Cayley–Hamilton theorem

In linear algebra, the Cayley–Hamilton theorem (named after the mathematicians Arthur Cayley and William Rowan Hamilton) states that every square matrix over a commutative ring (such as the real or complex field) satisfies its own characteristic equation.
If A is a given n×n matrix and In is the n×n identity matrix, then the characteristic polynomial of A is defined as[4]

where det is the determinant operation and λ is a scalar element of the base ring. Since the entries of the matrix are (linear or constant) polynomials in λ, the determinant is also an n-th order monic polynomial in λ. The Cayley–Hamilton theorem states that substituting the matrix A for λ in this polynomial results in the zero matrix,

The powers of A, obtained by substitution from powers of λ, are defined by repeated matrix multiplication; the constant term of p(λ) gives a multiple of the power A0, which power is defined as the identity matrix. The theorem allows An to be expressed as a linear combination of the lower matrix powers of A. When the ring is a field, the Cayley–Hamilton theorem is equivalent to the statement that the minimal polynomial of a square matrix divides its characteristic polynomial.
The theorem was first proved in 1853[5] in terms of inverses of linear functions of quaternions, a non-commutative ring, by Hamilton.[6][7][8] This corresponds to the special case of certain real 4 × 4 real or 2 × 2 complex matrices. The theorem holds for general quaternionic matrices.[9][nb 1] Cayley in 1858 stated it for 3 × 3 and smaller matrices, but only published a proof for the 2 × 2 case.[2] The general case was first proved by Frobenius in 1878.[10]
Examples
1×1 matrices
For a 1×1 matrix A = (a1,1), the characteristic polynomial is given by p(λ) = λ − a, and so p(A) = (a) − a1,1 = 0 is obvious.
2×2 matrices
As a concrete example, let
 .
.
Its characteristic polynomial is given by

The Cayley–Hamilton theorem claims that, if we define

then

We can verify by computation that indeed,
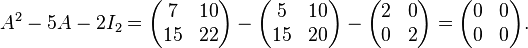
For a generic 2×2 matrix,

the characteristic polynomial is given by p(λ) = λ2 − (a + d)λ + (ad − bc), so the Cayley–Hamilton theorem states that

which is indeed always the case, evident by working out the entries of A2.
Practical applications
Inverse matrix

Hamilton proved that for a linear function of quaternions there exists a certain equation, depending on the linear function, that is satisfied by the linear function itself.[6][7][8]
For a general n×n invertible matrix A, i.e., one with nonzero determinant, A−1 can thus be written as an (n − 1)-th order polynomial expression in A: As indicated, the Cayley–Hamilton theorem amounts to the identity
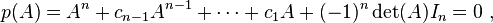
with cn − 1 = −tr A, etc., where tr A is the trace of the matrix A.
This can then be written as
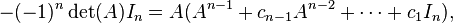
and, by multiplying both sides by A−1 (note −(−1)n = (−1)n−1), one is led to the compact expression for the inverse,

For larger matrices, the expressions for the coefficients ck of the characteristic polynomial in terms of the matrix components become increasingly complicated; but they can also be expressed in terms of traces of powers of the matrix A, using Newton's identities (at least when the ring contains the rational numbers), thus resulting in the expression for the inverse of A as a trace identity,

where the sum is taken over s and the sets of all integer partitions kl ≥ 0 satisfying the equation

Coefficients are then found by identifying powers of A. For instance, in the above 2×2 matrix example, the coefficient −c1 = a + d of λ above is just the trace of A, tr A, while the constant coefficient c0 = ad − bc can be written as ½((trA)2 − tr(A2)). (Of course, it is also the determinant of A, in this case.)
In fact, this expression, ½((trA)2 − tr(A2)), always gives the coefficient cn−2 of λn−2 in the characteristic polynomial of any n×n matrix; so, for a 3×3 matrix A, the statement of the Cayley–Hamilton theorem can also be written as
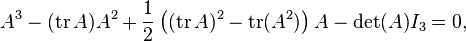
where the right-hand side designates a 3×3 matrix with all entries reduced to zero. Likewise, this determinant in the n = 3 case, is now

minus the coefficient cn−3 of λn−3 in the general case, as seen below.
Similarly, one can write for a 4×4 matrix A,

where, now, the determinant is

and so on for larger matrices, with the increasingly complex expressions for the coefficients deducible from Newton's identities.
A practical method for obtaining these coefficients ck for a general n×n matrix, yielding the above ones virtually by inspection, provided no root be zero, relies on the following alternative expression for the determinant,

Hence, by virtue of the Mercator series,

where the exponential only needs be expanded to order λ−n, since p(λ) is of order n, the net negative powers of λ automatically vanishing by the C–H theorem. (Again, this requires a ring containing the rational numbers.)
Differentiation of this expression with respect to λ allows determination of the generic coefficients of the characteristic polynomial for general n, as determinants of m×m matrices,[nb 2]

n-th Power of matrix
The Cayley–Hamilton theorem always provides a relationship between the powers of A (though not always the simplest one), which allows one to simplify expressions involving such powers, and evaluate them without having to compute the power An or any higher powers of A.
For instance, the concrete 2×2 example above can be written as
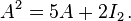
Then, for example, to calculate A4, observe

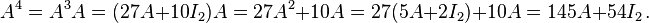
Likewise,

Power series
It is possible to define matrix valued functions of a real variable by giving its power series. An example of such usage is the exponential map from the Lie algebra of a matrix Lie group into the group. It is given by

Using the Cayley–Hamilton theorem, it becomes apparent that this expression reduces to an expression involving only powers of X up to n − 1 for an n × n-matrix X. Expressions have long been known for SU(2),

where the σ are the Pauli matrices and for SO(3),
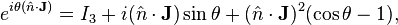
which is Rodrigues' rotation formula. For the notation, please see rotation group SO(3)#A note on representations. More recently, expressions have appeared for other groups, like the Lorentz group SO(3, 1),[11] O(4, 2)[12] and SU(2, 2),[13] as well as GL(n, R).[14] The group O(4, 2) is the conformal group of spacetime, SU(2, 2) its simply connected cover (to be precise, the simply connected cover of the connected component SO+(4, 2) of O(4, 2)). The obtained expressions are applicable to the standard representation of these groups. They require knowledge of (some of) the eigenvalues of the matrix to exponentiate. For SU(2) (and hence for SO(3)), closed expressions have recently been obtained for all irreducible representations, i.e. of any spin.[15]
Proving the theorem in general
As the examples above show, obtaining the statement of the Cayley–Hamilton theorem for an n×n matrix
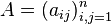
requires two steps: first the coefficients ci of the characteristic polynomial are determined by development as a polynomial in t of the determinant
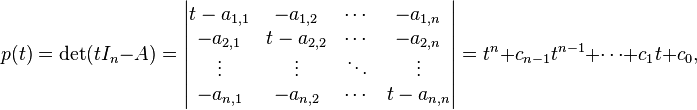
and then these coefficients are used in a linear combination of powers of A that is equated to the n×n null matrix:

The left hand side can be worked out to an n×n matrix whose entries are (enormous) polynomial expressions in the set of entries ai,j of A, so the Cayley–Hamilton theorem states that each of these n2 expressions are equal to 0. For any fixed value of n these identities can be obtained by tedious but completely straightforward algebraic manipulations. None of these computations can show however why the Cayley–Hamilton theorem should be valid for matrices of all possible sizes n, so a uniform proof for all n is needed.
Preliminaries

In 1878 he gave the first full proof of the Cayley–Hamilton theorem.[10]
If a vector v of size n happens to be an eigenvector of A with eigenvalue λ, in other words if A⋅v = λv, then

which is the null vector since p(λ) = 0 (the eigenvalues of A are precisely the roots of p(t). This holds for all possible eigenvalues λ, so the two matrices equated by the theorem certainly give the same (null) result when applied to any eigenvector. Now if A admits a basis of eigenvectors, in other words if A is diagonalizable, then the Cayley–Hamilton theorem must hold for A, since two matrices that give the same values when applied to each element of a basis must be equal. Not all matrices are diagonalizable, but for matrices with complex coefficients many of them are: the set of diagonalizable complex square matrices of a given size is dense in the set of all such square matrices[16] (for a matrix to be diagonalizable it suffices for instance that its characteristic polynomial not have any multiple roots). Now if any of the n2 expressions that the theorem equates to 0 would not reduce to a null expression, in other words if it would be a nonzero polynomial in the coefficients of the matrix, then the set of complex matrices for which this expression happens to give 0 would not be dense in the set of all matrices, which would contradict the fact that the theorem holds for all diagonalizable matrices. Thus one can see that the Cayley–Hamilton theorem must be true.
While this provides a valid proof (for matrices over the complex numbers), the argument is not very satisfactory, since the identities represented by the theorem do not in any way depend on the nature of the matrix (diagonalizable or not), nor on the kind of entries allowed (for matrices with real entries the diagonizable ones do not form a dense set, and it seems strange one would have to consider complex matrices to see that the Cayley–Hamilton theorem holds for them). We shall therefore now consider only arguments that prove the theorem directly for any matrix using algebraic manipulations only; these also have the benefit of working for matrices with entries in any commutative ring.
There is a great variety of such proofs of the Cayley–Hamilton theorem, of which several will be given here. They vary in the amount of abstract algebraic notions required to understand the proof. The simplest proofs use just those notions needed to formulate the theorem (matrices, polynomials with numeric entries, determinants), but involve technical computations that render somewhat mysterious the fact that they lead precisely to the correct conclusion. It is possible to avoid such details, but at the price of involving more subtle algebraic notions: polynomials with coefficients in a non-commutative ring, or matrices with unusual kinds of entries.
Adjugate matrices
All proofs below use the notion of the adjugate matrix adj(M) of an n×n matrix M, the transpose of its cofactor matrix.
This is a matrix whose coefficients are given by polynomial expressions in the coefficients of M (in fact, by certain (n − 1)×(n − 1) determinants), in such a way that the following fundamental relations hold,

These relations are a direct consequence of the basic properties of determinants: evaluation of the (i,j) entry of the matrix product on the left gives the expansion by column j of the determinant of the matrix obtained from M by replacing column i by a copy of column j, which is det(M) if i = j and zero otherwise; the matrix product on the right is similar, but for expansions by rows.
Being a consequence of just algebraic expression manipulation, these relations are valid for matrices with entries in any commutative ring (commutativity must be assumed for determinants to be defined in the first place). This is important to note here, because these relations will be applied below for matrices with non-numeric entries such as polynomials.
A direct algebraic proof
This proof uses just the kind of objects needed to formulate the Cayley–Hamilton theorem: matrices with polynomials as entries. The matrix t In −A whose determinant is the characteristic polynomial of A is such a matrix, and since polynomials form a commutative ring, it has an adjugate

Then, according to the right-hand fundamental relation of the adjugate, one has

Since B is also a matrix with polynomials in t as entries, one can, for each i , collect the coefficients of ti in each entry to form a matrix B i of numbers, such that one has
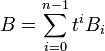
(the way the entries of B are defined makes clear that no powers higher than tn−1 occur). While this looks like a polynomial with matrices as coefficients, we shall not consider such a notion; it is just a way to write a matrix with polynomial entries as a linear combination of n constant matrices, and the coefficient t i has been written to the left of the matrix to stress this point of view.
Now one can expand the matrix product in our equation by bilinearity

Writing

one obtains an equality of two matrices with polynomial entries, written as linear combinations of constant matrices with powers of t as coefficients.
Such an equality can hold only if in any matrix position the entry that is multiplied by a given power ti is the same on both sides; it follows that the constant matrices with coefficient ti in both expressions must be equal. Writing these equations then for i from n down to 0, one finds

Finally, multiply the equation of the coefficients of ti from the left by Ai, and sum up: the left-hand sides form a telescoping sum and cancel completely, which results in the equation

This completes the proof.
A proof using polynomials with matrix coefficients
This proof is similar to the first one, but tries to give meaning to the notion of polynomial with matrix coefficients that was suggested by the expressions occurring in that proof. This requires considerable care, since it is somewhat unusual to consider polynomials with coefficients in a non-commutative ring, and not all reasoning that is valid for commutative polynomials can be applied in this setting. Notably, while arithmetic of polynomials over a commutative ring models the arithmetic of polynomial functions, this is not the case over a non-commutative ring (in fact there is no obvious notion of polynomial function in this case that is closed under multiplication). So when considering polynomials in t with matrix coefficients, the variable t must not be thought of as an "unknown", but as a formal symbol that is to be manipulated according to given rules; in particular one cannot just set t to a specific value.
 .
.
Let M(n, R) be the ring of n×n matrices with entries in some ring R (such as the real or complex numbers) that has A as an element. Matrices with as coefficients polynomials in t, such as 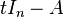 or its adjugate B in the first proof, are elements of M(n, R[t]). By collecting like powers of t, such matrices can be written as "polynomials" in t with constant matrices as coefficients; write M(n, R)[t] for the set of such polynomials. Since this set is in bijection with M(n, R[t]), one defines arithmetic operations on it correspondingly, in particular multiplication is given by
or its adjugate B in the first proof, are elements of M(n, R[t]). By collecting like powers of t, such matrices can be written as "polynomials" in t with constant matrices as coefficients; write M(n, R)[t] for the set of such polynomials. Since this set is in bijection with M(n, R[t]), one defines arithmetic operations on it correspondingly, in particular multiplication is given by

respecting the order of the coefficient matrices from the two operands; obviously this gives a non-commutative multiplication. Thus the identity

from the first proof can be viewed as one involving a multiplication of elements in M(n, R)[t].
At this point, it is tempting to simply set t equal to the matrix A, which makes the first factor on the left equal to the null matrix, and the right hand side equal to p(A); however, this is not an allowed operation when coefficients do not commute. It is possible to define a "right-evaluation map" evA : M[t] → M, which replaces each ti by the matrix power Ai of A, where one stipulates that the power is always to be multiplied on the right to the corresponding coefficient. But this map is not a ring homomorphism: the right-evaluation of a product differs in general from the product of the right-evaluations. This is so because multiplication of polynomials with matrix coefficients does not model multiplication of expressions containing unknowns: a product  is defined assuming that t commutes with N, but this may fail if t is replaced by the matrix A.
is defined assuming that t commutes with N, but this may fail if t is replaced by the matrix A.
One can work around this difficulty in the particular situation at hand, since the above right-evaluation map does become a ring homomorphism if the matrix A is in the center of the ring of coefficients, so that it commutes with all the coefficients of the polynomials (the argument proving this is straightforward, exactly because commuting t with coefficients is now justified after evaluation). Now A is not always in the center of M, but we may replace M with a smaller ring provided it contains all the coefficients of the polynomials in question:  , A, and the coefficients
, A, and the coefficients  of the polynomial B. The obvious choice for such a subring is the centralizer Z of A, the subring of all matrices that commute with A; by definition A is in the center of Z. This centralizer obviously contains , and A, but one has to show that it contains the matrices . To do this one combines the two fundamental relations for adjugates, writing out the adjugate B as a polynomial:
of the polynomial B. The obvious choice for such a subring is the centralizer Z of A, the subring of all matrices that commute with A; by definition A is in the center of Z. This centralizer obviously contains , and A, but one has to show that it contains the matrices . To do this one combines the two fundamental relations for adjugates, writing out the adjugate B as a polynomial:

Equating the coefficients shows that for each i, we have A Bi = Bi A as desired. Having found the proper setting in which evA is indeed a homomorphism of rings, one can complete the proof as suggested above:

This completes the proof.
A synthesis of the first two proofs
In the first proof, one was able to determine the coefficients Bi of B based on the right hand fundamental relation for the adjugate only. In fact the first n equations derived can be interpreted as determining the quotient B of the Euclidean division of the polynomial  on the left by the monic polynomial
on the left by the monic polynomial  , while the final equation expresses the fact that the remainder is zero. This division is performed in the ring of polynomials with matrix coefficients. Indeed, even over a non-commutative ring, Euclidean division by a monic polynomial P is defined, and always produces a unique quotient and remainder with the same degree condition as in the commutative case, provided it is specified at which side one wishes P to be a factor (here that is to the left). To see that quotient and remainder are unique (which is the important part of the statement here), it suffices to write
, while the final equation expresses the fact that the remainder is zero. This division is performed in the ring of polynomials with matrix coefficients. Indeed, even over a non-commutative ring, Euclidean division by a monic polynomial P is defined, and always produces a unique quotient and remainder with the same degree condition as in the commutative case, provided it is specified at which side one wishes P to be a factor (here that is to the left). To see that quotient and remainder are unique (which is the important part of the statement here), it suffices to write  as
as  and observe that since P is monic,
and observe that since P is monic, 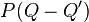 cannot have a degree less than that of P, unless
cannot have a degree less than that of P, unless 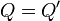 .
.
But the dividend and divisor used here both lie in the subring (R[A])[t], where R[A] is the subring of the matrix ring M(n, R) generated by A: the R-linear span of all powers of A. Therefore, the Euclidean division can in fact be performed within that commutative polynomial ring, and of course it then gives the same quotient B and remainder 0 as in the larger ring; in particular this shows that B in fact lies in (R[A])[t]. But in this commutative setting it is valid to set t to A in the equation  , in other words apply the evaluation map
, in other words apply the evaluation map
![\operatorname{ev}_A:(R[A])[t]\to R[A]](../I/m/29c9405596937c6afabc81d47fd092d3.png)
which is a ring homomorphism, giving

just like in the second proof, as desired.
In addition to proving the theorem, the above argument tells us that the coefficients Bi of B are polynomials in A, while from the second proof we only knew that they lie in the centralizer Z of A; in general Z is a larger subring than R[A], and not necessarily commutative. In particular the constant term  lies in R[A]. Since A is an arbitrary square matrix, this proves that adj(A) can always be expressed as a polynomial in A (with coefficients that depend on A), something that is not obvious from the definition of the adjugate matrix. In fact the equations found in the first proof allow successively expressing
lies in R[A]. Since A is an arbitrary square matrix, this proves that adj(A) can always be expressed as a polynomial in A (with coefficients that depend on A), something that is not obvious from the definition of the adjugate matrix. In fact the equations found in the first proof allow successively expressing  as polynomials in A, which leads to the identity
as polynomials in A, which leads to the identity

valid for all n×n matrices, where

is the characteristic polynomial of A. Note that this identity implies the statement of the Cayley–Hamilton theorem: one may move adj(−A) to the right hand side, multiply the resulting equation (on the left or on the right) by A, and use the fact that

A proof using matrices of endomorphisms
As was mentioned above, the matrix p(A) in statement of the theorem is obtained by first evaluating the determinant and then substituting the matrix A for t; doing that substitution into the matrix before evaluating the determinant is not meaningful. Nevertheless, it is possible to give an interpretation where p(A) is obtained directly as the value of a certain determinant, but this requires a more complicated setting, one of matrices over a ring in which one can interpret both the entries  of A, and all of A itself. One could take for this the ring M(n, R) of n×n matrices over R, where the entry is realised as
of A, and all of A itself. One could take for this the ring M(n, R) of n×n matrices over R, where the entry is realised as  , and A as itself. But considering matrices with matrices as entries might cause confusion with block matrices, which is not intended, as that gives the wrong notion of determinant (recall that the determinant of a matrix is defined as a sum of products of its entries, and in the case of a block matrix this is generally not the same as the corresponding sum of products of its blocks!). It is clearer to distinguish A from the endomorphism φ of an n-dimensional vector space V (or free R-module if R is not a field) defined by it in a basis e1, ..., en, and to take matrices over the ring End(V) of all such endomorphisms. Then φ ∈ End(V) is a possible matrix entry, while A designates the element of M(n, End(V)) whose i,j entry is endomorphism of scalar multiplication by ; similarly In will be interpreted as element of M(n, End(V)). However, since End(V) is not a commutative ring, no determinant is defined on M(n, End(V)); this can only be done for matrices over a commutative subring of End(V). Now the entries of the matrix
, and A as itself. But considering matrices with matrices as entries might cause confusion with block matrices, which is not intended, as that gives the wrong notion of determinant (recall that the determinant of a matrix is defined as a sum of products of its entries, and in the case of a block matrix this is generally not the same as the corresponding sum of products of its blocks!). It is clearer to distinguish A from the endomorphism φ of an n-dimensional vector space V (or free R-module if R is not a field) defined by it in a basis e1, ..., en, and to take matrices over the ring End(V) of all such endomorphisms. Then φ ∈ End(V) is a possible matrix entry, while A designates the element of M(n, End(V)) whose i,j entry is endomorphism of scalar multiplication by ; similarly In will be interpreted as element of M(n, End(V)). However, since End(V) is not a commutative ring, no determinant is defined on M(n, End(V)); this can only be done for matrices over a commutative subring of End(V). Now the entries of the matrix  all lie in the subring R[φ] generated by the identity and φ, which is commutative. Then a determinant map M(n, R[φ]) → R[φ] is defined, and
all lie in the subring R[φ] generated by the identity and φ, which is commutative. Then a determinant map M(n, R[φ]) → R[φ] is defined, and  evaluates to the value p(φ) of the characteristic polynomial of A at φ (this holds independently of the relation between A and φ); the Cayley–Hamilton theorem states that p(φ) is the null endomorphism.
evaluates to the value p(φ) of the characteristic polynomial of A at φ (this holds independently of the relation between A and φ); the Cayley–Hamilton theorem states that p(φ) is the null endomorphism.
In this form, the following proof can be obtained from that of (Atiyah & MacDonald 1969, Prop. 2.4) (which in fact is the more general statement related to the Nakayama lemma; one takes for the ideal in that proposition the whole ring R). The fact that A is the matrix of φ in the basis e1, ..., en means that

One can interpret these as n components of one equation in Vn, whose members can be written using the matrix-vector product M(n, End(V)) × Vn → Vn that is defined as usual, but with individual entries ψ ∈ End(V) and v in V being "multiplied" by forming  ; this gives:
; this gives:

where  is the element whose component i is ei (in other words it is the basis e1, ..., en of V written as a column of vectors). Writing this equation as
is the element whose component i is ei (in other words it is the basis e1, ..., en of V written as a column of vectors). Writing this equation as

one recognizes the transpose of the matrix considered above, and its determinant (as element of M(n, R[φ])) is also p(φ). To derive from this equation that p(φ) = 0 ∈ End(V), one left-multiplies by the adjugate matrix of 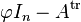 , which is defined in the matrix ring M(n, R[φ]), giving
, which is defined in the matrix ring M(n, R[φ]), giving
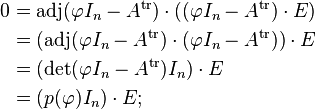
the associativity of matrix-matrix and matrix-vector multiplication used in the first step is a purely formal property of those operations, independent of the nature of the entries. Now component i of this equation says that p(φ)(ei) = 0 ∈ V; thus p(φ) vanishes on all ei, and since these elements generate V it follows that p(φ) = 0 ∈ End(V), completing the proof.
One additional fact that follows from this proof is that the matrix A whose characteristic polynomial is taken need not be identical to the value φ substituted into that polynomial; it suffices that φ be an endomorphism of V satisfying the initial equations

for some sequence of elements e1,...,en that generate V (which space might have smaller dimension than n, or in case the ring R is not a field it might not be a free module at all).
A bogus "proof": p(A) = det(AIn − A) = det(A − A) = 0
One elementary but incorrect argument for the theorem is to "simply" take the definition

and substitute A for λ, obtaining

There are many ways to see why this argument is wrong. First, in Cayley–Hamilton theorem, p(A) is an n×n matrix. However, the right hand side of the above equation is the value of a determinant, which is a scalar. So they cannot be equated unless n = 1 (i.e. A is just a scalar). Second, in the expression 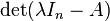 , the variable λ actually occurs at the diagonal entries of the matrix
, the variable λ actually occurs at the diagonal entries of the matrix  . To illustrate, consider the characteristic polynomial in the previous example again:
. To illustrate, consider the characteristic polynomial in the previous example again:

If one substitutes the entire matrix A for λ in those positions, one obtains

in which the "matrix" expression is simply not a valid one. Note, however, that if scalar multiples of identity matrices instead of scalars are subtracted in the above, i.e. if the substitution is performed as

then the determinant is indeed zero, but the expanded matrix in question does not evaluate to  ; nor can its determinant (a scalar) be compared to p(A) (a matrix). So the argument that
; nor can its determinant (a scalar) be compared to p(A) (a matrix). So the argument that  still does not apply.
still does not apply.
Actually, if such an argument holds, it should also hold when other multilinear forms instead of determinant is used. For instance, if we consider the permanent function and define 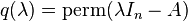 , then by the same argument, we should be able to "prove" that q(A) = 0. But this statement is demonstrably wrong. In the 2-dimensional case, for instance, the permanent of a matrix is given by
, then by the same argument, we should be able to "prove" that q(A) = 0. But this statement is demonstrably wrong. In the 2-dimensional case, for instance, the permanent of a matrix is given by
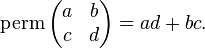
So, for the matrix A in the previous example,

Yet one can verify that

One of the proofs for Cayley–Hamilton theorem above bears some similarity to the argument that . By introducing a matrix with non-numeric coefficients, one can actually let A live inside a matrix entry, but then  is not equal to A, and the conclusion is reached differently.
is not equal to A, and the conclusion is reached differently.
Abstraction and generalizations
The above proofs show that the Cayley–Hamilton theorem holds for matrices with entries in any commutative ring R, and that p(φ) = 0 will hold whenever φ is an endomorphism of an R module generated by elements e1,...,en that satisfies

This more general version of the theorem is the source of the celebrated Nakayama lemma in commutative algebra and algebraic geometry.
See also
Remarks
- ↑ Due to the non-commutative nature of the multiplication operation for quaternions and related constructions, care needs to be taken with definitions, most notably in this context, for the determinant. The theorem holds as well for the slightly less well-behaved split-quaternions, see Alagös, Oral & Yüce (2012). The rings of quaternions and split-quaternions can both be represented by certain 2 × 2 complex matrices. (When restricted to unit norm, these are the groups SU(2) and SU(1, 1) respectively.) Therefore it is not surprising that the theorem holds.
There is no such matrix representation for the octonions, since the multiplication operation is not associative in this case. However, a modified Cayley-Hamilton theorem still holds for the octonions, see Tian (2000). - ↑ See, e.g., p. 54 of Brown 1994, which solves
 and the above derivative of p are utilized in the trace of
and the above derivative of p are utilized in the trace of
 . (cf. Hou, S. H. (1998) "Classroom Note: A Simple Proof of the Leverrier--Faddeev Characteristic Polynomial Algorithm" SIAM review 40(3) 706-709, doi:10.1137/S003614459732076X .)
. (cf. Hou, S. H. (1998) "Classroom Note: A Simple Proof of the Leverrier--Faddeev Characteristic Polynomial Algorithm" SIAM review 40(3) 706-709, doi:10.1137/S003614459732076X .)

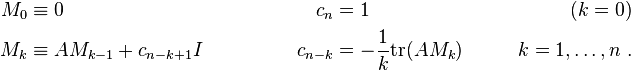

Notes
- 1 2 Crilly 1998
- 1 2 Cayley 1858, pp. 17–37
- ↑ Cayley 1889, pp. 475–496
- ↑ Atiyah & MacDonald 1969
- ↑ Hamilton 1853, p. 562
- 1 2 Hamilton 1864a
- 1 2 Hamilton 1864b
- 1 2 Hamilton 1862
- ↑ Zhang 1997
- 1 2 Frobenius 1878
- ↑ Zeni & Rodrigues 1992
- ↑ Barut, Zeni & Laufer 1994a
- ↑ Barut, Zeni & Laufer 1994b
- ↑ Laufer 1997
- ↑ Curtright, Fairlie & Zachos 2014
- ↑ Bhatia 1997, p. 7
References
- Alagös, Y.; Oral, K.; Yüce, S. (2012). "Split Quaternion Matrices". Miskolc Mathematical Notes 13 (2): 223–232. ISSN 1787-2405 (open access)
- Atiyah, M. F.; MacDonald, I. G. (1969), Introduction to Commutative Algebra, Westview Press, ISBN 0-201-40751-5
- Barut, A. O.; Zeni, J. R.; Laufer, A. (1994a). "The exponential map for the conformal group O(2,4)". J. Phys. A: Math. Gen. (IOPScience) 27 (15): 5239–5250. arXiv:hep-th/9408105. Bibcode:1994JPhA...27.5239B. doi:10.1088/0305-4470/27/15/022.
- Barut, A. O.; Zeni, J. R.; Laufer, A. (1994b). "The exponential map for the unitary group SU(2,2)". J. Phys. A: Math. Gen. (IOPScience) 27 (20): 6799–6806. arXiv:hep-th/9408145. Bibcode:1994JPhA...27.6799B. doi:10.1088/0305-4470/27/20/017.
- Bhatia, R. (1997). Matrix Analysis. Graduate texts in mathematics 169. Springer. ISBN 978-0387948461.
- Brown, Lowell S. (1994). Quantum Field Theory. Cambridge University Press. ISBN 978-0-521-46946-3.
- Cayley, A. (1858). "A Memoir on the Theory of Matrices". Phil.Trans. 148.
- Cayley, A. (1889). The Collected Mathematical Papers of Arthur Cayley. (Classic Reprint) 2. Forgotten books. ASIN B008HUED9O.
- Crilly, T. (1998). "The young Arthur Cayley". Notes Rec. R. Soc. Lond. (Royal Society) 52 (2): 267–282. doi:10.1098/rsnr.1998.0050.
- Curtright, T L; Fairlie, D B; Zachos, C K (2014). "A compact formula for rotations as spin matrix polynomials". SIGMA 10: 084. arXiv:1402.3541. Bibcode:2014SIGMA..10..084C. doi:10.3842/SIGMA.2014.084.
- Frobenius, G. (1878). "Ueber lineare Substutionen und bilineare Formen". J.reine angew Math.(Crelle J.) 84: 1–63.
- Gantmacher, F.R. (1960). The Theory of Matrices. NY: Chelsea Publishing. ISBN 0-8218-1376-5.
- Hamilton, W. R. (1853). Lectures on Quaternions. Dublin.
- Hamilton, W. R. (1864a). "On a New and General Method of Inverting a Linear and Quaternion Function of a Quaternion". Proceedings of the Royal Irish Academy (Royal Irish Academy) viii: 182–183. (communicated on June 9, 1862)
- Hamilton, W. R. (1864b). "On the Existence of a Symbolic and Biquadratic Equation, which is satisfied by the Symbol of Linear Operation in Quaternions". Proceedings of the Royal Irish Academy (Royal Irish Academy) viii: 190–101. (communicated on June 23, 1862)
- Hamilton, W. R. (1862). "On the Existence of a Symbolic and Biquadratic Equation which is satisfied by the Symbol of Linear or Distributive Operation on a Quaternion". The London, Edinburgh and Dublin Philosophical Magazine and Journal of Science. series iv (Taylor & Francis) 24: 127–128. ISSN 1478-6435. Retrieved 2015-02-14.
- Householder, Alston S. (2006). The Theory of Matrices in Numerical Analysis. Dover Books on Mathematics. ISBN 0486449726.
- Laufer, A. (1997). "The exponential map of GL(N)". J. Phys. A: Math. Gen. (IOPScience) 30 (15): 5455–5470. arXiv:hep-th/9604049. Bibcode:1997JPhA...30.5455L. doi:10.1088/0305-4470/30/15/029.
- Tian, Y. (2000). "Matrix representations of octonions and their application". Advances in Applied Clifford Algebras (Birkhäuser-Verlag) 10 (1): 61–90. arXiv:math/0003166v2. doi:10.1007/BF03042010. ISSN 0188-7009.
- Zeni, J. R.; Rodrigues, W.A. (1992). "A thoughful study of Lorentz transformations by Clifford algebras". Int. J. Mod. Phys. A (World Scientific) 7 (8): 1793 pp. Bibcode:1992IJMPA...7.1793Z. doi:10.1142/S0217751X92000776. (subscription required (help)).
- Zhang, F. (1997). "Quaternions and matrices of quaternions". Linear Algebra and its Applications (Elsevier) 251: 21–57. doi:10.1016/0024-3795(95)00543-9. ISSN 0024-3795 – via ScienceDirect (open archive).
External links
- Hazewinkel, Michiel, ed. (2001), "Cayley–Hamilton theorem", Encyclopedia of Mathematics, Springer, ISBN 978-1-55608-010-4
- A proof from PlanetMath.
- The Cayley–Hamilton theorem at MathPages