Gradient boosting
Gradient boosting is a machine learning technique for regression and classification problems, which produces a prediction model in the form of an ensemble of weak prediction models, typically decision trees. It builds the model in a stage-wise fashion like other boosting methods do, and it generalizes them by allowing optimization of an arbitrary differentiable loss function.
The idea of gradient boosting originated in the observation by Leo Breiman [1] that boosting can be interpreted as an optimization algorithm on a suitable cost function. Explicit regression gradient boosting algorithms were subsequently developed by Jerome H. Friedman[2][3] simultaneously with the more general functional gradient boosting perspective of Llew Mason, Jonathan Baxter, Peter Bartlett and Marcus Frean .[4][5] The latter two papers introduced the abstract view of boosting algorithms as iterative functional gradient descent algorithms. That is, algorithms that optimize a cost function over function space by iteratively choosing a function (weak hypothesis) that points in the negative gradient direction. This functional gradient view of boosting has led to the development of boosting algorithms in many areas of machine learning and statistics beyond regression and classification.
Informal introduction
(This section follows the exposition of gradient boosting by Li.[6])
Like other boosting methods, gradient boosting combines weak learners into a single strong learner, in an iterative fashion. It is easiest to explain in the least-squares regression setting, where the goal is to learn a model 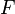 that predicts values
that predicts values  , minimizing the mean squared error
, minimizing the mean squared error  to the true values y (averaged over some training set).
to the true values y (averaged over some training set).
At each stage  of gradient boosting, it may be assumed that there is some imperfect model
of gradient boosting, it may be assumed that there is some imperfect model  (at the outset, a very weak model that just predicts the mean y in the training set could be used). The gradient boosting algorithm does not change in any way; instead, it improves on it by constructing a new model that adds an estimator h to provide a better model
(at the outset, a very weak model that just predicts the mean y in the training set could be used). The gradient boosting algorithm does not change in any way; instead, it improves on it by constructing a new model that adds an estimator h to provide a better model  . The question is now, how to find
. The question is now, how to find  ? The gradient boosting solution starts with the observation that a perfect h would imply
? The gradient boosting solution starts with the observation that a perfect h would imply

or, equivalently,
 .
.
Therefore, gradient boosting will fit h to the residual  . Like in other boosting variants, each
. Like in other boosting variants, each  learns to correct its predecessor . A generalization of this idea to other loss functions than squared error (and to classification and ranking problems) follows from the observation that residuals
learns to correct its predecessor . A generalization of this idea to other loss functions than squared error (and to classification and ranking problems) follows from the observation that residuals 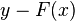 are the negative gradients of the squared error loss function
are the negative gradients of the squared error loss function  . So, gradient boosting is a gradient descent algorithm; and generalizing it entails "plugging in" a different loss and its gradient.
. So, gradient boosting is a gradient descent algorithm; and generalizing it entails "plugging in" a different loss and its gradient.
Algorithm
In many supervised learning problems one has an output variable y and a vector of input variables x connected together via a joint probability distribution 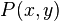 . Using a training set
. Using a training set  of known values of x and corresponding values of y, the goal is to find an approximation
of known values of x and corresponding values of y, the goal is to find an approximation 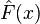 to a function
to a function  that minimizes the expected value of some specified loss function
that minimizes the expected value of some specified loss function  :
:
-
![F^* = \underset{F}{\arg\min} \, \mathbb{E}_{x,y}[L(y, F(x))]](../I/m/25883a88ae993489a62553d8da113cf5.png) .
.
Gradient boosting method assumes a real-valued y and seeks an approximation in the form of a weighted sum of functions  from some class ℋ, called base (or weak) learners:
from some class ℋ, called base (or weak) learners:
-
 .
.
In accordance with the empirical risk minimization principle, the method tries to find an approximation that minimizes the average value of the loss function on the training set. It does so by starting with a model, consisting of a constant function  , and incrementally expanding it in a greedy fashion:
, and incrementally expanding it in a greedy fashion:
-
 ,
, -
 ,
,
where 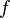 is restricted to be a function from the class ℋ of base learner functions.
is restricted to be a function from the class ℋ of base learner functions.
However, the problem of choosing at each step the best for an arbitrary loss function  is a hard optimization problem in general, and so we'll "cheat" by solving a much easier problem instead.
is a hard optimization problem in general, and so we'll "cheat" by solving a much easier problem instead.
The idea is to apply a steepest descent step to this minimization problem. If we only cared about predictions at the points of the training set, and were unrestricted, we'd update the model per the following equation, where we view  not as a functional of , but as a function of a vector of values
not as a functional of , but as a function of a vector of values  :
:


But as must come from a restricted class of functions (that's what allows us to generalize), we'll just choose the one that most closely approximates the gradient of . Having chosen , the multiplier 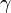 is then selected using line search just as shown in the second equation above.
is then selected using line search just as shown in the second equation above.
In pseudocode, the generic gradient boosting method is:[2][7]
Input: training set  a differentiable loss function
a differentiable loss function  number of iterations
number of iterations 
Algorithm:
- Initialize model with a constant value:
-
- For m = 1 to M:
- Compute so-called pseudo-residuals:
-
- Fit a base learner
 to pseudo-residuals, i.e. train it using the training set
to pseudo-residuals, i.e. train it using the training set  .
. - Compute multiplier
 by solving the following one-dimensional optimization problem:
by solving the following one-dimensional optimization problem:
-
- Update the model:
-
- Compute so-called pseudo-residuals:
- Output


![r_{im} = -\left[\frac{\partial L(y_i, F(x_i))}{\partial F(x_i)}\right]_{F(x)=F_{m-1}(x)} \quad \mbox{for } i=1,\ldots,n.](../I/m/0bebe45631e9a1c4ed693590d60829c0.png)


Gradient tree boosting
Gradient boosting is typically used with decision trees (especially CART trees) of a fixed size as base learners. For this special case Friedman proposes a modification to gradient boosting method which improves the quality of fit of each base learner.
Generic gradient boosting at the m-th step would fit a decision tree to pseudo-residuals. Let  be the number of its leaves. The tree partitions the input space into disjoint regions
be the number of its leaves. The tree partitions the input space into disjoint regions  and predicts a constant value in each region. Using the indicator notation, the output of for input x can be written as the sum:
and predicts a constant value in each region. Using the indicator notation, the output of for input x can be written as the sum:

where  is the value predicted in the region
is the value predicted in the region  .[8]
.[8]
Then the coefficients are multiplied by some value , chosen using line search so as to minimize the loss function, and the model is updated as follows:

Friedman proposes to modify this algorithm so that it chooses a separate optimal value  for each of the tree's regions, instead of a single for the whole tree. He calls the modified algorithm "TreeBoost". The coefficients from the tree-fitting procedure can be then simply discarded and the model update rule becomes:
for each of the tree's regions, instead of a single for the whole tree. He calls the modified algorithm "TreeBoost". The coefficients from the tree-fitting procedure can be then simply discarded and the model update rule becomes:

Size of trees
, the number of terminal nodes in trees, is the method's parameter which can be adjusted for a data set at hand. It controls the maximum allowed level of interaction between variables in the model. With  (decision stumps), no interaction between variables is allowed. With
(decision stumps), no interaction between variables is allowed. With  the model may include effects of the interaction between up to two variables, and so on.
the model may include effects of the interaction between up to two variables, and so on.
Hastie et al.[7] comment that typically  work well for boosting and results are fairly insensitive to the choice of
work well for boosting and results are fairly insensitive to the choice of 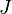 in this range,
in this range, 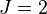 is insufficient for many applications, and
is insufficient for many applications, and  is unlikely to be required.
is unlikely to be required.
Regularization
Fitting the training set too closely can lead to degradation of the model's generalization ability. Several so-called regularization techniques reduce this overfitting effect by constraining the fitting procedure.
One natural regularization parameter is the number of gradient boosting iterations M (i.e. the number of trees in the model when the base learner is a decision tree). Increasing M reduces the error on training set, but setting it too high may lead to overfitting. An optimal value of M is often selected by monitoring prediction error on a separate validation data set. Besides controlling M, several other regularization techniques are used.
Shrinkage
An important part of gradient boosting method is regularization by shrinkage which consists in modifying the update rule as follows:

where parameter 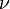 is called the "learning rate".
is called the "learning rate".
Empirically it has been found that using small learning rates (such as  ) yields dramatic improvements in model's generalization ability over gradient boosting without shrinking (
) yields dramatic improvements in model's generalization ability over gradient boosting without shrinking ( ).[7]
However, it comes at the price of increasing computational time both during training and querying: lower learning rate requires more iterations.
).[7]
However, it comes at the price of increasing computational time both during training and querying: lower learning rate requires more iterations.
Stochastic gradient boosting
Soon after the introduction of gradient boosting Friedman proposed a minor modification to the algorithm, motivated by Breiman's bagging method.[3] Specifically, he proposed that at each iteration of the algorithm, a base learner should be fit on a subsample of the training set drawn at random without replacement.[9] Friedman observed a substantial improvement in gradient boosting's accuracy with this modification.
Subsample size is some constant fraction f of the size of the training set. When f = 1, the algorithm is deterministic and identical to the one described above. Smaller values of f introduce randomness into the algorithm and help prevent overfitting, acting as a kind of regularization. The algorithm also becomes faster, because regression trees have to be fit to smaller datasets at each iteration. Friedman[3] obtained that  leads to good results for small and moderate sized training sets. Therefore, f is typically set to 0.5, meaning that one half of the training set is used to build each base learner.
leads to good results for small and moderate sized training sets. Therefore, f is typically set to 0.5, meaning that one half of the training set is used to build each base learner.
Also, like in bagging, subsampling allows one to define an out-of-bag error of the prediction performance improvement by evaluating predictions on those observations which were not used in the building of the next base learner. Out-of-bag estimates help avoid the need for an independent validation dataset, but often underestimate actual performance improvement and the optimal number of iterations.[10]
Number of observations in leaves
Gradient tree boosting implementations often also use regularization by limiting the minimum number of observations in trees' terminal nodes (this parameter is called n.minobsinnode in the R gbm package[10]). It is used in the tree building process by ignoring any splits that lead to nodes containing fewer than this number of training set instances.
Imposing this limit helps to reduce variance in predictions at leaves.
Penalize Complexity of Tree
Another useful regularization techniques for gradient boosted trees is to penalize model complexity of the learned model. [11] The model complexity can be defined proportional number of leaves in the learned trees. The jointly optimization of loss and model complexity corresponds to a post-pruning algorithm to remove branches that fail to reduce the loss by a threshold. Other kinds of regularization such as l2 penalty on the leave values can also be added to avoid overfitting.
Usage
Recently, gradient boosting has gained some popularity in the field of learning to rank. The commercial web search engines Yahoo[12] and Yandex[13] use variants of gradient boosting in their machine-learned ranking engines.
Names
The method goes by a variety of names. Friedman introduced his regression technique as a "Gradient Boosting Machine" (GBM).[2] Mason, Baxter et. el. described the generalized abstract class of algorithms as "functional gradient boosting".[4][5]
A popular open-source implementation[10] for R calls it "Generalized Boosting Model". Commercial implementations from Salford Systems use the names "Multiple Additive Regression Trees" (MART) and TreeNet, both trademarked.
See also
References
- ↑ Breiman, L. "Arcing The Edge" (June 1997)
- 1 2 3 Friedman, J. H. "Greedy Function Approximation: A Gradient Boosting Machine." (February 1999)
- 1 2 3 Friedman, J. H. "Stochastic Gradient Boosting." (March 1999)
- 1 2 Mason, L.; Baxter, J.; Bartlett, P. L.; Frean, Marcus (1999). "Boosting Algorithms as Gradient Descent" (PDF). In S.A. Solla and T.K. Leen and K. Müller. Advances in Neural Information Processing Systems 12. MIT Press. pp. 512–518.
- 1 2 Mason, L.; Baxter, J.; Bartlett, P. L.; Frean, Marcus (May 1999). Boosting Algorithms as Gradient Descent in Function Space (PDF).
- ↑ Cheng Li. "A Gentle Introduction to Gradient Boosting" (PDF). Northeastern University. Retrieved 19 August 2014.
- 1 2 3 Hastie, T.; Tibshirani, R.; Friedman, J. H. (2009). "10. Boosting and Additive Trees". The Elements of Statistical Learning (2nd ed.). New York: Springer. pp. 337–384. ISBN 0-387-84857-6.
- ↑ Note: in case of usual CART trees, the trees are fitted using least-squares loss, and so the coefficient
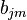 for the region
for the region  is equal to just the value of output variable, averaged over all training instances in .
is equal to just the value of output variable, averaged over all training instances in . - ↑ Note that this is different from bagging, which samples with replacement because it uses samples of the same size as the training set.
- 1 2 3 Ridgeway, Greg (2007). Generalized Boosted Models: A guide to the gbm package.
- ↑ Tianqi Chen. Introduction to Boosted Trees
- ↑ Cossock, David and Zhang, Tong (2008). Statistical Analysis of Bayes Optimal Subset Ranking, page 14.
- ↑ Yandex corporate blog entry about new ranking model "Snezhinsk" (in Russian)