Discriminant function analysis
Discriminant function analysis is a statistical analysis to predict a categorical dependent variable (called a grouping variable) by one or more continuous or binary independent variables (called predictor variables). The original dichotomous discriminant analysis was developed by Sir Ronald Fisher in 1936.[1] It is different from an ANOVA or MANOVA, which is used to predict one (ANOVA) or multiple (MANOVA) continuous dependent variables by one or more independent categorical variables. Discriminant function analysis is useful in determining whether a set of variables is effective in predicting category membership.[2]
Discriminant analysis is used when groups are known a priori (unlike in cluster analysis). Each case must have a score on one or more quantitative predictor measures, and a score on a group measure.[3] In simple terms, discriminant function analysis is classification - the act of distributing things into groups, classes or categories of the same type.
Moreover, it is a useful follow-up procedure to a MANOVA instead of doing a series of one-way ANOVAs, for ascertaining how the groups differ on the composite of dependent variables. In this case, a significant F test allows classification based on a linear combination of predictor variables. Terminology can get confusing here, as in MANOVA, the dependent variables are the predictor variables, and the independent variables are the grouping variables.[2]
Assumptions
The assumptions of discriminant analysis are the same as those for MANOVA. The analysis is quite sensitive to outliers and the size of the smallest group must be larger than the number of predictor variables.[3]
- Multivariate normality: Independent variables are normal for each level of the grouping variable.[2][3]
- Homogeneity of variance/covariance (homoscedasticity): Variances among group variables are the same across levels of predictors. Can be tested with Box's M statistic.[2] It has been suggested, however, that linear discriminant analysis be used when covariances are equal, and that quadratic discriminant analysis may be used when covariances are not equal.[3]
- Multicollinearity: Predictive power can decrease with an increased correlation between predictor variables.[3]
- Independence: Participants are assumed to be randomly sampled, and a participant’s score on one variable is assumed to be independent of scores on that variable for all other participants.[2][3]
It has been suggested that discriminant analysis is relatively robust to slight violations of these assumptions,[4] and it has also been shown that discriminant analysis may still be reliable when using dichotomous variables (where multivariate normality is often violated).[5]
Discriminant functions
Discriminant analysis works by creating one or more linear combinations of predictors, creating a new latent variable for each function. These functions are called discriminant functions. The number of functions possible is either Ng-1 where Ng = number of groups, or p (the number of predictors), whichever is smaller. The first function created maximizes the differences between groups on that function. The second function maximizes differences on that function, but also must not be correlated with the previous function. This continues with subsequent functions with the requirement that the new function not be correlated with any of the previous functions.
Given group 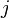 , with
, with 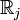 sets of sample space, there is a discriminant rule such that if
sets of sample space, there is a discriminant rule such that if 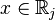 , then
, then 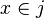 . Discriminant analysis then, finds “good” regions of to minimize classification error, therefore leading to a high percent correct classified in the classification table.Hardle, W., Simar, L. (2007). Applied Multivariate Statistical Analysis. Springer Berlin Heidelberg. pp. 289–303.
. Discriminant analysis then, finds “good” regions of to minimize classification error, therefore leading to a high percent correct classified in the classification table.Hardle, W., Simar, L. (2007). Applied Multivariate Statistical Analysis. Springer Berlin Heidelberg. pp. 289–303.
Each function is given a discriminant score to determine how well it predicts group placement.
- Structure Correlation Coefficients: The correlation between each predictor and the discriminant score of each function. This is a whole correlation.Garson, G. D. (2008). Discriminant function analysis. http://www2.chass.ncsu.edu/garson/pa765/discrim.htm .
- Standardized Coefficients: Each predictor’s unique contribution to each function, therefore this is a partial correlation. Indicates the relative importance of each predictor in predicting group assignment from each function.
- Functions at Group Centroids: Mean discriminant scores for each grouping variable are given for each function. The farther apart the means are, the less error there will be in classification.
Discrimination rules
- Maximum likelihood: Assigns x to the group that maximizes population (group) density.[6]
- Bayes Discriminant Rule: Assigns x to the group that maximizes
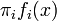 , where
, where 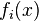 represents the prior probability of that classification, and πi represents the population density.[6]
represents the prior probability of that classification, and πi represents the population density.[6] - Fisher’s linear discriminant rule: Maximizes the ratio between SSbetween and SSwithin, and finds a linear combination of the predictors to predict group.[6]
Eigenvalues
An eigenvalue in discriminant analysis is the characteristic root of each function. It is an indication of how well that function differentiates the groups, where the larger the eigenvalue, the better the function differentiates.[3] This however, should be interpreted with caution, as eigenvalues have no upper limit.[2][3] The eigenvalue can be viewed as a ratio of SSbetween and SSwithin as in ANOVA when the dependent variable is the discriminant function, and the groups are the levels of the IV.[2] This means that the largest eigenvalue is associated with the first function, the second largest with the second, etc..
Effect size
Some suggest the use of eigenvalues as effect size measures, however, this is generally not supported.[2] Instead, the canonical correlation is the preferred measure of effect size. It is similar to the eigenvalue, but is the square root of the ratio of SSbetween and SStotal. It is the correlation between groups and the function.[2] Another popular measure of effect size is the percent of variance for each function. This is calculated by: (λx/Σλi) X 100 where λx is the eigenvalue for the function and Σλi is the sum of all eigenvalues. This tells us how strong the prediction is for that particular function compared to the others.[2] Percent correctly classified can also be analyzed as an effect size. The kappa value can describe this while correcting for chance agreement.[2]
Variations
- Multiple discriminant analysis (MDA): related to MANOVA. Has more than two groups, and uses multiple dummy variables.[7]
- Sequential discriminant analysis: assesses the importance of a set of IVs over and above a set of controls. In this case, the controls are entered first, and then the IVs.[7]
- Stepwise discriminant analysis: Selects the most correlated predictor first, removes that variance in the grouping variable then adds the next most correlated and continues until the change in canonical correlation is not significant. Of course, both forward and backward stepwise procedures may be performed.[7]
Comparison to logistic regression
Discriminant function analysis is very similar to logistic regression, and both can be used to answer the same research questions.[2] Logistic regression does not have as many assumptions and restrictions as discriminant analysis. However, when discriminant analysis’ assumptions are met, it is more powerful than logistic regression. Unlike logistic regression, discriminant analysis can be used with small sample sizes. It has been shown that when sample sizes are equal, and homogeneity of variance/covariance holds, discriminant analysis is more accurate.[3] With all this being considered, logistic regression is the common choice nowadays, since the assumptions of discriminant analysis are rarely met.[1][3]
See also
References
- 1 2 Cohen et al. Applied Multiple Regression/Correlation Analysis for the Behavioural Sciences 3rd ed. (2003). Taylor & Francis Group.
- 1 2 3 4 5 6 7 8 9 10 11 12 Green, S.B. Salkind, N. J. & Akey, T. M. (2008). Using SPSS for Windows and Macintosh: Analyzing and understanding data. New Jersey: Prentice Hall.
- 1 2 3 4 5 6 7 8 9 10 BÖKEOĞLU ÇOKLUK, Ö, & BÜYÜKÖZTÜRK, Ş. (2008). Discriminant function analysis: Concept and application. Eğitim araştırmaları dergisi, (33), 73-92.
- ↑ Lachenbruch, P. A. (1975). Discriminant analysis. NY: Hafner
- ↑ Klecka, William R. (1980). Discriminant analysis. Quantitative Applications in the Social Sciences Series, No. 19. Thousand Oaks, CA: Sage Publications.
- 1 2 3 Hardle, W., Simar, L. (2007). Applied Multivariate Statistical Analysis. Springer Berlin Heidelberg. pp. 289-303.
- 1 2 3 Garson, G. D. (2008). Discriminant function analysis. http://www2.chass.ncsu.edu/garson/pa765/discrim.htm .
External links
| Wikiversity has learning materials about Discriminant function analysis |
- Course notes, Discriminant function analysis by G. David Garson, NC State University
- Discriminant analysis tutorial in Microsoft Excel by Kardi Teknomo
- Course notes, Discriminant function analysis by David W. Stockburger, Missouri State University
- Discriminant function analysis (DA) by John Poulsen and Aaron French, San Francisco State University