Efficient estimator
In statistics, an efficient estimator is an estimator that estimates the quantity of interest in some “best possible” manner. The notion of “best possible” relies upon the choice of a particular loss function — the function which quantifies the relative degree of undesirability of estimation errors of different magnitudes. The most common choice of the loss function is quadratic, resulting in the mean squared error criterion of optimality.[1]
Finite-sample efficiency
Suppose { Pθ | θ ∈ Θ } is a parametric model and X = (X1, …, Xn) are the data sampled from this model. Let T = T(X) be an estimator for the parameter θ. If this estimator is unbiased (that is, E[ T ] = θ), then the Cramér–Rao inequality states the variance of this estimator is bounded from below:
![\operatorname{Var}[\,T\,]\ \geq\ \mathcal{I}_\theta^{-1},](../I/m/c31e8e7d4ca75b7d9e0dbe5592178325.png)
where 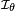 is the Fisher information matrix of the model at point θ. Generally, the variance measures the degree of dispersion of a random variable around its mean. Thus estimators with small variances are more concentrated, they estimate the parameters more precisely. We say that the estimator is finite-sample efficient estimator (in the class of unbiased estimators) if it reaches the lower bound in the Cramér–Rao inequality above, for all θ ∈ Θ. Efficient estimators are always minimum variance unbiased estimators. However the converse is false: There exist point-estimation problems for which the minimum-variance mean-unbiased estimator is inefficient.[2]
is the Fisher information matrix of the model at point θ. Generally, the variance measures the degree of dispersion of a random variable around its mean. Thus estimators with small variances are more concentrated, they estimate the parameters more precisely. We say that the estimator is finite-sample efficient estimator (in the class of unbiased estimators) if it reaches the lower bound in the Cramér–Rao inequality above, for all θ ∈ Θ. Efficient estimators are always minimum variance unbiased estimators. However the converse is false: There exist point-estimation problems for which the minimum-variance mean-unbiased estimator is inefficient.[2]
Historically, finite-sample efficiency was an early optimality criterion. However this criterion has some limitations:
- Finite-sample efficient estimators are extremely rare. In fact, it was proved that efficient estimation is possible only in an exponential family, and only for the natural parameters of that family.
- This notion of efficiency is restricted to the class of unbiased estimators. Since there are no good theoretical reasons to require that estimators are unbiased, this restriction is inconvenient. In fact, if we use mean squared error as a selection criterion, many biased estimators will slightly outperform the “best” unbiased ones. For example, in multivariate statistics for dimension three or more, the mean-unbiased estimator, sample mean, is inadmissible: Regardless of the outcome, its performance is worse than for example the James–Stein estimator.
- Finite-sample efficiency is based on the variance, as a criterion according to which the estimators are judged. A more general approach is to use loss functions other than quadratic ones, in which case the finite-sample efficiency can no longer be formulated.
Example
Among the models encountered in practice, efficient estimators exist for: the mean μ of the normal distribution (but not the variance σ2), parameter λ of the Poisson distribution, the probability p in the binomial or multinomial distribution.
Consider the model of a normal distribution with unknown mean but known variance: { Pθ = N(θ, σ2) | θ ∈ R }. The data consists of n iid observations from this model: X = (x1, …, xn). We estimate the parameter θ using the sample mean of all observations:
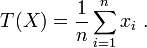
This estimator has mean θ and variance of σ2 / n, which is equal to the reciprocal of the Fisher information from the sample. Thus, the sample mean is a finite-sample efficient estimator for the mean of the normal distribution.
Relative efficiency
If  and
and  are estimators for the parameter
are estimators for the parameter  , then is said to dominate if:
, then is said to dominate if:
- its mean squared error (MSE) is smaller for at least some value of
- the MSE does not exceed that of for any value of θ.
Formally, dominates if
![\mathrm{E}
\left[
(T_1 - \theta)^2
\right]
\leq
\mathrm{E}
\left[
(T_2-\theta)^2
\right]](../I/m/372ed8d78dce9eef004a1e6e0c9de3dc.png)
holds for all , with strict inequality holding somewhere.
The relative efficiency is defined as
![e(T_1,T_2)
=
\frac
{\mathrm{E} \left[ (T_2-\theta)^2 \right]}
{\mathrm{E} \left[ (T_1-\theta)^2 \right]}](../I/m/17e7a0acc6536953ff3053bc1684bf75.png)
Although  is in general a function of , in many cases the dependence drops out; if this is so, being greater than one would indicate that is preferable, whatever the true value of .
is in general a function of , in many cases the dependence drops out; if this is so, being greater than one would indicate that is preferable, whatever the true value of .
Asymptotic efficiency
For some estimators, they can attain efficiency asymptotically and are thus called asymptotically efficient estimators. This can be the case for some maximum likelihood estimators or for any estimators that attain equality of the Cramér-Rao bound asymptotically.
See also
Notes
- ↑ Everitt (2002, p. 128)
- ↑ Romano & Siegel (1986, p. 194)
References
- Everitt, B.S. (2002). The Cambridge Dictionary of Statistics (2nd ed.). New York, Cambridge University Press. ISBN 0-521-81099-X.
- Romano, Joseph P.; Siegel, Andrew F. (1986). Counterexamples in Probability and Statistics. Chapman and Hall.
Further reading
- Lehmann, E.L.; Casella, G. (1998). Theory of Point Estimation (2nd ed.). Springer. ISBN 0-387-98502-6.
- Pfanzagl, Johann; with the assistance of R. Hamböker (1994). Parametric Statistical Theory. Berlin: Walter de Gruyter. ISBN 3-11-013863-8. MR 1291393.