Generalized normal distribution
The generalized normal distribution or generalized Gaussian distribution (GGD) is either of two families of parametric continuous probability distributions on the real line. Both families add a shape parameter to the normal distribution. To distinguish the two families, they are referred to below as "version 1" and "version 2". However this is not a standard nomenclature.
Version 1
|
Probability density function
| |
|
Cumulative distribution function
| |
| Parameters |
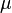 location (real) location (real)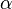 scale (positive, real) scale (positive, real) shape (positive, real) shape (positive, real) |
|---|---|
| Support |
 |
 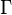 denotes the gamma function denotes the gamma function | |
| CDF |
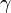 denotes the lower incomplete gamma function denotes the lower incomplete gamma function |
| Mean |
|
| Median |
|
| Mode |
|
| Variance |
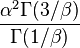 |
| Skewness | 0 |
| Ex. kurtosis |
 |
| Entropy |
![\frac{1}{\beta}-\log\left[\frac{\beta}{2\alpha\Gamma(1/\beta)}\right]](../I/m/b0092562a1469d656d32a73cb1bdbc8e.png) [1] [1] |


![\frac{1}{2} + \sgn(x-\mu)\frac{\gamma\left[1/\beta, \left( \frac{|x-\mu|}{\alpha} \right)^\beta\right]}{2\Gamma(1/\beta)}](../I/m/a80448119884003b4273c10740e34250.png)
Known also as the exponential power distribution, or the generalized error distribution, this is a parametric family of symmetric distributions. It includes all normal and Laplace distributions, and as limiting cases it includes all continuous uniform distributions on bounded intervals of the real line.
This family includes the normal distribution when 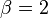 (with mean
(with mean 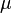 and variance
and variance 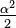 ) and it includes the Laplace distribution when
) and it includes the Laplace distribution when  . As
. As 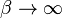 , the density converges pointwise to a uniform density on
, the density converges pointwise to a uniform density on  .
.
This family allows for tails that are either heavier than normal (when 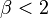 ) or lighter than normal (when
) or lighter than normal (when 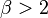 ). It is a useful way to parametrize a continuum of symmetric, platykurtic densities spanning from the normal () to the uniform density (
). It is a useful way to parametrize a continuum of symmetric, platykurtic densities spanning from the normal () to the uniform density (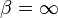 ), and a continuum of symmetric, leptokurtic densities spanning from the Laplace () to the normal density ().
), and a continuum of symmetric, leptokurtic densities spanning from the Laplace () to the normal density ().
Parameter estimation
Parameter estimation via maximum likelihood and the method of moments has been studied.[2] The estimates do not have a closed form and must be obtained numerically. Estimators that do not require numerical calculation have also been proposed.[3]
The generalized normal log-likelihood function has infinitely many continuous derivates (i.e. it belongs to the class C∞ of smooth functions) only if 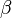 is a positive, even integer. Otherwise, the function has
is a positive, even integer. Otherwise, the function has 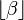 continuous derivatives. As a result, the standard results for consistency and asymptotic normality of maximum likelihood estimates of
continuous derivatives. As a result, the standard results for consistency and asymptotic normality of maximum likelihood estimates of 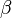 only apply when
only apply when  .
.
Maximum likelihood estimator
It is possible to fit the generalized normal distribution adopting an approximate maximum likelihood method.[4][5] With 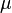 initially set to the sample first moment
initially set to the sample first moment 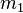 ,
is estimated by using a Newton-Raphson iterative procedure, starting from an initial guess of
,
is estimated by using a Newton-Raphson iterative procedure, starting from an initial guess of  ,
,
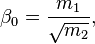
where

is the first statistical moment of the absolute values and 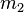 is the second statistical moment. The iteration is
is the second statistical moment. The iteration is
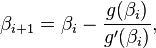
where
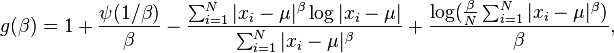
and

and where 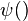 and
and 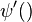 are the digamma function and trigamma function.
are the digamma function and trigamma function.
Given a value for , it is possible to estimate by finding the minimum of:
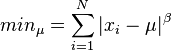
Finally  is evaluated as
is evaluated as
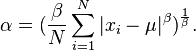
Applications
This version of the generalized normal distribution has been used in modeling when the concentration of values around the mean and the tail behavior are of particular interest.[6][7] Other families of distributions can be used if the focus is on other deviations from normality. If the symmetry of the distribution is the main interest, the skew normal family or version 2 of the generalized normal family discussed below can be used. If the tail behavior is the main interest, the student t family can be used, which approximates the normal distribution as the degrees of freedom grows to infinity. The t distribution, unlike this generalized normal distribution, obtains heavier than normal tails without acquiring a cusp at the origin.
Properties
The multivariate generalized normal distribution, i.e. the product of  exponential power distributions with the same and
exponential power distributions with the same and  parameters, is the only probability density that can be written in the form
parameters, is the only probability density that can be written in the form 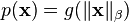 and has independent marginals.[8] The results for the special case of the Multivariate normal distribution is originally attributed to Maxwell.[9]
and has independent marginals.[8] The results for the special case of the Multivariate normal distribution is originally attributed to Maxwell.[9]
Version 2
|
Probability density function
| |
|
Cumulative distribution function
| |
| Parameters |
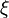 location (real) scale (positive, real) location (real) scale (positive, real)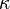 shape (real) shape (real) |
|---|---|
| Support |
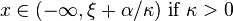  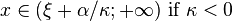 |
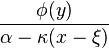 , where , where ![y = \begin{cases} - \frac{1}{\kappa} \log \left[ 1- \frac{\kappa(x-\xi)}{\alpha} \right] & \text{if } \kappa \neq 0 \\ \frac{x-\xi}{\alpha} & \text{if } \kappa=0 \end{cases}](../I/m/ca2d6327a2ecf3039a2234b9e588a4ab.png) 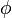 is the standard normal pdf is the standard normal pdf | |
| CDF |
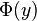 , where , where  is the standard normal CDF is the standard normal CDF |
| Mean |
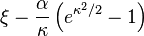 |
| Median |
|
| Variance |
 |
| Skewness |
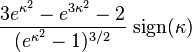 |
| Ex. kurtosis |
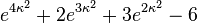 |


This is a family of continuous probability distributions in which the shape parameter can be used to introduce skew.[10][11] When the shape parameter is zero, the normal distribution results. Positive values of the shape parameter yield left-skewed distributions bounded to the right, and negative values of the shape parameter yield right-skewed distributions bounded to the left. Only when the shape parameter is zero is the density function for this distribution positive over the whole real line: in this case the distribution is a normal distribution, otherwise the distributions are shifted and possibly reversed log-normal distributions.
Parameter estimation
Parameters can be estimated via maximum likelihood estimation or the method of moments. The parameter estimates do not have a closed form, so numerical calculations must be used to compute the estimates. Since the sample space (the set of real numbers where the density is non-zero) depends on the true value of the parameter, some standard results about the performance of parameter estimates will not automatically apply when working with this family.
Applications
This family of distributions can be used to model values that may be normally distributed, or that may be either right-skewed or left-skewed relative to the normal distribution. The skew normal distribution is another distribution that is useful for modeling deviations from normality due to skew. Other distributions used to model skewed data include the gamma, lognormal, and Weibull distributions, but these do not include the normal distributions as special cases.
Other distributions related to the normal
The two generalized normal families described here, like the skew normal family, are parametric families that extends the normal distribution by adding a shape parameter. Due to the central role of the normal distribution in probability and statistics, many distributions can be characterized in terms of their relationship to the normal distribution. For example, the lognormal, folded normal, and inverse normal distributions are defined as transformations of a normally-distributed value, but unlike the generalized normal and skew-normal families, these do not include the normal distributions as special cases.
See also
References
- ↑ Nadarajah, Saralees (September 2005). "A generalized normal distribution". Journal of Applied Statistics 32 (7): 685–694. doi:10.1080/02664760500079464.
- ↑ Varanasi, M.K.; Aazhang, B. (October 1989). "Parametric generalized Gaussian density estimation". Journal of the Acoustical Society of America 86 (4): 1404–1415. doi:10.1121/1.398700.
- ↑ Domínguez-Molina, J. Armando; González-Farías, Graciela; Rodríguez-Dagnino, Ramón M. "A practical procedure to estimate the shape parameter in the generalized Gaussian distribution" (PDF). Retrieved 2009-03-03.
- ↑ Varanasi, M.K.; Aazhang B. (1989). "Parametric generalized Gaussian density estimation". J. Acoust. Soc. Am. 86: 1404–1415. doi:10.1121/1.398700.
- ↑ Do, M.N.; Vetterli, M. (February 2002). "Wavelet-based Texture Retrieval Using Generalised Gaussian Density and Kullback-Leibler Distance". Transaction on Image Processing 11: 146–158. doi:10.1109/83.982822.
- ↑ Liang, Faming; Liu, Chuanhai; Wang, Naisyin (April 2007). "A robust sequential Bayesian method for identification of differentially expressed genes". Statistica Sinica 17 (2): 571–597. Retrieved 2009-03-03.
- ↑ Box, George E. P.; Tiao, George C. (1992). Bayesian Inference in Statistical Analysis. New York: Wiley. ISBN 0-471-57428-7.
- ↑ Sinz, Fabian; Gerwinn, Sebastian; Bethge, Matthias (May 2009). "Characterization of the p-Generalized Normal Distribution.". Journal of Multivariate Analysis 100 (5): 817–820. doi:10.1016/j.jmva.2008.07.006.
- ↑ Kac, M. (1939). "On a characterization of the normal distribution". American Journal of Mathematics 61 (3): 726–728. doi:10.2307/2371328.
- ↑ Hosking, J.R.M., Wallis, J.R. (1997) Regional frequency analysis: an approach based on L-moments, Cambridge University Press. ISBN 0-521-43045-3. Section A.8
- ↑ Documentation for the lmomco R package
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||