Earley parser
In computer science, the Earley parser is an algorithm for parsing strings that belong to a given context-free language, though (depending on the variant) it may suffer problems with certain nullable grammars.[1] The algorithm, named after its inventor, Jay Earley, is a chart parser that uses dynamic programming; it is mainly used for parsing in computational linguistics. It was first introduced in his dissertation[2] in 1968 (and later appeared in abbreviated, more legible form in a journal[3]).
Earley parsers are appealing because they can parse all context-free languages, unlike LR parsers and LL parsers, which are more typically used in compilers but which can only handle restricted classes of languages. The Earley parser executes in cubic time in the general case 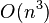 , where n is the length of the parsed string, quadratic time for unambiguous grammars
, where n is the length of the parsed string, quadratic time for unambiguous grammars 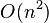 , and linear time for almost all LR(k) grammars. It performs particularly well when the rules are written left-recursively.
, and linear time for almost all LR(k) grammars. It performs particularly well when the rules are written left-recursively.
Earley recogniser
The following algorithm describes the Earley recogniser. The recogniser can be easily modified to create a parse tree as it recognises, and in that way can be turned into a parser.
The algorithm
In the following descriptions, α, β, and γ represent any string of terminals/nonterminals (including the empty string), X and Y represent single nonterminals, and a represents a terminal symbol.
Earley's algorithm is a top-down dynamic programming algorithm. In the following, we use Earley's dot notation: given a production X → αβ, the notation X → α • β represents a condition in which α has already been parsed and β is expected.
Input position 0 is the position prior to input. Input position n is the position after accepting the nth token. (Informally, input positions can be thought of as locations at token boundaries.) For every input position, the parser generates a state set. Each state is a tuple (X → α • β, i), consisting of
- the production currently being matched (X → α β)
- our current position in that production (represented by the dot)
- the position i in the input at which the matching of this production began: the origin position
(Earley's original algorithm included a look-ahead in the state; later research showed this to have little practical effect on the parsing efficiency, and it has subsequently been dropped from most implementations.)
The state set at input position k is called S(k). The parser is seeded with S(0) consisting of only the top-level rule. The parser then repeatedly executes three operations: prediction, scanning, and completion.
- Prediction: For every state in S(k) of the form (X → α • Y β, j) (where j is the origin position as above), add (Y → • γ, k) to S(k) for every production in the grammar with Y on the left-hand side (Y → γ).
- Scanning: If a is the next symbol in the input stream, for every state in S(k) of the form (X → α • a β, j), add (X → α a • β, j) to S(k+1).
- Completion: For every state in S(k) of the form (X → γ •, j), find states in S(j) of the form (Y → α • X β, i) and add (Y → α X • β, i) to S(k).
It is important to note that duplicate states are not added to the state set, only new ones. These three operations are repeated until no new states can be added to the set. The set is generally implemented as a queue of states to process, with the operation to be performed depending on what kind of state it is.
Pseudocode
Adapted from Speech and Language Processing[4] by Daniel Jurafsky and James H. Martin,
function EARLEY-PARSE(words, grammar)
ENQUEUE((γ → •S, 0), chart[0])
for i ← from 0 to LENGTH(words) do
for each state in chart[i] do
if INCOMPLETE?(state) then
if NEXT-CAT(state) is a nonterminal then
PREDICTOR(state, i, grammar) // non-terminal
else do
SCANNER(state, i) // terminal
else do
COMPLETER(state, i)
end
end
return chart
procedure PREDICTOR((A → α•B, i), j, grammar)
for each (B → γ) in GRAMMAR-RULES-FOR(B, grammar) do
ADD-TO-SET((B → •γ, j), chart[j])
end
procedure SCANNER((A → α•B, i), j)
if B ⊂ PARTS-OF-SPEECH(word[j]) then
ADD-TO-SET((B → word[j], j), chart[j + 1])
end
procedure COMPLETER((B → γ•, j), k)
for each (A → α•Bβ, i) in chart[j] do
ADD-TO-SET((A → αB•β, i), chart[k])
end
Example
Consider the following simple grammar for arithmetic expressions:
<P> ::= <S> # the start rule
<S> ::= <S> "+" <M> | <M>
<M> ::= <M> "*" <T> | <T>
<T> ::= "1" | "2" | "3" | "4"
With the input:
2 + 3 * 4
This is the sequence of state sets:
(state no.) Production (Origin) # Comment -----------------------------------------
S(0): • 2 + 3 * 4
(1) P → • S (0) # start rule (2) S → • S + M (0) # predict from (1) (3) S → • M (0) # predict from (1) (4) M → • M * T (0) # predict from (3) (5) M → • T (0) # predict from (3) (6) T → • number (0) # predict from (5)
S(1): 2 • + 3 * 4
(1) T → number • (0) # scan from S(0)(6) (2) M → T • (0) # complete from (1) and S(0)(5) (3) M → M • * T (0) # complete from (2) and S(0)(4) (4) S → M • (0) # complete from (2) and S(0)(3) (5) S → S • + M (0) # complete from (4) and S(0)(2) (6) P → S • (0) # complete from (4) and S(0)(1)
S(2): 2 + • 3 * 4
(1) S → S + • M (0) # scan from S(1)(5) (2) M → • M * T (2) # predict from (1) (3) M → • T (2) # predict from (1) (4) T → • number (2) # predict from (3)
S(3): 2 + 3 • * 4
(1) T → number • (2) # scan from S(2)(4) (2) M → T • (2) # complete from (1) and S(2)(3) (3) M → M • * T (2) # complete from (2) and S(2)(2) (4) S → S + M • (0) # complete from (2) and S(2)(1) (5) S → S • + M (0) # complete from (4) and S(0)(2) (6) P → S • (0) # complete from (4) and S(0)(1)
S(4): 2 + 3 * • 4
(1) M → M * • T (2) # scan from S(3)(3) (2) T → • number (4) # predict from (1)
S(5): 2 + 3 * 4 •
(1) T → number • (4) # scan from S(4)(2) (2) M → M * T • (2) # complete from (1) and S(4)(1) (3) M → M • * T (2) # complete from (2) and S(2)(2) (4) S → S + M • (0) # complete from (2) and S(2)(1) (5) S → S • + M (0) # complete from (4) and S(0)(2) (6) P → S • (0) # complete from (4) and S(0)(1)
The state (P → S •, 0) represents a completed parse. This state also appears in S(3) and S(1), which are complete sentences.
Constructing the parse forest
Earley's dissertation[5] briefly describes an algorithm for constructing parse trees by adding a set of pointers from each non-terminal in an Earley item back to the items which caused it to be recognized. But Tomita noticed[6] that this does not take into account the relations between symbols, so if we consider the grammar S → SS | b and the string bbb, it only notes that each S can match one or two b's, and thus produces spurious derivations for bb and bbbb as well as the two correct derivations for bbb.
It is relatively straightforward to take the complete items from the chart and search through them from the top down, assembling the ones which fit together to make the parse forest.
Another method, described in,[7] is to build the parse forest as you go, augmenting each Earley item with a pointer to a shared packed parse forest (SPPF) node labelled with a triple (s, i, j) where s is a symbol or an LR(0) item (production rule with dot), and i and j give the section of the input string derived by this node. A node's contents are either a pair of child pointers giving a single derivation, or a list of "packed" nodes each containing a pair of pointers and representing one derivation. SPPF nodes are unique (there is only one with a given label), but may contain more than one derivation for ambiguous parses. So even if an operation does not add an Earley item (because it already exists), it may still add a derivation to the item's parse forest.
- Predicted items have a null SPPF pointer.
- The scanner creates an SPPF node representing the non-terminal it is scanning.
- Then when the scanner or completer advance an item, they add a derivation whose children are the node from the item whose dot was advanced, and the one for the new symbol which was advanced over (the non-terminal or completed item).
Note also that SPPF nodes are never labeled with a completed LR(0) item: instead they are labelled with the symbol which is produced so that all derivations are combined under one node regardless of which alternative production they come from.
See also
Citations
- ↑ Kegler, Jeffrey. "What is the Marpa algorithm?". Retrieved 20 August 2013.
- ↑ Earley, Jay (1968). An Efficient Context-Free Parsing Algorithm (PDF). Carnegie-Mellon Dissertation.
- ↑ Earley, Jay (1970), "An efficient context-free parsing algorithm", Communications of the ACM 13 (2): 94–102, doi:10.1145/362007.362035
- ↑ Jurafsky, D. (2009). Speech and Language Processing: An Introduction to Natural Language Processing, Computational Linguistics, and Speech Recognition. Pearson Prentice Hall. ISBN 9780131873216.
- ↑ Earley, Jay (1968). An Efficient Context-Free Parsing Algorithm (PDF). Carnegie-Mellon Dissertation. p. 106.
- ↑ Tomita, Masaru (April 17, 2013). Efficient Parsing for Natural Language: A Fast Algorithm for Practical Systems. Springer Science and Business Media. p. 74. ISBN 1475718853. Retrieved 16 September 2015.
- ↑ Scott, Elizabeth (April 1, 2008). "SPPF-Style Parsing From Earley Recognizers". Electronic Notes in Theoretical Computer Science 203 (2): 53–67. doi:10.1016/j.entcs.2008.03.044. Retrieved 16 September 2015.
Other reference materials
- Aycock, John; Horspool, R. Nigel (2002). Practical Earley Parsing. The Computer Journal 45. pp. 620–630. doi:10.1093/comjnl/45.6.620.
- Leo, Joop M. I. M. (1991), "A general context-free parsing algorithm running in linear time on every LR(k) grammar without using lookahead", Theoretical Computer Science 82 (1): 165–176, doi:10.1016/0304-3975(91)90180-A, MR 1112117
- Tomita, Masaru (1984). "LR parsers for natural languages". COLING. 10th International Conference on Computational Linguistics. pp. 354–357.
Implementations
C, C++
- 'Yet Another Earley Parser (YAEP)' – C/C++ libraries
- 'C Earley Parser' – an Earley parser C
Haskell
Java
- PEN – a Java library that implements the Earley algorithm
- Pep – a Java library that implements the Earley algorithm and provides charts and parse trees as parsing artifacts
- Earley.java – a Java implementation of Earley parser
C#
- coonsta/earley - An Earley parser in C#
JavaScript
- JavaScript Moony Parser – A type of Earley parser written in JavaScript
- Nearley – an Earley parser that's starting to integrate the improvements that Marpa adopted
- A Pint-sized Earley Parser – a toy parser (with annotated pseudocode) to demonstrate Elizabeth Scott's technique for building the shared packed parse forest
- earley-parser-js – a tiny JavaScript implementation of Earley parser (including generation of the parsing-forest)
OCaml
- E3 - An implementation in OCaml, used as the engine for combinator libraries such as P3
- Simple Earley - An implementation of a simple Earley-like parsing algorithm, with documentation.
Perl
- Marpa::R2 – a Perl module. Marpa is an Earley's algorithm that includes the improvements made by Joop Leo, and by Aycock and Horspool.
- Parse::Earley – a Perl module implementing Jay Earley's original algorithm
Python
- Charty – a Python implementation of an Earley parser
- NLTK – a Python toolkit with an Earley parser
- Spark – an object-oriented little language framework for Python implementing an Earley parser
- earley3.py – a stand-alone implementation of the algorithm in less than 150 lines of code, including generation of the parsing-forest and samples
Common Lisp
- CL-Earley-parser – a Common Lisp library implementing an Earley parser
Scheme, Racket
- Charty-Racket – a Scheme-Racket implementation of an Earley parser