Functional decomposition
Functional decomposition refers broadly to the process of resolving a functional relationship into its constituent parts in such a way that the original function can be reconstructed (i.e., recomposed) from those parts by function composition. In general, this process of decomposition is undertaken either for the purpose of gaining insight into the identity of the constituent components (which may reflect individual physical processes of interest, for example), or for the purpose of obtaining a compressed representation of the global function, a task which is feasible only when the constituent processes possess a certain level of modularity (i.e., independence or non-interaction). Interactions between the components are critical to the function of the collection. All interactions may not be observable, but possibly deduced through repetitive perception, synthesis, validation and verification of composite behavior.
Basic mathematical definition
For a multivariate function 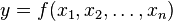 , functional decomposition generally refers to a process of identifying a set of functions
, functional decomposition generally refers to a process of identifying a set of functions 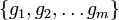 such that
such that
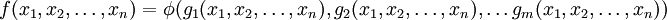
where 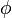 is some other function. Thus, we would say that the function
is some other function. Thus, we would say that the function 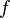 is decomposed into functions . This process is intrinsically hierarchical in the sense that we can (and often do) seek to further decompose the functions
is decomposed into functions . This process is intrinsically hierarchical in the sense that we can (and often do) seek to further decompose the functions 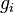 into a collection of constituent functions
into a collection of constituent functions 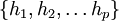 such that
such that
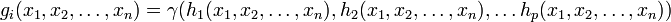
where 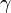 is some other function. Decompositions of this kind are interesting and important for a wide variety of reasons. In general, functional decompositions are worthwhile when there is a certain "sparseness" in the dependency structure; that is, when constituent functions are found to depend on approximately disjoint sets of variables. Thus, for example, if we can obtain a decomposition of
is some other function. Decompositions of this kind are interesting and important for a wide variety of reasons. In general, functional decompositions are worthwhile when there is a certain "sparseness" in the dependency structure; that is, when constituent functions are found to depend on approximately disjoint sets of variables. Thus, for example, if we can obtain a decomposition of 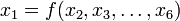 into a hierarchical composition of functions
into a hierarchical composition of functions 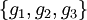 such that
such that 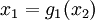 ,
, 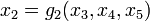 ,
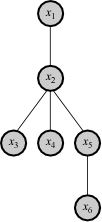
, 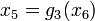 , as shown in the figure at right, this would probably be considered a highly valuable decomposition.
, as shown in the figure at right, this would probably be considered a highly valuable decomposition.
Example: Arithmetic
A basic example of functional decomposition is expressing the four binary arithmetic operations of addition, subtraction, multiplication, and division in terms of the two binary operations of addition  and multiplication
and multiplication 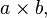 and the two unary operations of additive inversion
and the two unary operations of additive inversion  and multiplicative inversion
and multiplicative inversion 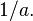 Subtraction can then be realized as the composition of addition and additive inversion,
Subtraction can then be realized as the composition of addition and additive inversion, 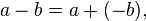 and division can be realized as the composition of multiplication and multiplicative inverse,
and division can be realized as the composition of multiplication and multiplicative inverse, 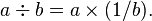 This simplifies the analysis of subtraction and division, and also makes it easier to axiomatize these operations in the notion of a field, as there are only two binary and two unary operations, rather than four binary operations.
This simplifies the analysis of subtraction and division, and also makes it easier to axiomatize these operations in the notion of a field, as there are only two binary and two unary operations, rather than four binary operations.
Motivation for decomposition
As to why the decomposition is valuable, the reason is twofold. Firstly, decomposition of a function into non-interacting components generally permits more economical representations of the function. For example, on a set of quaternary (i.e., 4-ary) variables, representing the full function requires storing 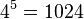 values, the value of the function for each element in the Cartesian product
values, the value of the function for each element in the Cartesian product 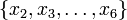 , i.e., each of the 1024 possible combinations for . However, if the decomposition into given above is possible, then
, i.e., each of the 1024 possible combinations for . However, if the decomposition into given above is possible, then 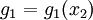 requires storing 4 values,
requires storing 4 values, 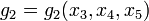 requires storing
requires storing 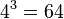 values, and
values, and 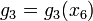 again requires storing just 4 values. So in virtue of the decomposition, we need store only
again requires storing just 4 values. So in virtue of the decomposition, we need store only 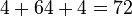 values rather than 1024 values, a dramatic savings.
values rather than 1024 values, a dramatic savings.

Intuitively, this reduction in representation size is achieved simply because each variable depends only on a subset of the other variables. Thus, variable 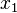 only depends directly on variable
only depends directly on variable 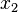 , rather than depending on the entire set of variables. We would say that variable screens off variable from the rest of the world. Practical examples of this phenomenon surround us, as discussed in the "Philosophical Considerations" below, but let's just consider the particular case of "northbound traffic on the West Side Highway." Let us assume this variable (
, rather than depending on the entire set of variables. We would say that variable screens off variable from the rest of the world. Practical examples of this phenomenon surround us, as discussed in the "Philosophical Considerations" below, but let's just consider the particular case of "northbound traffic on the West Side Highway." Let us assume this variable (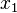 ) takes on three possible values of {"moving slow", "moving deadly slow", "not moving at all"}. Now let's say variable depends on two other variables, "weather" with values of {"sun", "rain", "snow"}, and "GW Bridge traffic" with values {"10mph", "5mph", "1mph"}. The point here is that while there are certainly many secondary variables that affect the weather variable (e.g., low pressure system over Canada, butterfly flapping in Japan, etc.) and the Bridge traffic variable (e.g., an accident on I-95, presidential motorcade, etc.) all these other secondary variables are not directly relevant to the West Side Highway traffic. All we need (hypothetically) in order to predict the West Side Highway traffic is the weather and the GW Bridge traffic, because these two variables screen off West Side Highway traffic from all other potential influences. That is, all other influences act through them.
) takes on three possible values of {"moving slow", "moving deadly slow", "not moving at all"}. Now let's say variable depends on two other variables, "weather" with values of {"sun", "rain", "snow"}, and "GW Bridge traffic" with values {"10mph", "5mph", "1mph"}. The point here is that while there are certainly many secondary variables that affect the weather variable (e.g., low pressure system over Canada, butterfly flapping in Japan, etc.) and the Bridge traffic variable (e.g., an accident on I-95, presidential motorcade, etc.) all these other secondary variables are not directly relevant to the West Side Highway traffic. All we need (hypothetically) in order to predict the West Side Highway traffic is the weather and the GW Bridge traffic, because these two variables screen off West Side Highway traffic from all other potential influences. That is, all other influences act through them.
Outside of purely mathematical considerations, perhaps the greatest value of functional decomposition is the insight it provides into the structure of the world. When a functional decomposition can be achieved, this provides ontological information about what structures actually exist in the world, and how they can be predicted and manipulated. For example, in the illustration above, if it is learned that depends directly only on 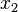 , this means that for purposes of prediction of , it suffices to know only . Moreover, interventions to influence can be taken directly on , and nothing additional can be gained by intervening on variables
, this means that for purposes of prediction of , it suffices to know only . Moreover, interventions to influence can be taken directly on , and nothing additional can be gained by intervening on variables 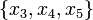 , since these only act through in any case.
, since these only act through in any case.
Philosophical considerations
The philosophical antecedents and ramifications of functional decomposition are quite broad, as functional decomposition in one guise or another underlies all of modern science. Here we review just a few of these philosophical considerations.
Reductionist tradition
One of the major distinctions that is often drawn between Eastern philosophy and Western Philosophy is that the Eastern philosophers tended to espouse ideas favoring holism while the Western thinkers tended to espouse ideas favoring reductionism. While this distinction between East and West — like other such philosophical distinctions that have been drawn (e.g., realism vs. anti-realism) — almost certainly simplifies matters too much, there is still a kernel of truth to be had. Some examples of the Eastern holistic spirit:
- "Open your mouth, increase your activities, start making distinctions between things, and you'll toil forever without hope." — The Tao Te Ching of Lao Tzu (Brian Browne Walker, translator)
- "It's a hard job for [people] to see the meaning of the fact that everything, including ourselves, depends on everything else and has no permanent self-existence." — Majjhima Nikaya (Anne Bankroft, translator)
- "A name is imposed on what is thought to be a thing or a state and this divides it from other things and other states. But when you pursue what lies behind the name, you find a greater and greater subtlety that has no divisions..." — Visuddhi Magga (Anne Bankroft, translator)
The Western tradition, from its origins among the Greek philosophers, preferred a position in which drawing correct distinctions, divisions, and contrasts was considered the very pinnacle of insight. In the Aristotelian/Porphyrian worldview, to be able to distinguish (via strict proof) which qualities of a thing represent its essence vs. property vs. accident vs. definition, and by virtue of this formal description to segregate that entity into its proper place in the taxonomy of nature — this was to achieve the very height of wisdom.
Characteristics of hierarchy and modularity
In natural or artificial systems that require components to be integrated in some fashion, but where the number of components exceeds what could reasonably be fully interconnected (due to square wise growth in number of connections (= n over two or = n * (n - 1) / 2)), one often finds that some degree of hierarchicality must be employed in the solution. The general advantages of sparse hierarchical systems over densely connected systems—and quantitative estimates of these advantage—are presented by Resnikoff (1989). In prosaic terms, a hierarchy is "a collection of elements that combine lawfully into complex wholes which depend for their properties upon those of their constituent parts," and wherein novelty is "fundamentally combinatorial, iterative, and transparent" (McGinn 1994).
An important notion that always arises in connection with hierarchies is modularity, which is effectively implied by the sparseness of connections in hierarchical topologies. In physical systems, a module is generally a set of interacting components that relates to the external world via a very limited interface, thus concealing most aspects of its internal structure. As a result, modifications that are made to the internals of a module (to improve efficiency for example) do not necessarily create a ripple effect through the rest of the system (Fodor 1983). This feature makes the effective use of modularity a centerpiece of all good software and hardware engineering, notably object oriented programming (Budd 2002). Other examples of the use of hierarchy in the manufacture of artifacts, including computer software (Tonge 1969,Simon 1973), are too obvious to bear mention.
Inevitability of hierarchy and modularity
There are many compelling arguments regarding the prevalence and necessity of hierarchy/modularity in nature (Koestler 1973). Simon (1996) points out that among evolving systems, only those that can manage to obtain and then reuse stable subassemblies (modules) are likely to be able to search through the fitness landscape with a reasonably quick pace; thus, Simon submits that "among possible complex forms, hierarchies are the ones that have the time to evolve." This line of thinking has led to the even stronger claim that although "we do not know what forms of life have evolved on other planets in the universe, ... we can safely assume that 'wherever there is life, it must be hierarchically organized'" (Koestler 1967). This would be a fortunate state of affairs since the existence of simple and isolable subsystems is thought to be a precondition for successful science (Fodor 1983). In any case, experience certainly seems to indicate that much of the world possesses hierarchical structure.
It has been proposed that perception itself is a process of hierarchical decomposition (Leyton 1992), and that phenomena which are not essentially hierarchical in nature may not even be "theoretically intelligible" to the human mind (McGinn 1994,Simon 1996). In Simon's words,
The fact then that many complex systems have a nearly decomposable, hierarchic structure is a major facilitating factor enabling us to understand, describe, and even "see" such systems and their parts. Or perhaps the proposition should be put the other way round. If there are important systems in the world that are complex without being hierarchic, they may to a considerable extent escape our observation and understanding. Analysis of their behavior would involve such detailed knowledge and calculations of the interactions of their elementary parts that it would be beyond our capacities of memory or computation.
Applications
Practical applications of functional decomposition are found in Bayesian networks, structural equation modeling, linear systems, and database systems.
Knowledge representation
Processes related to functional decomposition are prevalent throughout the fields of knowledge representation and machine learning. Hierarchical model induction techniques such as Logic circuit minimization, decision trees, grammatical inference, hierarchical clustering, and quadtree decomposition are all examples of function decomposition. A review of other applications and function decomposition can be found in Zupan et al. (1997), which also presents methods based on information theory and graph theory.
Many statistical inference methods can be thought of as implementing a function decomposition process in the presence of noise; that is, where functional dependencies are only expected to hold approximately. Among such models are mixture models and the recently popular methods referred to as "causal decompositions" or Bayesian networks.
Database theory
Machine learning
In practical scientific applications, it is almost never possible to achieve perfect functional decomposition because of the incredible complexity of the systems under study. This complexity is manifested in the presence of "noise," which is just a designation for all the unwanted and untraceable influences on our observations.
However, while perfect functional decomposition is usually impossible, the spirit lives on in a large number of statistical methods that are equipped to deal with noisy systems. When a natural or artificial system is intrinsically hierarchical, the joint distribution on system variables should provide evidence of this hierarchical structure. The task of an observer who seeks to understand the system is then to infer the hierarchical structure from observations of these variables. This is the notion behind the hierarchical decomposition of a joint distribution, the attempt to recover something of the intrinsic hierarchical structure which generated that joint distribution.
As an example, Bayesian network methods attempt to decompose a joint distribution along its causal fault lines, thus "cutting nature at its seams". The essential motivation behind these methods is again that within most systems (natural or artificial), relatively few components/events interact with one another directly on equal footing (Simon 1963). Rather, one observes pockets of dense connections (direct interactions) among small subsets of components, but only loose connections between these densely connected subsets. There is thus a notion of "causal proximity" in physical systems under which variables naturally precipitate into small clusters. Identifying these clusters and using them to represent the joint provides the basis for great efficiency of storage (relative to the full joint distribution) as well as for potent inference algorithms.
Software architecture
Functional Decomposition is a design method intending to produce a non-implementation, architectural description of a computer program. Rather than conjecturing Objects and adding methods to them (OOP), with each Object intending to capture some service of the program, the software architect first establishes a series of functions and types that accomplishes the main processing problem of the computer program, decomposes each to reveal common functions and types, and finally derives Modules from this activity.
For example, the design of the editor Emacs can initially be thought about in terms of functions:
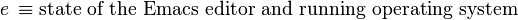
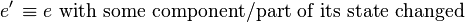
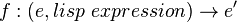
And a possible function decomposition of f:
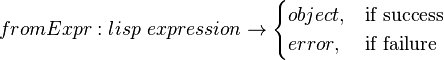
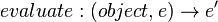
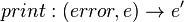
This leads one to the plausible Module, Service, or Object, of an interpreter (containing the function fromExpr). Function Decomposition arguably yields insights about re-usability, such as if during the course of analysis, two functions produce the same type, it is likely that a common function/cross-cutting concern resides in both. To contrast, in OOP, it is a common practice to conjecture Modules prior to considering such a decomposition. This arguably results in costly refactoring later. FD mitigates that risk to some extent. Further, arguably, what separates FD from other design methods- is that it provides a concise high-level medium of architectural discourse that is end-to-end, revealing flaws in upstream requirements and beneficially exposing more design decisions in advance. And lastly, FD is known to prioritize development. As arguably, if the FD is correct, the most re-usable and cost-determined parts of the program are identified far earlier in the development cycle.
Signal processing
Functional decomposition is used in the analysis of many signal processing systems, such as LTI systems. The input signal to an LTI system can be expressed as a function,  . Then can be decomposed into a linear combination of other functions, called component signals:
. Then can be decomposed into a linear combination of other functions, called component signals:
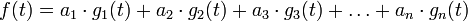
Here, 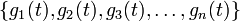 are the component signals. Note that
are the component signals. Note that 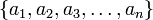 are constants. This decomposition aids in analysis, because now the output of the system can be expressed in terms of the components of the input. If we let
are constants. This decomposition aids in analysis, because now the output of the system can be expressed in terms of the components of the input. If we let 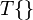 represent the effect of the system, then the output signal is
represent the effect of the system, then the output signal is 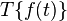 , which can be expressed as:
, which can be expressed as:
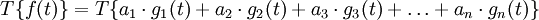
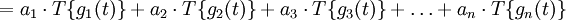
In other words, the system can be seen as acting separately on each of the components of the input signal. Commonly used examples of this type of decomposition are the Fourier series and the Fourier transform.
Systems engineering
Functional decomposition in systems engineering refers to the process of defining a system in functional terms, then defining lower-level functions and sequencing relationships from these higher level systems functions.[1] The basic idea is to try to divide a system in such a way that each block of a block diagram can be described without an "and" or "or" in the description.
This exercise forces each part of the system to have a pure function. When a system is designed as pure functions, they can be reused, or replaced. A usual side effect is that the interfaces between blocks become simple and generic. Since the interfaces usually become simple, it is easier to replace a pure function with a related, similar function.
For example, say that one needs to make a stereo system. One might functionally decompose this into speakers, amplifier, a tape deck and a front panel. Later, when a different model needs an audio CD, it can probably fit the same interfaces.
See also
- Bayesian networks
- Database normalization
- Function composition
- Inductive inference
- Knowledge representation
Notes
- ↑ Systems Engineering Fundamentals., Defense Acquisition University Press, Fort Belvoir, VA, January 2001, p45
References
- Budd, Timothy A. (2002), An Introduction to Object-Oriented Programming, Boston: Addison Wesley
- Fodor, Jerry (1983), The Modularity of Mind, Cambridge, MA: MIT Press
- Koestler, Arthur (1967), The Ghost in the Machine, New York: Macmillan
- Koestler, Athur (1973), "The tree and the candle", in Gray, William; Rizzo, Nicholas D., Unity Through Diversity: A Festschrift for Ludwig von Bertalanffy, New York: Gordon and Breach, pp. 287–314
- Leyton, Michael (1992), Symmetry, Causality, Mind, Cambridge, MA: MIT Press
- McGinn, Colin (1994), "The Problem of Philosophy", Philosophical Studies 76 (2–3): 133–156, doi:10.1007/BF00989821
- Resnikoff, Howard L. (1989), The Illusion of Reality, New York: Springer
- Simon, Herbert A. (1963), "Causal Ordering and Identifiability", in Ando, Albert & Fisher, Franklin M. & Simon, Herbert A., Essays on the Structure of Social Science Models, Cambridge, MA: MIT Press, pp. 5–31.
- Simon, Herbert A. (1973), "The organization of complex systems", in Pattee, Howard H., Hierarchy Theory: The Challenge of Complex Systems, New York: George Braziller, pp. 3–27.
- Simon, Herbert A. (1996), "The architecture of complexity: Hierarchic systems", The sciences of the artificial, Cambridge, MA: MIT Press, pp. 183–216.
- Tonge, Fred M. (1969), "Hierarchical aspects of computer languages", in Whyte, Lancelot Law & Wilson, Albert G. & Wilson, Donna, Hierarchical Structures, New York: American Elsevier, pp. 233–251.
- Zupan, Blaž; Bohanec, Marko; Bratko, Ivan; Demšar, Janez (1997), "Machine learning by function decomposition", Proc. 14th International Conference on Machine Learning, Morgan Kaufmann, pp. 421–429