Dynamic perfect hashing
In computer science, dynamic perfect hashing is a programming technique for resolving collisions in a hash table data structure.[1][2][3] While more memory-intensive than its hash table counterparts, this technique is useful for situations where fast queries, insertions, and deletions must be made on a large set of elements.
Details
Static Case
FKS Scheme
The problem of optimal static hashing was first solved in general by Fredman, Komlós and Szémeredi.[4] In their 1984 paper,[1] they detail a two-tiered hash table scheme in which each bucket of the (first-level) hash table corresponds to a separate second-level hash table. Keys are hashed twice—the first hash value maps to a certain bucket in the first-level hash table; the second hash value gives the position of that entry in that bucket's second-level hash table. The second-level table is guaranteed to be collision-free (i.e. perfect hashing) upon construction. Consequently the look-up cost is guaranteed to be O(1) in the worst-case.[2]
In the static case, we are given a set with a total of x entries, each one with a unique key, ahead of time. Fredman, Komlós and Szémeredi pick a first-level hash table with size s = 2(x-1) buckets.[2]
To construct, x entries are separated into s buckets by the top-level hashing function, where s = 2(x-1). Then for each bucket with k entries, a second-level table is allocated with k2 slots, and its hash function is selected at random from a universal hash function set so that it is collision-free (i.e. a perfect hash function) and stored alongside the hash table. If the hash function randomly selected creates a table with collisions, a new hash function is randomly selected until a collision-free table can be guaranteed. Finally, with the collision-free hash, the k entries are hashed into the second-level table.
The quadratic size of the k2 space ensures that randomly creating a table with collisions is infrequent and independent of the size of k, providing linear amortized construction time. Although each second-level table requires quadratic space, if the keys inserted into the first-level hash table are uniformly distributed, the structure as a whole occupies expected O(n) space, since bucket sizes are small with high probability.[1]
The first-level hash function is specifically chosen so that, for the specific set of x unique key values, the total space T used by all the second-level hash tables has expected O(n) space, and more specifically T < s + 4*x. Fredman, Komlós and Szémeredi showed that given a universal hashing family of hash functions, at least half of those functions have that property.[2]
Dynamic Case
Dietzfelbinger et al. present a dynamic dictionary algorithm that, when a set of n items is incrementally added to the dictionary, membership queries always run in constant time and therefore O(1) worst-case time, the total storage required is O(n) (linear), and O(1) expected amortized insertion and deletion time (amortized constant time).
In the dynamic case, when a key is inserted into the hash table, if its entry in its respective subtable is occupied, then a collision is said to occur and the subtable is rebuilt based on its new total entry count and randomly selected hash function. Because the load factor of the second-level table is kept low (1/k), rebuilding is infrequent, and the amortized expected cost of insertions is O(1).[2] Similarly, the amortized expected cost of deletions is O(1).[2]
Additionally, the ultimate sizes of the top-level table or any of the subtables is unknowable in the dynamic case. One method for maintaining expected O(n) space of the table is to prompt a full reconstruction when a sufficient number of insertions and deletions have occurred. By results due to Dietzfelbinger et al.,[2] as long as the total number of insertions or deletions exceeds the number of elements at the time of last construction, the amortized expected cost of insertion and deletion remain O(1) with full rehashing taken into consideration.
The implementation of dynamic perfect hashing by Dietzfelbinger et al. uses these concepts, as well as lazy deletion, and is shown in pseudocode below.
Pseudocode Implementation
locate
function Locate(x) is
j = h(x);
if (position hj(x) of subtable Tj contains x (not deleted))
return (x is in S);
end if
else
return (x is not in S);
end else
end
insert
During the insertion of a new entry x at j, the global operations counter, count, is incremented.
If x exists at j, but is marked as deleted, then the mark is removed.
If x exists at j or at the subtable Tj, and is not marked as deleted, then a collision is said to occur and the jth bucket's second-level table Tj is rebuilt with a different randomly selected hash function hj.
function Insert(x) is
count = count + 1;
if (count > M)
FullRehash(x);
end if
else
j = h(x);
if (Position hj(x) of subtable Tj contains x)
if (x is marked deleted)
remove the delete marker;
end if
end if
else
bj = bj + 1;
if (bj <= mj)
if position hj(x) of Tj is empty
store x in position hj(x) of Tj;
end if
else
Put all unmarked elements of Tj in list Lj;
Append x to list Lj;
bj = length of Lj;
repeat
hj = randomly chosen function in Hsj;
until hj is injective on the elements of Lj;
for all y on list Lj
store y in position hj(y) of Tj;
end for
end else
end if
else
mj = 2 * max{1, mj};
sj = 2 * mj * (mj - 1);
if the sum total of all sj ≤ 32 * M2 / s(M) + 4 * M
Allocate sj cells for Tj;
Put all unmarked elements of Tj in list Lj;
Append x to list Lj;
bj = length of Lj;
repeat
hj = randomly chosen function in Hsj;
until hj is injective on the elements of Lj;
for all y on list Lj
store y in position hj(y) of Tj;
end for
end if
else
FullRehash(x);
end else
end else
end else
end else
end
delete
Deletion of x simply flags x as deleted without removal and increments count. In the case of both insertions and deletions, if count reaches a threshold M the entire table is rebuilt, where M is some constant multiple of the size of S at the start of a new phase. Here phase refers to the time between full rebuilds. Note that here the -1 in "Delete(x)" is a representation of an element which is not in the set of all possible elements U.
function Delete(x) is
count = count + 1;
j = h(x);
if position hj(x) of subtable Tj contains x
mark x as deleted;
end if
else
return (x is not a member of S);
end else
if (count >= M)
FullRehash(-1);
end if
end
full rebuild
A full rebuild of the table of S first starts by removing all elements marked as deleted and then setting the next threshold value M to some constant multiple of the size of S. A hash function, which partitions S into s(M) subsets, where the size of subset j is sj, is repeatedly randomly chosen until:
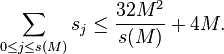
Finally, for each subtable Tj a hash function hj is repeatedly randomly chosen from Hsj until hj is injective on the elements of Tj. The expected time for a full rebuild of the table of S with size n is O(n).[2]
function FullRehash(x) is
Put all unmarked elements of T in list L;
if (x is in U)
append x to L;
end if
count = length of list L;
M = (1 + c) * max{count, 4};
repeat
h = randomly chosen function in Hs(M);
for all j < s(M)
form a list Lj for h(x) = j;
bj = length of Lj;
mj = 2 * bj;
sj = 2 * mj * (mj - 1);
end for
until the sum total of all sj ≤ 32 * M2 / s(M) + 4 * M
for all j < s(M)
Allocate space sj for subtable Tj;
repeat
hj = randomly chosen function in Hsj;
until hj is injective on the elements of list Lj;
end for
for all x on list Lj
store x in position hj(x) of Tj;
end for
end
See also
References
- 1 2 3 Fredman, M. L., Komlós, J., and Szemerédi, E. 1984. Storing a Sparse Table with 0(1) Worst Case Access Time. J. ACM 31, 3 (Jun. 1984), 538-544 http://portal.acm.org/citation.cfm?id=1884#
- 1 2 3 4 5 6 7 8 Dietzfelbinger, M., Karlin, A., Mehlhorn, K., Meyer auf der Heide, F., Rohnert, H., and Tarjan, R. E. 1994. "Dynamic Perfect Hashing: Upper and Lower Bounds". SIAM J. Comput. 23, 4 (Aug. 1994), 738-761. http://portal.acm.org/citation.cfm?id=182370 doi:10.1137/S0097539791194094
- ↑ Erik Demaine, Jeff Lind. 6.897: Advanced Data Structures. MIT Computer Science and Artificial Intelligence Laboratory. Spring 2003.
- ↑ Yap, Chee. "Universal Construction for the FKS Scheme". New York University. New York University. Retrieved 15 February 2015.