Generalization error
In supervised learning applications in machine learning and statistical learning theory, generalization error (also known as the out-of-sample error[1]) is a measure of how accurately an algorithm is able to predict outcome values for previously unseen data. Because learning algorithms are evaluated on finite samples, the evaluation of a learning algorithm may be sensitive to sampling error. As a result, measurements of prediction error on the current data may not provide much information about predictive ability on new data. Generalization error can be minimized by avoiding overfitting in the learning algorithm. The performance of a machine learning algorithm is measured by plots of the generalization error values through the learning process and are called learning curve.
Definition
In a learning problem, the goal is to develop a function 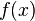 that predicts output values
that predicts output values 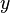 based on some input data
based on some input data  . The expected error,
. The expected error, ![I[f_n]](../I/m/47ade760dd0da9ea924c43db781c93af.png) of a particular function
of a particular function 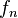 over all possible values of x and y is:
over all possible values of x and y is:
![I[f_n] = \int_{X \times Y} V(f_n(x),y) \rho(x,y) dx dy,](../I/m/89759b507ad1a3eff2eb2fc55a11f374.png)
where 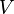 denotes a loss function and
denotes a loss function and 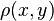 is the unknown joint probability distribution for and .
is the unknown joint probability distribution for and .
Without knowing the joint probability distribution, it is impossible to compute I[f]. Instead, we can compute the empirical error on sample data. Given 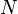 data points, the empirical error is:
data points, the empirical error is:
![I_S[f_n] = \frac{1}{n} \sum_{i=1}^n V(f_n(x_i),y_i)](../I/m/be7f9402ffc5f7353f7e6c7fc6617697.png)
The generalization error is the difference between the expected and empirical error. This is the difference between error on the training set and error on the underlying joint probability distribution. It is defined as:
![G = I[f_n] - I_S[f_n]](../I/m/6e4e7cb487dfe227cf3f93ca9a0a040e.png)
An algorithm is said to generalize if:
![\lim_{n \rightarrow \infty} I[f_n] - I_S[f_n] = 0](../I/m/9795397a6c4b265067bc63bcf32cf393.png)
Since cannot be computed for an unknown probability distribution, the generalization error cannot be computed either. Instead, the aim of many problems in statistical learning theory is to bound or characterize the generalization error in probability:
![P_G = P(I(f_n) - I_S[f_n]) \leq \epsilon) \geq 1 - \delta_n](../I/m/f21cbec5a2135e303a44ef47433235a7.png)
That is, the goal is to characterize the probability 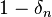 that the generalization error is less than some error bound
that the generalization error is less than some error bound  (known as the learning rate and generally dependent on
(known as the learning rate and generally dependent on 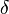 and
and  .
.
Relation to stability
For many types of algorithms, it has been shown that an algorithm has generalization bounds if it meets certain stability criteria. Specifically, if an algorithm is symmetric (the order of inputs does not affect the result), has bounded loss and meets two stability conditions, it will generalize. The first stability condition, leave-one-out cross-validation stability, says that to be stable, the prediction error for each data point when leave-one-out cross validation is used must converge to zero as 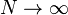 . The second condition, expected-to-leave-one-out error stability (also known as hypothesis stability if operating in the
. The second condition, expected-to-leave-one-out error stability (also known as hypothesis stability if operating in the 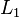 norm) is met if the prediction on a left-out datapoint does not change when a single data point is removed from the training dataset.[2]
norm) is met if the prediction on a left-out datapoint does not change when a single data point is removed from the training dataset.[2]
These conditions can be formalized as:
Leave-one-out cross-validation Stability
An algorithm  has CVloo stability if for each n, there exists a
has CVloo stability if for each n, there exists a 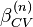 and
and 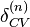 such that:
such that:
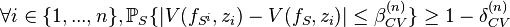
and and go to zero as N goes to infinity.[3]
Expected-leave-one-out error Stability
An algorithm has 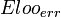 stability if for each n there exists a
stability if for each n there exists a  and a
and a  such that:
such that:
![\forall i\in\{1,...,n\}, \mathbb{P}_S\{|I[f_S]-\frac{1}{n}\sum_{i=1}^N V(f_{S^{i}},z_i)|\leq\beta_{EL}^{(n)}\}\geq1-\delta_{EL}^{(n)}](../I/m/73e975ceb612801a51fa8fa9d375657c.png)
with and going to zero for  .
.
For leave-one-out stability in the norm, this is the same as hypothesis stability:
![\mathbb{E}_{S,z}[|V(f_S,z) - V(f_{S^i},z)|] \leq \beta_H^{(n)}](../I/m/9287f64e6d5a8f80798a6d9a843678f9.png)
with 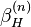 going to zero as N goes to infinity.[4]
going to zero as N goes to infinity.[4]
Algorithms with proven stability
A number of algorithms have been proven to be stable and as a result have bounds on their generalization error. A list of these algorithms and the papers that proved stability is available here.
Relation to overfitting
The concepts of generalization error and overfitting are closely related. Overfitting occurs when the learned function  becomes sensitive to the noise in the sample. As a result, the function will perform well on the training set but not perform well on other data from the joint probability distribution of x and y. Thus, the more overfitting occurs, the larger the generalization error.
becomes sensitive to the noise in the sample. As a result, the function will perform well on the training set but not perform well on other data from the joint probability distribution of x and y. Thus, the more overfitting occurs, the larger the generalization error.
The amount of overfitting can be tested using cross-validation methods, which splits the sample into simulated training samples and testing samples. The model is then trained on a training sample and evaluated on the testing sample. The testing sample is previously unseen by the algorithm and so represents a random sample from the joint probability distribution of x and y. This test sample allows us to approximate the expected error and as a result approximate a particular form of the generalization error.
Many algorithms exists to prevent overfitting. The minimization algorithm can penalize more complex functions (known as Tikhonov regularization, or the hypothesis space can be constrained, either explicitly in the form of the functions or by adding constraints to the minimization function (Ivanov regularization).
The approach to finding a function that does not overfit is at odds with the goal of finding a function that is sufficiently complex to capture the particular characteristics of the data. This is known as the bias–variance tradeoff. Keeping a function simple to avoid overfitting may introduce a bias in the resulting predictions, while allowing it to be more complex leads to overfitting and a higher variance in the predictions. It is impossible to minimize both simultaneously.
References
- ↑ Y S. Abu-Mostafa, M.Magdon-Ismail, and H.-T. Lin (2012) Learning from Data, AMLBook Press. ISBN 978-1600490064
- ↑ S. Mukherjee, P. Niyogi, T. Poggio, and R. M. Rifkin. Learning theory: stability is sufficient for generalization and necessary and sufficient for consistency of empirical risk minimization. Adv. Comput. Math., 25(1-3):161–193, 2006.
- ↑ S. Mukherjee, P. Niyogi, T. Poggio, and R. M. Rifkin. Learning theory: stability is sufficient for generalization and necessary and sufficient for consistency of empirical risk minimization. Adv. Comput. Math., 25(1-3):161–193, 2006.
- ↑ S. Mukherjee, P. Niyogi, T. Poggio, and R. M. Rifkin. Learning theory: stability is sufficient for generalization and necessary and sufficient for consistency of empirical risk minimization. Adv. Comput. Math., 25(1-3):161–193, 2006.
Additional literature
- Bousquet, O., S. Boucheron and G. Lugosi. Introduction to Statistical Learning Theory. Advanced Lectures on Machine Learning Lecture Notes in Artificial Intelligence 3176, 169-207. (Eds.) Bousquet, O., U. von Luxburg and G. Ratsch, Springer, Heidelberg, Germany (2004)
- Bousquet, O. and A. Elisseef (2002), Stability and Generalization, Journal of Machine Learning Research, 499-526.
- Devroye L. , L. Gyorfi, and G. Lugosi (1996). A Probabilistic Theory of Pattern Recognition. Springer-Verlag. ISBN 978-0387946184.
- Poggio T. and S. Smale. The Mathematics of Learning: Dealing with Data. Notices of the AMS, 2003
- Vapnik, V. (2000). The Nature of Statistical Learning Theory. Information Science and Statistics. Springer-Verlag. ISBN 978-0-387-98780-4.
- Bishop, C.M. (1995), Neural Networks for Pattern Recognition, Oxford: Oxford University Press, especially section 6.4.
- Finke, M., and Müller, K.-R. (1994), "Estimating a-posteriori probabilities using stochastic network models," in Mozer, Smolensky, Touretzky, Elman, & Weigend, eds., Proceedings of the 1993 Connectionist Models Summer School, Hillsdale, NJ: Lawrence Erlbaum Associates, pp. 324–331.
- Geman, S., Bienenstock, E. and Doursat, R. (1992), "Neural Networks and the Bias/Variance Dilemma", Neural Computation, 4, 1-58.
- Husmeier, D. (1999), Neural Networks for Conditional Probability Estimation: Forecasting Beyond Point Predictions, Berlin: Springer Verlag, ISBN 1-85233-095-3.
- McCullagh, P. and Nelder, J.A. (1989) Generalized Linear Models, 2nd ed., London: Chapman & Hall.
- Moody, J.E. (1992), "The Effective Number of Parameters: An Analysis of Generalization and Regularization in Nonlinear Learning Systems", in Moody, J.E., Hanson, S.J., and Lippmann, R.P., Advances in Neural Information Processing Systems 4, 847-854.
- Ripley, B.D. (1996) Pattern Recognition and Neural Networks, Cambridge: Cambridge University Press.
- Rohwer, R., and van der Rest, J.C. (1996), "Minimum description length, regularization, and multimodal data," Neural Computation, 8, 595-609.
- Rojas, R. (1996), "A short proof of the posterior probability property of classifier neural networks," Neural Computation, 8, 41-43.
- White, H. (1990), "Connectionist Nonparametric Regression: Multilayer Feedforward Networks Can Learn Arbitrary Mappings," Neural Networks, 3, 535-550. Reprinted in White (1992).
- White, H. (1992a), "Nonparametric Estimation of Conditional Quantiles Using Neural Networks," in Page, C. and Le Page, R. (eds.), Proceedings of the 23rd Sympsium on the Interface: Computing Science and Statistics, Alexandria, VA: American Statistical Association, pp. 190–199. Reprinted in White (1992b).
- White, H. (1992b), Artificial Neural Networks: Approximation and Learning Theory, Blackwell.