Condition number
In the field of numerical analysis, the condition number of a function with respect to an argument measures how much the output value of the function can change for a small change in the input argument. This is used to measure how sensitive a function is to changes or errors in the input, and how much error in the output results from an error in the input. Very frequently, one is solving the inverse problem – given 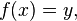 one is solving for x, and thus the condition number of the (local) inverse must be used. In linear regression the condition number can be used as a diagnostic for multicollinearity.
one is solving for x, and thus the condition number of the (local) inverse must be used. In linear regression the condition number can be used as a diagnostic for multicollinearity.
The condition number is an application of the derivative, and is formally defined as the value of the asymptotic worst-case relative change in output for a relative change in input. The "function" is the solution of a problem and the "arguments" are the data in the problem. The condition number is frequently applied to questions in linear algebra, in which case the derivative is straightforward but the error could be in many different directions, and is thus computed from the geometry of the matrix. More generally, condition numbers can be defined for non-linear functions in several variables.
A problem with a low condition number is said to be well-conditioned, while a problem with a high condition number is said to be ill-conditioned. The condition number is a property of the problem. Paired with the problem are any number of algorithms that can be used to solve the problem, that is, to calculate the solution. Some algorithms have a property called backward stability. In general, a backward stable algorithm can be expected to accurately solve well-conditioned problems. Numerical analysis textbooks give formulas for the condition numbers of problems and identify the backward stable algorithms.
As a rule of thumb, if the condition number 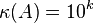 , then you may lose up to
, then you may lose up to  digits of accuracy on top of what would be lost to the numerical method due to loss of precision from arithmetic methods.[1] However, the condition number does not give the exact value of the maximum inaccuracy that may occur in the algorithm. It generally just bounds it with an estimate (whose computed value depends on the choice of the norm to measure the inaccuracy).
digits of accuracy on top of what would be lost to the numerical method due to loss of precision from arithmetic methods.[1] However, the condition number does not give the exact value of the maximum inaccuracy that may occur in the algorithm. It generally just bounds it with an estimate (whose computed value depends on the choice of the norm to measure the inaccuracy).
Matrices
For example, the condition number associated with the linear equation Ax = b gives a bound on how inaccurate the solution x will be after approximation. Note that this is before the effects of round-off error are taken into account; conditioning is a property of the matrix, not the algorithm or floating point accuracy of the computer used to solve the corresponding system. In particular, one should think of the condition number as being (very roughly) the rate at which the solution, x, will change with respect to a change in b. Thus, if the condition number is large, even a small error in b may cause a large error in x. On the other hand, if the condition number is small then the error in x will not be much bigger than the error in b.
The condition number is defined more precisely to be the maximum ratio of the relative error in x divided by the relative error in b.
Let e be the error in b. Assuming that A is a nonsingular matrix, the error in the solution A−1b is A−1e. The ratio of the relative error in the solution to the relative error in b is
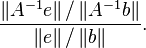
This is easily transformed to
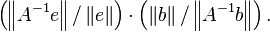
The maximum value (for nonzero b and e) is easily seen to be the product of the two operator norms:

The same definition is used for any consistent norm, i.e. one that satisfies
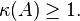
When the condition number is exactly one (which can only happen if A is a linear isometry), then a solution algorithm can find (in principle, meaning if the algorithm introduces no errors of its own) an approximation of the solution whose precision is no worse than that of the data.
However, it does not mean that the algorithm will converge rapidly to this solution, just that it won't diverge arbitrarily because of inaccuracy on the source data (backward error), provided that the forward error introduced by the algorithm does not diverge as well because of accumulating intermediate rounding errors.
The condition number may also be infinite, but this implies that the problem is ill-posed (does not possess a unique, well-defined solution for each choice of data -- that is, the matrix is not invertible), and no algorithm can be expected to reliably find a solution.
The definition of the condition number depends on the choice of norm, as can be illustrated by two examples.
If 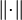 is the norm (usually noted as
is the norm (usually noted as  ) defined in the square-summable sequence space ℓ2 (which matches the usual distance in a standard Euclidean space), then
) defined in the square-summable sequence space ℓ2 (which matches the usual distance in a standard Euclidean space), then

where 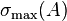 and
and 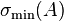 are maximal and minimal singular values of
are maximal and minimal singular values of 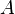 respectively. Hence
respectively. Hence
- If is normal then
-
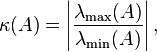
where  and
and  are maximal and minimal (by moduli) eigenvalues of respectively.
are maximal and minimal (by moduli) eigenvalues of respectively.
- If is unitary then
-
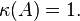
The condition number with respect to L2 arises so often in numerical linear algebra that it is given a name, the condition number of a matrix.
If is the norm (usually denoted by 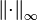 ) defined in the sequence space ℓ∞ of all bounded sequences (which matches the maximum of distances measured on projections into the base subspaces), and is lower triangular non-singular (i.e.,
) defined in the sequence space ℓ∞ of all bounded sequences (which matches the maximum of distances measured on projections into the base subspaces), and is lower triangular non-singular (i.e., 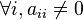 ) then
) then
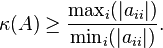
The condition number computed with this norm is generally larger than the condition number computed with square-summable sequences, but it can be evaluated more easily (and this is often the only practicably computable condition number, when the problem to solve involves a non-linear algebra, for example when approximating irrational and transcendental functions or numbers with numerical methods.)
If the condition number is not too much larger than one (but it can still be a multiple of one), the matrix is well conditioned which means its inverse can be computed with good accuracy. If the condition number is very large, then the matrix is said to be ill-conditioned. Practically, such a matrix is almost singular, and the computation of its inverse, or solution of a linear system of equations is prone to large numerical errors. A matrix that is not invertible has condition number equal to infinity.
Non-linear
Condition numbers can also be defined for nonlinear functions, and can be computed using calculus. The condition number varies with the point; in some cases one can use the maximum (or supremum) condition number over the domain of the function or domain of the question as an overall condition number, while in other cases the condition number at a particular point is of more interest.
One variable
The condition number of a differentiable function f in one variable as a function is 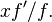 Evaluated at a point x this is:
Evaluated at a point x this is:

Most elegantly, this can be understood as (the absolute value of) the ratio of the logarithmic derivative of f, which is 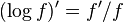 and the logarithmic derivative of x, which is
and the logarithmic derivative of x, which is 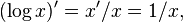 yielding a ratio of This is because the logarithmic derivative is the infinitesimal rate of relative change in a function: it is the derivative
yielding a ratio of This is because the logarithmic derivative is the infinitesimal rate of relative change in a function: it is the derivative  scaled by the value of f. Note that if a function has a zero at a point, its condition number at the point is infinite, as infinitesimal changes in the input can change the output from zero to positive or negative, yielding a ratio with zero in the denominator, hence infinite relative change.
scaled by the value of f. Note that if a function has a zero at a point, its condition number at the point is infinite, as infinitesimal changes in the input can change the output from zero to positive or negative, yielding a ratio with zero in the denominator, hence infinite relative change.
More directly, given a small change 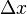 in x, the relative change in x is
in x, the relative change in x is ![[(x + \Delta x) - x]/x = (\Delta x)/x,](../I/m/e9a89b9b3dc889dd10d959ece25e254c.png) while the relative change in
while the relative change in 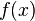 is
is ![[f(x + \Delta x) - f(x)]/f(x).](../I/m/5b3dd81e5b350c93f7240cb08cce0626.png) Taking the ratio yields:
Taking the ratio yields:
![\frac{[f(x + \Delta x) - f(x)]/f(x)}{(\Delta x)/x}
= \frac{x}{f(x)}\frac{f(x + \Delta x) - f(x)}{(x + \Delta x) - x}.](../I/m/1af838133cb1194aaac34638a93e9d99.png)
The last term is the difference quotient (the slope of the secant line), and taking the limit yields the derivative.
Condition numbers of common elementary functions are particularly important in computing significant figures, and can be computed immediately from the derivative; see significance arithmetic of transcendental functions. A few important ones are given below:
- Exponential function
 :
: 
- Natural logarithm function
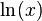 :
: 
- Sine function
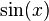 :
: 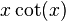
- Cosine function
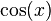 :
: 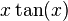
- Tangent function
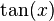 :
: 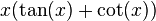
- Inverse sine function
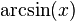 :
: 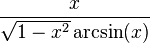
- Inverse cosine function
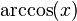 :
: 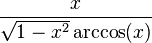
- Inverse tangent function
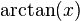 :
: 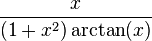
Several variables
Condition numbers can be defined for any function ƒ mapping its data from some domain (e.g. an m-tuple of real numbers x) into some codomain [e.g. an n-tuple of real numbers ƒ(x)], where both the domain and codomain are Banach spaces. They express how sensitive that function is to small changes (or small errors) in its arguments. This is crucial in assessing the sensitivity and potential accuracy difficulties of numerous computational problems, for example polynomial root finding or computing eigenvalues.
The condition number of ƒ at a point x (specifically, its relative condition number[2]) is then defined to be the maximum ratio of the fractional change in ƒ(x) to any fractional change in x, in the limit where the change δx in x becomes infinitesimally small:[2]
![\lim_{ \varepsilon \to 0^+ }
\sup_{ \Vert \delta x \Vert \leq \varepsilon }
\left[ \frac{ \left\Vert f(x + \delta x) - f(x)\right\Vert }{ \Vert f(x) \Vert }
/ \frac{ \Vert \delta x \Vert }{ \Vert x \Vert }
\right],](../I/m/fbe98d08a1671533b857bacb2091cd90.png)
where  is a norm on the domain/codomain of ƒ(x).
is a norm on the domain/codomain of ƒ(x).
If ƒ is differentiable, this is equivalent to:[2]

where J(x) denotes the Jacobian matrix of partial derivatives of ƒ at x and 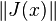 is the induced norm on the matrix.
is the induced norm on the matrix.
See also
References
- ↑ Cheney; Kincaid (2007-08-03). Numerical Mathematics and Computing. ISBN 978-0-495-11475-8.
- 1 2 3 Trefethen, L. N.; Bau, D. (1997). Numerical Linear Algebra. SIAM. ISBN 978-0-89871-361-9.
External links
- Condition Number of a Matrix at Holistic Numerical Methods Institute
- Matrix condition number at PlanetMath.org.
- MATLAB library function to determine condition number
- Condition number – Encyclopedia of Mathematics