Fractal tree index
| Fractal Tree index | ||
|---|---|---|
| Type | Tree | |
| Invented | 2007 | |
| Invented by | Michael A. Bender, Martin Farach-Colton, Bradley C. Kuszmaul | |
| Time complexity in big O notation | ||
| Average | Worst case | |
| Space | O(N/B) | O(N/B) |
| Search | O(logB N) | O(logB N) |
| Insert | O(logB N/Bε) | O(logB N/Bε) |
| Delete | O(logB N/Bε) | O(logB N/Bε) |
In computer science, a Fractal Tree index is a tree data structure that keeps data sorted and allows searches and sequential access in the same time as a B-tree but with insertions and deletions that are asymptotically faster than a B-tree. Like a B-tree, a Fractal Tree index is a generalization of a binary search tree in that a node can have more than two children. Furthermore, unlike a B-tree, a Fractal Tree index has buffers at each node, which allow insertions, deletions and other changes to be stored in intermediate locations. The goal of the buffers is to schedule disk writes so that each write performs a large amount of useful work, thereby avoiding the worst-case performance of B-trees, in which each disk write may change a small amount of data on disk. Like a B-tree, Fractal Tree indexes are optimized for systems that read and write large blocks of data. The Fractal Tree index has been commercialized in databases by Tokutek. Originally, it was implemented as a cache-oblivious lookahead array,[1] but the current implementation is an extension of the Bε tree.[2] The Bε is related to the Buffered Repository Tree.[3] The Buffered Repository Tree has degree 2, whereas the Bε tree has degree Bε. The Fractal Tree index has also been used in a prototype filesystem.[4][5] An open source implementation of the Fractal Tree index is available,[6] which demonstrates the implementation details outlined below.
Overview
In Fractal Tree indexes, internal (non-leaf) nodes can have a variable number of child nodes within some pre-defined range. When data is inserted or removed from a node, its number of child nodes changes. In order to maintain the pre-defined range, internal nodes may be joined or split. Each internal node of a B-tree will contain a number of keys that is one less than its branching factor. The keys act as separation values which divide its subtrees. Keys in subtrees are stored in search tree order, that is, all keys in a subtree are between the two bracketing values. In this regard, they are just like B-trees.
Fractal Tree indexes and B-trees both exploit the fact that when a node is fetched from storage, a block of memory, whose size is denoted by 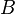 , is fetched. Thus, nodes are tuned to be of size approximately . Since access to storage can dominate the running time of a data structure, the time-complexity of external memory algorithms is dominated by the number of read/writes a data structure induces. (See, e.g.,[7] for the following analyses.)
, is fetched. Thus, nodes are tuned to be of size approximately . Since access to storage can dominate the running time of a data structure, the time-complexity of external memory algorithms is dominated by the number of read/writes a data structure induces. (See, e.g.,[7] for the following analyses.)
In a B-tree, this means that the number of keys in a node is targeted to be enough to fill the node, with some variability for node splits and merges. For the purposes of theoretical analysis, if  keys fit in a node, then the tree has depth
keys fit in a node, then the tree has depth  , and this is the I/O complexity of both searches and insertions.
, and this is the I/O complexity of both searches and insertions.
Fractal Trees nodes use a smaller branching factor, say, of  . The depth of the tree is then
. The depth of the tree is then  , thereby matching the B-tree asymptotically. The remaining space in each node is used to buffer insertions, deletion and updates, which we refer to in aggregate as messages. When a buffer is full, it is flushed to the children in bulk. There are several choices for how the buffers are flushed, all leading to similar I/O complexity. Each message in a node buffer will be flushed to a particular child, as determined by its key. Suppose, for concreteness, that messages are flushed that are heading to the same child, and that among the
, thereby matching the B-tree asymptotically. The remaining space in each node is used to buffer insertions, deletion and updates, which we refer to in aggregate as messages. When a buffer is full, it is flushed to the children in bulk. There are several choices for how the buffers are flushed, all leading to similar I/O complexity. Each message in a node buffer will be flushed to a particular child, as determined by its key. Suppose, for concreteness, that messages are flushed that are heading to the same child, and that among the 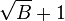 children, we pick the one with the most messages. Then there are at least
children, we pick the one with the most messages. Then there are at least 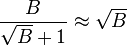 messages that can be flushed to the child. Each flush requires
messages that can be flushed to the child. Each flush requires  flushes, and therefore the per-message cost of a flush is
flushes, and therefore the per-message cost of a flush is 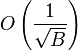 .
.
Consider the cost of an insertion. Each message gets flushed times, and the cost of a flush is . Therefore, the cost of an insertion is  . Finally, note that the branching factor can vary, but for any branching factor
. Finally, note that the branching factor can vary, but for any branching factor 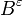 , the cost of a flush is
, the cost of a flush is  , thereby providing a smooth tradeoff between search cost, which depends on the depth of the search tree, and therefore the branching factor, versus the insertion time, which depends on the depth of the tree but more sensitively on the size of the buffer flushes.
, thereby providing a smooth tradeoff between search cost, which depends on the depth of the search tree, and therefore the branching factor, versus the insertion time, which depends on the depth of the tree but more sensitively on the size of the buffer flushes.
Comparisons with other External-Memory Indexes
This section compares Fractal Tree indexes with other external memory indexing data structures. The theoretical literature on this topic is very large, so this discussion is limited to a comparison with popular data structures that are in use in databases and file systems.
B-trees
The search time of a B-tree is asymptotically the same as that of a Fractal Tree index. However, a Fractal Tree index has deeper trees than a B-tree, and if each node were to require an I/O, say if the cache is cold, then a Fractal Tree index would induce more IO. However, for many workloads most or all internal nodes of both B-trees and Fractal Tree indexes are already cached in RAM. In this case, the cost of a search is dominated by the cost of fetching the leaf, which is the same in both cases. Thus, for many workloads, Fractal Tree indexes can match B-trees in terms of search time.
Where they differ is on insertions, deletions and updates. An insertion in a Fractal Tree index takes whereas B-trees require . Thus, Fractal Tree indexes are faster than B-trees by a factor of  . Since can be quite large, this yields a potential two-order-of-magnitude improvement in worst-case insertion times, which is observed in practice. Both B-trees and Fractal Tree indexes can perform insertions faster in the best case. For example, if keys are inserted in sequential order, both data structures achieve a
. Since can be quite large, this yields a potential two-order-of-magnitude improvement in worst-case insertion times, which is observed in practice. Both B-trees and Fractal Tree indexes can perform insertions faster in the best case. For example, if keys are inserted in sequential order, both data structures achieve a  I/Os per insertion. Thus, because the best and worst cases of B-trees differ so widely, whereas Fractal Tree indexes are always near their best case, the actual speedup that Fractal Tree indexes achieve over B-trees depends on the details of the workload.
I/Os per insertion. Thus, because the best and worst cases of B-trees differ so widely, whereas Fractal Tree indexes are always near their best case, the actual speedup that Fractal Tree indexes achieve over B-trees depends on the details of the workload.
Log-structured Merge-trees
Log-structured merge-trees (LSMs) refer to a class of data structures which consists of two or more index structures of exponentially growing capacities. When a tree at some level reaches its capacity, it is merged into the next bigger level. The IO-complexity of an LSM depends on parameters such as the growth factor between levels and the data structure chosen at each level, so in order to analyze the complexity of LSMs, we need to pick a specific version. For comparison purposes, we select the version of LSMs that match Fractal Tree indexes on insertion performance.
Suppose an LSM is implemented via B-trees, each of which has a capacity that is larger than its predecessor.
The merge time depends on three facts: The sorted order of keys in an 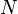 -item B-tree can be produced in
-item B-tree can be produced in 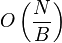 IOs; Two sorted lists of and
IOs; Two sorted lists of and 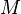 items can be merged into a sorted list in
items can be merged into a sorted list in 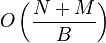 IOs; and a B-tree of a sorted list of items can be built in IOs. When a tree overflows, it is merged into a tree whose size is larger, therefore a level that holds
IOs; and a B-tree of a sorted list of items can be built in IOs. When a tree overflows, it is merged into a tree whose size is larger, therefore a level that holds  items requires
items requires  IOs to merge. An item may be merged once per level, giving a total time of , which matches the Fractal Tree index.
IOs to merge. An item may be merged once per level, giving a total time of , which matches the Fractal Tree index.
The query time is simply the B-tree query time at each level. The query time into the  th level is
th level is 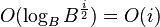 , since the th level has capacity
, since the th level has capacity  . The total time is therefore
. The total time is therefore 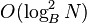 . This is larger than both the B-tree and Fractal Tree indexes by a logarithmic factor. In fact, although B-trees and Fractal Tree indexes are both on the optimal tradeoff curve between insertions and queries, LSMs are not. They are incomparable with B-trees and are dominated by Fractal Tree indexes.
. This is larger than both the B-tree and Fractal Tree indexes by a logarithmic factor. In fact, although B-trees and Fractal Tree indexes are both on the optimal tradeoff curve between insertions and queries, LSMs are not. They are incomparable with B-trees and are dominated by Fractal Tree indexes.
A few notes about LSMs: there are ways to make the queries faster. For example, if only membership queries are required and no successor/predecessor/range queries are, then Bloom filters can be used to speed up queries. Also, the growth factor between levels can be set to some other value, giving a range of insertion/query tradeoffs. However, for every choice of insertion rate, the corresponding Fractal Tree index has faster queries.
Bε Trees
The Fractal Tree index is a refinement of the Bε tree. Like a Bε tree, it consists of nodes with keys and buffers and realizes the optimal insertion/query tradeoff. The Fractal Tree index differs in including performance optimization and in extending the functionality. Examples of improved functionality include ACID semantics. B-tree implementations of ACID semantics typically involve locking rows that are involved in an active transactions. Such a scheme works well in a B-tree because both insertions and queries involve fetching the same leaf into memory. Thus, locking an inserted row does not incur an IO penalty. However, in Fractal Tree indexes, insertions are messages, and a row may reside in more than one node at the same time. Fractal Tree indexes therefore require a separate locking structure that is IO-efficient or resides in memory in order to implement the locking involved in implementing ACID semantics.
Fractal Tree indexes also have several performance optimizations. First, buffers are themselves indexed in order to speed up searches. Second, leaves are much larger than in B-trees, which allows for greater compression. In fact, the leaves are chosen to be large enough that their access time is dominated by the bandwidth time, and therefore amortizes away the seek and rotational latency. Large leaves are an advantage with large range queries but slow down point queries, which require accessing a small portion of the leaf. The solution implemented in Fractal Tree indexes is to have large leaves that can be fetched as a whole for fast range queries but are broken into smaller pieces call basement nodes which can be fetched individually. Accessing a basement node is faster than accessing a leaf, because of the reduced bandwidth time. Thus the substructure of leaves in Fractal Tree indexes, as compared to Bε trees allows both range and point queries to be fast.
Messaging and Fractal Tree Indexes
Insertions, deletions and updates are inserted as message into buffers that make their way towards the leaves. The messaging infrastructure can be exploited to implement a variety of other operations, some of which are discussed below.
Upserts
An upsert is a statement that inserts a row if it does not exist and updates it if it does. In a B-tree, an upsert is implemented by first searching for the row and then implementing an insertion or an update, depending on the result of the search. This requires fetching the row into memory if it is not already cached. A Fractal Tree index can implement an upsert by inserting a special upsert message. Such a message can, in theory, implement arbitrary pieces of code during the update. In practice, four update operations are supported:
- x = constant
- x = x + constant (a generalized increment)
- x = x - constant (a generalized decrement)
- x = if(x=0,0,x-1) (a decrement with a floor at 0)
These correspond to the update operations used in LinkBench,[8] a benchmark proposed by Facebook. By avoiding the initial search, upsert messages can improve the speed of upserts by orders of magnitude.
Schema Changes
So far, all message types have modified single rows. However, broadcast messages, which are copied to all outgoing buffers, can modify all rows in a database. For example, broadcast messages can be used to change the format of all rows in a database. Although the total work required to change all rows is unchanged over the brute-force method of traversing the table, the latency is improved, since, once the message is injected into the root buffer, all subsequent queries will be able to apply the schema modification to any rows they encounter. The schema change is immediate and the work is deferred to such a time when buffers overflow and leaves would have gotten updated anyway.
Implementations
The Fractal Tree index has been implemented and commercialized by Tokutek. It is available as TokuDB as a storage engine for MySQL and MariaDB, and as TokuMX, a more complete integration with MongoDB. Fractal Tree indexes have also been used in a prototype file system, TokuFS.[4]
References
- ↑ Bender, M. A.; Farach-Colton, M.; Fineman, J.; Fogel, Y.; Kuszmaul, B.; Nelson, J. (June 2007). "Cache-Oblivious streaming B-trees". Proceedings of the 19th Annual ACM Symposium on Parallelism in Algorithms and Architectures (CA: ACM Press): 81–92.
- ↑ Brodal, G.; Fagerberg, R. (Jan 2003). "Lower Bounds for External Memory Dictionaries". Proceedings of the Fourteenth Annual ACM-SIAM Symposium on Discrete Algorithms (N.Y.: ACM Press): 546–554.
- ↑ Buchsbaum, A.; Goldwasswer, M.; Venkatasubramanian, S.; Westbrook, J. (Jan 2000). "On External Memory Graph Traversal". Porceedings of the Eleventh Annual ACM-SIAM Symposium on Discrete Algorithms: 859–860. CiteSeerX: 10
.1 ..1 .27 .9904 - 1 2 Esmet, J.; Bender, M.; Farach-Colton, M.; Kuszmaul, B. (June 2007). "The TokuFS Streaming File System" (PDF). Proceedings of the 4th USENIX Conference on Hot Topics in Storage and File Systems. MA: USENIX Association. pp. 14–14.
- ↑ Jannen, William; Yuan, Jun; Zhan, Yang; Akshintala, Amogh; Esmet, John; Jiao, Yizheng; Mittal, Ankur; Pandey, Prashant; Reddy, Phaneendra; Walsh, Leif; Bender, Michael; Farach-Colton, Martin; Johnson, Rob; Kuszmaul, Bradley C.; Porter, Donald E. (February 2015). "BetrFS: A Right-Optimized Write-Optimized File System" (PDF). Proceedings of the 13th USENIX Conference on File and Storage Technologies. Santa Clara, California.
- ↑ Github Repository
- ↑ Cormen, T.; Leiserson, C.E.; Rivest, R.; Stein, C. (2001). "Introduction to Algorithms" (2nd ed.). MIT Press and McGraw-Hill. ISBN 0-262-03293-7.
- ↑ Armstrong, T.; Ponnekanti, V.; Borthakur, D.; Callaghan, M. (2013). "LinkBench: A Database Benchmark Based on the Facebook Social Graph". Proceedings of the 2013 ACM SIGMOD International Conference on Management of Data (NY: ACM Press): 1185–1196.
| ||||||||||||||||||||||
| ||||||||||||||||||||||||||||||