Invariant estimator
In statistics, the concept of being an invariant estimator is a criterion that can be used to compare the properties of different estimators for the same quantity. It is a way of formalising the idea that an estimator should have certain intuitively appealing qualities. Strictly speaking, "invariant" would mean that the estimates themselves are unchanged when both the measurements and the parameters are transformed in a compatible way, but the meaning has been extended to allow the estimates to change in appropriate ways with such transformations.[1] The term equivariant estimator is used in formal mathematical contexts that include a precise description of the relation of the way the estimator changes in response to changes to the dataset and parameterisation: this corresponds to the use of "equivariance" in more general mathematics.
General setting
Background
In statistical inference, there are several approaches to estimation theory that can be used to decide immediately what estimators should be used according to those approaches. For example, ideas from Bayesian inference would lead directly to Bayesian estimators. Similarly, the theory of classical statistical inference can sometimes lead to strong conclusions about what estimator should be used. However, the usefulness of these theories depends on having a fully prescribed statistical model and may also depend on having a relevant loss function to determine the estimator. Thus a Bayesian analysis might be undertaken, leading to a posterior distribution for relevant parameters, but the use of a specific utility or loss function may be unclear. Ideas of invariance can then be applied to the task of summarising the posterior distribution. In other cases, statistical analyses are undertaken without a fully defined statistical model or the classical theory of statistical inference cannot be readily applied because the family of models being considered are not amenable to such treatment. In addition to these cases where general theory does not prescribe an estimator, the concept of invariance of an estimator can be applied when seeking estimators of alternative forms, either for the sake of simplicity of application of the estimator or so that the estimator is robust.
The concept of invariance is sometimes used on its own as a way of choosing between estimators, but this is not necessarily definitive. For example, a requirement of invariance may be incompatible with the requirement that the estimator be mean-unbiased; on the other hand, the criterion of median-unbiasedness is defined in terms of the estimator's sampling distribution and so is invariant under many transformations.
One use of the concept of invariance is where a class or family of estimators is proposed and a particular formulation must be selected amongst these. One procedure is to impose relevant invariance properties and then to find the formulation within this class that has the best properties, leading to what is called the optimal invariant estimator.
Some classes of invariant estimators
There are several types of transformations that are usefully considered when dealing with invariant estimators. Each gives rise to a class of estimators which are invariant to those particular types of transformation.
- Shift invariance: Notionally, estimates of a location parameter should be invariant to simple shifts of the data values. If all data values are increased by a given amount, the estimate should change by the same amount. When considering estimation using a weighted average, this invariance requirement immediately implies that the weights should sum to one. While the same result is often derived from a requirement for unbiasedness, the use of "invariance" does not require that a mean value exists and makes no use of any probability distribution at all.
- Scale invariance: Note that this topic about the invariance of the estimator scale parameter not to be confused with the more general scale invariance about the behavior of systems under aggregate properties (in physics).
- Parameter-transformation invariance: Here, the transformation applies to the parameters alone. The concept here is that essentially the same inference should be made from data and a model involving a parameter θ as would be made from the same data if the model used a parameter φ, where φ is a one-to-one transformation of θ, φ=h(θ). According to this type of invariance, results from transformation-invariant estimators should also be related by φ=h(θ). Maximum likelihood estimators have this property. Though the asymptotic properties of the estimator might be invariant, the small sample properties can be different, and a specific distribution needs to be derived.[2]
- Permutation invariance: Where a set of data values can be represented by a statistical model that they are outcomes from independent and identically distributed random variables, it is reasonable to impose the requirement that any estimator of any property of the common distribution should be permutation-invariant: specifically that the estimator, considered as a function of the set of data-values, should not change if items of data are swapped within the dataset.
The combination of permutation invariance and location invariance for estimating a location parameter from an independent and identically distributed dataset using a weighted average implies that the weights should be identical and sum to one. Of course, estimators other than a weighted average may be preferable.
Optimal invariant estimators
Under this setting, we are given a set of measurements  which contains information about an unknown parameter
which contains information about an unknown parameter  . The measurements are modelled as a vector random variable having a probability density function
. The measurements are modelled as a vector random variable having a probability density function  which depends on a parameter vector .
which depends on a parameter vector .
The problem is to estimate given . The estimate, denoted by 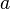 , is a function of the measurements and belongs to a set
, is a function of the measurements and belongs to a set 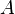 . The quality of the result is defined by a loss function
. The quality of the result is defined by a loss function  which determines a risk function
which determines a risk function ![R=R(a,\theta)=E[L(a,\theta)|\theta]](../I/m/6e666eecb4db084fcf6016ff2daacfde.png) . The sets of possible values of , , and are denoted by
. The sets of possible values of , , and are denoted by 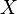 ,
, 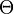 , and , respectively.
, and , respectively.
In classification
In statistical classification, the rule which assigns a class to a new data-item can be consider to be a special type of estimator. A number of invariance-type considerations can be brought to bear in formulating prior knowledge for pattern recognition.
Mathematical setting
Definition
An invariant estimator is an estimator which obeys the following two rules:
- Principle of Rational Invariance: The action taken in a decision problem should not depend on transformation on the measurement used
- Invariance Principle: If two decision problems have the same formal structure (in terms of , , and
 ), then the same decision rule should be used in each problem.
), then the same decision rule should be used in each problem.
To define an invariant or equivariant estimator formally, some definitions related to groups of transformations are needed first. Let denote the set of possible data-samples. A group of transformations of , to be denoted by  , is a set of (measurable) 1:1 and onto transformations of into itself, which satisfies the following conditions:
, is a set of (measurable) 1:1 and onto transformations of into itself, which satisfies the following conditions:
- If
 and
and  then
then 
- If
 then
then  , where
, where  (That is, each transformation has an inverse within the group.)
(That is, each transformation has an inverse within the group.) -
 (i.e. there is an identity transformation
(i.e. there is an identity transformation  )
)
Datasets 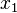 and
and 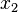 in are equivalent if
in are equivalent if  for some . All the equivalent points form an equivalence class.
Such an equivalence class is called an orbit (in ). The
for some . All the equivalent points form an equivalence class.
Such an equivalence class is called an orbit (in ). The 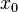 orbit,
orbit,  , is the set
, is the set  .
If consists of a single orbit then
.
If consists of a single orbit then  is said to be transitive.
is said to be transitive.
A family of densities 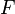 is said to be invariant under the group if, for every and
is said to be invariant under the group if, for every and  there exists a unique
there exists a unique  such that
such that  has density
has density  .
. 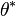 will be denoted
will be denoted  .
.
If is invariant under the group then the loss function  is said to be invariant under if for every and
is said to be invariant under if for every and  there exists an
there exists an  such that
such that  for all . The transformed value
for all . The transformed value  will be denoted by
will be denoted by 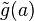 .
.
In the above,  is a group of transformations from to itself and
is a group of transformations from to itself and  is a group of transformations from to itself.
is a group of transformations from to itself.
An estimation problem is invariant(equivariant) under if there exist three groups  as defined above.
as defined above.
For an estimation problem that is invariant under , estimator 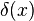 is an invariant estimator under if, for all
is an invariant estimator under if, for all  and ,
and ,

Properties
- The risk function of an invariant estimator,
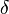 , is constant on orbits of . Equivalently
, is constant on orbits of . Equivalently  for all and
for all and  .
. - The risk function of an invariant estimator with transitive
 is constant.
is constant.
For a given problem, the invariant estimator with the lowest risk is termed the "best invariant estimator". Best invariant estimator cannot always be achieved. A special case for which it can be achieved is the case when is transitive.
Example: Location parameter
Suppose is a location parameter if the density of is of the form  . For
. For  and
and  , the problem is invariant under
, the problem is invariant under  . The invariant estimator in this case must satisfy
. The invariant estimator in this case must satisfy

thus it is of the form  (
( ). is transitive on so the risk does not vary with : that is,
). is transitive on so the risk does not vary with : that is, ![R(\theta,\delta)=R(0,\delta)=\operatorname{E}[L(X+K)|\theta=0]](../I/m/55b0a7f4f256ea88e2d54d7dcc4af953.png) . The best invariant estimator is the one that brings the risk
. The best invariant estimator is the one that brings the risk  to minimum.
to minimum.
In the case that L is the squared error ![\delta(x)=x-\operatorname{E}[X|\theta=0].](../I/m/ae5cc32a508f3fa69ca1b39855596d96.png)
Pitman estimator
The estimation problem is that  has density
has density 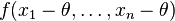 , where θ is a parameter to be estimated, and where the loss function is
, where θ is a parameter to be estimated, and where the loss function is  . This problem is invariant with the following (additive) transformation groups:
. This problem is invariant with the following (additive) transformation groups:



The best invariant estimator is the one that minimizes
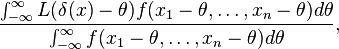
and this is Pitman's estimator (1939).
For the squared error loss case, the result is

If  (i.e. a multivariate normal distribution with independent, unit-variance components) then
(i.e. a multivariate normal distribution with independent, unit-variance components) then

If  (independent components having a Cauchy distribution with scale parameter σ) then
(independent components having a Cauchy distribution with scale parameter σ) then
 ,. However the result is
,. However the result is
![\delta_{pitman}=\sum_{k=1}^n{x_k\left[\frac{Re\{w_k\}}{\sum_{m=1}^{n}{Re\{w_k\}}}\right]}, \qquad n>1,](../I/m/a3587915647c18a1eaff503342e87e3e.png)
with
![w_k = \prod_{j\ne k}\left[\frac{1}{(x_k-x_j)^2+4\sigma^2}\right]\left[1-\frac{2\sigma}{(x_k-x_j)}i\right].](../I/m/31ec86ba8d567985d83e6fe1e08a953c.png)
References
- Berger, James O. (1985). Statistical decision theory and Bayesian Analysis (2nd ed.). New York: Springer-Verlag. ISBN 0-387-96098-8. MR 0804611.
- Freue, Gabriela V. Cohen (2007) "The Pitman estimator of the Cauchy location parameter", Journal of Statistical Planning and Inference, 137, 1900–1913 doi:10.1016/j.jspi.2006.05.002
- Pitman, E.J.G. (1939) "The estimation of the location and scale parameters of a continuous population of any given form", Biometrika, 30 (3/4), 391–421. JSTOR 2332656
- Pitman, E.J.G. (1939) "Tests of Hypotheses Concerning Location and Scale Parameters", Biometrika, 31 (1/2), 200–215. JSTOR 2334983