowan (2001). "A judgmental reconstruction of modal logic" (PDF). Mathematical Structures in Computer Science 11 (4): 511–540. doi:10.1017/S0960129501003322.
- Prawitz, Dag (1965). Natural deduction: A proof-theoretical study. Acta Universitatis Stockholmiensis, Stockholm studies in philosophy 3. Stockholm, Göteborg, Uppsala: Almqvist & Wicksell.
- Prawitz, Dag (2006) [1965]. Natural deduction: A proof-theoretical study. Mineola, New York: Dover Publications. ISBN 978-0-486-44655-4.
- Quine, Willard Van Orman (1981) [1940]. Mathematical logic (Revised ed.). Cambridge, Massachusetts: Harvard University Press. ISBN 978-0-674-55451-1.
- Quine, Willard Van Orman (1982) [1950]. Methods of logic (Fourth ed.). Cambridge, Massachusetts: Harvard University Press. ISBN 978-0-674-57176-1.
- Simpson, Alex (1993). The proof theory and semantics of intuitionistic modal logic. University of Edinburgh. PhD thesis.
- Stoll, Robert Roth (1979) [1963]. Set Theory and Logic. Mineola, New York: Dover Publications. ISBN 978-0-486-63829-4.
- Stouppa, Phiniki (2004). The Design of Modal Proof Theories: The Case of S5. University of Dresden. MSc thesis.
- Suppes, Patrick Colonel (1999) [1957]. Introduction to logic. Mineola, New York: Dover Publications. ISBN 978-0-486-40687-9.
External links
- Clemente, Daniel, "Introduction to natural deduction."
- Domino On Acid. Natural deduction visualized as a game of dominoes.
- Pelletier, Jeff, "A History of Natural Deduction and Elementary Logic Textbooks."
- Levy, Michel, A Propositional Prover.
- A Propositional proving tool for iOS
| ||||||||||||||||||||||||||||||||||||||