Dunnett's test
In statistics, Dunnett's test is a multiple comparison procedure[1] developed by Canadian statistician Charles Dunnett[2] to compare each of a number of treatments with a single control.[3][4] Multiple comparisons to a control are also referred to as many-to-one comparisons.
History
Dunnett's test was developed in 1955;[5] an updated table of critical values was published in 1964.[6]
Multiple Comparisons Problem
The multiple comparisons, multiplicity or multiple testing problem occurs when one considers a set of statistical inferences simultaneously or infers a subset of parameters selected based on the observed values. The major issue in any discussion of multiple-comparison procedures is the question of the probability of Type I errors. Most differences among alternative techniques result from different approaches to the question of how to control these errors. The problem is in part technical; but it is really much more a subjective question of how you want to define the error rate and how large you are willing to let the maximum possible error rate be.[7]
Dunnett's test are well known and widely used in multiple comparison procedure for simultaneously comparing, by interval estimation or hypothesis testing, all active treatments with a control when sampling from a distribution where the normality assumption is reasonable.
Dunnett's test is designed to hold the familywise error rate at or below  when performing multiple comparisons of treatment group with control.[7]
when performing multiple comparisons of treatment group with control.[7]
Uses of Dunnett’s test
The original work on Multiple Comparisons problem was made by Tukey and Scheffé. Their method was a general one, which considered all kinds of pairwise comparisons.[7] Tukey's and Scheffé's methods allow any number of comparisons among a set of sample means. On the other hand, Dunnett's test only compares one group with the others, addressing a special case of multiple comparisons problem — pairwise comparisons of multiple treatment groups with a single control group. In the general case, where we compare each of the pairs, we make 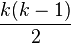 comparisons (where k is the number of groups), but in the treatment vs. controls case we will make only
comparisons (where k is the number of groups), but in the treatment vs. controls case we will make only 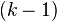 comparisons. If in the case of treatment and control groups we were to use the more general Tukey's and Scheffé's methods, it can result in unnecessary wider confidence intervals. Dunnett's test takes into consideration the special structure of comparing treatment against control and results in narrower confidence intervals.[5]
comparisons. If in the case of treatment and control groups we were to use the more general Tukey's and Scheffé's methods, it can result in unnecessary wider confidence intervals. Dunnett's test takes into consideration the special structure of comparing treatment against control and results in narrower confidence intervals.[5]
It is very common to use Dunnett's test in medical experiments, for example comparing blood count measurements on three groups of animals, one of which served as a control while the other two were treated with two different drugs. Another common use of this method is among agronomists: agronomists may want to study the effect of certain chemicals added to the soil on crop yield, so they will leave some plots untreated (control plots) and compare them to the plots where chemicals were added to the soil (treatment plots).
Formal description of Dunnett's test
Dunnett's test is performed by computing a Student's t-statistic for each experimental, or treatment, group where the statistic compares the treatment group to a single control group.[8][9] Since each comparison has the same control in common, the procedure incorporates the dependencies between these comparisons. In particular, the t-statistics are all derived from the same estimate of the error variance which is obtained by pooling the sums of squares for error across all (treatment and control) groups. The formal test statistic for Dunnett's test is either the largest in absolute value of these t-statistics (if a two-tailed test is required), or the most negative or most positive of the t-statistics (if a one-tailed test is required).
In Dunnett's test we can use a common table of critical values, but more flexible options are nowadays readily available in many statistics packages such as R. The critical values for any given percentage point depend on: whether a one- or- two-tailed test is performed; the number of groups being compared; the overall number of trials.
Assumptions
The analysis considers the case where the results of the experiment are numerical, and the experiment is performed to compare p treatments with a control group. The results can be summarized as a set of 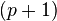 calculated means of the sets of observations,
calculated means of the sets of observations, 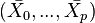 , while
, while 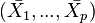 are referring to the treatment and
are referring to the treatment and 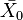 is referring to the control set of observations, and
is referring to the control set of observations, and  is an independent estimate of the common standard deviation of all
is an independent estimate of the common standard deviation of all 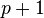 sets of observations. All
sets of observations. All 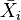 of the sets of observations are assumed to be independently and normally distributed with a common variance
of the sets of observations are assumed to be independently and normally distributed with a common variance  and means
and means  . There is also an assumption that there is an available estimate
. There is also an assumption that there is an available estimate 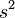 for .
for .
Calculation
Calculation
Dunnett's test's calculation is a procedure that is based on calculating confidence statements about the true or the expected values of the 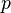 differences
differences 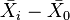 , thus the differences between treatment groups' mean and control group's mean. This procedure enables that the probability of all statements being simultaneously correct is equal to a specified value,
, thus the differences between treatment groups' mean and control group's mean. This procedure enables that the probability of all statements being simultaneously correct is equal to a specified value, . When calculating one sided upper (or lower) Confidence interval for the true value of the difference between the mean of the treatment and the control group, constitutes the probability that this actual value will be less than the upper (or greater than the lower) limit of that interval. When calculating two-sided confidence interval, constitutes the probability that the true value will be between the upper and the lower limits.
. When calculating one sided upper (or lower) Confidence interval for the true value of the difference between the mean of the treatment and the control group, constitutes the probability that this actual value will be less than the upper (or greater than the lower) limit of that interval. When calculating two-sided confidence interval, constitutes the probability that the true value will be between the upper and the lower limits.
First, we will denote the available N observations by 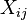 when
when 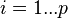 and
and 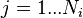 and estimate the common variance by, for example:
and estimate the common variance by, for example:
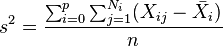 when is the mean of group
when is the mean of group  and
and 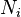 is the number of observations in group , and
is the number of observations in group , and 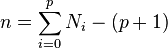 degrees of freedom. As mentioned before, we would like to obtain separate confidence limits for each of the differences
degrees of freedom. As mentioned before, we would like to obtain separate confidence limits for each of the differences 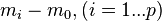 such that the probability that all confidence intervals will contain the corresponding
such that the probability that all confidence intervals will contain the corresponding 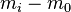 is equal to .
is equal to .
We will consider the general case where there are treatment groups and one control group. We will write:
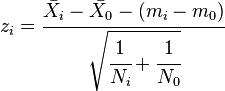
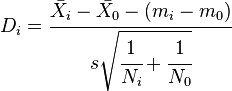
we will also write: 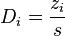 , which follows the Student's t-statistic distribution with n degrees of freedom. The lower confidence limits with joint confidence coefficient for the treatment effects will be given by:
, which follows the Student's t-statistic distribution with n degrees of freedom. The lower confidence limits with joint confidence coefficient for the treatment effects will be given by:
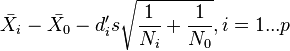
and the constants 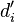 are chosen so that
are chosen so that 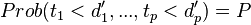 .
Similarly, the upper limits will be given by:
.
Similarly, the upper limits will be given by:
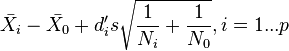
For bounding in both directions, the following interval might be taken:
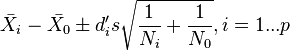
when 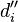 are chosen to satisfy
are chosen to satisfy 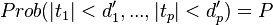 .
The solution to those particular values of for two sided test and for one sided test is given in the tables.[5] An updated table of critical values was published in 1964.[6]
.
The solution to those particular values of for two sided test and for one sided test is given in the tables.[5] An updated table of critical values was published in 1964.[6]
Examples
Breaking strength of fabric[5]
The following example was adapted from one given by Villars[6]. The data represent measurements on the breaking strength of fabric treated by three different chemical process compared with a standard method of manufacture.
| standard | process 1 | process 2 | process 3 | |
|---|---|---|---|---|
| 55 | 55 | 55 | 50 | |
| 47 | 64 | 49 | 44 | |
| 48 | 64 | 52 | 41 | |
| Means | 50 | 61 | 52 | 45 |
| Variance | 19 | 27 | 9 | 21 |
Here , p=3 and N=3. The average variance is 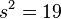 ,
which is an estimate of the common variance of the four sets with (p+1)(N-1)=8
degrees of freedom.
This can be calculated as follows:
,
which is an estimate of the common variance of the four sets with (p+1)(N-1)=8
degrees of freedom.
This can be calculated as follows:
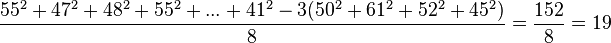 .
.
The standard deviation is 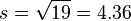 and the estimated standard error of a difference between two means is
and the estimated standard error of a difference between two means is
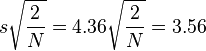 .
.
The quantity which must be added to and/or subtracted from the observed differences between the means to give their confidence limits has been called by Tukey an "allowance" and is given by 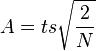 ,
where t is obtained from Dunnett's Table 1 if one side limits are desired or from
Dunnett's Table 2 if two-sided limits are wanted.
For p=3 and d.f.=8 , t=2.42 for one side limits and t=2.88 for two-sided limits for p=95%. Analogous values of t can be determined from the tables if p=99% confidence is required.
For one-sided limits, the allowance is A=(2.42)(3.56)=9 and the experimenter can conclude that:
,
where t is obtained from Dunnett's Table 1 if one side limits are desired or from
Dunnett's Table 2 if two-sided limits are wanted.
For p=3 and d.f.=8 , t=2.42 for one side limits and t=2.88 for two-sided limits for p=95%. Analogous values of t can be determined from the tables if p=99% confidence is required.
For one-sided limits, the allowance is A=(2.42)(3.56)=9 and the experimenter can conclude that:
- The breaking strength using process 1 exceeds the standard by at least
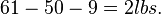
- The breaking strength using process 2 exceeds the standard by at least
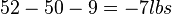 .
. - The breaking strength using process 3 exceeds the standard by at least
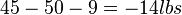 .
.
The joint statement consisting of the above three conclusions has a confidence coefficient of 95%, i.e., in the long run, 95% of such joint statements will actually be correct. Upper limits for the three differences could be obtained in an analogous manner. For two-sided limits, the allowance is A=(2.94)(3.56)=11 and the experimenter can conclude that:
- The breaking strength using process 1 exceeds the standard by an amount between
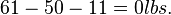 and
and 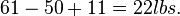
- The breaking strength using process 2 exceeds the standard by an amount between
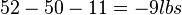 and
and 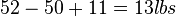 .
.
- The breaking strength using process 3 exceeds the standard by an amount between
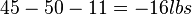 and
and 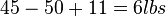 .
The joint confidence coefficient for these three statement is greater than 95%.
(Due to an approximation made in computing Tables 2a and 2b, the tabulated values of t are somewhat larger than necessary so that the actual p's attained are slightly greater than 95 and 99%.No such approximation was made in computing Tables 1a and 1b).
.
The joint confidence coefficient for these three statement is greater than 95%.
(Due to an approximation made in computing Tables 2a and 2b, the tabulated values of t are somewhat larger than necessary so that the actual p's attained are slightly greater than 95 and 99%.No such approximation was made in computing Tables 1a and 1b).
References
- ↑ Upton G. & Cook I. (2006.) A Dictionary of Statistics, 2e, Oxford University Press, Oxford, United Kingdom.
- ↑ Statistics II for Dummies - Deborah Rumsey - Google Books. Books.google.com. 2009-08-19. Retrieved 2012-08-22.
- ↑ Everett B. S. & Shrondal A. (2010.) The Cambridge Dictionary of Statistics, 4e, Cambridge University Press, Cambridge, United Kingdom.
- ↑ "Statistical Software | University of Kentucky Information Technology". Uky.edu. Retrieved 2012-08-22.
- 1 2 3 4 Dunnett C. W. (1955.) "A multiple comparison procedure for comparing several treatments with a control", Journal of the American Statistical Association, 50:1096–1121.
- 1 2 Dunnett C. W. (1964.) "New tables for multiple comparisons with a control", Biometrics, 20:482–491.
- 1 2 3 David C. Howell, "Statistical Methods for Psychology",8th ed.
- ↑ Dunnett's test, HyperStat Online: An Introductory Statistics Textbook and Online Tutorial for Help in Statistics Courses
- ↑ Mechanics of Different Tests - Biostatistics BI 345, Saint Anselm College