Explained sum of squares
In statistics, the explained sum of squares (ESS), alternatively known as the model sum of squares or sum of squares due to regression ("SSR" – not to be confused with the residual sum of squares RSS), is a quantity used in describing how well a model, often a regression model, represents the data being modelled. In particular, the explained sum of squares measures how much variation there is in the modelled values and this is compared to the total sum of squares, which measures how much variation there is in the observed data, and to the residual sum of squares, which measures the variation in the modelling errors.
Definition
The explained sum of squares (ESS) is the sum of the squares of the deviations of the predicted values from the mean value of a response variable, in a standard regression model — for example, yi = a + b1x1i + b2x2i + ... + εi, where yi is the i th observation of the response variable, xji is the i th observation of the j th explanatory variable, a and bi are coefficients, i indexes the observations from 1 to n, and εi is the i th value of the error term. In general, the greater the ESS, the better the estimated model performs.
If  and
and  are the estimated coefficients, then
are the estimated coefficients, then

is the i th predicted value of the response variable. The ESS is the sum of the squares of the differences of the predicted values and the mean value of the response variable:
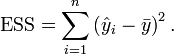
In general: total sum of squares = explained sum of squares + residual sum of squares.
Partitioning in simple linear regression
The following equality, stating that the total sum of squares equals the residual sum of squares plus the explained sum of squares, is generally true in simple linear regression:
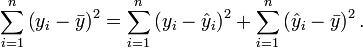
Simple derivation
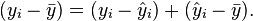
Square both sides and sum over all i:
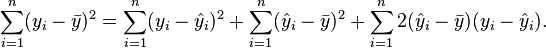
Simple linear regression gives  .[1] What follows depends on this.
.[1] What follows depends on this.

Again simple linear regression gives[1]
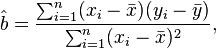
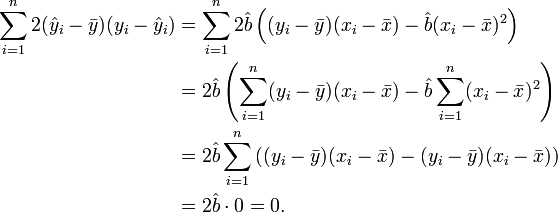
Partitioning in the general ordinary least squares model
The general regression model with n observations and k explanators, the first of which is a constant unit vector whose coefficient is the regression intercept, is
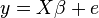
where y is an n × 1 vector of dependent variable observations, each column of the n × k matrix X is a vector of observations on one of the k explanators, 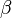 is a k × 1 vector of true coefficients, and e is an n × 1 vector of the true underlying errors. The ordinary least squares estimator for is
is a k × 1 vector of true coefficients, and e is an n × 1 vector of the true underlying errors. The ordinary least squares estimator for is

The residual vector 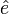 is
is  , so the residual sum of squares
, so the residual sum of squares 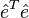 is, after simplification,
is, after simplification,
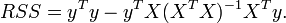
Denote as 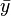 the constant vector all of whose elements are the sample mean
the constant vector all of whose elements are the sample mean 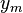 of the dependent variable values in the vector y. Then the total sum of squares is
of the dependent variable values in the vector y. Then the total sum of squares is
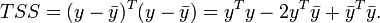
The explained sum of squares, defined as the sum of squared deviations of the predicted values from the observed mean of y, is

Using 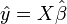 in this, and simplifying to obtain
in this, and simplifying to obtain 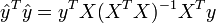 , gives the result that TSS = ESS + RSS if and only if
, gives the result that TSS = ESS + RSS if and only if 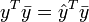 . The left side of this is times the sum of the elements of y, and the right side is times the sum of the elements of
. The left side of this is times the sum of the elements of y, and the right side is times the sum of the elements of  , so the condition is that the sum of the elements of y equals the sum of the elements of , or equivalently that the sum of the prediction errors (residuals)
, so the condition is that the sum of the elements of y equals the sum of the elements of , or equivalently that the sum of the prediction errors (residuals) 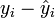 is zero. This can be seen to be true by noting the well-known OLS property that the k × 1 vector
is zero. This can be seen to be true by noting the well-known OLS property that the k × 1 vector ![X^T \hat e = X^T [I - X(X^T X)^{-1}X^T]y= 0](../I/m/80cb74137f71207c1b9be6b9f41f3f8a.png) : since the first column of X is a vector of ones, the first element of this vector
: since the first column of X is a vector of ones, the first element of this vector 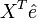 is the sum of the residuals and is equal to zero. This proves that the condition holds for the result that TSS = ESS + RSS.
is the sum of the residuals and is equal to zero. This proves that the condition holds for the result that TSS = ESS + RSS.
In linear algebra terms, we have 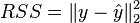 ,
, 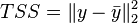 ,
,  .
The proof can be simplified by noting that
.
The proof can be simplified by noting that 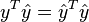 . The proof is as follows:
. The proof is as follows:

Thus,
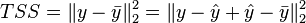


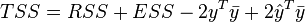
which again gives the result that TSS = ESS + RSS if and only if .
See also
Notes
References
- S. E. Maxwell and H. D. Delaney (1990), "Designing experiments and analyzing data: A model comparison perspective". Wadsworth. pp. 289–290.
- G. A. Milliken and D. E. Johnson (1984), "Analysis of messy data", Vol. I: Designed experiments. Van Nostrand Reinhold. pp. 146–151.
- B. G. Tabachnick and L. S. Fidell (2007), "Experimental design using ANOVA". Duxbury. p. 220.
- B. G. Tabachnick and L. S. Fidell (2007), "Using multivariate statistics", 5th ed. Pearson Education. pp. 217–218.