Generalized additive model
In statistics, a generalized additive model (GAM) is a generalized linear model in which the linear predictor depends linearly on unknown smooth functions of some predictor variables, and interest focuses on inference about these smooth functions. GAMs were originally developed by Trevor Hastie and Robert Tibshirani[1] to blend properties of generalized linear models with additive models.
The model relates a univariate response variable, Y, to some predictor variables, xi. An exponential family distribution is specified for Y (for example normal, binomial or Poisson distributions) along with a link function g (for example the identity or log functions) relating the expected value of Y to the predictor variables via a structure such as
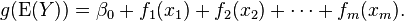
The functions fi(xi) may be functions with a specified parametric form (for example a polynomial, or a coefficient depending on the levels of a factor variable) or may be specified non-parametrically, or semi-parametrically, simply as 'smooth functions', to be estimated by non-parametric means. So a typical GAM might use a scatterplot smoothing function, such as a locally weighted mean, for f1(x1), and then use a factor model for f2(x2). This flexibility to allow non-parametric fits with relaxed assumptions on the actual relationship between response and predictor, provides the potential for better fits to data than purely parametric models, but arguably with some loss of interpretability.
Theoretical Background
It had been known since the 1950s (via. the Kolmogorov–Arnold representation theorem) that any multivariate function could be represented as sums and compositions of univariate functions. This decomposition is always possible, but may be very difficult to approximate, or even to write down. For example...

For arbitrary continuous univariate functions  ,
,  , and
, and  (with invertible). The family of all such functions can then be referred to as
(with invertible). The family of all such functions can then be referred to as 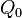 . This approach can then be iterated inductively. Here
. This approach can then be iterated inductively. Here 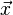 is written in place of
is written in place of 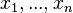 .
.
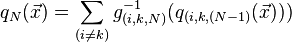
In this version, the functions  are simply individual examples from the family
are simply individual examples from the family 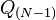 . The Kolmogorov–Arnold representation theorem then states that every multivariate function
. The Kolmogorov–Arnold representation theorem then states that every multivariate function 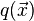 is a member of
is a member of 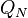 for some finite
for some finite 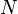 . An efficient mechanism to discover this representation would mean that given arbitrarily large amounts of data, the exact functional form of any phenomenon could always be recovered.
. An efficient mechanism to discover this representation would mean that given arbitrarily large amounts of data, the exact functional form of any phenomenon could always be recovered.
Unfortunately, there is no known mechanism whereby this recovery can be performed efficiently. Though the Kolmogorov–Arnold representation theorem asserts the existence of a function of this form, it gives no mechanism whereby one could be constructed. It is not clear that any step-wise (i.e. backfitting algorithm) approach could approach even an approximate solution. Therefore, the Generalized Additive Model[1] drops some of this complexity, and demands instead that the function belong to a simpler class.

When this function is approximating the expectation of some observed quantity, it could be written as
Which is the standard formulation of a Generalized Additive Model. It was then shown[1] that the backfitting algorithm will always converge for these functions.
Non-Parametric GAMs
The original GAMs were a form of Nonparametric regression, and estimated using the backfitting algorithm,[1] which provides a very general modular estimation method capable of using a wide variety of smoothing methods to estimate the fᵢ(xᵢ). The advantage of non-parametric models is that they are easy and efficient to fit. A disadvantage is that backfitting is difficult to integrate with well founded methods for choosing the degree of smoothness of the fᵢ(xᵢ). This is analogous to problems in semi-parametric models related to choosing the allowed complexity (i.e. number of parameters) of allowable models.
The inability to control the complexity of the model often gives rise to problems with interpretation. For instance, the non-parametric method may produce very complicated responses to input variables that could include a lot of behavior that is not statistically significant, or especially material. In many applications, it is important to have a compact and statistically significant representation of a problem, and non-parametric methods are not well suited to this use case.
Parametric GAMs
As a result alternative methods have been developed in which smooth functions are represented semi-parametrically, using penalized regression splines,[2] in order to allow computationally efficient estimation of the degree of smoothness of the model components using generalized cross validation[3] or similar criteria.
Typically, as in the examples above, fully parametric models will not be used. It is generally more effective to allow the models to be chosen from a family with an arbitrary (unbounded) number of parameters, and then limit the resulting model in some way. Wood's[2] examples uses cubic splines and a penalty term, but delegates most of the computation to R.
For problems that are more information theoretic (i.e. built on log-likelihood and related to discrete observations), it is more appropriate to use an information criterion (e.g. Akaike Information Criterion). For these information theoretic models, typically a cubic spline (or polynomial) is an inappropriate choice of basis, and may be hard to generate automatically. In an alternative formulation,[4] analytical curves are used instead. This can be easier to automatically generate, and has the advantage of being somewhat more resistant to classical overfitting than a typical penalized regression.
Typically, any semi-parameteric approach would be combined with an a-priori limit on complexity, especially in cases where the dataset is very large and might otherwise support a huge number of parameters. Without this limitation, these models could generate a large number of immaterial (but statistically significant) effects, especially in the presence of very large datasets (with large Effective Sample Size) where available complexity may be almost unbounded. The inclusion of immaterial effects is not overfitting, and does little harm, but it may reduce the computational efficiency of the model, and also impact its interpretability.
Estimation
Overfitting can be a problem with GAMs.[5] The number of smoothing parameters can be specified, and this number should be reasonably small, certainly well under the degrees of freedom offered by the data. Cross-validation can be used to detect and/or reduce overfitting problems with GAMs (or other statistical methods).[6]
If the Akaike Information Criterion is used, the model can become highly resistant to overfitting (in the sense of fitting noise) subject to certain conditions. These conditions require that the base model (e.g. the model with just an intercept term) is statistically significant, that the observations are independent conditional on the regressors, and that none of the regressors are highly colinear. Generally, independence of observations is assumed, but not assured, and thus Cross-validation is still prudent. Strictly speaking, provided the conditions above are met, two GAMs constructed via [4] or a similar method should produce statistically indistinguishable predictions for random draws from the distribution that generated the fitting data. For such a model, failures in Cross-validation would indicate that some regressors are highly colinear or that the effective observation count along some dimensions is much smaller than the actual observation count (i.e. the observations are not independent). Problems related to regressor colinearity are not typically severe for these models, but failures due to lack of conditional independence of the observations could generate highly misleading projections.
Other models such as GLMs may be preferable to GAMs unless GAMs improve predictive ability substantially (in validation sets) for the application in question.
See also
- Additive model
- Backfitting algorithm
- Generalized additive model for location, scale, and shape (GAMLSS)
- Hilbert's thirteenth problem
- Nomogram
- Residual effective degrees of freedom
References
- 1 2 3 4 Hastie, T. J.; Tibshirani, R. J. (1990). Generalized Additive Models. Chapman & Hall/CRC. ISBN 978-0-412-34390-2.
- 1 2 Wood, S. N. (2006). Generalized Additive Models: An Introduction with R. Chapman & Hall/CRC. ISBN 978-1-58488-474-3.
- ↑ Wood, S.N. (2000) Modelling and smoothing parameter estimation with multiple quadratic penalties. Journal of the Royal Statistical Society: Series B 62(2),413-428.
- 1 2 Tyler Ward (November 5, 2014). "The Information Theoretically Efficient Model" (pdf).
- ↑ Wood, Simon N. (2008). "Fast stable direct fitting and smoothness selection for generalized additive models". Journal of the Royal Statistical Society: Series B (Statistical Methodology) 70 (3): 495–518. doi:10.1111/j.1467-9868.2007.00646.x.
- ↑ Brian Junker (March 22, 2010). "Additive models and cross-validation" (pdf).
External links
- gam, an R package for GAMs by backfitting
- mgcv, an R package for GAMs using penalized regression splines
- GAM: The Predictive Modeling Silver Bullet