Fixed effects model
| Part of a series on Statistics |
| Regression analysis |
|---|
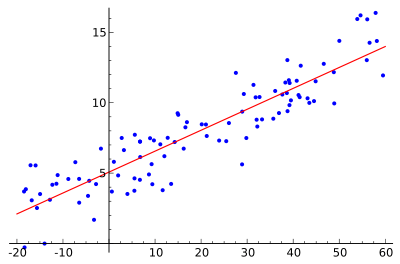 |
| Models |
| Estimation |
| Background |
|
In econometrics and statistics, a fixed effects model is a statistical model that represents the observed quantities in terms of explanatory variables that are treated as if the quantities were non-random. This is in contrast to random effects models and mixed models in which either all or some of the explanatory variables are treated as if they arise from random causes. Contrast this to the biostatistics definitions,[1][2][3][4] as biostatisticians use "fixed" and "random" effects to respectively refer to the population-average and subject-specific effects (and where the latter are generally assumed to be unknown, latent variables). Often the same structure of model, which is usually a linear regression model, can be treated as any of the three types depending on the analyst's viewpoint, although there may be a natural choice in any given situation.
In panel data analysis, the term fixed effects estimator (also known as the within estimator) is used to refer to an estimator for the coefficients in the regression model. If we assume fixed effects, we impose time independent effects for each entity that are possibly correlated with the regressors.
Qualitative description
Such models assist in controlling for unobserved heterogeneity when this heterogeneity is constant over time. This constant can be removed from the data through differencing, for example by taking a first difference which will remove any time invariant components of the model.
There are two common assumptions made about the individual specific effect, the random effects assumption and the fixed effects assumption. The random effects assumption (made in a random effects model) is that the individual specific effects are uncorrelated with the independent variables. The fixed effect assumption is that the individual specific effect is correlated with the independent variables. If the random effects assumption holds, the random effects model is more efficient than the fixed effects model. However, if this assumption does not hold, the random effects model is not consistent. The Durbin-Wu-Hausman test is often used to discriminate between the fixed and the random effects model.
Formal description
Consider the linear unobserved effects model for 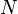 observations and
observations and  time periods:
time periods:
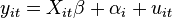 for
for 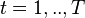 and
and 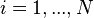
where 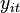 is the dependent variable observed for individual
is the dependent variable observed for individual  at time
at time
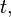
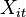 is the time-variant
is the time-variant 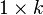 regressor matrix,
regressor matrix,  is the unobserved time-invariant individual effect and
is the unobserved time-invariant individual effect and 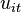 is the error term. Unlike , cannot be observed by the econometrician. Common examples for time-invariant effects are innate ability for individuals or historical and institutional factors for countries.
is the error term. Unlike , cannot be observed by the econometrician. Common examples for time-invariant effects are innate ability for individuals or historical and institutional factors for countries.
Unlike the Random effects (RE) model where the unobserved is independent of 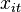 for all
for all 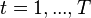 , the FE model allows to be correlated with the regressor matrix . Strict exogeneity, however, is still required.
, the FE model allows to be correlated with the regressor matrix . Strict exogeneity, however, is still required.
Since is not observable, it cannot be directly controlled for. The FE model eliminates by demeaning the variables using the within transformation:
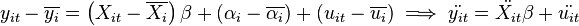
where 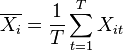 and
and 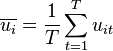 . Since is constant,
. Since is constant, 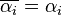 and hence the effect is eliminated. The FE estimator
and hence the effect is eliminated. The FE estimator 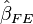 is then obtained by an OLS regression of
is then obtained by an OLS regression of 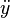 on
on 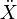 .
.
At least three alternatives to the within transformation exist with variations. One is to add a dummy variable for each individual . This is numerically, but not computationally, equivalent to the fixed effect model and only works if the sum of the number of series and the number of global parameters is smaller than the number of observations.[5] The dummy variable approach is particularly demanding with respect to computer memory usage and it is not recommended for problems larger than the available RAM, and the applied program compilation, can accommodate. Second alternative is to use consecutive reiterations approach to local and global estimations.[6] This approach is very suitable for low memory systems on which it is much more computationally efficient than the dummy variable approach. The third approach is a nested estimation whereby the local estimation for individual series is programmed in as a part of the model definition.[7] This approach is the most computationally and memory efficient, but it requires proficient programming skills and access to the model programming code; although, it can be programmed even in SAS.[8][9] Finally, each of the above alternatives can be improved if the series-specific estimation is linear (within a nonlinear model), in which case the direct linear solution for individual series can be programmed in as part of the nonlinear model definition.[10]
Equality of Fixed Effects (FE) and First Differences (FD) estimators when T=2
For the special two period case (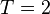 ), the FE estimator and the FD estimator are numerically equivalent. This is because the FE estimator effectively "doubles the data set" used in the FD estimator. To see this, establish that the fixed effects estimator is:
), the FE estimator and the FD estimator are numerically equivalent. This is because the FE estimator effectively "doubles the data set" used in the FD estimator. To see this, establish that the fixed effects estimator is:
![{FE}_{T=2}= \left[ (x_{i1}-\bar x_{i}) (x_{i1}-\bar x_{i})' +
(x_{i2}-\bar x_{i}) (x_{i2}-\bar x_{i})' \right]^{-1}\left[
(x_{i1}-\bar x_{i}) (y_{i1}-\bar y_{i}) + (x_{i2}-\bar x_{i}) (y_{i2}-\bar y_{i})\right]](../I/m/a54aad83c5652aef82b0f5265234e1d5.png)
Since each 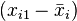 can be re-written as
can be re-written as 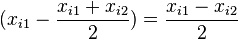 , we'll re-write the line as:
, we'll re-write the line as:
![{FE}_{T=2}= \left[\sum_{i=1}^{N} \dfrac{x_{i1}-x_{i2}}{2} \dfrac{x_{i1}-x_{i2}}{2} ' + \dfrac{x_{i2}-x_{i1}}{2} \dfrac{x_{i2}-x_{i1}}{2} ' \right]^{-1} \left[\sum_{i=1}^{N} \dfrac{x_{i1}-x_{i2}}{2} \dfrac{y_{i1}-y_{i2}}{2} + \dfrac{x_{i2}-x_{i1}}{2} \dfrac{y_{i2}-y_{i1}}{2} \right]](../I/m/0caa1de06b30fe19509804cf176be863.png)
![= \left[\sum_{i=1}^{N} 2 \dfrac{x_{i2}-x_{i1}}{2} \dfrac{x_{i2}-x_{i1}}{2} ' \right]^{-1} \left[\sum_{i=1}^{N} 2 \dfrac{x_{i2}-x_{i1}}{2} \dfrac{y_{i2}-y_{i1}}{2} \right]](../I/m/c47024fc0a3107b7fdea0fddcfcb019a.png)
![= 2\left[\sum_{i=1}^{N} (x_{i2}-x_{i1})(x_{i2}-x_{i1})' \right]^{-1} \left[\sum_{i=1}^{N} \frac{1}{2} (x_{i2}-x_{i1})(y_{i2}-y_{i1}) \right]](../I/m/9f20aeea969fdac4ed1318a910b0c9f9.png)
![= \left[\sum_{i=1}^{N} (x_{i2}-x_{i1})(x_{i2}-x_{i1})' \right]^{-1} \sum_{i=1}^{N} (x_{i2}-x_{i1})(y_{i2}-y_{i1}) ={FD}_{T=2}](../I/m/16722f237709d94cded72624aef9b7ec.png)
Hausman–Taylor method
Need to have more than one time-variant regressor ( ) and time-invariant
regressor (
) and time-invariant
regressor ( ) and at least one and one that are uncorrelated with
.
) and at least one and one that are uncorrelated with
.
Partition the and variables such that ![\begin{array}
[c]{c}
X=[\underset{TN\times K1}{X_{1it}}\vdots\underset{TN\times K2}{X_{2it}}]\\
Z=[\underset{TN\times G1}{Z_{1it}}\vdots\underset{TN\times G2}{Z_{2it}}]
\end{array}](../I/m/7714a62ab13789367ece34ab00872c2f.png) where
where  and
and 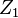 are uncorrelated with . Need
are uncorrelated with . Need 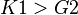 .
.
Estimating 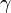 via OLS on
via OLS on 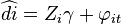 using
using  and
and 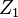 as instruments yields a consistent estimate.
as instruments yields a consistent estimate.
Testing fixed effects (FE) vs. random effects (RE)
We can test whether a model is appropriate using a Hausman test.
-
 :
: 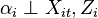
-
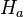 :
: 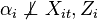
If is true, both 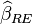 and
and 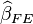 are
consistent, but only is efficient. If is true,
is consistent and is not.
are
consistent, but only is efficient. If is true,
is consistent and is not.
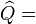

-
![\widehat{HT}=T\widehat{Q}^{\prime}[Var(\widehat{\beta}_{FE})-Var(\widehat
{\beta}_{RE})]^{-1}\widehat{Q}\sim\chi_{K}^{2}](../I/m/8c75aa73347678e8b4c41833c53dd526.png) where
where 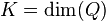
The Hausman test is a specification test so a large test statistic might be
indication that there might be Errors in Variables (EIV) or our model is
misspecified. If the FE assumption is true, we should find that 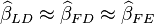 .
.
A simple heuristic is that if 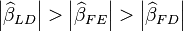 there could be EIV.
there could be EIV.
Steps in Fixed Effects Model for sample data
- Calculate group and grand means
- Calculate k=number of groups, n=number of observations per group, N=total number of observations (k x n)
- Calculate SS-total (or total variance) as: (Each score - Grand mean)^2 then summed
- Calculate SS-treat (or treatment effect) as: (Each group mean- Grand mean)^2 then summed x n
- Calculate SS-error (or error effect) as (Each score - Its group mean)^2 then summed
- Calculate df-total: N-1, df-treat: k-1 and df-error k(n-1)
- Calculate Mean Square MS-treat: SS-treat/df-treat, then MS-error: SS-error/df-error
- Calculate obtained f value: MS-treat/MS-error
- Use F-table or probability function, to look up critical f value with a certain significance level
- Conclude as to whether treatment effect significantly affects the variable of interest
See also
Notes
- ↑ Diggle, Peter J.; Heagerty, Patrick; Liang, Kung-Yee; Zeger, Scott L. (2002). Analysis of Longitudinal Data (2nd ed.). Oxford University Press. pp. 169–171. ISBN 0-19-852484-6.
- ↑ Fitzmaurice, Garrett M.; Laird, Nan M.; Ware, James H. (2004). Applied Longitudinal Analysis. Hoboken: John Wiley & Sons. pp. 326–328. ISBN 0-471-21487-6.
- ↑ Laird, Nan M.; Ware, James H. (1982). "Random-Effects Models for Longitudinal Data". Biometrics 38 (4): 963–974. JSTOR 2529876.
- ↑ Gardiner, Joseph C.; Luo, Zhehui; Roman, Lee Anne (2009). "Fixed effects, random effects and GEE: What are the differences?". Statistics in Medicine 28: 221–239. doi:10.1002/sim.3478.
- ↑ Garcia, Oscar. (1983). "A stochastic differential equation model for the height growth of forest stands". Biometrics: 1059–1072.
- ↑ Tait, David; Cieszewski, Chris J.; Bella, Imre E. (1986). "The stand dynamics of lodgepole pine". Can. J. For. Res. 18: 1255–1260.
- ↑ Strub, Mike; Cieszewski, Chris J. (2006). "Base–age invariance properties of two techniques for estimating the parameters of site index models". Forest Science 52 (2): 182–186.
- ↑ Strub, Mike; Cieszewski, Chris J. (2003). "Fitting global site index parameters when plot or tree site index is treated as a local nuisance parameter In: Burkhart HA, editor. Proceedings of the Symposium on Statistics and Information Technology in Forestry; 2002 September 8–12; Blacksburg, Virginia: Virginia Polytechnic Institute and State University": 97–107.
- ↑ Cieszewski, Chris J.; Harrison, Mike; Martin, Stacey W. (2000). "Practical methods for estimating non-biased parameters in self-referencing growth and yield models" (PDF). PMRC Technical Report 2000 (7): 12.
- ↑ Schnute, Jon; McKinnell, Skip (1984). "A biologically meaningful approach to response surface analysis". Can. J. Fish. Aquat. 41: 936–953.
References
- Christensen, Ronald (2002). Plane Answers to Complex Questions: The Theory of Linear Models (Third ed.). New York: Springer. ISBN 0-387-95361-2.
- Gujarati, Damodar N.; Porter, Dawn C. (2009). "Panel Data Regression Models". Basic Econometrics (Fifth international ed.). Boston: McGraw-Hill. pp. 591–616. ISBN 978-007-127625-2.
- Hsiao, Cheng (2003). "Fixed-effects models". Analysis of Panel Data (2nd ed.). New York: Cambridge University Press. pp. 95–103. ISBN 0-521-52271-4.
- Wooldridge, Jeffrey M. (2013). "Fixed Effects Estimation". Introductory Econometrics: A Modern Approach (Fifth international ed.). Mason, OH: South-Western. pp. 466–474. ISBN 978-1-111-53439-4.
External links
- Fixed and random effects models
- Examples of all ANOVA and ANCOVA models with up to three treatment factors, including randomized block, split plot, repeated measures, and Latin squares, and their analysis in R