Frequency distribution
In statistics, a frequency distribution is a table that displays the frequency of various outcomes in a sample.[1] Each entry in the table contains the frequency or count of the occurrences of values within a particular group or interval, and in this way, the table summarizes the distribution of values in the sample.
Univariate frequency tables
An example of a univariate (i.e. single variable) frequency table. The frequency of each response to a survey question is depicted.
| Rank | Degree of agreement | Number |
|---|---|---|
| 1 | Strongly agree | 20 |
| 2 | Agree somewhat | 30 |
| 3 | Not sure | 20 |
| 4 | Disagree somewhat | 15 |
| 5 | Strongly disagree | 15 |
A different tabulation scheme aggregates values into bins such that each bin encompasses a range of values. For example, the heights of the students in a class could be organized into the following frequency table.
| Height range | Number of students | Cumulative number |
|---|---|---|
| less than 5.0 feet | 25 | 25 |
| 5.0–5.5 feet | 35 | 60 |
| 5.5–6.0 feet | 20 | 80 |
| 6.0–6.5 feet | 20 | 100 |
A frequency distribution shows us a summarized grouping of data divided into mutually exclusive classes and the number of occurrences in a class. It is a way of showing unorganized data e.g. to show results of an election, income of people for a certain region, sales of a product within a certain period, student loan amounts of graduates, etc. Some of the graphs that can be used with frequency distributions are histograms, line charts, bar charts and pie charts. Frequency distributions are used for both qualitative and quantitative data.
Construction of frequency distributions
- Decide about the number of classes. Too many classes or too few classes might not reveal the basic shape of the data set, also it will be difficult to interpret such frequency distribution. The maximum number of classes may be determined by formula:
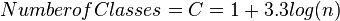 or
or 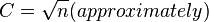 where n is the total number of observations in the data.
where n is the total number of observations in the data. - Calculate the range of the data (Range = Max – Min) by finding minimum and maximum data value. Range will be used to determine the class interval or class width.
- Decide about width of the class denote by h and obtained by
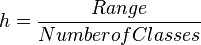 .
.
Generally the class interval or class width is the same for all classes. The classes all taken together must cover at least the distance from the lowest value (minimum) in the data set up to the highest (maximum) value. Also note that equal class intervals are preferred in frequency distribution, while unequal class interval may be necessary in certain situations to avoid a large number of empty, or almost empty classes.
- Decide the individual class limits and select a suitable starting point of the first class which is arbitrary, it may be less than or equal to the minimum value. Usually it is started before the minimum value in such a way that the midpoint (the average of lower and upper class limits of the first class) is properly placed.
- Take an observation and mark a vertical bar (|) for a class it belongs. A running tally is kept till the last observation. The tally counts indicates five.
- Find the frequencies, relative frequency, cumulative frequency etc. as required.[2]
Joint frequency distributions
Bivariate joint frequency distributions are often presented as (two-way) contingency tables:
| Dance | Sports | TV | Total | |
|---|---|---|---|---|
| Men | 2 | 10 | 8 | 20 |
| Women | 16 | 6 | 8 | 30 |
| Total | 18 | 16 | 16 | 50 |
The total row and total column report the marginal frequencies or marginal distribution, while the body of the table reports the joint frequencies.[3]
Applications
Managing and operating on frequency tabulated data is much simpler than operation on raw data. There are simple algorithms to calculate median, mean, standard deviation etc. from these tables.
Statistical hypothesis testing is founded on the assessment of differences and similarities between frequency distributions. This assessment involves measures of central tendency or averages, such as the mean and median, and measures of variability or statistical dispersion, such as the standard deviation or variance.
A frequency distribution is said to be skewed when its mean and median are different, or the same, depending on the textbook. The kurtosis of a frequency distribution is the concentration of scores at the mean, or how peaked the distribution appears if depicted graphically—for example, in a histogram. If the distribution is more peaked than the normal distribution it is said to be leptokurtic; if less peaked it is said to be platykurtic.
Letter frequency distributions are also used in frequency analysis to crack codes and are referred to the relative frequency of letters in different languages.
See also
Notes
- ↑ Australian Bureau of Statistics, http://www.abs.gov.au/websitedbs/a3121120.nsf/home/statistical+language+-+frequency+distribution
- ↑ Imdadullah, Muhammad. "Frequency Distribution". http://itfeature.com/statistics/frequency-distribution-table. itfeature.com. External link in
|work=(help); - ↑ Stat Trek, Statistics and Probability Glossary, s.v. Joint frequency
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||