Extreme learning machine
| Machine learning and data mining |
|---|
 |
| Problems |
| Clustering |
| Dimensionality reduction |
| Structured prediction |
| Anomaly detection |
| Neural nets |
| Theory |
| Machine learning venues |
| Data mining venues |
|
|
Extreme learning machines are feedforward neural network for classification or regression with a single layer of hidden nodes, where the weights connecting inputs to hidden nodes are randomly assigned and never updated. These weights between hidden nodes and outputs are learned in a single step, which essentially amounts to learning a linear model. The name "extreme learning machine" (ELM) was given to such models by Guang-Bin Huang.
These models can produce good generalization performance and learn thousands of times faster than networks trained using backpropagation.[1]
Algorithm
The simplest ELM training algorithm learns a model of the form
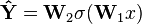
where W1 is the matrix of input-to-hidden-layer weights, σ is some activation function, and W2 is the matrix of hidden-to-output-layer weights. The algorithm proceeds as follows:
- Fill W1 with Gaussian random noise;
- estimate W2 by least-squares fit to a matrix of response variables Y, computed using the pseudoinverse ⋅+, given a design matrix X:
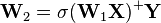
Controversy
The purported invention of the ELM, in 2006, provoked some debate. In particular, it was pointed out in a letter to the editor of IEEE Transactions on Neural Networks that the idea of using a hidden layer connected to the inputs by random untrained weights was already suggested in the original papers on RBF networks in the late 1980s, and experiments with multi-layer perceptrons with similar randomness had appeared in about the same timeframe; Guang-Bin Huang replied by pointing out subtle differences.[2] In a 2015 paper, Huang responded to complaints about his invention of the name ELM for already-existing methods, complaining of "very negative and unhelpful comments on ELM in neither academic nor professional manner due to various reasons and intentions" and an "irresponsible anonymous attack which intends to destroy harmony research environment", arguing that his work "provides a unifying learning platform" for various types of neural nets.[3]
See also
References
- ↑ Huang, Guang-Bin; Zhu, Qin-Yu; Siew, Chee-Kheong (2006). "Extreme learning machine: theory and applications". Neurocomputing 70 (1): 489–501. doi:10.1016/j.neucom.2005.12.126. CiteSeerX: 10
.1 ..1 .217 .3692 - ↑ Wang, Lipo P.; Wan, Chunru R. "Comments on “The Extreme Learning Machine”". IEEE Trans. Neural Networks. CiteSeerX: 10
.1 ..1 .217 .2330 - ↑ Huang, Guang-Bin (2015). "What are Extreme Learning Machines? Filling the Gap Between Frank Rosenblatt’s Dream and John von Neumann’s Puzzle" (PDF). Cognitive Computing 7. doi:10.1007/s12559-015-9333-0.