Focused information criterion
In statistics, the focused information criterion (FIC) is a method for selecting the most appropriate model among a set of competitors for a given data set. Unlike most other model selection strategies, like the Akaike information criterion (AIC), the Bayesian information criterion (BIC) and the deviance information criterion (DIC), the FIC does not attempt to assess the overall fit of candidate models but focuses attention directly on the parameter of primary interest with the statistical analysis, say 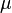 , for which competing models lead to different estimates, say
, for which competing models lead to different estimates, say 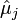 for model
for model 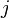 . The FIC method consists in first developing an exact or approximate expression for the precision or quality of each estimator, say
. The FIC method consists in first developing an exact or approximate expression for the precision or quality of each estimator, say  for , and then use data to estimate these precision measures, say
for , and then use data to estimate these precision measures, say 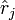 . In the end the model with best estimated precision is selected. The FIC methodology was developed by Gerda Claeskens and Nils Lid Hjort, first in two 2003 discussion articles in Journal of the American Statistical Association and later on in other papers and in their 2008 book.
. In the end the model with best estimated precision is selected. The FIC methodology was developed by Gerda Claeskens and Nils Lid Hjort, first in two 2003 discussion articles in Journal of the American Statistical Association and later on in other papers and in their 2008 book.
The concrete formulae and implementation for FIC depend firstly on the particular parameter of interest, the choice of which does not depend on mathematics but on the scientific and statistical context. Thus the FIC apparatus may be selecting one model as most appropriate for estimating a quantile of a distribution but preferring another model as best for estimating the mean value. Secondly, the FIC formulae depend on the specifics of the models used for the observed data and also on how precision is to be measured. The clearest case is where precision is taken to be mean squared error, say 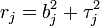 in terms of squared bias and variance for the estimator associated with model . FIC formulae are then available in a variety of situations, both for handling parametric, semiparametric and nonparametric situations, involving separate estimation of squared bias and variance, leading to estimated precision . In the end the FIC selects the model with smallest estimated mean squared error.
in terms of squared bias and variance for the estimator associated with model . FIC formulae are then available in a variety of situations, both for handling parametric, semiparametric and nonparametric situations, involving separate estimation of squared bias and variance, leading to estimated precision . In the end the FIC selects the model with smallest estimated mean squared error.
Associated with the use of the FIC for selecting a good model is the FIC plot, designed to give a clear and informative picture of all estimates, across all candidate models, and their merit. It displays estimates on the 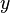 axis along with FIC scores on the
axis along with FIC scores on the  axis; thus estimates found to the left in the plot are associated with the better models and those found in the middle and to the right stem from models less or not adequate for the purpose of estimating the focus parameter in question.
axis; thus estimates found to the left in the plot are associated with the better models and those found in the middle and to the right stem from models less or not adequate for the purpose of estimating the focus parameter in question.
Generally speaking, complex models (with many parameters relative to sample size) tend to lead to estimators with small bias but high variance; more parsimonious models (with fewer parameters) typically yield estimators with larger bias but smaller variance. The FIC method balances the two desired data of having small bias and small variance in an optimal fashion. The main difficulty lies with the bias 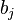 , as it involves the distance from the expected value of the estimator to the true underlying quantity to be estimated, and the true data generating mechanism may lie outside each of the candidate models.
, as it involves the distance from the expected value of the estimator to the true underlying quantity to be estimated, and the true data generating mechanism may lie outside each of the candidate models.
In situations where there is not a unique focus parameter, but rather a family of such, there are versions of average FIC (AFIC or wFIC) that find the best model in terms of suitably weighted performance measures, e.g. when searching for a regression model to perform particularly well in a portion of the covariate space.
It is also possible to keep several of the best models on board, ending the statistical analysis with a data-dicated weighted average of the estimators of the best FIC scores, typically giving highest weight to estimators associated with the best FIC scores. Such schemes of model averaging extend the direct FIC selection method.
The FIC methodology applies in particular to selection of variables in different forms of regression analysis, including the framework of generalised linear models and the semiparametric proportional hazards models (i.e. Cox regression).
See also
References
- Claeskens, G. and Hjort, N.L. (2003). "The focused information criterion" (with discussion). Journal of the American Statistical Association, volume 98, pp. 879–899. doi:10.1198/016214503000000819
- Hjort, N.L. and Claeskens, G. (2003). "Frequentist model average estimators" (with discussion). Journal of the American Statistical Association, volume 98, pp. 900–916. doi:10.1198/016214503000000828
- Hjort, N.L. and Claeskens, G. (2006). "Focused information criteria and model averaging for the Cox hazard regression model." Journal of the American Statistical Association, volume 101, pp. 1449–1464. doi:10.1198/016214506000000069
- Claeskens, G. and Hjort, N.L. (2008). Model Selection and Model Averaging. Cambridge University Press.
External links
- Interview on frequentist model averaging with Essential Science Indicators
- Webpage for Model Selection and Model Averaging the Claeskens and Hjort book