FastICA
FastICA is an efficient and popular algorithm for independent component analysis invented by Aapo Hyvärinen at Helsinki University of Technology.[1][2] Like most ICA algorithms, FastICA seeks an orthogonal rotation of prewhitened data, through a fixed-point iteration scheme, that maximizes a measure of non-Gaussianity of the rotated components. Non-gaussianity serves as a proxy for statistical independence, which is a very strong condition and requires infinite data to verify. FastICA can also be alternatively derived as an approximative Newton iteration.
Algorithm
Prewhitening the data
Let the  denote the input vector data matrix. The columns of
denote the input vector data matrix. The columns of  correspond to
correspond to 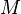 observed mixed vectors of dimension
observed mixed vectors of dimension 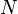 . The input data matrix
. The input data matrix 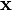 must be prewhitened, or centered and whitened, before applying the FastICA algorithm to it.
must be prewhitened, or centered and whitened, before applying the FastICA algorithm to it.
- Centering the data entails demeaning each component of the input data , that is,
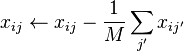
- for each
 and
and 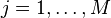 . After centering, each row of has an expected value of
. After centering, each row of has an expected value of  .
.
- Whitening the data requires a linear transformation
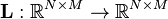 of the centered data so that the components of
of the centered data so that the components of 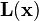 are uncorrelated and have variance one. More precisely, if is a centered data matrix, the covariance of
are uncorrelated and have variance one. More precisely, if is a centered data matrix, the covariance of 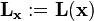 is the
is the 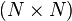 -dimensional identity matrix, that is,
-dimensional identity matrix, that is,
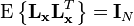
- A common method for whitening is by performing a eigenvalue decomposition on the covariance matrix of the centered data ,
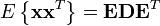 , where
, where 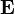 is the matrix of eigenvectors and
is the matrix of eigenvectors and  is the diagonal matrix of eigenvalues. The whitened data matrix is defined thus by
is the diagonal matrix of eigenvalues. The whitened data matrix is defined thus by
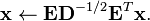
Single component extraction
The iterative algorithm finds the direction for the weight vector 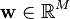 that maximizes a measure of non-Gaussianity of the projection
that maximizes a measure of non-Gaussianity of the projection 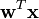 ,
with
,
with 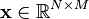 denoting a prewhitened data matrix as described above.
To measure non-Gaussianity, FastICA relies on a nonquadratic nonlinearity function
denoting a prewhitened data matrix as described above.
To measure non-Gaussianity, FastICA relies on a nonquadratic nonlinearity function 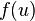 , its first derivative
, its first derivative 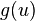 , and its second derivative
, and its second derivative 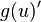 . Hyvärinen states that the functions
. Hyvärinen states that the functions
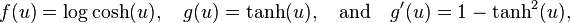
are useful for general purposes, while
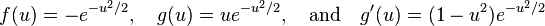
may be highly robust.[1] The steps for extracting the weight vector  for single component in FastICA are the following.
for single component in FastICA are the following.
- Randomize the initial weight vector
- Let
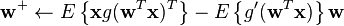 , where
, where 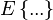 means averaging over all column-vectors of matrix
means averaging over all column-vectors of matrix 
- Let
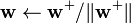
- If not converged, go back to 2
Multiple component extraction
The single unit iterative algorithm estimates only one weight vector which extracts a single component. Estimating additional components that are mutually "independent" requires repeating the algorithm to obtain linearly independent projection vectors - note that the notion of independence here refers to maximizing non-Gaussianity in the estimated components. Hyvärinen provides several ways of extracting multiple components with the simplest being the following. Here,  is a column vector of 1's of dimension M.
is a column vector of 1's of dimension M.
Algorithm FastICA
- Input:
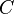 Number of desired components
Number of desired components - Input:
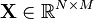 Matrix, where each column represents an N-dimensional sample, where
Matrix, where each column represents an N-dimensional sample, where 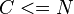
- Output:
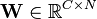 Un-mixing matrix where each row projects X onto into independent component.
Un-mixing matrix where each row projects X onto into independent component. - Output:
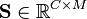 Independent components matrix, with M columns representing a sample with C dimensions.
Independent components matrix, with M columns representing a sample with C dimensions.
for p in 1 to C:
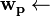 Random vector of length N
while
Random vector of length N
while 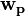 changes
changes
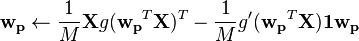
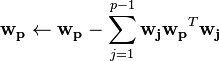
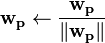 Output:
Output: 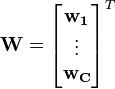 Output:
Output: 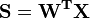
See also
- Unsupervised learning
- Machine learning
- The IT++ library features a FastICA implementation in C++
References
- 1 2 Hyvärinen, A.; Oja, E. (2000). "Independent component analysis: Algorithms and applications" (PDF). Neural Networks 13 (4–5): 411–430. doi:10.1016/S0893-6080(00)00026-5. PMID 10946390.
- ↑ Hyvarinen, A. (1999). "Fast and robust fixed-point algorithms for independent component analysis" (PDF). IEEE Transactions on Neural Networks 10 (3): 626–634. doi:10.1109/72.761722. PMID 18252563.
External links
- FastICA package for Matlab or Octave
- fastICA package in R programming language
- FastICA in Java on SourceForge
- FastICA in Java in RapidMiner.